







目录
一、HDFS文件系统基本信息
1. HDFS的路径表达形式
HDFS作为分布式存储的文件系统,有其对数据的路径表达方式。
HDFS同Linux系统一样,均是以/作为根目录的组织形式。
2.HDFS和Linux的根目录的区分
2.1 HDFS和Linux的根目录都是/ 那该如何区分两者的根目录呢?
使用协议头file:// 和 hdfs://namenode:port 来区分。
- Linux :file:///
- HDFS:hdfs://namenode:port/ (namenode:主节点 port:端口号)
示例:
- Linux根目录下的test.txt文件路径 :file:///test.txt
- HDFS根目录下的test.txt文件路径:hdfs://node1:8020/test.txt
2.2 协议头file:/// 或 hdfs://node1:8020/可以省略
一般情况下,命令中需要提供Linux路径的参数,会自动识别为file:// ,需要提供HDFS路径的参数,会自动识别为hdfs://
除非命令的文档中明确需要写或不写会有BUG,否则一般不用写协议头,在下面的命令讲解中我会详细说明。

二、 使用命令操作HDFS文件系统
0. Hadoop的两套命令体系
对于HDFS文件系统的操作,Hadoop有2套命令体系:
- hadoop命令(老版本用法),用法:hadoop fs [generic options]
- hdfs命令(新版本用法),用法:hdfs dfs [generic options]
两者在文件系统操作上,用法完全一致 用哪个都可以
某些特殊操作需要选择hadoop命令或hdfs命令 讲到的时候具体分析
1. 创建文件夹
命令: hadoop fs -mkdir [-p] <path> ... hdfs dfs -mkdir [-p] <path> ... 示例: hadoop fs -mkdir -p /bigdata1/test1 hdfs dfs -mkdir -p /bigdata2/test2 说明: 如果不带协议头默认是在hdfs的根目录中创建目录 path 为待创建的目录 -p选项的行为与Linux mkdir -p一致,它会沿着路径创建父目录。

2. 查看指定目录下内容
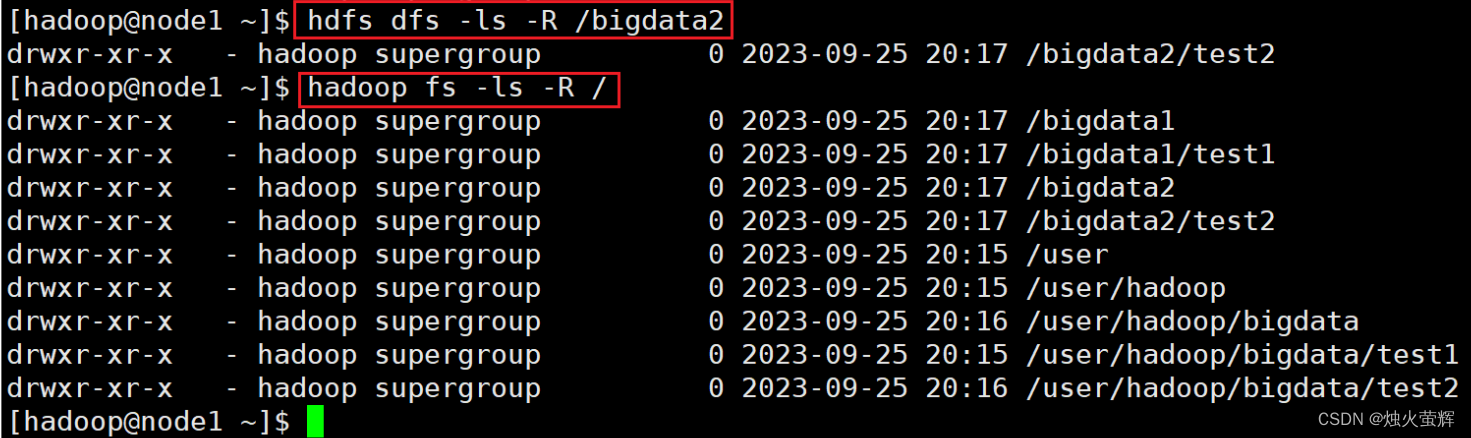
命令: hadoop fs -ls [-h] [-R] [<path> ...] hdfs dfs -ls [-h] [-R] [<path> ...] 示例: hadoop fs -ls -h -R /bigdata1 hdfs dfs -ls -h -R /bigdata12 说明: path 指定目录路径 -h 显示文件大小,带单位 -R 递归查看指定目录及其子目录
3. 上传文件到HDFS指定目录下
上传命令的作用是从Linux文件系统上传文件到HDFS文件系统下。
命令: hadoop fs -put [-f] [-p] <localsrc> ... <dst> hdfs dfs -put [-f] [-p] <localsrc> ... <dst> 示例: hadoop fs -put /data/test.txt / hdfs dfs -put -f /data/test.txt / 说明: -f 覆盖目标文件(如果已存在同名文件,只能用-f选项强行覆盖,不然无法上传) -p 保留访问和修改时间、所有权和权限。 localsrc 本地文件系统路径(Linux路径) dst 目标文件系统路径(HDFS路径)

