







Ansible自动化
自动化的需求:
1. 在什么样的场景下需要自动化?
批量化的工作: 装软件包、配置服务、升级、下发文件…
2. 为什么在自动化工具中选择ansible?
对比shell脚本: 相对于用shell的脚本来实现自动化,ansible更加的灵活;比如ansible的变量、ansible的模块、ansible的剧本,通过ansible的高级特性,可以轻松的完成自动化的任务
对比其他自动化工具: ansible 简单 、 强大
简单: 人工可读的自动化 剧本的语言使用yaml来进行编写
强大: 在所有的被控节点,不需要安装任何客户端代理
可以通过应用原生的方式管理应用本身而无需代理
什么是ansible:
ansible是一个自动化的工具;ansible可以完成基础设施的自动化管理,包括但不限于服务器、网络设备、存储、公私有云都能进行自动化,在滚动更新、配置下发上有天然的优势
ansible的特点:
1. 不需要再被控节点(被管理节点)不需要安装任何客户端代理
应用原生的方式来管理应用本身,所谓应用原生的方式指的就是:应用自带的管理方式,例如Linux的ssh、windows的 winrm、公私有云的API接口、网络设备的SNMP…
2. ansible是一个工具,没有任何的服务需要启动;只需要执行ansible命令即可
3. ansible是基于python进行开发,但是ansible的模块可以使用任意语言进行开发
4. ansible通过剧本来对任务进行编排,使得任务具有可移植性
5. ansible 默认使用ssh 来管理被控,因此Linux不需要做配置即可被管理
6. ansible支持多级控制
ansible的架构:
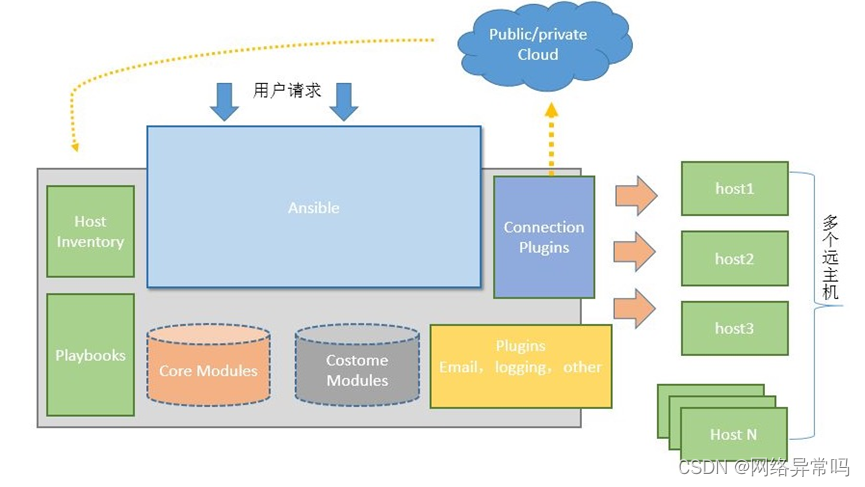
- 核心:ansible
- 核心模块(Core Modules):这些都是ansible自带的模块
- 扩展模块(Custom Modules):如果核心模块不足以完成某种功能,可以添加扩展模块
- 插件(Plugins):完成模块功能的补充
- 剧本(Playbooks):把需要完成的多个任务定义在剧本中
- 连接插件(Connectior Plugins):ansible基于连接插件连接到各个主机上,虽然ansible是使用ssh连接到各个主机的,但是它还支持其他的连接方法,所以需要有连接插件
- 主机清单(Host Inventory):ansible在管理多台主机时,可以选择只对其中的一部分执行某些操作
ansible工作机制:
Ansible 在管理节点将 Ansible 模块通过 SSH 协议(或者 Kerberos、LDAP)推送到被管理端执行,执行完之后自动删除,可以使用版本控制系统(git/svn)来管理自定义模块及playbooks

ansible的安装方式:
1.通过源码包进行安装
wget https://kkgithub.com/ansible/ansible/archive/refs/tags/v2.9.0.zip
unzip v2.9.0.zip
python3 setup.py build 构建包
python3 setup.py install 安装包
wget https://raw.kkgithub.com/bikashhite/ansible.cfg/master/cfg%20file 下载配置文件
2.通过发行包进行安装(RHEL:RPM包、ubuntu:Deb包)
配置YUM仓库地址: Index of /ansible/rpm/release
适用于RHEL9 yum install ansible-core -y
适用于RHEL8 yum install ansible -y
3.通过第三方PIP包管理器进行安装
pip install ansible==2.9.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
4.通过容器进行安装——>ansible的导航器
安装ansible的导航器
yum install ansible-navigator
拉取容器镜像
podman login registry.redhat.io
使用导航器运行容器
ansible-navigator images 查看运行的ansible环境
在RHEL9中将ansible拆分成两部分
ansible的核心包 ansible核心主程序 只携带了ansible的必要模块
ansible的扩展包 ansible的附加模块 集合
主机清单的定义方式:
1. 直接使用主机名进行定义
node1.example.com
node2.example.com
node3.example.com
2. 使用IP地址定义主机
192.168.1.10
3. 使用主机组定义主机
[webserver] 组名
172.16.0.100 组的成员
172.16.0.200
4. 使用嵌套组调用多个主机组
[allserver:children] 嵌套组名
mysql
webserver
注意: 在定义主机和主机组时,主机需要定义在主机组的前面;如果定义在主机组后面,无论有多少空行,该主机都会成为组的成员
5. 通过数字或者字母范围批量定义主机
lvs[1:100] 表示一百台lvs,也就是从lvs1 - lvs100 一共100台
demo[a:z]
清单主机的查询方式:
如何使用ansible选择主机:
1. 直接选择所有的主机
ansible all --list-hosts
2. 选择指定的主机或者主机组
ansible node1.example.com --list-hosts
ansible webserver --list-hosts
3. 选择指定的多个主机或多个主机组
ansible node1.example.com,db1.example.com --list-hosts
ansible webserver,mysql --list-hosts
4. 选择没有主机组的主机
ansible ungrouped --list-hosts
5. 使用通配符来选择主机
ansible node* --list-hosts
ansible *.example.com --list-hosts
ansible db*com --list-hosts
6. 使用感叹号反向过滤
ansible '*.example.com,!node3*' --list-hosts 对指定主机取反
7. 使用and符号来联合选择主机
ansible 'mysql,&webserver' --list-hosts 选择即在mysql组中又在webserver中
8. 通过正则进行选择主机
