






前言
翻译和记录CS224N课程的答案,原文来源于:https://github.com/amanchadha/stanford-cs224n-assignments-2021/blob/main/a1/CS224nAssignment1.pdf
课程官网:https://web.stanford.edu/class/cs224n/index.html
b站链接:https://www.bilibili.com/video/BV1Nf4y1K7kU?p=1&vd_source=d5d89e6f0cdebce7b6bcd6aa0f5978a3
因为是斯坦福的NLP公开课,所以本文一些链接需要科学上网。
探索词向量
2021年1月19日
1 CS224N 作业1:探索词向量(25分)
1.0.1 截止日期:1月19日周二下午4:30
欢迎来到CS224N!
在开始之前,请确保阅读与本笔记本相同目录下的README.txt,以获取重要的设置信息。在这个笔记本中提供了很多代码,我们强烈建议你阅读并理解它,作为学习的一部分:)
如果你对Python,Numpy,或者Matplotlib还不是很熟练,我们建议你看一下星期五的复习课。该课程将被记录下来并与材料一起放在我们的网站上。CS231N Python/Numpy教程也是一个很好的资源。
作业笔记:请务必保存好该笔记本。提交说明放在笔记本的底部。
# All Import Statements Defined Here
# Note: Do not add to this list.
# ----------------
import sys
assert sys.version_info[0]==3
assert sys.version_info[1] >= 5
from gensim.models import KeyedVectors
from gensim.test.utils import datapath
import pprint
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = [10, 5]
import nltk
nltk.download('reuters')
from nltk.corpus import reuters
import numpy as np
import random
import scipy as sp
from sklearn.decomposition import TruncatedSVD
from sklearn.decomposition import PCA
START_TOKEN = '<START>'
ND_TOKEN = '<END>'
np.random.seed(0)
random.seed(0)
# ----------------
[nltk_data] Downloading package reuters to /Users/Aman/nltk_data...
[nltk_data] Package reuters is already up-to-date!
1.1 词向量
词向量通常被用作下游NLP任务的基本组成部分,例如问题回答,文本生成,翻译等,所以建立一些关于他们的优点和缺点的直觉是很重要的。在这里,你将会探索到两种类型的词向量:从共现矩阵派生的词向量和通过GloVe派生的词向量。
关于术语的注意事项:术语“词向量”和“词嵌入”经常可以互换使用。术语“embedding”指的是我们在一个更低维度的空间中对一个词的含义进行编码。维基百科称,“从概念上讲,它涉及到从每个单词有一个维度的空间到一个维数低得多的连续向量空间的数学嵌入”。
1.2 第一部分:基于计数的单词向量(10分)
大多数词向量模型都是从以下的观点出发:
你可以从与它所一起出现的其他词来认识一个词(Firth, J. R. 1957:11)
许多词向量实现都是基于这样一种想法,即相似的词,即(接近)同义词,将在相似的上下文中使用。因此,相似的单词通常会在口语或书面语中出现一个共享的单词子集,也就是上下文(context)。通过检查这些上下文,我们可以尝试为我们的词汇建立嵌入。带着这种直觉,许多“老派”的做法依赖于词数去构建词向量。这里我们详细阐述其中一种策略,即同现矩阵(有关更多信息,请参阅此处或此处)。
1.2.1 共现
共现矩阵计算单词在某些语境中共现的频率。给定文档中出现的一个单词 w i w_i wi,我们考虑 w i w_i wi周围的上下文窗口。假设我们的固定窗口大小为n,那么这是该文档中前n个单词和后n个单词,即单词 w i − n … w i − 1 , w i + 1 … w i + n w_{i-n}…w_{i−1},w_{i +1}…w_{i + n} wi−n…wi−1,wi+1…wi+n。我们建立这样一个共现矩阵 M M M,它是一个对称的逐字矩阵,其中 M i j M_{ij} Mij是 w j w_j wj在所有文档中出现在 w i w_i wi窗口内的次数。
示例:与 n = 1 n=1 n=1的固定窗口共现:
文档1:“all that glitters is not gold”
文档2: “all is well that ends well”
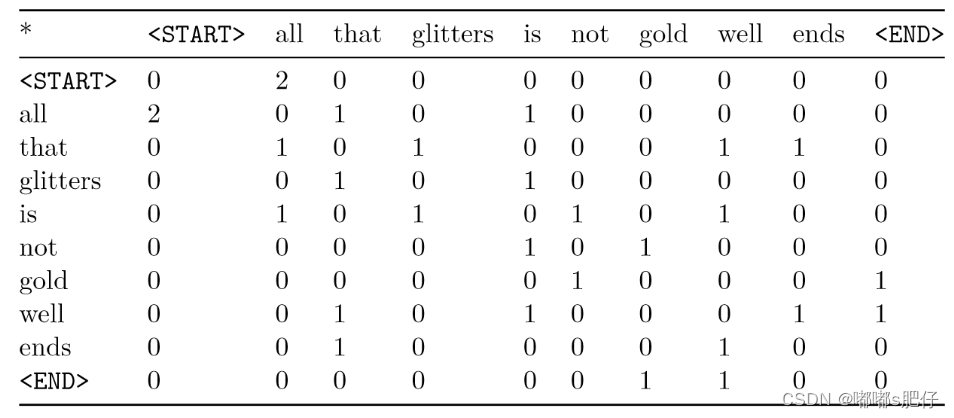
注意:在NLP中,我们经常添加<START>和<END>标记来表示句子、段落或文档的开始和结束。在这种情况下,我们想象<START>和<END>标记封装每个文档,例如,“<START> All that glitters is not gold <END>”,并将这些标记包含在我们的共现矩阵中。
这个矩阵的行(或列)提供了一种类型的单词向量(那些基于单词-单词共现的向量),但向量通常很大(语料库中不同单词的数量呈线性)。因此,我们的下一步是进行降维。特别是,我们将运行SVD(奇异值分解),它是一种广义主成分分析(PCA, Principal Components Anal- ysis)来选择最上面的k个主成分。下图是SVD进行降维的可视化。在这个图中,共现矩阵是 A A A,其中n行对应 n n n个单词。我们得到了一个完整的矩阵分解,其中奇异值在对角矩阵 S S S中排序,以及 U k U_k Uk中新的、长度较短的 k k k个词向量。
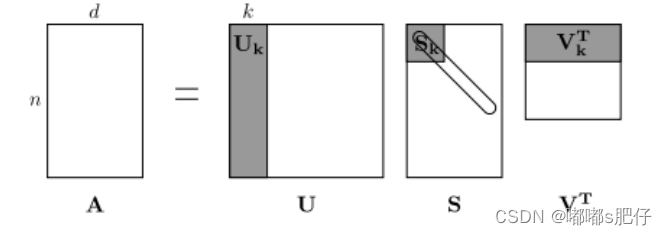
这种降维共现的表示保留了单词之间的语义关系,例如,doctor和hospital会比doctor和dog更接近。
注意:如果你不太记得特征值是什么,这里有一个对SVD缓慢而友好的介绍。如果您想更彻底地了解PCA或SVD,请随时查看课程CS168的7,8,9。这些课程笔记提供了这些通用算法的高级处理。不过,因为本课程的开课目的(偏向实践),您只需要知道如何利用numpy、scipy或sklearn python包中预先编程的算法实现来提取k维嵌入。在实践中,想要将完整的SVD应用于大型语料库是比较困难的,因为电脑程序执行PCA或SVD需要大量内存。如果您只想要相对较小的k的最上面的k个向量——被称为截断SVD——那么有一些合理的可伸缩技术来迭代计算这些向量。
1.2.2 共现词嵌入的可视化
在这里,我们将使用路透社(商业和金融新闻)语料库。如果你还没有运行这个页面顶部的导入单元格,请现在运行它(点击它并同时按SHIFT-RETURN)。该语料库包含10788份新闻文档,共130万字。这些文档跨越90个类别,分为训练集和测试集。更多详情请参见https://www.nltk.org/book/ch02.html。
我们在下面提供了一个read_corpus函数,它只从“原油”类别中提取文章(即关于石油、天然气等的新闻文章)。该功能还添加了对每个文档还添加了 <START>和 <END>标记和小写单词。您不需要执行任何其他类型的预处理。
def read_corpus(category="crude"):
""" Read files from the specified Reuter's category.
