







【Sklearn驯化-数据处理】一文搞懂sklearn中数据处理方法StandardScaler、OneHotEncoder、pca
本次修炼方法请往下查看

🌈 欢迎莅临我的个人主页 👈这里是我工作、学习、实践 IT领域、真诚分享 踩坑集合,智慧小天地!
🎇 相关内容文档获取 微信公众号
🎇 相关内容视频讲解 B站
🎓 博主简介:AI算法驯化师,混迹多个大厂搜索、推荐、广告、数据分析、数据挖掘岗位 个人申请专利40+,熟练掌握机器、深度学习等各类应用算法原理和项目实战经验。
🔧 技术专长: 在机器学习、搜索、广告、推荐、CV、NLP、多模态、数据分析等算法相关领域有丰富的项目实战经验。已累计为求职、科研、学习等需求提供近千次有偿|无偿定制化服务,助力多位小伙伴在学习、求职、工作上少走弯路、提高效率,近一年好评率100% 。
📝 博客风采: 积极分享关于机器学习、深度学习、数据分析、NLP、PyTorch、Python、Linux、工作、项目总结相关的实用内容。
🌵文章目录🌵
下滑查看解决方法
🎯 1、sklearn自带数据
scikit-learn(简称sklearn)是Python中一个广泛使用的机器学习库,它不仅提供了众多的机器学习算法实现,还包含了若干内置数据集,这些数据集被广泛用于学习、测试和演示机器学习算法。这些数据集包括鸢尾花(Iris)、葡萄酒(Wine)、波士顿房价(Boston)等经典数据集。
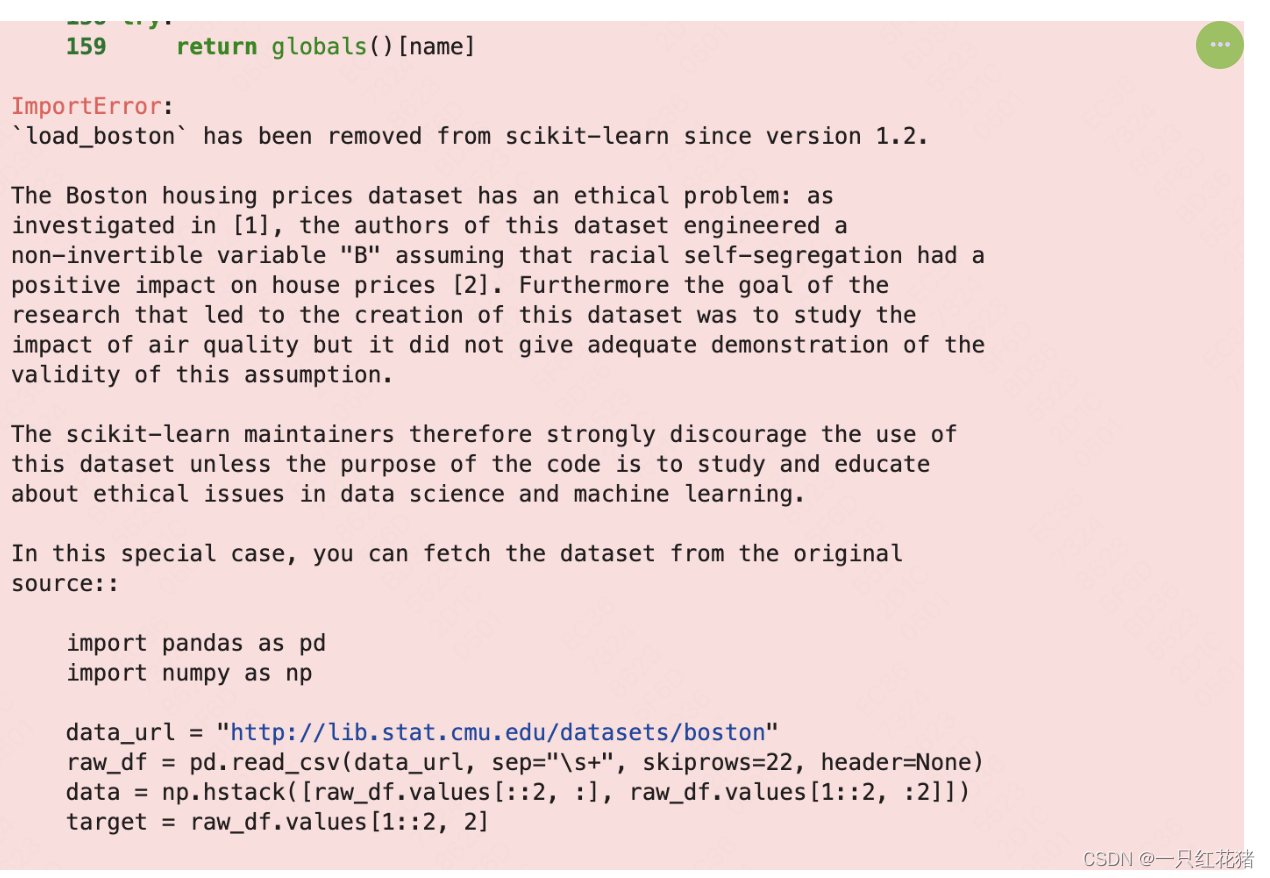
但是波士顿房价数据在sklearn大于1.2版本之后不再进行更新迭代了,后续如果使用将通过下面的方法进行:
1.1 鸢尾花(Iris)数据
在scikit-learn(sklearn)库中,鸢尾花(Iris)数据集被称为"load_iris"数据集。该数据集是一个监督型数据集,可以根据该数据集作为后续监督学习算法的实践学习,具体关于该数据集的一些介绍如下所示:
-
该数据集在sklearn库中是一个字典对象,包含以下几个属性:
-
data: 一个包含鸢尾花样本特征的二维数组,每一行代表一个样本,每一列代表一个特征(萼片长度、萼片宽度、花瓣长度和花瓣宽度)。
-
target: 一个包含鸢尾花样本标签的一维数组,每个元素代表对应样本的品种(0:Setosa,1:Versicolor,2:Virginica)。
-
target_names: 一个包含鸢尾花品种名称的一维数组,与目标数组中的标签相对应。
-
feature_names: 一个包含鸢尾花特征名称的一维数组,与特征数组中的列相对应。
-
DESCR: 一个包含数据集描述的字符串。
具体的数据使用方法如下所示:
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data # 特征数组
y = iris.target # 目标数组
target_names = iris.target_names # 目标类别名称
feature_names = iris.feature_names # 特征名称
print(feature_name)
feature_names
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
description = iris.DESCR # 数据集描述
1.2 葡萄酒(Wine)数据集
葡萄酒数据集(Wine Dataset)是sklearn中常用的一个数据集,它包含了来自于不同产地的三种不同品种的葡萄酒的化学分析结果。该数据集共有178个样本,每个样本有13个特征,分别是:
-
- Alcohol(酒精含量)
-
- Malic acid(苹果酸含量)
-
- Ash(灰分含量)
-
- Alcalinity of ash(灰分的碱度)
-
- Magnesium(镁含量)
-
- Total phenols(总酚含量)
-
- Flavanoids(类黄酮含量)
-
- Nonflavanoid phenols(非类黄酮酚含量)
-
- Proanthocyanins(原花青素含量)
-
- Color intensity(颜色强度)
-
- Hue(色相)
-
- OD280/OD315 of diluted wines(稀释酒样的吸光度之比)
-
- Proline(脯氨酸含量)
这个数据集可以用于分类任务,其中的样本被分为三个类别,分别表示三个不同的葡萄酒品种。葡萄酒数据集可以被用来训练和评估机器学习模型,例如分类算法、聚类算法等。具体的用法如下所示:
from sklearn.datasets import load_wine