ansible '~^(d|n)' --list-hosts
9. 通过limit进行选择主机
ansible node1.example.com --list-hosts
ansible all --limit @host.txt --list-hosts
ansible的配置文件优先级:
优先级最高的是 ANSIBLE_CONFIG 环境变量
优先级其次的是 当前工作目录下的ansible.cfg
优先级较次的是 当前用户家目录下的.ansible.cfg 隐藏文件
优先级最低的是 /etc/ansible/ansible.cfg 全局默认文件
ansible的配置文件:
[defaults]:通用配置项
[inventory]:与主机清单相关的配置项
[privilege_escalation]:特权升级相关的配置项
[paramiko_connection]:使用paramiko连接的相关配置项,Paramiko在RHEL6以及更早的版本中默认使用的ssh连接方式
[ssh_connection]:使用OpenSSH连接的相关配置项,OpenSSH是Ansible在RHEL6之后默认使用的ssh连接方式
[persistent_connection]:持久连接的配置项
[accelerate]:加速模式配置项
[selinux]:selinux相关的配置项
[colors]:ansible命令输出的颜色相关的配置项
[diff]:定义是否在运行时打印diff(变更前与变更后的差异)
ansible的配置案例:
被控端配置:
创建devops用户:
useradd devops
echo redhat|passwd --stdin devops
配置sudo免密提权:
echo devop ALL=(ALL) NOPASSWD:ALL >> /etc/sudoers.d/devops
主控端配置:
ansible.cfg配置文件:
[defaults]
inventory = ./hosts
ask_pass = False
remote_user = devops
deprecation_warnings=False
module_name = shell
host_key_checking = False
[privilege_escalation]
become = True
become_method = sudo
become_ask_pass = False
become_user = root
[ssh_connection]
ssh_args = -C -o ControlMaster=auto -o ControlPersist=60
hosts文件:
node1
node2
ssh生成公私钥并拷贝给node1和node2节点:
ssh-keygen
ssh-copy-id devops@node1
ssh-copy-id devops@node2
ansible连通性测试:
ansible all -m ping
ansible运行任务的方式:
1. 使用ad-hoc运行任务 ——> ansible的临时指令 用来执行简单的任务
2. 使用playbook运行任务 ——> ansible 的剧本 用来执行复杂的任务
注意:在ansible的导航器中,也就是容器版本中ansible的ad-hoc已经废除
ad-hoc的执行:
语法格式:
ansible 主机/主机组 -m 模块 -a ‘模块的参数’ ansible的参数
ansible的模块:
ansible-doc -l 列出当前系统中ansible的所有模块
ansible-doc -s 模块名 查看模块的参数
ansible-doc 模块名 查看模块的详细信息 包括用法
ansible的四大命令执行模块:
command、shell、raw、script 四个模块专门用来执行Linux的指令
ansible默认使用command模块作为默认的命令执行模块
command 有四个例外,如果命令中出现了 <、>、&、|符号则command无法执行
shell 模块相当于在本机执行bash shell一样,可以让ansible执行Linux的指令,并且支持一些高阶参数,例如chdir可以在执行命令前切换到指定的目录,creates、removes等
raw 模块 也相当于在本机执行命令,但是缺少chdir、creates、removes的高阶参数
creates 当文件存在时命令不执行 removes 当文件不存在时命令不执行
script模块 将主控端的shell复制到被控端执行(没有将脚本文件拷贝到对端执行,而是将文件中shell的内容复制到被控端执行)
Ansible Playbook:
playbook 是一系列ansible命令的集合,通过playbook的高级特性可以完成很多复杂的自动化任务,比如在playbook中可以进行任务的判断、循环、还可以将任务的执行结果作为变量,以及从外部或者其他位置获得变量;让playbook 更加的灵活
playbook语言:
playbook 使用yaml作为配置语言,yaml 是非标记型语言(其实还是一种标记型语言),这类语言,通俗易懂;并且不需要掌握编程技能就可以写好这个配置
yaml的约束:
1. 大小写敏感—> 变量的大小写是完全不同的两个变量
2. 使用缩进表示层级关系
3. 只能使用空格进行缩进不能使用tab(从RHEL8.4开始会将yaml中的tab转成空格,个人感觉是vim的版本有关系,vim的版本更高了)
4. 空格的数量不重要,相同的元素向左对齐很重要
5. 使用#符号注释内容,注释一整行
yaml的数据类型:
纯量: 不可再分的值
数组(序列、列表): 一组有次序的值 ,通常使用短横线开头 “-”
对象(字典/哈希/映射): 键值对 key = vaule 用冒号进行表示,也就是key和vaule之间使用冒号分隔,并且vaule前需要使用空格
playbook的示例需求:
1. 在所有节点上安装apache
2. 在所有节点上生成一个名为/var/www/html/index.html的文件内容为hello rhce
3. apache服务需要开机自启动,且当前立即启动
4.配置firewalld防火墙允许web服务器的规则
- name: configure website
hosts: all
remote_user: devops
tasks:
- name: install httpd
yum:
name: httpd
state: present
- name: create file for index.html
copy:
content: "hello rhce\n"
dest: /var/www/html/index.html