Params:
category (string): category name
Return:
list of lists, with words from each of the processed files
"""
files = reuters.fileids(category)
return [[START_TOKEN] + [w.lower() for w in list(reuters.words(f))] +␣
↪→[END_TOKEN] for f in files]
让我们看看这些文档长什么样
reuters_corpus = read_corpus()
pprint.pprint(reuters_corpus[:3], compact=True, width=100)
[['<START>', 'japan', 'to', 'revise', 'long', '-', 'term', 'energy', 'demand',
'downwards', 'the',
'ministry', 'of', 'international', 'trade', 'and', 'industry', '(', 'miti',
')', 'will', 'revise',
'its', 'long', '-', 'term', 'energy', 'supply', '/', 'demand', 'outlook',
'by', 'august', 'to',
'meet', 'a', 'forecast', 'downtrend', 'in', 'japanese', 'energy', 'demand',
',', 'ministry',
'officials', 'said', '.', 'miti', 'is', 'expected', 'to', 'lower', 'the',
'projection', 'for',
'primary', 'energy', 'supplies', 'in', 'the', 'year', '2000', 'to', '550',
'mln', 'kilolitres',
'(', 'kl', ')', 'from', '600', 'mln', ',', 'they', 'said', '.', 'the',
'decision', 'follows',
'the', 'emergence', 'of', 'structural', 'changes', 'in', 'japanese',
'industry', 'following',
'the', 'rise', 'in', 'the', 'value', 'of', 'the', 'yen', 'and', 'a',
'decline', 'in', 'domestic',
'electric', 'power', 'demand', '.', 'miti', 'is', 'planning', 'to', 'work','out', 'a', 'revised',
'energy', 'supply', '/', 'demand', 'outlook', 'through', 'deliberations',
'of', 'committee',
'meetings', 'of', 'the', 'agency', 'of', 'natural', 'resources', 'and',
'energy', ',', 'the',
'officials', 'said', '.', 'they', 'said', 'miti', 'will', 'also', 'review',
'the', 'breakdown',
'of', 'energy', 'supply', 'sources', ',', 'including', 'oil', ',', 'nuclear',
',', 'coal', 'and',
'natural', 'gas', '.', 'nuclear', 'energy', 'provided', 'the', 'bulk', 'of',
'japan', "'", 's',
'electric', 'power', 'in', 'the', 'fiscal', 'year', 'ended', 'march', '31',
',', 'supplying',
'an', 'estimated', '27', 'pct', 'on', 'a', 'kilowatt', '/', 'hour', 'basis',
',', 'followed',
'by', 'oil', '(', '23', 'pct', ')', 'and', 'liquefied', 'natural', 'gas', '(',
'21', 'pct', '),',
'they', 'noted', '.', '<END>'],
['<START>', 'energy', '/', 'u', '.', 's', '.', 'petrochemical', 'industry',
'cheap', 'oil',
'feedstocks', ',', 'the', 'weakened', 'u', '.', 's', '.', 'dollar', 'and',
'a', 'plant',
'utilization', 'rate', 'approaching', '90', 'pct', 'will', 'propel', 'the',
'streamlined', 'u',
'.', 's', '.', 'petrochemical', 'industry', 'to', 'record', 'profits', 'this',
'year', ',',
'with', 'growth', 'expected', 'through', 'at', 'least', '1990', ',', 'major',
'company',
'executives', 'predicted', '.', 'this', 'bullish', 'outlook', 'for',
'chemical', 'manufacturing',
'and', 'an', 'industrywide', 'move', 'to', 'shed', 'unrelated', 'businesses',
'has', 'prompted',
'gaf', 'corp', '&', 'lt', ';', 'gaf', '>,', 'privately', '-', 'held', 'cain',
'chemical', 'inc',
',', 'and', 'other', 'firms', 'to', 'aggressively', 'seek', 'acquisitions',
'of', 'petrochemical',
'plants', '.', 'oil', 'companies', 'such', 'as', 'ashland', 'oil', 'inc', '&',
'lt', ';', 'ash',
'>,', 'the', 'kentucky', '-', 'based', 'oil', 'refiner', 'and', 'marketer',
',', 'are', 'also',
'shopping', 'for', 'money', '-', 'making', 'petrochemical', 'businesses',
'to', 'buy', '.', '"',
'i', 'see', 'us', 'poised', 'at', 'the', 'threshold', 'of', 'a', 'golden',
'period', ',"', 'said',
'paul', 'oreffice', ',', 'chairman', 'of', 'giant', 'dow', 'chemical', 'co',
'&', 'lt', ';',
'dow', '>,', 'adding', ',', '"', 'there', "'", 's', 'no', 'major', 'plant',
'capacity', 'being','added', 'around', 'the', 'world', 'now', '.', 'the', 'whole', 'game', 'is',
'bringing', 'out',
'new', 'products', 'and', 'improving', 'the', 'old', 'ones', '."', 'analysts',
'say', 'the',
'chemical', 'industry', "'", 's', 'biggest', 'customers', ',', 'automobile',
'manufacturers',
'and', 'home', 'builders', 'that', 'use', 'a', 'lot', 'of', 'paints', 'and',
'plastics', ',',
'are', 'expected', 'to', 'buy', 'quantities', 'this', 'year', '.', 'u', '.',
's', '.',
'petrochemical', 'plants', 'are', 'currently', 'operating', 'at', 'about',
'90', 'pct',
'capacity', ',', 'reflecting', 'tighter', 'supply', 'that', 'could', 'hike',
'product', 'prices',
'by', '30', 'to', '40', 'pct', 'this', 'year', ',', 'said', 'john', 'dosher',
',', 'managing',
'director', 'of', 'pace', 'consultants', 'inc', 'of', 'houston', '.',
'demand', 'for', 'some',
'products', 'such', 'as', 'styrene', 'could', 'push', 'profit', 'margins',
'up', 'by', 'as',
'much', 'as', '300', 'pct', ',', 'he', 'said', '.', 'oreffice', ',',
'speaking', 'at', 'a',
'meeting', 'of', 'chemical', 'engineers', 'in', 'houston', ',', 'said', 'dow',
'would', 'easily',
'top', 'the', '741', 'mln', 'dlrs', 'it', 'earned', 'last', 'year', 'and',
'predicted', 'it',
'would', 'have', 'the', 'best', 'year', 'in', 'its', 'history', '.', 'in',
'1985', ',', 'when',
'oil', 'prices', 'were', 'still', 'above', '25', 'dlrs', 'a', 'barrel', 'and',
'chemical',
'exports', 'were', 'adversely', 'affected', 'by', 'the', 'strong', 'u', '.',
's', '.', 'dollar',
',', 'dow', 'had', 'profits', 'of', '58', 'mln', 'dlrs', '.', '"', 'i',
'believe', 'the',
'entire', 'chemical', 'industry', 'is', 'headed', 'for', 'a', 'record',
'year', 'or', 'close',
'to', 'it', ',"', 'oreffice', 'said', '.', 'gaf', 'chairman', 'samuel',
'heyman', 'estimated',
'that', 'the', 'u', '.', 's', '.', 'chemical', 'industry', 'would', 'report',
'a', '20', 'pct',
'gain', 'in', 'profits', 'during', '1987', '.', 'last', 'year', ',', 'the',
'domestic',
'industry', 'earned', 'a', 'total', 'of', '13', 'billion', 'dlrs', ',', 'a',
'54', 'pct', 'leap',
'from', '1985', '.', 'the', 'turn', 'in', 'the', 'fortunes', 'of', 'the',
'once', '-', 'sickly',
'chemical', 'industry', 'has', 'been', 'brought', 'about', 'by', 'a',
'combination', 'of', 'luck','and', 'planning', ',', 'said', 'pace', "'", 's', 'john', 'dosher', '.',
'dosher', 'said', 'last',
'year', "'", 's', 'fall', 'in', 'oil', 'prices', 'made', 'feedstocks',
'dramatically', 'cheaper',
'and', 'at', 'the', 'same', 'time', 'the', 'american', 'dollar', 'was',
'weakening', 'against',
'foreign', 'currencies', '.', 'that', 'helped', 'boost', 'u', '.', 's', '.',
'chemical',
'exports', '.', 'also', 'helping', 'to', 'bring', 'supply', 'and', 'demand',
'into', 'balance',
'has', 'been', 'the', 'gradual', 'market', 'absorption', 'of', 'the', 'extra',
'chemical',
'manufacturing', 'capacity', 'created', 'by', 'middle', 'eastern', 'oil',
