







背景
Read the fucking source code!--By 鲁迅A picture is worth a thousand words.--By 高尔基
说明:
- Kernel版本:4.14
- ARM64处理器,Contex-A53,双核
- 使用工具:Source Insight 3.5, Visio
1. 概述
这篇文章,让我们来看看用户态进程的地址空间情况,主要会包括以下:
vma;malloc;mmap;
进程地址空间中,我们常见的代码段,数据段,bss段等,实际上都是一段地址空间区域。Linux将地址空间中的区域称为Virtual Memory Area, 简称VMA,使用struct vm_area_struct来描述。
在进行内存申请和映射时,都会去地址空间中申请一段虚拟地址区域,而这部分操作也与vma关系密切,因此本文将vma/malloc/mmap三个放到一块来进行分析。
开启探索之旅吧。
2. 数据结构
主要涉及两个结构体:struct mm_struct和struct vm_area_struct。
struct mm_struct
用于描述与进程地址空间有关的全部信息,这个结构也包含在进程描述符中,关键字段的描述见注释。
struct mm_struct {
struct vm_area_struct *mmap; /* list of VMAs */ //指向VMA对象的链表头
struct rb_root mm_rb; //指向VMA对象的红黑树的根
u64 vmacache_seqnum; /* per-thread vmacache */
#ifdef CONFIG_MMU
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags); // 在进程地址空间中搜索有效线性地址区间的方法
#endif
unsigned long mmap_base; /* base of mmap area */
unsigned long mmap_legacy_base; /* base of mmap area in bottom-up allocations */
#ifdef CONFIG_HAVE_ARCH_COMPAT_MMAP_BASES
/* Base adresses for compatible mmap() */
unsigned long mmap_compat_base;
unsigned long mmap_compat_legacy_base;
#endif
unsigned long task_size; /* size of task vm space */
unsigned long highest_vm_end; /* highest vma end address */
pgd_t * pgd; //指向页全局目录
/**
* @mm_users: The number of users including userspace.
*
* Use mmget()/mmget_not_zero()/mmput() to modify. When this drops
* to 0 (i.e. when the task exits and there are no other temporary
* reference holders), we also release a reference on @mm_count
* (which may then free the &struct mm_struct if @mm_count also
* drops to 0).
*/
atomic_t mm_users; //使用计数器
/**
* @mm_count: The number of references to &struct mm_struct
* (@mm_users count as 1).
*
* Use mmgrab()/mmdrop() to modify. When this drops to 0, the
* &struct mm_struct is freed.
*/
atomic_t mm_count; //使用计数器
atomic_long_t nr_ptes; /* PTE page table pages */ //进程页表数
#if CONFIG_PGTABLE_LEVELS > 2
atomic_long_t nr_pmds; /* PMD page table pages */
#endif
int map_count; /* number of VMAs */ //VMA的个数
spinlock_t page_table_lock; /* Protects page tables and some counters */
struct rw_semaphore mmap_sem;
struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung
* together off init_mm.mmlist, and are protected
* by mmlist_lock
*/
unsigned long hiwater_rss; /* High-watermark of RSS usage */
unsigned long hiwater_vm; /* High-water virtual memory usage */
unsigned long total_vm; /* Total pages mapped */ //进程地址空间的页数
unsigned long locked_vm; /* Pages that have PG_mlocked set */ //锁住的页数,不能换出
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long data_vm; /* VM_WRITE & ~VM_SHARED & ~VM_STACK */ //数据段内存的页数
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE & ~VM_STACK */ //可执行内存映射的页数
unsigned long stack_vm; /* VM_STACK */ //用户态堆栈的页数
unsigned long def_flags;
unsigned long start_code, end_code, start_data, end_data; //代码段,数据段等的地址
unsigned long start_brk, brk, start_stack; //堆栈段的地址,start_stack表示用户态堆栈的起始地址,brk为堆的当前最后地址
unsigned long arg_start, arg_end, env_start, env_end; //命令行参数的地址,环境变量的地址
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
/*
* Special counters, in some configurations protected by the
* page_table_lock, in other configurations by being atomic.