mode: 0777
- name: start service
systemd:
name: httpd
state: started
enabled: yes
- name: enable firewalld for 80/tcp
firewalld:
service: http
permanent: yes
immediate: yes
state: enabled
ansible-playbook的执行选项:
-v v越多信息越详细
-syntax-check 检查语法错误
-C 测试运行playbook,测试运行下不会对目标造成真正的影响,则测试剧本能否成功执行
playbook的定义:
playbook由一个或者多个play组成的列表,而一个play就是一组任务的集合,一个play中tasks的任务列表,就是play中要完成的需求,而每一个需求或者说每一个tasks的任务都是对一个模块的调用,因此将play根据一定的顺序或者是逻辑组合在一起完成一个复杂的大任务,我们将其称为playbook的编排
playbook的结构:
Target section:目标、指的是play中需要定义的远程主机、远程用户、是否开启提权、是否需要密码连接等,都在此定义,如果没有定义则使用ansible.cfg中默认的配置,如果用户进行了定义,则以用户定义的为准
Variable section: 变量、指的是在playbook的执行过程中,需要传递给任务或者是其他插件的变量,在此定义,该段落专门用来给playbook定义变量
Task section: 任务、指的是play中所有需要执行的任务在此定义,也就是play的任务列表
Handler section:特定任务、该任务是有条件执行的任务,只有当达到特定条件是该任务才会被触发,一般情况下该任务不会自动执行;该任务在所有tasks任务执行完成后,根据触发的条件来决定是否执行
playbook的任务列表:
1. 任务列表中的所有任务都是从上向下执行
2. 任务列表中任务一旦在某个主机上执行失败,则playbook接下来的任务不会在该主机上执行,也就是在该主机上停止
3. 任务列表中有任务执行失败,只需要修复该任务后继续执行playbook即可完成失败的任务,这是因为ansible具有幂等性,期望值一致(期望状态一致,则任务是执行成功的)
幂等性:对同一个系统,使用同样的条件,一次请求和重复的多次请求对系统资源的影响是一致的
解决ansible的任务报错:
命令执行模块报错(shell、raw): 可以使用逻辑或 通过|| /usr/bin/true 让其返回值永远为零,则任务不会失败
其他模块执行报错:file、user等模块通过ignore_errors: true 来忽略报错
handlers:
在Ansible Playbook中,handler事实上也是个task,只不过这个task默认并不执行,只有在被触发时才执行。
handler通过notify来监视某个或者某几个task,一旦task执行结果发生变化,则触发handler,执行相应操作。
handler会在所有的play都执行完毕之后才会执行,这样可以避免当handler监视的多个task执行结果都发生了变化之后而导致handler的重复执行(handler只需要在最后执行一次即可)
- hosts: node1
force_handlers: yes
tasks:
- name: install vsftpd
dnf:
name: vsftpd
state: present
notify: get_status
- name: create file
file:
path: /opt/vsftpd.txt
state: touch
- shell: ls -l /opt/abbbb.txt
handlers:
- name: aaaaa
systemd:
name: vsftpd
state: started
listen: get_status
Ansible的变量:
变量的约束:
1. ansible的变量名不能以数字开头,但是不表示不能使用数字
2. ansible的变量名,只能是字母或者是下划线和数字组成,只能以字母开头
3. 自定义ansible的变量时,最好不要以ansible作为变量名的开头,以防止和系统中已经存在的变量冲突
调试变量的方式:
ansible中使用 debug模块来调试变量
debug模块有两个参数,且不能共用(也就是两个参数不能一起使用)
msg: 输出字符串内容
var: 输出变量的内容
ansible中定义变量的位置:
1. 在inventory的清单中进行定义
# 一般连接
ansible_host #用于指定被管理的主机的真实IP
ansible_port #用于指定连接到被管理主机的ssh端口号,默认是22
ansible_user #ssh连接时默认使用的用户名
# 特权升级
ansible_become #相当于ansible_sudo或者ansible_su,允许强制特权升级
ansible_become_user #通过特权升级到的用户,相当于ansible_sudo_user或者ansible_su_user
ansible_become_pass # 提升特权时,如果需要密码的话,可以通过该变量指定,相当于ansible_sudo_pass或者ansible_su_pass
ansible_sudo_exec #如果sudo命令不在默认路径,需要指定sudo命令路径
# 特定ssh连接
ansible_connection #SSH连接的类型:local, ssh, paramiko,默认是ssh
ansible_ssh_pass #ssh连接时的密码
ansible_ssh_private_key_file #秘钥文件路径,如果不想使用ssh-agent管理秘钥文件时可以使用此选项
ansible_ssh_executable #如果ssh指令不在默认路径当中,可以使用该变量来定义其路径
#自定义主机变量变量
node1 webserver=nginx
#自定义主机组变量
[group1]
node1
node2
[group2]
node1
[group1:vars]
webserver=tomcat
注意:如果主机组和主机的变量发生了冲突,则以主机的变量为准,主机的变量会覆盖主机组的变量
2. 在playbook的vars关键字段落定义变量
- name: vars demo
hosts: group1
vars:
test: hello
tasks:
- name: print debuginfo
debug:
msg: "{{ test }}"
3. 通过vars_files外部文件引入变量