'producers', 'in',
'the', 'early', '1980s', '.', 'finally', ',', 'virtually', 'all', 'major',
'u', '.', 's', '.',
'chemical', 'manufacturers', 'have', 'embarked', 'on', 'an', 'extensive',
'corporate',
'restructuring', 'program', 'to', 'mothball', 'inefficient', 'plants', ',',
'trim', 'the',
'payroll', 'and', 'eliminate', 'unrelated', 'businesses', '.', 'the',
'restructuring', 'touched',
'off', 'a', 'flurry', 'of', 'friendly', 'and', 'hostile', 'takeover',
'attempts', '.', 'gaf', ',',
'which', 'made', 'an', 'unsuccessful', 'attempt', 'in', '1985', 'to',
'acquire', 'union',
'carbide', 'corp', '&', 'lt', ';', 'uk', '>,', 'recently', 'offered', 'three',
'billion', 'dlrs',
'for', 'borg', 'warner', 'corp', '&', 'lt', ';', 'bor', '>,', 'a', 'chicago',
'manufacturer',
'of', 'plastics', 'and', 'chemicals', '.', 'another', 'industry',
'powerhouse', ',', 'w', '.',
'r', '.', 'grace', '&', 'lt', ';', 'gra', '>', 'has', 'divested', 'its',
'retailing', ',',
'restaurant', 'and', 'fertilizer', 'businesses', 'to', 'raise', 'cash', 'for',
'chemical',
'acquisitions', '.', 'but', 'some', 'experts', 'worry', 'that', 'the',
'chemical', 'industry',
'may', 'be', 'headed', 'for', 'trouble', 'if', 'companies', 'continue',
'turning', 'their',
'back', 'on', 'the', 'manufacturing', 'of', 'staple', 'petrochemical',
'commodities', ',', 'such',
'as', 'ethylene', ',', 'in', 'favor', 'of', 'more', 'profitable', 'specialty',
'chemicals',
'that', 'are', 'custom', '-', 'designed', 'for', 'a', 'small', 'group', 'of',
'buyers', '.', '"',
'companies', 'like', 'dupont', '&', 'lt', ';', 'dd', '>', 'and', 'monsanto',
'co', '&', 'lt', ';','mtc', '>', 'spent', 'the', 'past', 'two', 'or', 'three', 'years', 'trying',
'to', 'get', 'out',
'of', 'the', 'commodity', 'chemical', 'business', 'in', 'reaction', 'to',
'how', 'badly', 'the',
'market', 'had', 'deteriorated', ',"', 'dosher', 'said', '.', '"', 'but', 'i',
'think', 'they',
'will', 'eventually', 'kill', 'the', 'margins', 'on', 'the', 'profitable',
'chemicals', 'in',
'the', 'niche', 'market', '."', 'some', 'top', 'chemical', 'executives',
'share', 'the',
'concern', '.', '"', 'the', 'challenge', 'for', 'our', 'industry', 'is', 'to',
'keep', 'from',
'getting', 'carried', 'away', 'and', 'repeating', 'past', 'mistakes', ',"',
'gaf', "'", 's',
'heyman', 'cautioned', '.', '"', 'the', 'shift', 'from', 'commodity',
'chemicals', 'may', 'be',
'ill', '-', 'advised', '.', 'specialty', 'businesses', 'do', 'not', 'stay',
'special', 'long',
'."', 'houston', '-', 'based', 'cain', 'chemical', ',', 'created', 'this',
'month', 'by', 'the',
'sterling', 'investment', 'banking', 'group', ',', 'believes', 'it', 'can',
'generate', '700',
'mln', 'dlrs', 'in', 'annual', 'sales', 'by', 'bucking', 'the', 'industry',
'trend', '.',
'chairman', 'gordon', 'cain', ',', 'who', 'previously', 'led', 'a',
'leveraged', 'buyout', 'of',
'dupont', "'", 's', 'conoco', 'inc', "'", 's', 'chemical', 'business', ',',
'has', 'spent', '1',
'.', '1', 'billion', 'dlrs', 'since', 'january', 'to', 'buy', 'seven',
'petrochemical', 'plants',
'along', 'the', 'texas', 'gulf', 'coast', '.', 'the', 'plants', 'produce',
'only', 'basic',
'commodity', 'petrochemicals', 'that', 'are', 'the', 'building', 'blocks',
'of', 'specialty',
'products', '.', '"', 'this', 'kind', 'of', 'commodity', 'chemical',
'business', 'will', 'never',
'be', 'a', 'glamorous', ',', 'high', '-', 'margin', 'business', ',"', 'cain',
'said', ',',
'adding', 'that', 'demand', 'is', 'expected', 'to', 'grow', 'by', 'about',
'three', 'pct',
'annually', '.', 'garo', 'armen', ',', 'an', 'analyst', 'with', 'dean',
'witter', 'reynolds', ',',
'said', 'chemical', 'makers', 'have', 'also', 'benefitted', 'by',
'increasing', 'demand', 'for',
'plastics', 'as', 'prices', 'become', 'more', 'competitive', 'with',
'aluminum', ',', 'wood',
'and', 'steel', 'products', '.', 'armen', 'estimated', 'the', 'upturn', 'in',
'the', 'chemical','business', 'could', 'last', 'as', 'long', 'as', 'four', 'or', 'five',
'years', ',', 'provided',
'the', 'u', '.', 's', '.', 'economy', 'continues', 'its', 'modest', 'rate',
'of', 'growth', '.',
'<END>'],
['<START>', 'turkey', 'calls', 'for', 'dialogue', 'to', 'solve', 'dispute',
'turkey', 'said',
'today', 'its', 'disputes', 'with', 'greece', ',', 'including', 'rights',
'on', 'the',
'continental', 'shelf', 'in', 'the', 'aegean', 'sea', ',', 'should', 'be',
'solved', 'through',
'negotiations', '.', 'a', 'foreign', 'ministry', 'statement', 'said', 'the',
'latest', 'crisis',
'between', 'the', 'two', 'nato', 'members', 'stemmed', 'from', 'the',
'continental', 'shelf',
'dispute', 'and', 'an', 'agreement', 'on', 'this', 'issue', 'would', 'effect',
'the', 'security',
',', 'economy', 'and', 'other', 'rights', 'of', 'both', 'countries', '.', '"',
'as', 'the',
'issue', 'is', 'basicly', 'political', ',', 'a', 'solution', 'can', 'only',
'be', 'found', 'by',
'bilateral', 'negotiations', ',"', 'the', 'statement', 'said', '.', 'greece',
'has', 'repeatedly',
'said', 'the', 'issue', 'was', 'legal', 'and', 'could', 'be', 'solved', 'at',
'the',
'international', 'court', 'of', 'justice', '.', 'the', 'two', 'countries',
'approached', 'armed',
'confrontation', 'last', 'month', 'after', 'greece', 'announced', 'it',
'planned', 'oil',
'exploration', 'work', 'in', 'the', 'aegean', 'and', 'turkey', 'said', 'it',
'would', 'also',
'search', 'for', 'oil', '.', 'a', 'face', '-', 'off', 'was', 'averted',
'when', 'turkey',
'confined', 'its', 'research', 'to', 'territorrial', 'waters', '.', '"',
'the', 'latest',
'crises', 'created', 'an', 'historic', 'opportunity', 'to', 'solve', 'the',
'disputes', 'between',
'the', 'two', 'countries', ',"', 'the', 'foreign', 'ministry', 'statement',
'said', '.', 'turkey',
"'", 's', 'ambassador', 'in', 'athens', ',', 'nazmi', 'akiman', ',', 'was',
'due', 'to', 'meet',
'prime', 'minister', 'andreas', 'papandreou', 'today', 'for', 'the', 'greek',
'reply', 'to', 'a',
'message', 'sent', 'last', 'week', 'by', 'turkish', 'prime', 'minister',
'turgut', 'ozal', '.',
'the', 'contents', 'of', 'the', 'message', 'were', 'not', 'disclosed', '.',
'<END>']]
1.2.3 问题1.1:实现distinct_words[code](2分)
编写一个方法来找出语料库中出现的不同单词(单词类型)。您可以使用for循环来实现这一点,但使用Python列表推导式更有效。特别地,这对于想要扁平列表可能是有用的。如果你不熟悉Python列表推导式,这里有更多信息。
应该对返回的corpus_words进行排序。你可以使用python的sorted函数。
您可能会发现使用Python集合来删除重复的单词很有用。
def distinct_words(corpus):
""" Determine a list of distinct words for the corpus.