*/
struct mm_rss_stat rss_stat;
struct linux_binfmt *binfmt;
cpumask_var_t cpu_vm_mask_var;
/* Architecture-specific MM context */
mm_context_t context;
unsigned long flags; /* Must use atomic bitops to access the bits */
struct core_state *core_state; /* coredumping support */
#ifdef CONFIG_MEMBARRIER
atomic_t membarrier_state;
#endif
#ifdef CONFIG_AIO
spinlock_t ioctx_lock;
struct kioctx_table __rcu *ioctx_table;
#endif
#ifdef CONFIG_MEMCG
/*
* "owner" points to a task that is regarded as the canonical
* user/owner of this mm. All of the following must be true in
* order for it to be changed:
*
* current == mm->owner
* current->mm != mm
* new_owner->mm == mm
* new_owner->alloc_lock is held
*/
struct task_struct __rcu *owner;
#endif
struct user_namespace *user_ns;
/* store ref to file /proc/<pid>/exe symlink points to */
struct file __rcu *exe_file;
#ifdef CONFIG_MMU_NOTIFIER
struct mmu_notifier_mm *mmu_notifier_mm;
#endif
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && !USE_SPLIT_PMD_PTLOCKS
pgtable_t pmd_huge_pte; /* protected by page_table_lock */
#endif
#ifdef CONFIG_CPUMASK_OFFSTACK
struct cpumask cpumask_allocation;
#endif
#ifdef CONFIG_NUMA_BALANCING
/*
* numa_next_scan is the next time that the PTEs will be marked
* pte_numa. NUMA hinting faults will gather statistics and migrate
* pages to new nodes if necessary.
*/
unsigned long numa_next_scan;
/* Restart point for scanning and setting pte_numa */
unsigned long numa_scan_offset;
/* numa_scan_seq prevents two threads setting pte_numa */
int numa_scan_seq;
#endif
/*
* An operation with batched TLB flushing is going on. Anything that
* can move process memory needs to flush the TLB when moving a
* PROT_NONE or PROT_NUMA mapped page.
*/
atomic_t tlb_flush_pending;
#ifdef CONFIG_ARCH_WANT_BATCHED_UNMAP_TLB_FLUSH
/* See flush_tlb_batched_pending() */
bool tlb_flush_batched;
#endif
struct uprobes_state uprobes_state;
#ifdef CONFIG_HUGETLB_PAGE
atomic_long_t hugetlb_usage;
#endif
struct work_struct async_put_work;
#if IS_ENABLED(CONFIG_HMM)
/* HMM needs to track a few things per mm */
struct hmm *hmm;
#endif
} __randomize_layout;
struct vm_area_struct
用于描述进程地址空间中的一段虚拟区域,每一个VMA都对应一个struct vm_area_struct。
/*
* This struct defines a memory VMM memory area. There is one of these
* per VM-area/task. A VM area is any part of the process virtual memory
* space that has a special rule for the page-fault handlers (ie a shared
* library, the executable area etc).
*/
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */ //起始地址
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */ //结束地址,区间中不包含结束地址
/* linked list of VM areas per task, sorted by address */ //按起始地址排序的链表
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb; //红黑树节点
/*
* Largest free memory gap in bytes to the left of this VMA.
* Either between this VMA and vma->vm_prev, or between one of the
* VMAs below us in the VMA rbtree and its ->vm_prev. This helps
* get_unmapped_area find a free area of the right size.
*/
unsigned long rb_subtree_gap;
/* Second cache line starts here. */
struct mm_struct *vm_mm; /* The address space we belong to. */
pgprot_t vm_page_prot; /* Access permissions of this VMA. */
unsigned long vm_flags; /* Flags, see mm.h. */
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap interval tree.