引入的外部文件的格式为yaml的格式
vim users.yml
users:
- name: ituser001
uid: 1000
- name: ituser002
uid: 2000
vim vars.yml
- name: vars demo
hosts: group1
vars_files:
- users.yml
tasks:
- name: print debuginfo
debug:
msg: "{{ users }}"
如果是字典结构要取到具体的某一项的值,使用点来表示对象的层级结构
4. 通过主机和主机组的目录文件中来定义变量
host_vars、group_vars
在host_vars中定义变量,以主机名称作为文件名,在其中进行变量的定义
在group_vars中定义变量,以主机组名称作为文件名,在其中定义变量
在文件中定义的变量的格式为yaml的格式
如果主机和主机组的变量发生冲突,主机的变量优先级更高
5. 注册变量
所谓的注册变量,指的是将一个任务的执行结果注册成为变量给到其他的任务来进行调用
- name: vars demo
hosts: node1
tasks:
- shell: touch /opt/ansible1.txt
register: get_file
- name: print debuginfo
debug:
msg: "{{ get_file.rc }}"
6. 通过命令行来定义变量
ansible-playbook test.yml -e hello=redhat
ansible node1 -m debug -a 'var=hello' --extra-vars hello=redhat
7. 收集facts的事实变量
所谓的事实变量,指的是ansible被控主机上的信息将其收集成为变量,通过一个setup的模块,以facts的方式将其作为变量;facts是setup模块的一个方法,专门用来收集被控主机的信息,我们将这种收集的被控端的信息称为facts变量(事实变量)
7.1 使用filter过滤facts的变量
filter在过滤时,只能过滤到ansible_facts的下一个层级,也就是ansible_开头的这一部分变量,除此以外其他的变量都不能过滤到
例如:
无法过滤 ansible node1 -m setup -a 'filter=ansible_ens160.ipv4.address'
可以过滤 ansible node1 -m setup -a 'filter=ansible_ens160'
7.2 使用通配符过滤facts的变量
ansible node1 -m setup -a 'filter=ansible_ens*' 可以在变量中未知的部分使用*号来进行通配
7.3 导出facts的变量到文件
ansible node1 -m setup --tree /tmp/facts 在导出文件中只有一行内容,不容易查看
ansible node1 -m setup > /tmp/node1.facts 重定向导出,以原有的格式存储到文件
7.4 facts变量的引用方式
facts的变量中,ansible_facts层级可以省略,因为所有的变量都注册在ansible_facts中,facts的下一个层级通过点来进行调用
例子:
取值ens160的网卡IP ansible_ens160.ipv4.address
7.5 禁止剧本收集facts变量
- hosts: node1
gather_facts: no 如果是yes /true则收集,默认为true;no/false则关闭
tasks:
- debug:
var: ansible_ens160.ipv4.address
7.5 自定义主机facts变量
实现每一台主机都有其不同的自定义facts变量
每一台主机的facts变量都存储在/etc/ansible/facts.d/ 目录下
文件可以是ini或者是yaml的格式,一般是ini,文件的后缀必须以fact结尾,自定义的facts变量都存储在ansible_local这个变量中,因此调用时需要使用ansible_local
案例: 自定义node1主机 facts变量
编写facts文件
vim test.facts
[dbserver]
name = mysql
conf = /etc/my.cnf
service = mysql.service
将文件传输到被控端的 /etc/ansible/facts.d目录下
通过剧本 定义两个任务
创建目录、copy文件
通过ansible facts 来测试是否生效
ansible node1 -m setup -a 'filter=ansible_local'
7.6 整合facts变量,将多个facts变量生成一个新的变量
通过set_fact模块将多个facts变量结合在一起进行调用
- hosts: node1
gather_facts: yes
tasks:
- name: define vars
set_fact:
get_rhel: "{{ ansible_distribution }}-{{ ansible_distribution_version }}" 其中get_rhel 就是定义的变量名,后面就是facts的变量
- debug:
var: get_rhel
8. 通过lookup插件来生成变量
lookup的插件有很多方式可以将外部的数据源作为变量,例如:文件、命令、环境变量……
使用文件的内容作为变量 “{{ lookup(‘file’,’文件的路径’) }}”
使用命令的结果作为变量 “{{ lookup(‘pipe’,’执行的命令’) }}”
使用环境变量值作为变量 “{{ lookup(‘env’,’环境变量’) }}”
lookup变量使用lookup(‘方法’,’内容’) 内容都是在主控节点上获取的
lookup获取的数据源都是在主控节点上获取的
9. ansible的魔法变量
所谓ansible的魔法变量,其实就是ansible的内置变量,只是这一些变量有特殊意义,我们将其称为魔法变量
hostvars 用来获取清单中指定主机的facts变量
"{{ hostvars['node1'].ansible_ens160.ipv4.address }}"
其中node1 只能是主机名,并且是清单中的名称,不能是IP地址,但是如果清单中只使用了IP地址,则可以将地址作为主机名
inventory_hostname 列出当前任务正在执行的主机
groups 列出清单中的所有主机组
groups.all 列出所有主机
groups.test 列出指定主机组的主机
group_names 列出当前运行任务的主机所在主机组
