







Pagerank的实现原理
目录
PageRank背景知识
Google早已成为全球最成功的互联网搜索引擎,但这个当前的搜索引擎巨无霸却不是最早的互联网搜索引擎,在Google出现之前,曾出现过许多通用或专业领域搜索引擎。Google最终能击败所有竞争对手,很大程度上是因为它解决了困扰前辈们的最大难题:对搜索结果按重要性排序。而解决这个问题的算法就是PageRank。毫不夸张的说,是PageRank算法成就了Google今天的低位。
最早的搜索引擎采用的是分类目录的方法,即通过人工进行网页分类并整理出高质量的网站。那时 Yahoo 和国内的 hao123 就是使用的这种方法。
后来网页越来越多,人工分类已经不现实了。搜索引擎进入了文本检索的时代,即计算用户查询关键词与网页内容的相关程度来返回搜索结果。这种方法突破了数量的限制,但是搜索结果不是很好。因为总有某些网页来回地倒腾某些关键词使自己的搜索排名靠前。
于是我们的主角要登场了。没错,谷歌的两位创始人,当时还是美国斯坦福大学 (Stanford University) 研究生的佩奇 (Larry Page) 和布林 (Sergey Brin) 开始了对网页排序问题的研究。他们的借鉴了学术界评判学术论文重要性的通用方法, 那就是看论文的引用次数。由此想到网页的重要性也可以根据这种方法来评价。于是PageRank的核心思想就诞生了,非常简单:
如果一个网页被很多其他网页链接到的话说明这个网页比较重要,也就是PageRank值会相对较高.
如果一个PageRank值很高的网页链接到一个其他的网页,那么被链接到的网页的PageRank值会相应地因此而提高.
*背景知识部分主要参考大佬的博客 张洋:浅析PageRank算法 和 刀刀流:PageRank算法–从原理到实现
PageRank简析
问题:Pagerank是什么
将各网页之间的链接关系按照下文中的幂次迭代矩阵A形式表示,那么各个网页的PageRank值将组成一个长度为URLNUM的列向量,该列向量就是矩阵A的特征值为1对应的特征向量。
即 PagerRank就是幂次迭代矩阵A的特征值为1的特征向量的元素值
即 求解PageRank的值就是求解幂次迭代矩阵A的特征值为1对应的特征向量
*看到这个结论你可能云里雾里,稀里糊涂。但是请你放心大胆的先记住这个结论,学会使用。如果你想深入了解为什么特征值为1对应的特征向量就是PageRank值,可以参考佩奇和布林的论文。本文暂不做深入解析。
*本文后面部分主要解决:1.幂次迭代矩阵A是什么 | 2.如何求解某矩阵特征值为1的特征向量
链接关系的矩阵表示形式
我们使用邻接矩阵的方式来表示各网页之间链接关系,可以非常高效和方便,同时也便于理解和计算。本部分以下图为例,主要讲解表示链接关系的邻接矩阵,以及后续计算会用到的各种其他形式的矩阵
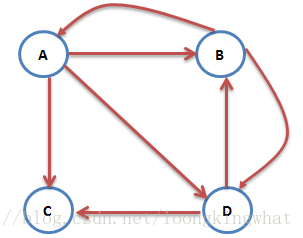
设定参与PageRank计算的所有URL数目为URLNUM,该数值可以在从文件中读取网页的时候进行统计。也可以从简单的有向图中进行统计,此处以以上有向图为例,所以URLNUM =4
所有网页有固定的编号,从0~URLNUM或者从1~(URLNUM-1),各个网页的链接关系由两个编号表示,例如“ 1 4”表示从编号为1的网页可以连接到编号为4的网页。同时本项目在github上的代码支持从后者编号连接到前者编号对应网页的表示形式。
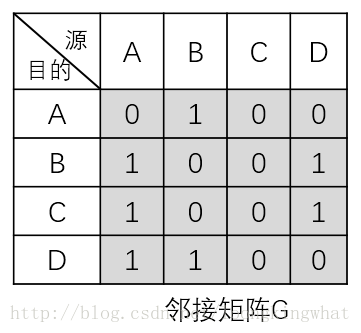
邻接矩阵G
用邻接矩阵表示各个网页之间的链接关系,为了方便迭代中矩阵相乘的运算,要求G_ij中的某一个元素是从ID= i 的源网页链接到ID= j 的目的网页的关系值。如果有链接关系值为1,如果没有链接关系值为0。换句话来说,行号对应的是目的网页ID,而列号对应的是源网页ID,且邻接矩阵的大小是URLNUM x URLNUM.