Params:
corpus (list of list of strings): corpus of documents
Return:
corpus_words (list of strings): sorted list of distinct words␣
,→across the corpus
num_corpus_words (integer): number of distinct words across the␣
,→corpus
"""
corpus_words = []
num_corpus_words = -1
# ------------------
# Write your implementation here.
corpus_words = {word for doc in corpus for word in doc}
corpus_words = sorted(list(corpus_words))
num_corpus_words = len(corpus_words)
# ------------------
return corpus_words, num_corpus_words
# ---------------------
# Run this sanity check
# Note that this not an exhaustive check for correctness.
# ---------------------
# Define toy corpus
test_corpus = ["{} All that glitters isn't gold {}".format(START_TOKEN,␣
,→END_TOKEN).split(" "), "{} All's well that ends well {}".format(START_TOKEN,␣
,→END_TOKEN).split(" ")]
test_corpus_words, num_corpus_words = distinct_words(test_corpus)
# Correct answers
ans_test_corpus_words = sorted([START_TOKEN, "All", "ends", "that", "gold",␣
,→"All's", "glitters", "isn't", "well", END_TOKEN])
ans_num_corpus_words = len(ans_test_corpus_words)
# Test correct number of words
assert(num_corpus_words == ans_num_corpus_words), "Incorrect number of distinct␣
,→words. Correct: {}. Yours: {}".format(ans_num_corpus_words, num_corpus_words)
# Test correct words
assert (test_corpus_words == ans_test_corpus_words), "Incorrect corpus_words.
,→\nCorrect: {}\nYours: {}".format(str(ans_test_corpus_words),␣
,→str(test_corpus_words))
# Print Success
print ("-" * 80)
print("Passed All Tests!")
print ("-" * 80)
--------------------------------------------------------------------------------
Passed All Tests!
--------------------------------------------------------------------------------
1.2.4 问题1.2:实现compute_co_recurce_matrix [code](3分)
编写一个方法,为特定的窗口大小n(默认值为4)构造一个共现矩阵,考虑窗口最中间的单词,该单词在窗口中前面有n个单词和后面也有n个单词。在这里,我们开始使用numpy (np)来表示向量、矩阵和张量。如果您不熟悉NumPy,在CS231n Python NumPy教程的第二部分中有一个NumPy教程。
def compute_co_occurrence_matrix(corpus, window_size=4):
""" Compute co-occurrence matrix for the given corpus and window_size␣
,→(default of 4).
Note: Each word in a document should be at the center of a window.␣
,→Words near edges will have a smaller
number of co-occurring words.
For example, if we take the document "<START> All that glitters␣
,→is not gold <END>" with window size of 4,
"All" will co-occur with "<START>", "that", "glitters", "is", and␣
,→"not".
Params:
corpus (list of list of strings): corpus of documents
window_size (int): size of context window
Return:
M (a symmetric numpy matrix of shape (number of unique words in the␣
,→corpus , number of unique words in the corpus)):
Co-occurence matrix of word counts.
The ordering of the words in the rows/columns should be the␣
,→same as the ordering of the words given by the distinct_words function.word2ind (dict): dictionary that maps word to index (i.e. row/
,→column number) for matrix M.
"""
words, num_words = distinct_words(corpus)
M = None
word2ind = {}
# ------------------
# Write your implementation here.
# Build the word to index mapping.
word2ind = {word: i for i, word in enumerate(words)}
# Build the co-occurrence matrix.
M = np.zeros((num_words, num_words))
for body in corpus:
for curr_idx, word in enumerate(body):
for window_idx in range(-window_size, window_size + 1):
neighbor_idx = curr_idx + window_idx
if (neighbor_idx < 0) or (neighbor_idx >= len(body)) or␣
,→(curr_idx == neighbor_idx):
continue
co_occur_word = body[neighbor_idx]
(word_idx, co_occur_idx) = (word2ind[word],␣
,→word2ind[co_occur_word])
M[word_idx, co_occur_idx] += 1
# ------------------
return M, word2ind
# ---------------------
# Run this sanity check
# Note that this is not an exhaustive check for correctness.
# ---------------------
# Define toy corpus and get student's co-occurrence matrix
test_corpus = ["{} All that glitters isn't gold {}".format(START_TOKEN,␣
,→END_TOKEN).split(" "), "{} All's well that ends well {}".format(START_TOKEN,␣
,→END_TOKEN).split(" ")]
M_test, word2ind_test = compute_co_occurrence_matrix(test_corpus, window_size=1)
# Correct M and word2ind
M_test_ans = np.array(
[[0., 0., 0., 0., 0., 0., 1., 0., 0., 1.,],
[0., 0., 1., 1., 0., 0., 0., 0., 0., 0.,],
[0., 1., 0., 0., 0., 0., 0., 0., 1., 0.,],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 1.,],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 1.,],
[0., 0., 0., 0., 0., 0., 0., 1., 1., 0.,],
[1., 0., 0., 0., 0., 0., 0., 1., 0., 0.,],
[0., 0., 0., 0., 0., 1., 1., 0., 0., 0.,],
[0., 0., 1., 0., 1., 1., 0., 0., 0., 1.,],
[1., 0., 0., 1., 1., 0., 0., 0., 1., 0.,]]
)
ans_test_corpus_words = sorted([START_TOKEN, "All", "ends", "that", "gold",␣
,→"All's", "glitters", "isn't", "well", END_TOKEN])
word2ind_ans = dict(zip(ans_test_corpus_words,␣
,→range(len(ans_test_corpus_words))))
# Test correct word2ind
assert (word2ind_ans == word2ind_test), "Your word2ind is incorrect:\nCorrect:␣
,→{}\nYours: {}".format(word2ind_ans, word2ind_test)
# Test correct M shape
assert (M_test.shape == M_test_ans.shape), "M matrix has incorrect shape.