其他的魔法变量:
https://docs.ansible.com/ansible/latest/reference_appendices/special_variables.html#magic-variables
ansible的条件判断
ansible的判断应用场景:
- 在目标主机上定义了一个硬限制,比如目标主机的最小内存必须达到多少,才能执行该task
- 捕获一个命令的输出,根据命令输出结果的不同以触发不同的task
- 根据不同目标主机的facts,以定义不同的task
- 根据目标机的cpu的大小,以调优相关应用性能
- 用于判断某个服务的配置文件是否发生变更,以确定是否需要重启服务
1. 比较运算符
==:比较两个对象是否相等,相等则返回真。可用于比较字符串和数字
- !=:比较两个对象是否不等,不等则为真。
- >:比较两个对象的大小,左边的值大于右边的值,则为真
- <:比较两个对象的大小,左边的值小于右边的值,则为真
- >=:比较两个对象的大小,左边的值大于等于右边的值,则为真
- <=:比较两个对象的大小,左边的值小于等于右边的值,则为真
2. 逻辑运算符
- and:逻辑与,当左边和右边两个表达式同时为真,则返回真
- or:逻辑或,当左右和右边两个表达式任意一个为真,则返回真
- not:逻辑否/非,对表达式取反
- ():当一组表达式组合在一起,形成一个更大的表达式,组合内的所有表达式都是逻辑与的关系
例子:
逻辑与 when: ansible_hostname == 'node1' and ansible_distribution == "RedHat"
逻辑或 when: ansible_hostname == 'node1' or ansible_distribution == "RedHat"
逻辑非 when: not ansible_hostname == 'node1'
逻辑组合条件 when: (ansible_hostname == 'node1' and ansible_distribution == "RedHat") or (ansible_distribution_version == "9.0" and ansible_ens160.ipv4.address == "172.18.0.139")
3. 判断shell模块的任务是否执行成功
通过对shell任务的rc的值来判断任务是否执行成功
- hosts: node1
tasks:
- shell: ls -l /opt/hello.txt
register: get_file
ignore_errors: yes
- debug:
msg: "Tasks Ok"
when: get_file.rc == 0
- debug:
msg: "Tasks Failed"
when: get_file.rc != 0
4. 对路径进行判断
路径的所有判断,都是判断的主控端上的路径,不能判断被控端的路径
- file:判断指定路径是否为一个文件,是则为真
- directory:判断指定路径是否为一个目录,是则为真
- link:判断指定路径是否为一个软链接,是则为真
- mount:判断指定路径是否为一个挂载点,是则为真
- exists:判断指定路径是否存在,存在则为真
表达式为: when: 变量 is file/directory/link/mount/exists
when: "'/etc/hostname' is file"
- hosts: node1
gather_facts: yes
vars:
file_path: /etc/hostname
tasks:
- debug:
msg: hello ansible
when: file_path is file
5. 对任务的执行结果进行判断
- ok:目标状态与期望值一致,没有发生变更 à 任务执行成功
- change或changed:目标发生变更,与期望值一样
- sucess或succeeded:目标状态与期望值一致,或者任务执行成功
- failure或failed:任务执行失败
- skip或skipped:任务被跳过
注意: 是对任务的执行结果进行判断,是整个任务的状态而不是任务中命令的执行状态
6. 对变量的判断
- defined:判断变量是否已定义,已定义则返回真
- undefined:判断变量是否未定义,未定义则返回真
none:判断变量的值是否为空,如果变量已定义且值为空,则返回真;前提是变量要定义
例子:
- hosts: node1
gather_facts: yes
vars:
hello:
tasks:
- debug:
msg: hello ansible
when: hello is none 判断变量的值为空,前提是变量需要先定义
7. 对字符串进行判断
- lower:判断字符串中的所有字母是否都是小写,是则为真
- upper:判断字符串中的所有字母是否都是大写,是则为真
例子:
when: hello is upper
8. 判断整除
- even:判断数值是否为偶数,是则为真
- odd:判断数值是否为奇数,是则为真
- divisibleby(num):判断是否可以整除指定的数值,是则为真
- hosts: test
gather_facts: no
vars:
num1: 6
num2: 8
num3: 15
tasks:
- debug:
msg: "num1 is an even number"
when: num1 is even
- debug:
msg: "num2 is an odd number"
when: num2 is odd
- debug:
msg: "num3 can be divided exactly by"
when: num3 is divisibleby(3)
9. 判断集合
- subset 判断一个list是不是另一个list的子集:when: a is subset(b)
- superset 判断一个list是不是另一个list的父集:when: b is superset(a)
例子:
- hosts: node1
gather_facts: yes
vars:
os_list:
- centos
- rhel
- openeuler
- fedora
test_list:
- centos
- rhel
tasks:
- debug:
msg: hello ansible
when: test_list is subset(os_list) 判断test_list 是不是os_list的子集
when: os_list is superset(test_list) 判断os_list是不是test_list的父集