# 加载葡萄酒数据集
data = load_wine()
# 打印数据集的描述信息
print("数据集描述:\n", data.DESCR)
数据集描述:
.. _wine_dataset:
Wine recognition dataset
------------------------
**Data Set Characteristics:**
:Number of Instances: 178
:Number of Attributes: 13 numeric, predictive attributes and the class
:Attribute Information:
- Alcohol
- Malic acid
- Ash
- Alcalinity of ash
- Magnesium
- Total phenols
- Flavanoids
- Nonflavanoid phenols
- Proanthocyanins
- Color intensity
- Hue
- OD280/OD315 of diluted wines
- Proline
- class:
- class_0
- class_1
- class_2
:Summary Statistics:
============================= ==== ===== ======= =====
Min Max Mean SD
============================= ==== ===== ======= =====
Alcohol: 11.0 14.8 13.0 0.8
Malic Acid: 0.74 5.80 2.34 1.12
Ash: 1.36 3.23 2.36 0.27
Alcalinity of Ash: 10.6 30.0 19.5 3.3
Magnesium: 70.0 162.0 99.7 14.3
Total Phenols: 0.98 3.88 2.29 0.63
Flavanoids: 0.34 5.08 2.03 1.00
Nonflavanoid Phenols: 0.13 0.66 0.36 0.12
Proanthocyanins: 0.41 3.58 1.59 0.57
Colour Intensity: 1.3 13.0 5.1 2.3
Hue: 0.48 1.71 0.96 0.23
OD280/OD315 of diluted wines: 1.27 4.00 2.61 0.71
Proline: 278 1680 746 315
============================= ==== ===== ======= =====
1.3 波士顿房价(Boston)
波士顿房价数据集(Boston Housing Dataset)是机器学习中常用的一个数据集,用于预测波士顿地区房屋的中位数价格。该数据集共有506个样本,每个样本有13个特征,分别是:
-
- CRIM:城镇人均犯罪率。
-
- ZN:住宅用地超过 25000 平方英尺的比例。
-
- INDUS:城镇中非零售商业用地的比例。
-
- CHAS:查尔斯河的虚拟变量(如果一个样本在河边,则取值为1,否则取值为0)。
-
- NOX:一氧化氮浓度。
-
- RM:平均每个住宅的房间数。
-
- AGE:1940 年之前建成的自住单位的比例。
-
- DIS:到波士顿五个中心区域的加权距离。
-
- RAD:离住宅最近的公路入口的可达性指数。
-
- TAX:每 10000 美元的全值财产税率。
-
- PTRATIO:城镇中教师与学生的比例。
-
- B:1000(Bk - 0.63)^2,其中Bk是城镇黑人的比例。
-
- LSTAT:人口中地位低下者的比例。这个数据集中的目标变量是房价的中位数(MEDV)。
波士顿房价数据集可以用于回归任务,例如预测房价。在scikit-learn(sklearn)库中,数据集的使用如下所示:
import pandas as pd
import numpy as np
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
print(data)
array([[6.3200e-03, 1.8000e+01, 2.3100e+00, ..., 1.5300e+01, 3.9690e+02,
4.9800e+00],
[2.7310e-02, 0.0000e+00, 7.0700e+00, ..., 1.7800e+01, 3.9690e+02,
9.1400e+00],