,→\nCorrect: {}\nYours: {}".format(M_test.shape, M_test_ans.shape)
# Test correct M values
for w1 in word2ind_ans.keys():
idx1 = word2ind_ans[w1]
for w2 in word2ind_ans.keys():
idx2 = word2ind_ans[w2]
student = M_test[idx1, idx2]
correct = M_test_ans[idx1, idx2]
if student != correct:
print("Correct M:")
print(M_test_ans)
print("Your M: ")
print(M_test)
raise AssertionError("Incorrect count at index ({}, {})=({}, {}) in␣
,→matrix M. Yours has {} but should have {}.".format(idx1, idx2, w1, w2,␣
,→student, correct))
# Print Success
print ("-" * 80)
print("Passed All Tests!")
print ("-" * 80)
--------------------------------------------------------------------------------
Passed All Tests!
--------------------------------------------------------------------------------
1.2.5 问题 1.3: 实现 reduce_to_k_dim [code] (1 分)
构造一个对矩阵进行降维的方法来产生k维嵌入。使用SVD提取最上面的k个分量,并产生一个k维嵌入的新矩阵。
注意:numpy、scipy和scikit-learn (sklearn)都提供了SVD的一些实现,但只有scipy和sklearn提供了Truncated SVD的实现,只有sklearn提供了计算大规模Truncated SVD的有效随机算法。所以请使用sklearn.decomposition.TruncatedSVD。
def reduce_to_k_dim(M, k=2):
""" Reduce a co-occurence count matrix of dimensionality (num_corpus_words,␣
,→num_corpus_words)
to a matrix of dimensionality (num_corpus_words, k) using the following␣
,→SVD function from Scikit-Learn:
- http://scikit-learn.org/stable/modules/generated/sklearn.
,→decomposition.TruncatedSVD.html
Params:
M (numpy matrix of shape (number of unique words in the corpus ,␣
,→number of unique words in the corpus)): co-occurence matrix of word counts
k (int): embedding size of each word after dimension reduction
Return:
M_reduced (numpy matrix of shape (number of corpus words, k)):␣
,→matrix of k-dimensioal word embeddings.
In terms of the SVD from math class, this actually returns␣
,→U * S
"""
n_iters = 10 # Use this parameter in your call to `TruncatedSVD`
M_reduced = None
print("Running Truncated SVD over %i words..." % (M.shape[0]))
# ------------------
# Write your implementation here.
svd = TruncatedSVD(n_components = k)
svd.fit(M)
M_reduced = svd.transform(M)
# ------------------
print("Done.")
return M_reduced
# ---------------------
# Run this sanity check
# Note that this is not an exhaustive check for correctness
# In fact we only check that your M_reduced has the right dimensions.
# ---------------------
# Define toy corpus and run student code
test_corpus = ["{} All that glitters isn't gold {}".format(START_TOKEN,␣
,→END_TOKEN).split(" "), "{} All's well that ends well {}".format(START_TOKEN,␣
,→END_TOKEN).split(" ")]
M_test, word2ind_test = compute_co_occurrence_matrix(test_corpus, window_size=1)
M_test_reduced = reduce_to_k_dim(M_test, k=2)
# Test proper dimensions
assert (M_test_reduced.shape[0] == 10), "M_reduced has {} rows; should have {}".
,→format(M_test_reduced.shape[0], 10)
assert (M_test_reduced.shape[1] == 2), "M_reduced has {} columns; should have␣
,→{}".format(M_test_reduced.shape[1], 2)
# Print Success
print ("-" * 80)
print("Passed All Tests!")
print ("-" * 80)
Running Truncated SVD over 10 words…
Done.
--------------------------------------------------------------------------------
Passed All Tests!
--------------------------------------------------------------------------------
1.2.6 问题1.4:实现plot_embeddings [code](1分)
这里你要写一个函数来绘制二维空间中的一组二维向量。对于画图部分,我们将使用Matplotlib (plt)。
对于本例,您可能会发现修改此代码很有用。将来,制作绘图的一个好方法是查看Matplotlib库,然后找到一个看起来有点像您想要的绘图,并调整它们提供的代码。
def plot_embeddings(M_reduced, word2ind, words):
""" Plot in a scatterplot the embeddings of the words specified in the list␣
,→"words".
NOTE: do not plot all the words listed in M_reduced / word2ind.
Include a label next to each point.
Params:
M_reduced (numpy matrix of shape (number of unique words in the␣
,→corpus , 2)): matrix of 2-dimensioal word embeddings
word2ind (dict): dictionary that maps word to indices for matrix M
words (list of strings): words whose embeddings we want to visualize
"""
# ------------------
# Write your implementation here.
# Get only the rows corresponding the words we want to plot.
word_idxs = [word2ind[word] for word in words]
word_vectors = M_reduced[word_idxs]
# Get 2D coordinates.
x_coords = [vec[0] for vec in word_vectors]
y_coords = [vec[1] for vec in word_vectors]
# Plot the scatter points in 2D.
for i, word in enumerate(words):
x = x_coords[i]
y = y_coords[i]
plt.scatter(x, y, marker='x', color='red')
plt.text(x, y, word, fontsize=9)
plt.show()
# ------------------
# ---------------------
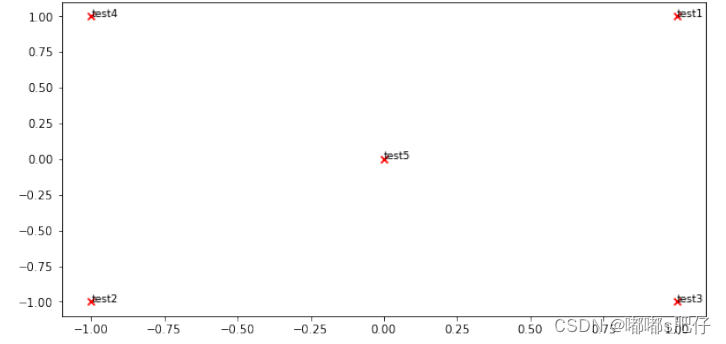
# Run this sanity check
# Note that this is not an exhaustive check for correctness.
# The plot produced should look like the "test solution plot" depicted below.
# ---------------------
print ("-" * 80)
print ("Outputted Plot:")
M_reduced_plot_test = np.array([[1, 1], [-1, -1], [1, -1], [-1, 1], [0, 0]])
word2ind_plot_test = {'test1': 0, 'test2': 1, 'test3': 2, 'test4': 3, 'test5':␣
,→4}
words = ['test1', 'test2', 'test3', 'test4', 'test5']
plot_embeddings(M_reduced_plot_test, word2ind_plot_test, words)
print ("-" * 80)
--------------------------------------------------------------------------------
Outputted Plot:
--------------------------------------------------------------------------------
1.2.7 问题1.5:共现图分析【书面】(3分)
现在我们将把你写的所有部分放在一起!我们将在路透社“原油”(石油)语料库上计算固定窗口为4(默认窗口大小)的同现矩阵,然后我们将使用TruncatedSVD来计算每个单词的二维嵌入。TruncatedSVD返回 U ∗ S U*S U∗S,所以我们需要将返回的向量归一化,这样所有的向量都将出现在单位圆周围(因此两个向量接不接近可以看他们指向的方向是否接近)。注意:下面执行规范化的代码行使用了NumPy的广播概念。如果你不知道广播,可以看看Jake VanderPlas的《数组计算:广播》。
运行下面的单元格生成绘图。运行起来可能需要几秒钟。在二维嵌入空间中有什么聚集在了一起?你认为应该聚集在一起的东西是什么?注:“bpd”表示“每日桶数”,是原油专题文章中常用的缩写。
# -----------------------------
# Run This Cell to Produce Your Plot
# ------------------------------
reuters_corpus = read_corpus()
M_co_occurrence, word2ind_co_occurrence =␣
,→compute_co_occurrence_matrix(reuters_corpus)
M_reduced_co_occurrence = reduce_to_k_dim(M_co_occurrence, k=2)
# Rescale (normalize) the rows to make them each of unit-length
M_lengths = np.linalg.norm(M_reduced_co_occurrence, axis=1)
M_normalized = M_reduced_co_occurrence / M_lengths[:, np.newaxis] # broadcasting
words = ['barrels', 'bpd', 'ecuador', 'energy', 'industry', 'kuwait', 'oil',␣
,→'output', 'petroleum', 'iraq']
plot_embeddings(M_normalized, word2ind_co_occurrence, words
Running Truncated SVD over 8185 words…
Done.