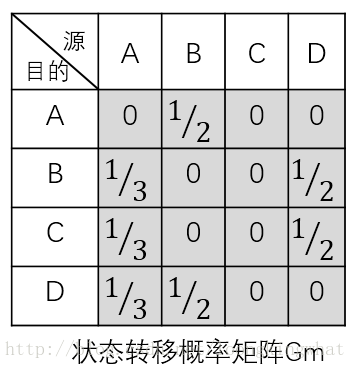
状态转移概率矩阵Gm
设定每一个网页的pagerank初始值为1,那么由该网页链接出linkOutNum个网页,每个网页获得的pagerank值为1/linkOutNum。将邻接矩阵当中的非零元素值都进行这样的计算之后再替换原本所有的1。状态转移概率矩阵的大小也为URLNUM x URLNUM.
校正基础矩阵D
为了避免link seal等问题,需要根据公式进行校正。如果,那么就会有一个校正基础矩阵D,与邻接矩阵叠加形成最后参与幂次迭代矩阵A。校正基础矩阵的每一个元素都等于1/URLNUM,且大小为URLNUM x URLNUM.

幂次迭代矩阵A
校正基础矩阵D与概率转移矩阵Gm按照如下图中的公式叠加形成参与幂次迭代的矩阵A。且该幂次迭代矩阵A大小为URLNUM x URLNUM.

*看完各种矩阵,可能会和我当初学习的时候一样疑惑,这都什么!都有什么用!上述所有的矩阵中,秉持一个原则
参与后续计算的矩阵只有最后的幂次迭代矩阵A,其他的矩阵都是计算矩阵A的辅助过程
*当然,还有很多博客使用如下的公式直接从概率转移矩阵Gm求解出参与幂次迭代的矩阵A。总而言之,不管任何方法,只要能正确求出矩阵A都是可以的。本文中引入校正基础矩阵D,主要是为了更清晰的展示矩阵A的生成过程。

简单模型的缺点与随机浏览模型
简单模型的缺点
简单模型就是简单分配每个网页的PageRank值,将所有链接关系通过邻接矩阵表示出来的Gm。它是存在rank leak和rank sink的缺点,无法用来进行计算。
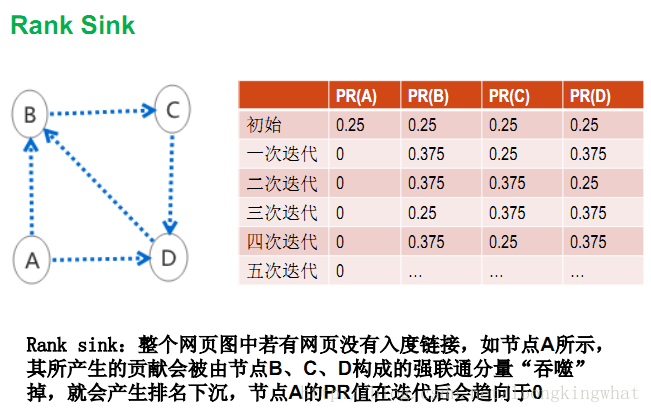
上述的迭代是指初始的PageRank列向量与矩阵Gm不断相乘,得到新的PageRank的过程,发现节点A只有出度链接,没有入度链接,该节点A在迭代过程中,其PageRank值会变成0,这显然是不符合实际的。
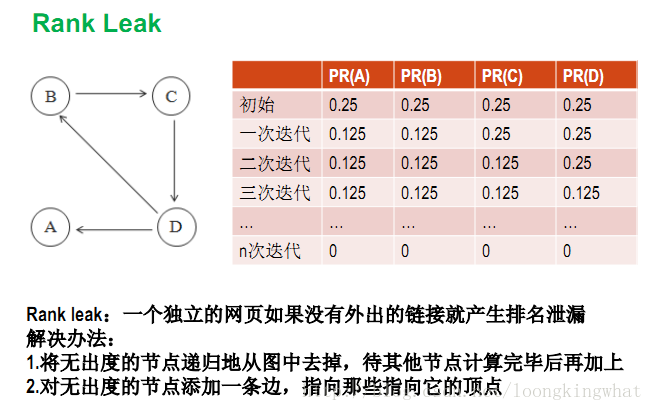
上述展示的是Rank sink的问题,即如果存在只有入度链接而没有出度链接的节点时,经过多次迭代之后,各个节点的PageRank值都会变成0,这显然也是不符合实际的。
*图片来源:苹果9090的博客 该博客在简单模型和随机浏览模型的辨析上写的非常详细,如果对这部分内容不理解,可以参考这篇博文。
*大佬的这篇博客PageRank算法简介及Map-Reduce实现 中对简单模型的缺点也进行了详细的解析,其中提到终止点问题和陷阱问题就对应本文的Rank Leak问题。
上述的问题也说明了,利用简单模型的Gm求解特征向量是不可行的,需要进行改进
随机浏览模型