4. 查看HDFS文件内容
命令: hadoop fs -cat <dst> ... hdfs dfs -cat <dst> ... 示例: hdfs dfs -cat /test.txt 说明: dst HDFS文件系统路径读取大文件可以使用管道符配合more hadoop fs -cat <dst> | more hdfs dfs -cat <dst> | more 示例: hadoop fs -cat /test.txt | more hdfs dfs -cat /test.txt | more 说明: dst HDFS文件系统路径 | Linux下的管道符 more Linux下的翻页指令 | 和 more配合使用,即可实现翻页查看大文件,不会直接一股脑往后面跳

5. 下载HDFS文件
命令: hadoop fs -get [-f] [-p] <src> ... <localdst> hdfs dfs -get [-f] [-p] <src> ... <localdst> 示例: hadoop fs -get ./test.txt . hdfs dfs -get ./test.txt . 说明: 下载文件到本地文件系统指定目录,localdst必须是目录 -f 覆盖目标文件(如果已存在同名文件,只能用-f选项强行覆盖,不然无法下载) -p 保留访问和修改时间,所有权和权限。下载命令的作用是从HDFS文件系统下载文件到Linux文件系统下。

6. 拷贝HDFS文件
命令: hadoop fs -cp [-f] <src> ... <dst> hdfs dfs -cp [-f] <src> ... <dst> 示例: hadoop fs -cp /test.txt /bigdata1/test1/ 说明: -f 覆盖目标文件(已存在下) src HDFS文件系统路径(HDFS路径) dst 目标HDFS文件系统路径(HDFS路径) 该命令用于HDFS文件系统中文件拷贝,从Linux到HDFS这叫上传