*/
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_chain; /* Serialized by mmap_sem &
* page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units */
struct file * vm_file; /* File we map to (can be NULL). */ //指向文件的一个打开实例
void * vm_private_data; /* was vm_pte (shared mem) */
atomic_long_t swap_readahead_info;
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
struct vm_userfaultfd_ctx vm_userfaultfd_ctx;
} __randomize_layout;
关系图来了:
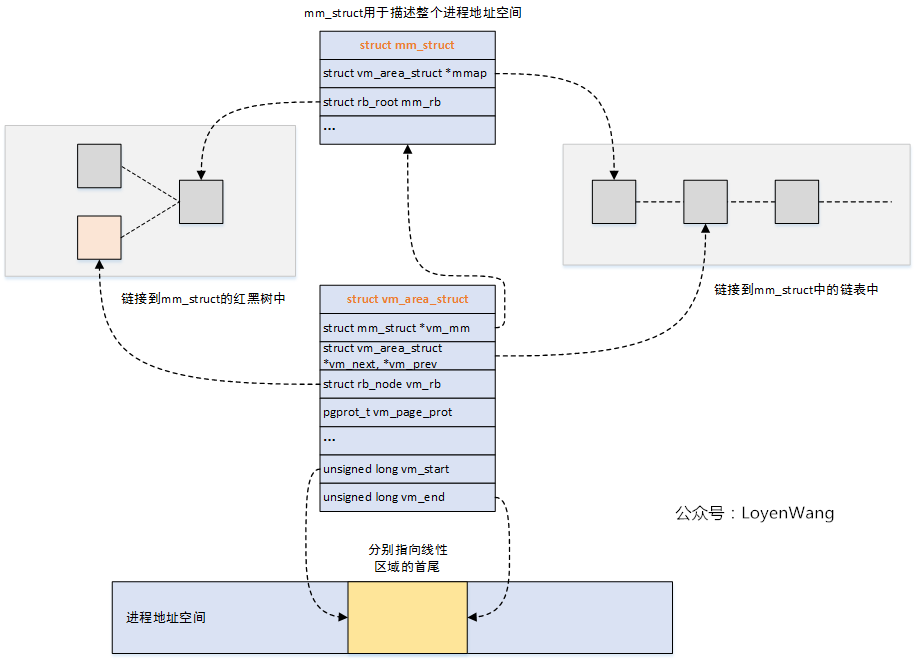
是不是有点眼熟?这个跟内核中的vmap机制很类似。
宏观的看一下进程地址空间中的各个VMA:
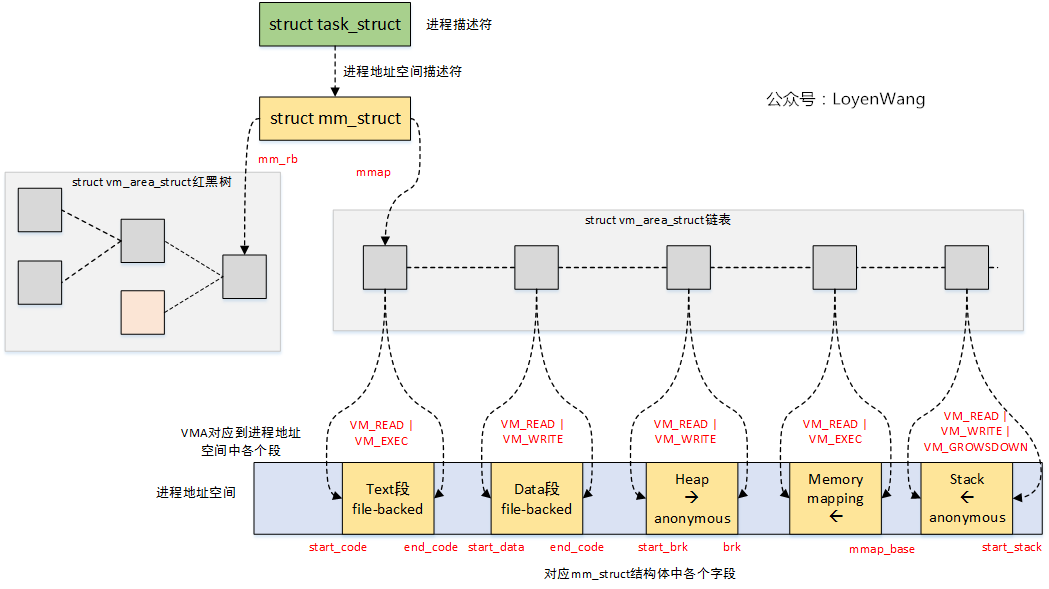
针对VMA的操作,有如下接口:
/* VMA的查找 */
/* Look up the first VMA which satisfies addr < vm_end, NULL if none. */
extern struct vm_area_struct * find_vma(struct mm_struct * mm, unsigned long addr); //查找第一个满足addr < vm_end的VMA块
extern struct vm_area_struct * find_vma_prev(struct mm_struct * mm, unsigned long addr,
struct vm_area_struct **pprev); //与find_vma功能类似,不同之处在于还会返回VMA链接的前一个VMA;
static inline struct vm_area_struct * find_vma_intersection(struct mm_struct * mm, unsigned long start_addr, unsigned long end_addr); //查找与start_addr~end_addr区域有交集的VMA
/* VMA的插入 */
extern int insert_vm_struct(struct mm_struct *, struct vm_area_struct *); //插入VMA到红黑树中和链表中
/* VMA的合并 */
extern struct vm_area_struct *vma_merge(struct mm_struct *,
struct vm_area_struct *prev, unsigned long addr, unsigned long end,
unsigned long vm_flags, struct anon_vma *, struct file *, pgoff_t,
struct mempolicy *, struct vm_userfaultfd_ctx); //将VMA与附近的VMA进行融合操作
/* VMA的拆分 */
extern int split_vma(struct mm_struct *, struct vm_area_struct *,
unsigned long addr, int new_below); //将VMA以addr为界线分成两个VMA
上述的操作基本上也就是针对红黑树的操作。
3. malloc
malloc大家都很熟悉,那么它是怎么与底层去交互并申请到内存的呢?