用户的浏览行为其实不仅仅只是浏览某个页面,然后点击该页面中的某个链接,进行下一个页面访问。有时候用户浏览完某个页面之后,会随机浏览另外的页面,而不是根据该页面的链接。因此PageRank随机浏览模型更贴近用户的行为方式。具体的内容可以仔细查看下图,对随机浏览模型进行了详细的解释,同时也回到了前面矩阵表示的相关问题。
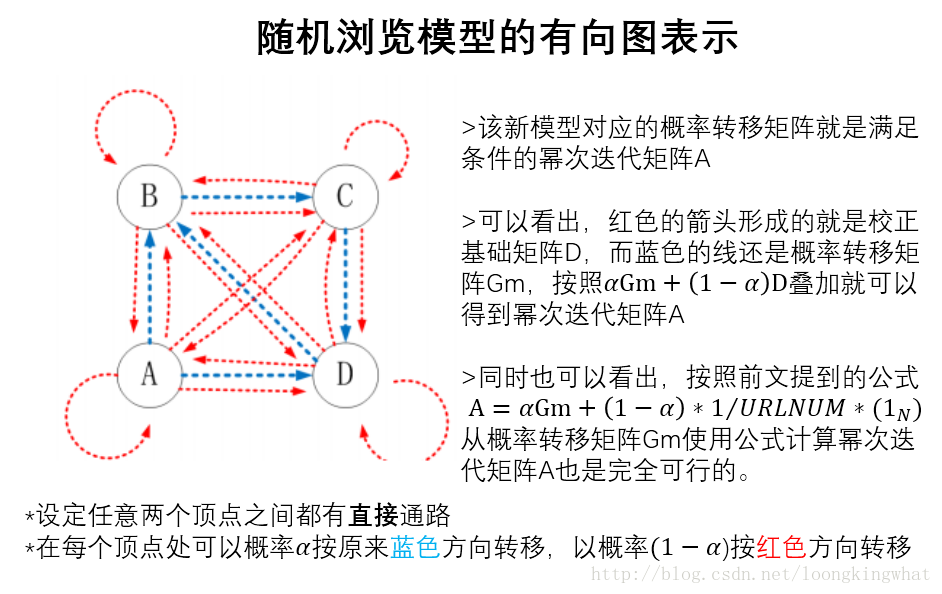
其实,随机浏览模型相对于简单模型而言,该模型更加符合用户的行为,同时解决了Rank Leak和Rank Sink的问题,保证了算法收敛的唯一性。
链接关系在程序中的存储形式
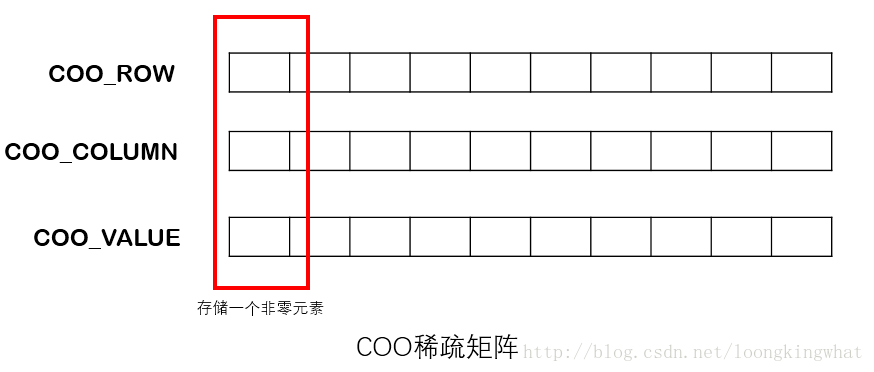
当参与PageRank计算的网页数目达到百万级甚至更大的时候,无法将二维的矩阵直接通过二维的数组进行完整的存储的时候,可以考虑使用稀疏矩阵来存储。本文主要讲解COO稀疏矩阵。
链接关系在程序中用邻接矩阵表示,但是考虑邻接矩阵中零元素很多,可以采用稀疏矩阵存储。本项目中采用COO稀疏矩阵模式,用行数组、列数组和value数组三个数组,将非零元素的位置(行、列)和值(value)存储下来。
在存储幂次迭代矩阵A的时候,发现矩阵A中没有零元素,但是依旧可以使用该COO稀疏矩阵进行存储矩阵A。因为原本Gm中所有零元素的位置在叠加校正基本矩阵A之后,值统一都是(1-α)/URLNUM。可以将除该值之外的其他元素视为非零元素存储在稀疏矩阵中,所有值为(1-α)/URLNUM都视作“零元素”而不需要存储,我们可以默认知道所有没有存在稀疏矩阵中的元素的值都等于(1-α)/URLNUM,就像原本默认没有存在稀疏矩阵中的元素的值都是零一样。
值得注意的是,由于邻接矩阵中行号标识目的网页ID,列号标识源网页ID。所以COO稀疏矩阵中,行数组存储邻接矩阵中非零元素位置的行号,即存储的都是目的网页ID;列数组存储该非零元素的列号,即存储的都是源网页ID; value数组用来存储这个非零元素的值。并且,行数组、列数组和value数组的同一位置元素值,刚好可以还原一个非零元素的位置信息和值信息。那么,容易知道行数组和列数组应该定义为int类型,而value数组应该定义为float类型。
迭代规则和原理
本文的前面的部分主要解决了关于矩阵A的求解的问题,后面部分开始讲解求矩阵A的特征向量。
该小节主要解析两个问题:1.为什么要进行幂次迭代;2.如何进行幂次迭代。
为什么要进行幂次迭代
首先再次强调,要知道所谓的各个网页的pagerank值,其实是关于矩阵A的特征值为1的特征向量。要求pagerank值就是要求特征向量。求解特征向量的计算规模是O(n^3),也就是求得慢同时还有可能求不准。所以只能采用迭代的方式,最终迭代出收敛的特征向量,也即待求的pagerank数组。