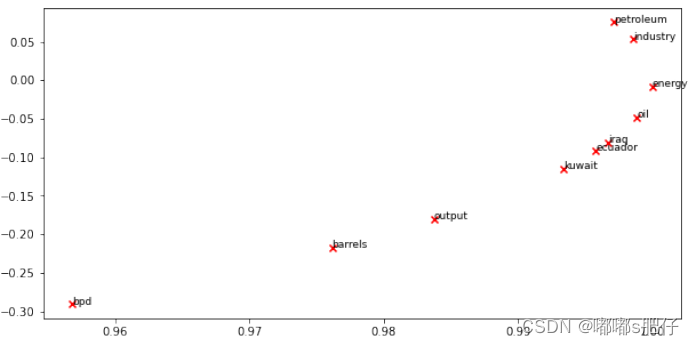
在这里写下你的答案。
•从上面的情节中,我们可以观察到三个簇:
——石油行业
——能源,石油
-厄瓜多尔、伊拉克、科威特
•主要石油出口国聚集在一起。这是有意义的,因为共现矩阵将一般的主题分组,而且由于石油国家可能在路透社的文章语料库中共享类似的共现词,它们更有可能聚集。
•“bpd”、“桶”和“输出”应该聚在一起,但显然它们在给定的数据集中的共现率较低。此外,石油(petroleum)和石油(oil)可以更紧密地聚集在一起,因为原油(crude oil)和石油(petroleum)有时是同义词。
1.3 第二部分:基于预测的词向量(15分)
正如在课堂上讨论的,基于预测的词向量越接近表现出越好的性能,如word2vec和GloVe(也利用了计数的好处)。在这里,我们将探索GloVe产生的嵌入。请重新查看课堂笔记和讲座幻灯片以了解更多关于word2vec和GloVe算法的细节。如果你喜欢冒险挑,战自己,那就去尝试阅读GloVe的原稿。
然后运行以下单元格,将GloVe向量加载到内存中。注意:如果这是你第一次运行这些单元格,即下载嵌入模型,将需要几分钟运行。如果您以前运行过这些单元格,重新运行它们将加载模型,而无需重新下载,这将需要大约1到2分钟。
def load_embedding_model():
""" Load GloVe Vectors
Return:
wv_from_bin: All 400000 embeddings, each lengh 200
"""
import gensim.downloader as api
wv_from_bin = api.load("glove-wiki-gigaword-200")
print("Loaded vocab size %i" % len(wv_from_bin.vocab.keys()))
return wv_from_bin
# -----------------------------------
# Run Cell to Load Word Vectors
# Note: This will take a couple minutes
# -----------------------------------
wv_from_bin = load_embedding_model()
Loaded vocab size 400000
注意:如果您收到一个“reset by peer”错误,请重新运行单元以重新启动下载。
1.3.1 词嵌入的降维
让我们直接将GloVe嵌入与共生矩阵的嵌入进行比较。为了避免内存耗尽,我们将使用10000个GloVe向量的样本。运行以下单元格:
1. 将10000个手套向量放入矩阵M中
2. 运行reduce_to_k_dim(截断后的SVD函数)将向量从200维降为2维。
def get_matrix_of_vectors(wv_from_bin, required_words=['barrels', 'bpd',␣
,→'ecuador', 'energy', 'industry', 'kuwait', 'oil', 'output', 'petroleum',␣
,→'iraq']):
""" Put the GloVe vectors into a matrix M.
Param:
wv_from_bin: KeyedVectors object; the 400000 GloVe vectors loaded␣
,→from file
Return:
M: numpy matrix shape (num words, 200) containing the vectors
word2ind: dictionary mapping each word to its row number in M
"""
import random
words = list(wv_from_bin.vocab.keys())
print("Shuffling words ...")
random.seed(224)
random.shuffle(words)
words = words[:10000]
print("Putting %i words into word2ind and matrix M..." % len(words))
word2ind = {}
M = []
curInd = 0
for w in words:
try:
M.append(wv_from_bin.word_vec(w))
word2ind[w] = curInd
curInd += 1
except KeyError:
continue
for w in required_words:
if w in words:
continue
try:
M.append(wv_from_bin.word_vec(w))
word2ind[w] = curInd
curInd += 1
except KeyError:
continue
M = np.stack(M)
print("Done.")
return M, word2ind
# -----------------------------------------------------------------
# Run Cell to Reduce 200-Dimensional Word Embeddings to k Dimensions
# Note: This should be quick to run
# -----------------------------------------------------------------
M, word2ind = get_matrix_of_vectors(wv_from_bin)
M_reduced = reduce_to_k_dim(M, k=2)
# Rescale (normalize) the rows to make them each of unit-length
M_lengths = np.linalg.norm(M_reduced, axis=1)
M_reduced_normalized = M_reduced / M_lengths[:, np.newaxis] # broadcasting
Shuffling words …
Putting 10000 words into word2ind and matrix M…
Done.
Running Truncated SVD over 10010 words…
Done.
注:如果您在本地机器上遇到内存不足的问题,请尝试关闭其他应用程序以释放设备上更多的内存。你可能想要重新启动你的机器,这样你就可以释放额外的内存。然后立即运行jupyter笔记本,看看你能否正确加载词向量。如果在此之后您仍然在加载嵌入到本地机器上时遇到问题,请到办公时间或联系课程工作人员。
1.3.2 问题2.1:GloVe图分析写作
运行下面的单元格来绘制 [‘barrels’, ‘bpd’, ‘ecuador’,
‘energy’, ‘industry’, ‘kuwait’, ‘oil’, ‘output’, ‘petroleum’, ‘iraq’]。
在二维嵌入空间中有哪些向量聚成一类?哪些向量不聚在一起,但是你认为它们应该聚在一起?这个图与之前从共现矩阵中生成的图有什么不同?造成这种差异的可能原因是什么?
words = ['barrels', 'bpd', 'ecuador', 'energy', 'industry', 'kuwait', 'oil',␣
,→'output', 'petroleum', 'iraq']
plot_embeddings(M_reduced_normalized, word2ind, words)
在这里写下你的答案。
•与基于窗口的共现嵌入不同,这些基于预测的GloVe嵌入没有将聚集在一起的国家聚成一类。例如,科威特离伊拉克变得特别远。
•手套似乎将“能源”和“产业”更紧密地聚集在一起,而不是同时出现的嵌入。“桶”和“bpd”仍然很遥远,尽管它们预计会更接近,因为每天桶数应该是桶数的函数。
1.3.3 余弦相似度
现在我们有了词向量,我们需要一种方法来根据这些向量量化单个单词之间的相似度。其中一个度量是余弦相似度(cosine-similarity)。我们将使用它来寻找彼此离得“近”和“远”的单词。
我们可以将n维向量视为n维空间中的点。如果我们从这个角度来看L1和L2距离有助于量化这两个点之间“我们必须组走过”的空间大小。另一种方法是检查两个向量之间的夹角。根据三角学,我们知道:
我们可以用
s
i
m
i
l
a
r
i
t
y
=
c
o
s
(
Θ
)
similarity = cos(Θ)
similarity=cos(Θ)来表示相似度,而不是计算实际的角度。
形式上,两个向量
p
p
p和
q
q
q之间的余弦相似度
s
s
s定义为:
s = p ⋅ q , s = p \cdot q \,, s=p⋅q, ∥ p ∥ ∥ q ∥ , w h e r e s ∈ [ − 1 , 1 ] . \Vert p \Vert\Vert q \Vert , where s ∈ [−1, 1]\,. ∥p∥∥q∥,wheres∈[−1,1].