10. 判断关键字是否出现在列表或者字符串中
in 判断一个字符串是否存在于另一个字符串中,也可用于判断某个特定的值是否存在于列表中
- hosts: node1
gather_facts: yes
vars:
os_list:
- centos
- RedHat
- openeuler
- fedora
tasks:
- debug:
msg: hello ansible
when: ansible_distribution in os_list
when: “’字符串’ in 变量” 直接判断字符串是否在一个变量之中
11. 判断对象是否是一个数字或者是字符串
- string 判断对象是否为一个字符串,是则为真 when: var1 is string
- number 判断对象是否为一个数字,是则为真 when: var3 is number
- hosts: node1
gather_facts: yes
vars:
RHCE9: ansible10.0
RHCE8: 2.9
tasks:
- debug:
msg: str
when: RHCE9 is string
- debug:
msg: num
when: RHCE8 is number
12. 对多个任务使用同一个条件判断
通过block关键字使用同一个条件对多个任务进行判断,也就是使用when来判断block,如果block中的条件成立,则block中的所有任务都会执行,如果条件不成立,则任务不会执行
- hosts: node1
gather_facts: yes
vars:
RHCE9: ansible10.0
RHCE8: 2.9
tasks:
- block:
- debug:
msg: hello1
- debug:
msg: hello2
- debug:
msg: hello3
- debug:
msg: hello4
when: ansible_distribution == "RedHat"
12.1 使用rescue修复 block中的报错
也就是如果block中的任务出错,则触发rescue,rescue也是一组特殊的任务,只有当block报错,其中的任务才会执行
12.2 通过always来执行必须执行的任务
也就是不管block中的任务是否出错,都执行always,其也是特殊的任务列表
- hosts: node1
gather_facts: yes
tasks:
- block:
- debug:
msg: hello1
- shell: ls -l /opt/key00000.txt
- debug:
msg: hello3
- debug:
msg: hello4
rescue:
- debug:
msg: file not
always:
- debug:
msg: "hello always"
when: ansible_distribution == "RedHat"
13. fail模块帮助剧本在特定条件下终止执行
- hosts: node1
gather_facts: yes
vars:
RHCE9: ansible10.0
RHCE8: 2.9
tasks:
- debug:
msg: hello1
- shell: ls -l /opt/key00000.txt
register: get_status
ignore_errors: yes
- fail:
msg: "playbook exit"
when: get_status.rc != 0 如果shell的任务执行失败,则终止剧本执行
- debug:
msg: hello3
除了使用fail模块来终止剧本的执行,也可以使用failed_when,将判断和fail结合在一起,只要达到条件立即退出剧本
- hosts: node1
gather_facts: yes
vars:
RHCE9: ansible10.0
RHCE8: 2.9
tasks:
- debug:
msg: hello1
- shell: ls -l /opt/key0000aaa.txt
register: get_status
ignore_errors: yes
- debug:
msg: hello3
failed_when: get_status is failed
- debug:
msg: hello4
Ansible的循环语句
1. 基于列表的循环
with_items 循环列表
表现形式:
形式一:
- hosts: node1
vars:
pkgs:
- vsftpd
- cifs-utils
- samba
- mariadb
tasks:
- name: install pkgs
yum:
name: "{{ item }}"
state: present
with_items: "{{ pkgs }}"
形式二:
- hosts: node1
vars:
tasks:
- name: install pkgs
yum:
name: "{{ item }}"
state: present
with_items:
- vsftpd
- cifs-utils
- samba
- mariadb
形式三: 不常用
- hosts: node1
vars:
tasks:
- name: install pkgs
yum:
name: "{{ item }}"
state: present
with_items: ["vsftpd","cifs-utils","samba","mariadb"]
比较特殊的列表:
- hosts: node1
vars:
users:
- name: bob
uid: 2000
comment: "dev user"
- name: alice
uid: 3000
comment: "oc user"
tasks:
- name: create user
user:
name: "{{ item.name }}"
uid: "{{ item.uid }}"
comment: "{{ item.comment }}"
state: present
with_items: "{{ users }}"
基于字典的循环:
with_dict 进行字典的结构循环
- hosts: node1
vars:
users:
dev:
name: bob
uid: 2000
oc:
name: alice
uid: 3000
tasks:
- name: create user
user:
name: "{{ item.value.name }}" 如果不知道取值,使用debug进行输出查看
uid: "{{ item.value.uid }}"
state: present