*当然,除了幂次迭代的方式之外,还有很多其他的方法可以求解特征向量,但是幂法是最经典的一种方法,本文仅介绍该方法。
*随机浏览模型保证了幂法的可用性,即迭代一定会收敛。所以要用幂法迭代,就要使用随机概率模型对应的幂次迭代矩阵A。
*如果想了解幂法背后的数学原理,可以参考 真实的归宿:PageRank算法概述 中第4部分 PageRank幂法计算。
如何进行幂次迭代
迭代初始向量PageRank[URLNUM]与幂次迭代矩阵A相乘,直到满足精度条件。即
LastRank[ URLNUM ] = PageRank[URLNUM]
PageRank[URLNUM] = A× LastRank [ URLNUM ]
Until |PageRank[URLNUM] – LastRank[URLNUM]| < limitation
方阵和列向量的相乘获得一个新的列向量,新列向量的第i个元素值就是方阵的每i行与原列向量的第i个相乘累加求得。
两个向量之间的距离就是各个元素之间距离平方累加求和之后,再对和开方求得
*在张洋:浅析PageRank算法 中使用了另外一种基于矩阵Gm进行迭代方式,无需计算幂次迭代矩阵A,而是在每次迭代的计算中直接叠加一个列向量。如果对矩阵的计算比较熟悉,该列向量就相当于校正基本矩阵A与PageRank列向量相乘得到的列向量,可以发现它的方法与基于矩阵A做迭代背后的思想和结果都一样。如果感兴趣,可以了解一下。不感兴趣,可以依旧沿着之前理解继续做,没有任何应用上的影响。个人认为,按照本文随机浏览模型中蓝色的线代表校正基础矩阵A部分,红色线代表转移概率矩阵Gm部分,更容易理解,在计算的时候也更方便处理。
迭代在程序中的具体实现
如果采用稀疏矩阵进行链接关系的存储,可以采用本部分的迭代操作。如果采用简单的二维数组完整的存储了所有的链接关系,可以依次取行和列向量计算迭代。本小节主要针对COO稀疏矩阵下的高效迭代
在程序具体实现矩阵相乘迭代过程中,首先将所有元素点都按照无链接关系处理,完成一部分累加。然后遍历COO数组,将有链接关系的点重新累加到迭代关系中,同时减去原本该位置按照无链接关系处理时的累加值。最终即可得到完成所有累加操作的pagerank数组。操作过程及原因见下图:
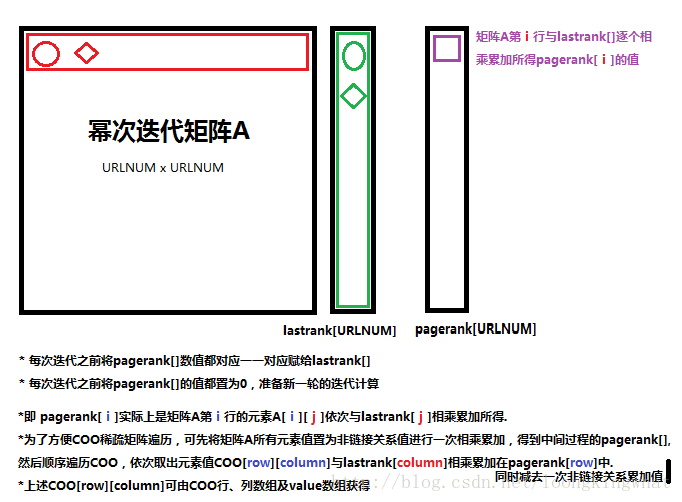
本文代码已经放在https://github.com/dragon-wl/PageRank,代码经测试可用,使用说明和注释已经在代码中标注。欢迎小伙伴们随时交流(403537257@qq.com)~















 935
935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