1.3.4 问题2.2:多义词(1.5分)[代码+书面]
多义词和同音异义词是指具有多个含义的单词(查看这个wiki页面了解更多关于多义词和同音异义词之间的区别)。找到一个至少有两种不同含义的单词,使前10个最相似的单词(根据余弦相似度)包含两种含义的相关单词。例如," leaves “同时包含” go_away ",“a_structure_of_a_plant”跻身前十,“scoop”同时拥有“handded_waffle_cone”和“lowdown”的意思。在找到一个词之前,你可能需要尝试几个多义词或同音异义词。
请说出你发现的单词以及出现在前10名中的多种含义。为什么你认为你尝试过的许多多义词或同音词都不起作用(即10个最相似的单词只包含单词的一种含义)?
注意:您应该使用wv_from_bin.most_similar(word)函数来获得前10个相似的单词。这个函数根据单词与给定单词的余弦相似度对词汇表中的所有其他单词进行排名。如需进一步帮助,请查看GenSim文档。
# ------------------
# Write your implementation here.
wv_from_bin.most_similar("arms")
#wv_from_bin.most_similar("mouse")
#wv_from_bin.most_similar("mole")
#wv_from_bin.most_similar("tear")
# ------------------
[('weapons', 0.7115006446838379),
('hand', 0.5853789448738098),
('hands', 0.582863986492157),
('weapon', 0.5786144733428955),
('embargo', 0.5249772667884827),
('arm', 0.5146462917327881),
('weaponry', 0.513433039188385),
('nuclear', 0.5115358829498291),
('disarmament', 0.5083263516426086),
('iraq', 0.49865245819091797)]
在这里写下你的答案。
•由于“weapons”和“arms”都在“arms”的十大含义之列,这意味着嵌入包含了“arms”的两个含义:: weaponry 和 limb。(译者注:都是 武器 的意思)
•许多多义词没有表现出不同含义的一个原因是这些手套向量是建立在Wiki数据之上的,其中单词通常具有相同的含义。另一个原因可能是前10个相似的单词有时包括同一个单词的不同形式(arm)或它的含义(hand/hands)。
1.3.5 问题2.3:同义词和反义词(2分)[代码+书面]
当考虑余弦相似度时,通常认为余弦距离更方便,它简单地是1 - 余弦相似度。
找到三个单词(w1, w2, w3),其中w1和w2是同义词,w1和w3是反义词,但是
C
o
s
i
n
e
D
i
s
t
a
n
c
e
(
w
1
,
w
3
)
<
C
o
s
i
n
e
D
i
s
t
a
n
c
e
(
w
1
,
w
2
)
Cosine Distance (w1, w3) < Cosine Distance (w1, w2)
CosineDistance(w1,w3)<CosineDistance(w1,w2)
例如,
w
1
=
“快乐”
w1=“快乐”
w1=“快乐”比
w
2
=
“快乐
w2=“快乐
w2=“快乐”更接近于
w
3
=
“悲伤”
w3=“悲伤”
w3=“悲伤”。请找到一个满足以上所形容的不同的例子。一旦你找到了你的例子,请给出一个可能的解释,为什么会出现这个反直觉的结果。
您应该使用wv_from_bin。这里的
D
i
s
t
a
n
c
e
(
w
1
,
w
2
)
Distance (w1, w2)
Distance(w1,w2)函数用来计算两个单词之间的余弦距离。请参阅GenSim文档以获得进一步的帮助。
# ------------------
# Write your implementation here.
w1 = "love" # synonym 1
w2 = "affection" # synonym 2
w3 = "hate" # antonym
w1_w2_dist = wv_from_bin.distance(w1, w2)
w1_w3_dist = wv_from_bin.distance(w1, w3)
print("Synonyms {}, {} have cosine distance: {}".format(w1, w2, w1_w2_dist))
print("Antonyms {}, {} have cosine distance: {}".format(w1, w3, w1_w3_dist))
# ------------------
Synonyms love, affection have cosine distance: 0.42052197456359863
Antonyms love, hate have cosine distance: 0.49353712797164917
在这里写下你的答案。
•在确定词嵌入时,在序列中单词之间的邻近性,即上下文,比它们在含义/语义上的相似性具有更大的权重。
•有些词可以是反义词,但仍然可以在同一语境中使用,所以它们的距离比一对同义词要小。相反,即使两个单词是同义词,它们也可以用于不同的上下文中。因此,
w
1
w1
w1和
w
3
w3
w3可能比
w
1
w1
w1和
w
2
w2
w2出现在更相似的环境中。这会导致
w
1
′
s
w_{1's}
w1′s与
w
3
′
s
w_{3's}
w3′s的向量比
w
1
′
s
w_{1's}
w1′s与
w
2
′
s
w_{2's}
w2′s向量更相似。
1.3.6 问题2.4:类比词向量[写作](1.5分)
词向量有时显示出解决类比的能力。
举个例子,类比“man : king :: woman : x”(读作man之于king就像woman之于x), x是什么?
在下面的单元格中,我们将向您展示如何使用GenSim文档中的most_similar函数使用词向量来查找x。该函数找出与正列表中单词最相似、与负列表中单词最不相似的单词(同时省略输入单词,它们通常最相似;见这篇paper)。这个类比的答案将具有最大的余弦相似度(最大的返回数值)。
# Run this cell to answer the analogy -- man : king :: woman : x
pprint.pprint(wv_from_bin.most_similar(positive=['woman', 'king'],␣
,→negative=['man']))
[('queen', 0.6978679299354553),
('princess', 0.6081743836402893),
('monarch', 0.5889754891395569),
('throne', 0.5775110125541687),
('prince', 0.5750998258590698),
('elizabeth', 0.5463595986366272),
('daughter', 0.5399126410484314),
('kingdom', 0.5318052768707275),
('mother', 0.5168544054031372),
('crown', 0.5164472460746765)]
设m、k、w和x分别表示man、king、woman和答案的词向量。
在你的答案中(仅使用向量m、k、w和向量算术运算符+和-来表示),我们最大化与x的余弦相似度的表达式是什么?
提示:回想一下,词向量只是表示单词的多维向量。使用每个向量的随机位置绘制一个2D示例可能会有所帮助。相对于国王和答案,男人和女人在坐标平面上的哪个位置?
在这里写下你的答案。最大化与x的余弦相似度的表达式为:
∣
k
−
m
∣
≈
∣
x
−
w
∣
|k − m| ≈ |x − w|
∣k−m∣≈∣x−w∣
通过编程,我们试图确保k - m之间的距离(使用余弦相似性度量)与x - w尽可能相似。
1.3.7 问题2.5:寻找类比代码+写作
根据这些向量找到一个类比的例子(即,预期的单词排在前面)。在你的解决方案中,请以x:y::a:b的形式陈述完整的类比。如果你认为这个类比很复杂,用一两句话解释为什么这个类比成立。
注意:你可能需要尝试许多类比才能找到一个有效的!