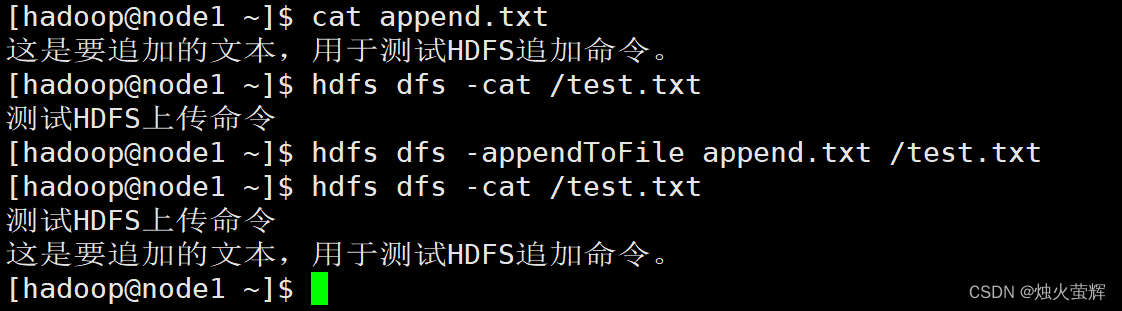
7. 追加数据到HDFS文件中
命令: hadoop fs -appendToFile <localsrc> ... <dst> hdfs dfs -appendToFile <localsrc> ... <dst> 示例: hadoop fs -appendToFile 说明: 该命令用于将给定本地文件的内容追加到给定HDFS文件末尾。 dst如果文件不存在,将创建该文件。 对于HDFS中的文件,我们只能追加和删除,无法随意修改。 如果<localSrc>为-,则输入为从标准输入中读取。
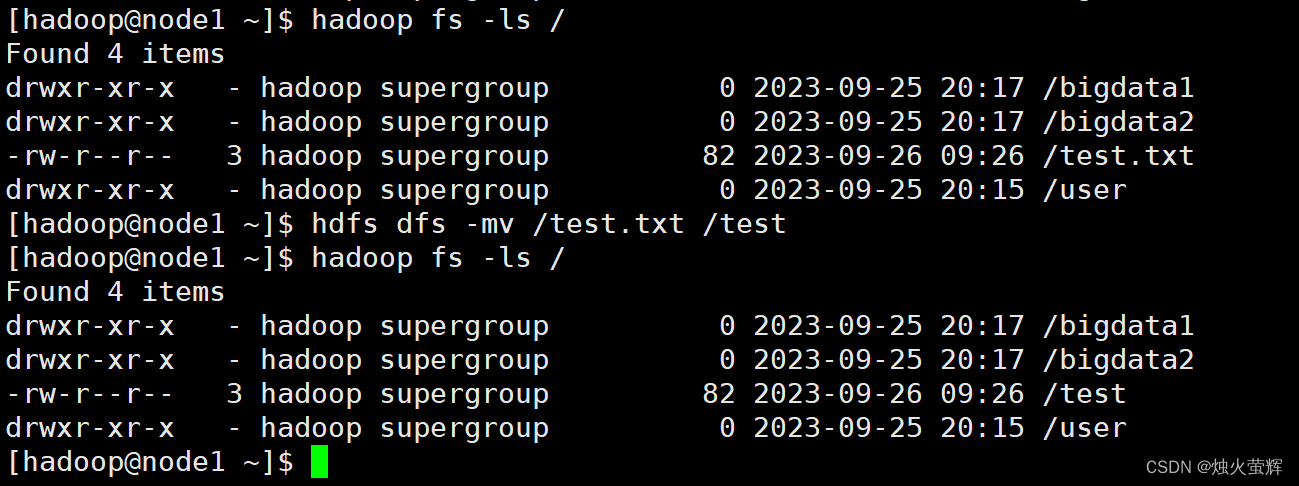
8. HDFS数据移动操作
命令: hadoop fs -mv <src> ... <dst> hdfs dfs -mv <src> ... <dst> 示例: hadoop fs -mv /test.txt /test hdfs dfs -mv /test.txt /test 说明: 该命令可以移动HDFS文件到指HDFS定文件夹下 也可以使用该命令对文件进行重命名
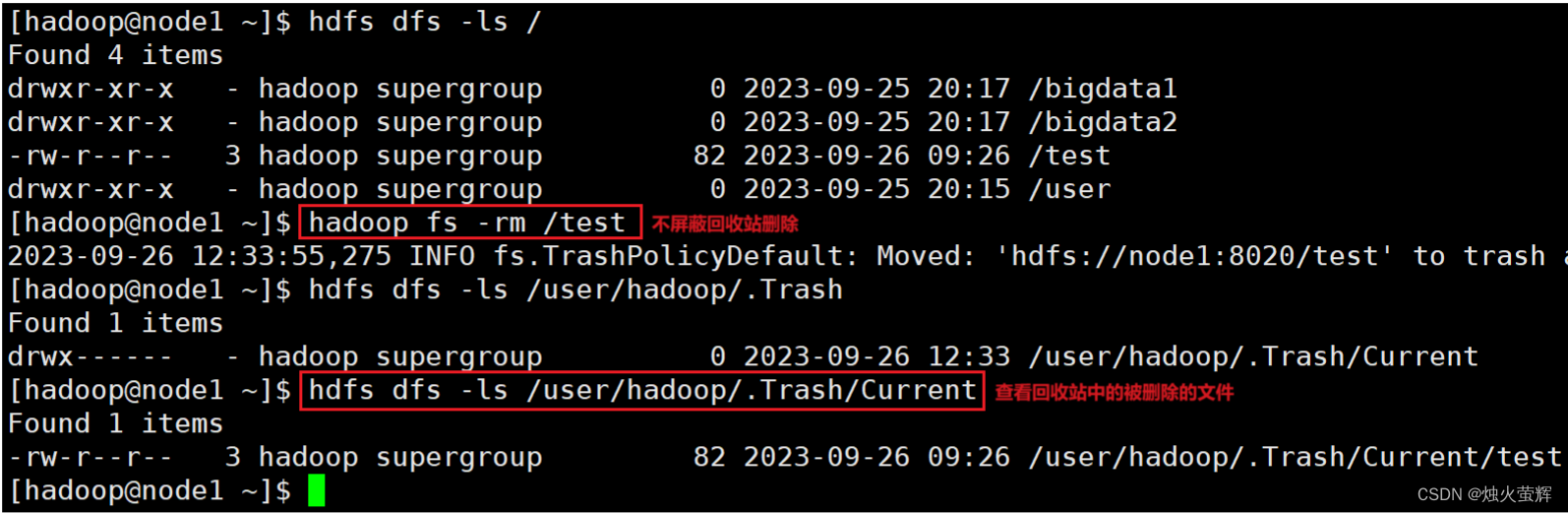
9. HDFS数据删除操作
命令: hadoop fs -rm -r [-skipTrash] URI [URI ...] hdfs dfs -rm -r [-skipTrash] URI [URI ...] 示例: hadoop fs -rm -r bigdata 说明: 带-r就是删除文件夹 删除指定路径的文件或文件夹 -skipTrash 跳过回收站,直接删除(如果没有设置回收站,不用这个选项也是直接删除)

