







1.分析目的:用户在观看视频时会产生丰富的行为数据,如弹幕。通过分析这些行为数据,可以了解用户的兴趣偏好、观看习惯等
2.请求数据
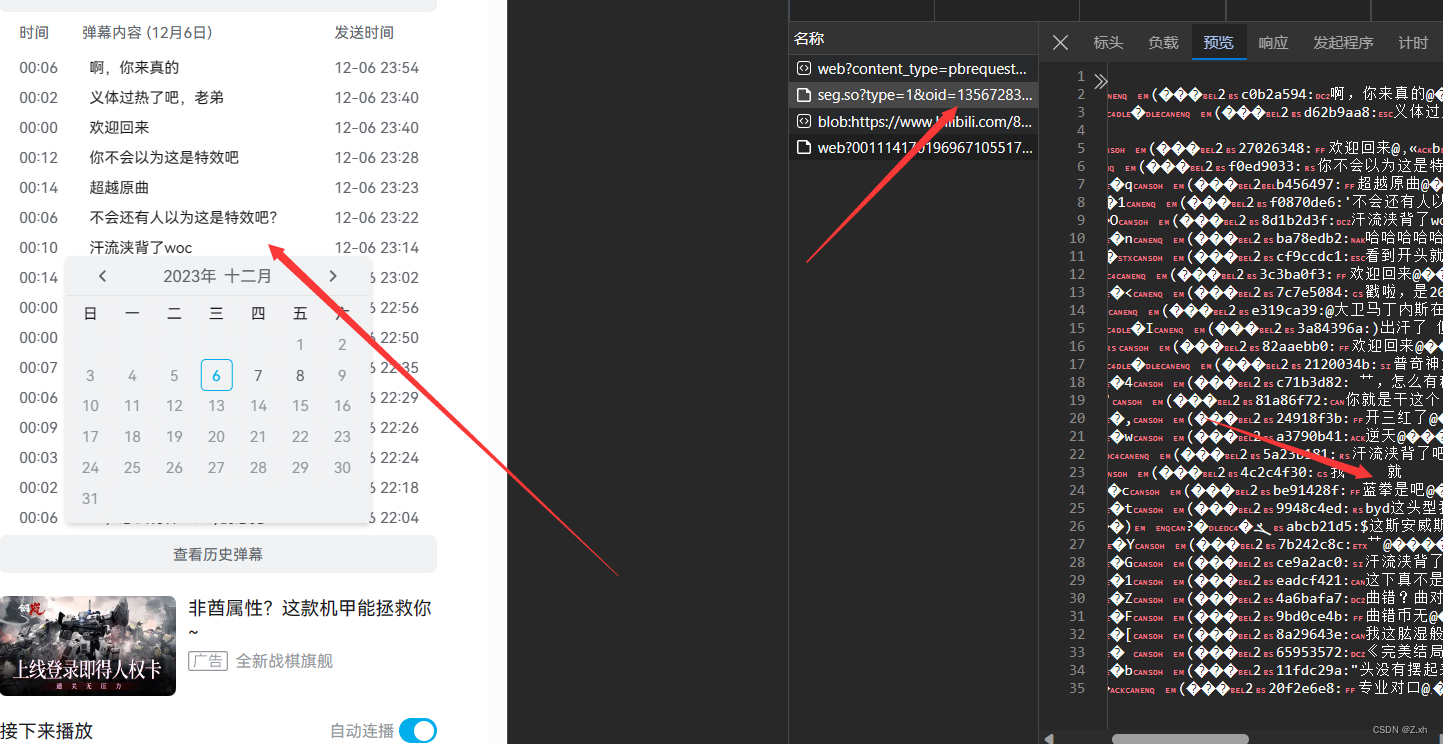 3.这里选取首页的热门视频,打开网页的开发者模式,点击网络刷新页面,点击查看历史弹幕。
3.这里选取首页的热门视频,打开网页的开发者模式,点击网络刷新页面,点击查看历史弹幕。
4.这里再次刷新,能看到一个数据包里面又想要的弹幕数据。
5.这里的地址作为请求数据,查看历史弹幕需要登陆,这里需要放入cookie信息
import requests
import re
for page in range (6,9): #爬取六号到八号的弹幕
url = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=1356728331&date=2023-12-0{page}'
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3704
3704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