# ------------------
# Write your implementation here.
pprint.pprint(wv_from_bin.most_similar(positive=['woman','actor'],␣
,→negative=['man']))
#pprint.pprint(wv_from_bin.most_similar(positive=['paris', 'italy'],␣
,→negative=['rome']))
# ------------------
[('actress', 0.8572621941566467),
('actresses', 0.6734701991081238),
('actors', 0.6297088861465454),
('starring', 0.6084522604942322),
('starred', 0.5989463925361633),
('screenwriter', 0.595988929271698),
('dancer', 0.5881683230400085),
('comedian', 0.5791141390800476),
('singer', 0.5661861300468445),
('married', 0.5574131011962891)]
在这里写下你的答案。
•示例1:
-man:actor :: woman:actress 男:男演员:女演员
•示例2:
-rome:italy :: paris:france 罗马:意大利:巴黎:法国
1.3.8 问题2.6:不正确的类比[代码+写作](1.5分)
根据这些向量找一个不成立的类比例子。在你的解决方案中,以x:y:: a:b的形式陈述预期的类比,并根据词向量陈述b的(不正确的)值。
# ------------------
# Write your implementation here.
pprint.pprint(wv_from_bin.most_similar(positive=["america", "peacock"],␣
,→negative=["india"]))
#pprint.pprint(wv_from_bin.most_similar(positive=["england", "india"],␣
,→negative=["english"]))
# ------------------
[('nbc', 0.3861715793609619),
('betsy', 0.38571250438690186),
('channing', 0.3854195177555084),
('abc', 0.3780362904071808),
('jamie', 0.3735346794128418),
('carol', 0.3651508688926697),
('bonnie', 0.3609510064125061),
('turner', 0.3577595353126526),
('jennings', 0.3513510227203369),
('kelley', 0.34911856055259705)]
在这里写下你的答案。
•示例1:
– Actual: india:peacock :: america:nbc 实际:印度:孔雀:美国:nbc
– Expected: india:peacock :: america:eagle 预期:印度:孔雀:美国:鹰
•示例2:
– Actual: england:english :: india:pakistan 实际:英国:英语:印度:巴基斯坦
– Expected: england:english :: india:hindi 期望:英国:英语:印度:印地语
1.3.9 问题2.7:词向量偏置的引导分析[写作](1分)
认识到我们的词嵌入中隐含的偏见(性别、种族、性取向等)是很重要的。偏见可能是危险的,因为它会通过使用这些模型的应用程序加强刻板印象。
运行下面的单元格,以检查(a)哪些术语与“女人”和“工人”最相似,与“男人”最不相似,以及(b)哪些术语与“男人”和“工人”最相似,与“女人”最不相似。指出女性关联词列表和男性关联词列表之间的区别,并解释它如何反映性别偏见。
# Run this cell
# Here `positive` indicates the list of words to be similar to and `negative`␣
,→indicates the list of words to be
# most dissimilar from.
pprint.pprint(wv_from_bin.most_similar(positive=['woman', 'worker'],␣
,→negative=['man']))
print()
pprint.pprint(wv_from_bin.most_similar(positive=['man', 'worker'],␣
,→negative=['woman']))
[('employee', 0.6375863552093506),
('workers', 0.6068919897079468),
('nurse', 0.5837946534156799),
('pregnant', 0.536388635635376),
('mother', 0.5321309566497803),
('employer', 0.5127025842666626),
('teacher', 0.5099576711654663),
('child', 0.5096741914749146),
('homemaker', 0.5019454956054688),
('nurses', 0.4970572292804718)]
[('workers', 0.611325740814209),
('employee', 0.5983108282089233),
('working', 0.5615329146385193),
('laborer', 0.5442320108413696),
('unemployed', 0.5368516445159912),
('job', 0.5278826951980591),
('work', 0.5223962664604187),
('mechanic', 0.5088937282562256),
('worked', 0.5054520964622498),
('factory', 0.4940453767776489)]
在这里写下你的答案。围绕职业产生的向量似乎在性别方面存在一些偏见。
•Nurse, teacher, homemaker 护士、教师、家庭主妇是与“woman女人”和“worker工人”最相似但与“man男人”最不相似的10个词汇。
•Laborer, mechanic and factory 劳动者、技工和工厂是与“man男人”和“worker工人”最相似但与“woman女人”最不相似的词汇。
因此,这些向量似乎已经了解到性别之间在就业角色方面的一些差异。然而,确实一些性别中性的词同时出现在两种情况下,如 employee, workers雇员,工人。
1.3.10 问题2.8:词向量偏置的独立性分析[代码+写作](1分)
使用most_similar函数来找到向量表现出一些偏差的另一种情况。
请简要解释你发现的偏见的例子。
# ------------------
# Write your implementation here.
pprint.pprint(wv_from_bin.most_similar(positive=['woman', 'profession'],␣
,→negative=['man']))
print()
pprint.pprint(wv_from_bin.most_similar(positive=['man', 'profession'],␣
,→negative=['woman']))
# ------------------
[('professions', 0.5957457423210144),
('practitioner', 0.49884119629859924),
('teaching', 0.48292142152786255),
('nursing', 0.4821180999279022),
('vocation', 0.4788965880870819),
('teacher', 0.47160348296165466),
('practicing', 0.4693780839443207),
('educator', 0.46524325013160706),
('physicians', 0.4628995358943939),
('professionals', 0.4601393938064575)]
在这里写下你的答案。
•与“man”最相似但与“woman”最不相似的职业列出了一系列职业,如physicians, educator/teacher 医生、教育家/教师等,还包括practitioner and professionals 从业者和专业人员等关键词。
•另一方面,与“women”和“profession 职业”最相似但与“man”最不相似的嵌入词是reputation, skills, ethic, business, 声誉、技能、伦理、业务等。
•因此,这个例子在针对性别的职业选择中表现出了明显的偏见,因为像physicians, educator/teacher 医生、教育家/教师这样的职业与“man”比“woman”更相似。
1.3.11 问题2.9:关于偏见的思考[写作](2分)
解释一下偏见是如何进入词向量的。你可以做什么实验来测试或测量这个偏差源?
在这里写下你的答案。
•“你的模型只有在它训练的数据上才好”,也就是“垃圾进/垃圾出”。
•由于你的模型仅依赖于输入数据来生成其嵌入,社会固有的偏见可以通过模型训练的数据隐式传播。这引起了关注,因为它们的广泛使用往往会放大这些偏见。
•新闻文章经常在种族、宗教、性别、性取向等方面表现出偏见。由于训练目标是最大化正确预测下一个单词的概率,如果数据中的上下文窗口具有隐式偏差,则它们可能会被模型捕获。例如,虽然希望在"女性"和"女王"之间建立联系,但在"女性"和"接待员"之间建立联系表明一种不健康的性别刻板印象,需要加以消除,即不与性别有关。
为了测试或测量偏差来源,你可以计算一个向量
g
=
e
w
o
m
a
n
−
e
m
a
n
g = ewoman−eman
g=ewoman−eman,其中ewoman表示单词“woman”对应的词向量,eman表示单词“man”对应的词向量。由此产生的向量g粗略地编码了“性别”的概念。现在,通过比较g和一系列职业之间的距离,我们可以发现不健康的性别刻板印象。
•此外,利用bolukbasi等人(2016)提出的均衡算法,我们可以通过修改词向量来减少性别刻板印象(但不能完全消除它),在一定程度上消除词向量的偏见。

















 2575
2575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