with_dict: "{{ users }}"
统一的循环语句:
从ansible2.6 开始使用loop进行循环,不再需要with的各种前缀关键字,但是部分with依然保留使用;注意loop本身只能循环列表,可以通过过滤器来对字典进行循环
loop 直接循环列表
loop {{ 变量|dict2items }} 使用dict2items 过滤器进行循环字典结构
过滤器在ansible中,专门用来对数据或者是变量进行处理,过滤器的种类非常多,如果需要查看较为全面的过滤器可以看python中jinja2的文档
- hosts: node1
vars:
users:
dev:
name: bob
uid: 2000
oc:
name: alice
uid: 3000
tasks:
- name: create user
user:
name: "{{ item.value.name }}"
uid: "{{ item.value.uid }}"
state: present
loop: "{{ users|dict2items }}"
常用到的过滤器:
dict2items 将字典转化成列表
password_hash(‘sha512’) 将数据使用sha512 进行加密,通常用在用户的密码上
default(‘值’) 如果变量不存在,则给变量赋予默认的值
修改配置文件
单行修改:lineinfile模块
path:要修改的文件
regexp:正则表达式匹配要修改的行
line:修改或者插入行的内容
insertbefore:在匹配的行前面插入
insertafter:在匹配的行后面插入
backup:是否备份文件
create:文件不存在则创建文件
backrefs: 默认值为 no,如果该项为yes,则不匹配关键字时,不在文件的末尾追加内容,默认找不到关键字则在文件末尾追加内容
validate:验证文件修改的有效性,需要文件自带验证机制;ansible本身不能校验配置文件的,主要靠服务自身携带的校验机制,例如httpd -t 、visudo 这样的校验方式,如果需要校验使用%s 来通配path的路径,eg /usr/sbin/httpd -tf %s 校验apache的配置文件
多行增加:blockinfile 模块
除了使用lineinfile的参数外,还支持如下参数:
block:要插入的文本内容
marker:指定块标记,"# {mark} ANSIBLE MANAGED BLOCK"
通过将lineinfile和blockinfile 结合起来删除文件中的段落:
- hosts: node1
tasks:
- lineinfile:
path: /opt/passwd
insertbefore: "^root"
line: "A BEGIN blockinfile test"
- lineinfile:
path: /opt/passwd
insertafter: "^adm"
line: "A END blockinfile test"
- blockinfile:
path: /opt/passwd
state: absent
marker: "A {mark} blockinfile test"
生成通用配置文件模板
Jinja2是基于python的模板引擎,那么什么是模板?
在服务器的批量管理中,如果需要对某个服务进行批量配置,例如:在10台主机上安装apache,每一个apache的web服务都需要监听本机的IP地址,那就会出现我们要对每一台机器都需要修改配置文件,如果机器的数量多,修改的配置项多,效率就会低下;但是在这些配置文件中,除了要修改的少部分配置以外,绝大部分的配置;每台机器都是相同的;因此需要一个通用解决方案,来解决配置文件的分发问题,也就是每台机器都可以差异化配置文件
template模块: template 将配置文件中的变量,复制到被控端时,会将配置文件中的变量渲染成具体的值,它与copy模块的参数相同;但是可以将变量渲染成具体的值;因此我们将template拷贝的配置文件称为通用模板,该模板使用j2结尾,表示其是一个jinja2的模板文件
jinja2中进行判断:
{% if 表达式 %} 表达式和when中的条件一致
执行语句
{% elif 表达式%}
执行语句
{% else %}
执行语句
{% endif %}
例子:
{% if ansible_hostname == 'node1' %}
hello node1
{% elif ansible_hostname == 'node2' %}
hello node2
{% else %}
hello master
{% endif %}
jinja2中的循环:
{% for 变量 in 循环的对象 %}
循环体结构
{% endfor %}
复杂的循环例子:在 node1上生成ansible中所有主机的ip和主机名的映射清单文件,文件名为/opt/get_hosts.txt;文件每一行应该包含受管主机的IP地址,完全限定的域名以及主机名,格式如下:
172.18.0.136 node1.example.com node1
172.18.0.139 node2.example.com node2
172.18.0.135 host1.sina.com host1
template的模板: hosts.j2
{% for host in groups.all %}
{{ hostvars[host].ansible_ens160.ipv4.address }} {{ hostvars[host].ansible_fqdn }} {{ hostvars[host].ansible_hostname }}
{% endfor %}
playbook的剧本: hosts.yml
- hosts: all
tasks:
- hosts: node1
tasks:
- template:
src: hosts.j2
dest: /opt/get_hosts.txt
roles角色管理
roles的作用就是为了更好的移植项目(playbook);如果在大型项目中,例如openstack的部署,ceph的部署等项目中,可能会有很多的任务,以及外部依赖的文件;还有各种需要拷贝的模板,如果仅仅只是将playbook复制给其他人进行使用,其他人因为缺少文件或者是模板将导致playbook执行失败,那么roles的引入就是为了将一个项目的playbook 以及该项目用到文件、模板、外部的变量等打包成一个文件,我们将这个文件称为roles角色
直接在角色中对项目进行开发:
ansible 2.9 以前 使用的是角色——> r roles ==>oles 包含playbook、文件(模板、普通文件)、变量….