[2.7290e-02, 0.0000e+00, 7.0700e+00, ..., 1.7800e+01, 3.9283e+02,
4.0300e+00],
...,
[6.0760e-02, 0.0000e+00, 1.1930e+01, ..., 2.1000e+01, 3.9690e+02,
5.6400e+00],
[1.0959e-01, 0.0000e+00, 1.1930e+01, ..., 2.1000e+01, 3.9345e+02,
6.4800e+00],
[4.7410e-02, 0.0000e+00, 1.1930e+01, ..., 2.1000e+01, 3.9690e+02,
7.8800e+00]])
💡 2 Sklearn中的数据处理
在机器学习中,数据处理是至关重要的一步。scikit-learn(简称sklearn)提供了一系列的数据处理函数,这些函数可以帮助我们进行数据清洗、特征选择、特征缩放等操作,从而提高模型的性能。具体的一些方法如下所示:
2.1 缺失值处理
真实数据中,缺失值有较大的比例都是存在的,在sklearn中处理相关的缺失值的代码如下所示:
from sklearn.impute import SimpleImputer
# 假设有以下含缺失值的数据
data = [[np.nan, 2], [6, np.nan], [7, 6]]
# 创建填充对象并拟合数据
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
data_imputed = imputer.fit_transform(data)
print(data_imputed)
[[4.5 2. ]
[ 6. 4.5]
[ 7. 6. ]]
2.2 特征缩放
特征缩放用于将数据标准化,以消除不同量纲的影响。
from sklearn.preprocessing import StandardScaler
# 使用标准缩放器
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data_imputed)
print(scaled_data)
[[-1.224744871 1.224744871]
[ 1.224744871 -1.224744871]
[ 0. 0. ]]
2.3 特征编码
特征编码是将类别型特征转换为模型可以处理的数值型特征。
from sklearn.preprocessing import OneHotEncoder
# 假设有以下类别型数据
data_categorical = [['male', 'young'], ['female', 'old'], ['female', 'young']]
# 创建编码器并拟合数据
encoder = OneHotEncoder(sparse=False)
data_encoded = encoder.fit_transform(data_categorical)
print(data_encoded)
[[1.0 0.0 1.0 0.0]
[0.0 1.0 0.0 1.0]
[0.0 1.0 1.0 0.0]]
2.4 主成分分析(PCA)
PCA是一种降维技术,用于在保留数据集中大部分变异性的同时减少特征数量。
from sklearn.decomposition import PCA
# 使用PCA降维
pca = PCA(n_components=1)
data_pca = pca.fit_transform(scaled_data)
print(data_pca)
[[-1.33630621]
[ 1.23675577]
[ 0.99954949]]
🔍 3. 注意事项
对上述的各个函数在使用的过程中需要注意的一些事项,不然可能会出现error,具体主要为:
- 在进行特征缩放或编码之前,确保已经处理了所有缺失值。
- 特征编码和PCA等方法可能会影响模型的性能,需要根据具体情况选择合适的参数。
- 一些数据处理方法,如PCA,对数据的尺度敏感,可能需要先进行标准化。
🔧 4. 总结
scikit-learn提供了强大的数据处理函数,这些函数涵盖了从数据清洗到特征工程的各个环节。通过本博客的代码示例,我们学习了如何使用sklearn进行数据清洗、特征缩放、特征编码和降维。正确的数据处理方法可以显著提高模型的准确性和效率。希望这篇博客能够帮助你更好地理解sklearn中的数据处理函数,并将其应用于实际的机器学习项目中。

















 312
312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