拓. 开启HDFS文件系统回收站
HDFS文件系统是支持回收站的,不过回收站功能默认关闭,如果要开启需要在core-site.xml内配置:
1. 使用vim打开core-site.xml文件: vim /export/server/hadoop/etc/hadoop/core-site.xml 2. 按i进入插入模式 3. 在<configuration></configuration>中间加入以下内容: <property> <name>fs.trash.interval</name> <value>1440</value> </property> <property> <name>fs.trash.checkpoint.interval</name> <value>120</value> </property> 4. 按下Esc退出插入模式,按下Shift+:进入底行模式,按下wq!和回车保存文件并退出。 说明: 1. <name>fs.trash.interval</name> <value>1440</value> 是在设置回收站保留时间,这里设置的是保留1440分钟,也就是一天。 2. <name>fs.trash.checkpoint.interval</name> <value>120</value> 是在设置回收站检查时间,检查回收站要删除的文件,这里设置的是120分钟。 3.无需重启集群,在哪个机器配置的,保存配置后,在哪个机器执行命令就生效。 4.回收站默认位置在:/user/用户名(hadoop)/.Trash

10. HDFS的其它命令
HDFS还有其他许多命令,博主在这里只介绍几个日常中常用的基本命令,如果对这块感兴趣的话,可以看这个:命令官方指导文档
三、 HDFS WEB操作HDFS文件系统
1. HDFS WEB浏览HDFS文件系统
除了使用命令操作HDFS文件系统外,在HDFS的WEB UI上也可以查看HDFS文件系统的内容。
1. 在浏览器输入http://node1:9870/进入HDFS WEB
2. 选择导航栏Utilities下的Browse the file system


2. HDFS WEB操作HDFS文件系统
2.1 默认以匿名用户进入HDFS WEB
我们进入HDFS WEB是以匿名用户(dr.who)进入,只有只读权限,默认是没有权限操作HDFS文件系统的。
2.2 配置core-site.xml文件以特权用户进入HDFS WEB
想要操作的话需要以特权用户在浏览器中进行操作,需要配置core-site.xml文件并重启集群。
步骤:
1. 使用vim打开core-site.xml文件: vim /export/server/hadoop/etc/hadoop/core-site.xml 2. 按i进入插入模式 3. 在<configuration></configuration>中间加入以下内容: <property> <name>hadoop.http.staticuser.user</name> <value>hadoop</value> </property> 4. 按下Esc退出插入模式,按下Shift+:进入底行模式,按下wq!和回车保存文件并退出。 说明: <name>hadoop.http.staticuser.user</name> <value>hadoop</value> 默认以hadoop用户登录HDFS WEB,hadoop在之前已经被授权为了最高级别用户。
2.3 使用HDFS WEB对HDFS文件系统进行基本操作
现在我们能使用HDFS WEB对HDFS文件系统进行基本操作了。
博主写这个,这是想告诉大家我们可以这样做。但是,不推荐这样做!
因为以匿名用户(dr.who)进入HDFS WEBUI,只有只读权限就够了,我们用HDFS WEBUI能简单浏览即可,如果给与高权限,会有很大的安全问题,如容易造成数据泄露或丢失。


------------------------END-------------------------
才疏学浅,谬误难免,欢迎各位批评指正。
















 1565
1565











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