ansible 2.9 以后 使用的是集合 ——> collection ==> 包含 模块、插件、角色
ansible 将不再和 模块同步更新;也就是模块可以更新的更快
将ansible以容器的方式提供给用户进行使用,可以通过安装集合来获得指定的模块
角色的组成:
files:用于存放一些非模板文件的文件,如https证书等。
tempaltes:用于存放角色相关的Jinja2模板文件,当使用角色相关的模板时,如未明确指定模板路径,则默认使用此目录中的模板
tasks:角色所要执行的所有任务文件都存放于此,包含一个主文件main.yml,可以在主文件中通过include的方式引入其他任务文件
handlers:用于定义角色中需要调用 的handlers,包含一个主配置文件main.yml,可通过include引入其他的handlers文件。
vars:用于定义此角色用到的变量,包含一个主文件main.yml
meta:用于存储角色的元数据信息,这些元数据用于描述角色的相关属性,包括作者,角色的主要作用,角色的依赖关系等。默认这些信息会写入到当前目录下的main.yml文件中
defaults:除了vars目录,defaults目录也用于定义此角色用到的变量,与vars不同的是,defaults中定义的变量的优先级最低。
创建角色的步骤:
1. 在roles的目录中创建一个以角色名,命名的目录(目录的名字就是角色的名称)
2. 在创建的目录下,创建所需的角色配置的子目录,如tasks、file、defaults、templates… 不需要的角色配置目录,可以不创建或者保留空白目录
3. 编写playbook来调用这个角色
拆分角色中的任务:
通过include_tasks 来对tasks目录中的任务进行拆分
在tasks目录中的main.yml中使用
include_tasks:
file: 拆分的任务文件 进行引入任务
在playbook中有两类特殊的任务:
pre_tasks 中的任务在执行角色之前执行
post_tasks 中的任务在执行角色之后执行
- hosts: node1
pre_tasks:
- debug:
msg: " start roles"
roles:
- apache
post_tasks:
- debug:
msg: "end roles"
获得角色的方式:
1.通过ansible的仓库来进行获取 ansible-galaxy
galaxy.ansible.com 来搜索下载角色
ansible-galaxy search role-name 搜索角色
ansible-galaxy role install role-name 安装角色
ansible-galaxy list 查看角色
ansible-galaxy init role-name 创建一个角色目录结构
ansible-galaxy role install url的地址 -p 角色存放的目录 离线进行安装
ansible-galaxy role install -r download.yml -p roles
-r 表示后面接yml文件
-p 角色的存放的目录
download.yml
- name: 角色名(此处写什么角色名,安装后角色就叫这名称)
src: url的地址
ansible-galaxy remove role-name 删除角色
ansible-galaxy info role-name 查看角色的详细信息
2. 红帽提供了RHEL的系统管理角色包
selinux、时间同步、postfix、firewalld …
可以通过使用红帽的role角色来管理系统
yum install rhel-system-roles -y
Ansible Vault 加解密
1. 创建一个加密文件
ansible-vault create file.yml
2. 查看一个加密文件
ansible-vault view file.yml
3. 解密一个加密文件
ansible-vault decrypt file.yml
4.加密一个存在的文件
ansible-vault encrypt file.yml
5.修改加密文件的密码
ansible-vault rekey file.yml
6. 运行带有加密内容的剧本
6.1 在运行playbook时通过命令行指定密码
ansible-playbook file.yml --ask-vault-pass
6.2 在运行playbook时 通过文件读取密码
ansible-playbook file.yml --vault-password-file pass.txt
cat pass.txt 将密码写入到pass.txt文件中,通过文件传递密码给playbook
redhat
Ansible的导航器:
使用容器来运行ansible的playbook,用容器运行playbook的优势在于可以摆脱对物理机上ansible版本的依赖
ansible的导航器只能用来运行playbook 而不能运行ad-hoc
ansible-navigator run -i 主机清单的位置 file.yml -m stdout
run 用来运行playbook
-i 指定主机清单的位置
-m 指定输出的模式 ,可视化模式(在容器中以可视化的形式显示)
字符模式 -m stdout 就是字符模式
ansible的自动化执行环境:
vim ~/.ansible- navigator.yml
ansible-navigator:
execution-environment:
image: registry.redhat.io/ansible-automation-platform-22/ee-supported-rhel8
pull:
policy: missing















 646
646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