图来了:
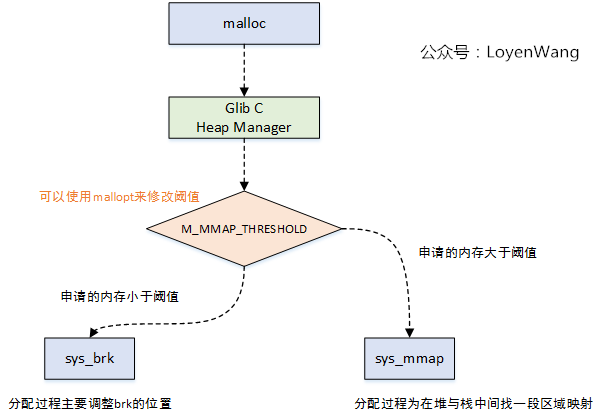
如图所示,malloc最终会调到底层的sys_brk函数和sys_mmap函数,在分配小内存时调用sys_brk函数,动态的调整进程地址空间中的brk位置;在分配大块内存时,调用sys_mmap函数,在堆和栈之间找到一片区域进行映射处理。
先来看sys_brk函数,通过SYSCALL_DEFINE1来定义,整体的函数调用流程如下:
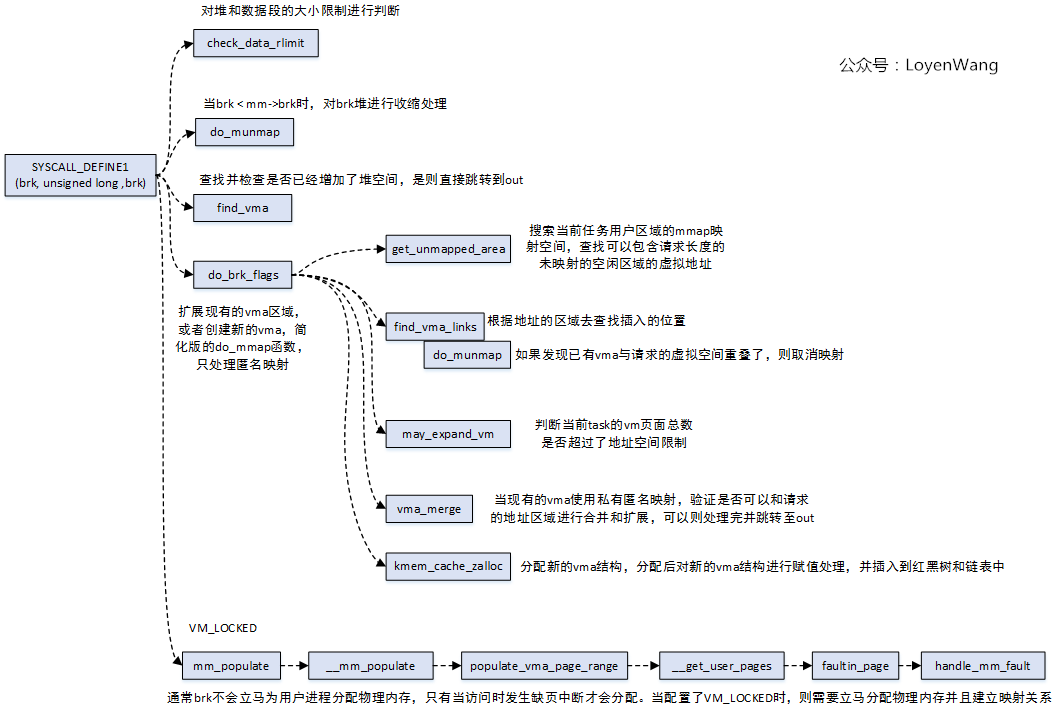
从函数的调用过程中可以看出有不少操作是针对vma的,那么结合起来的效果图如下:
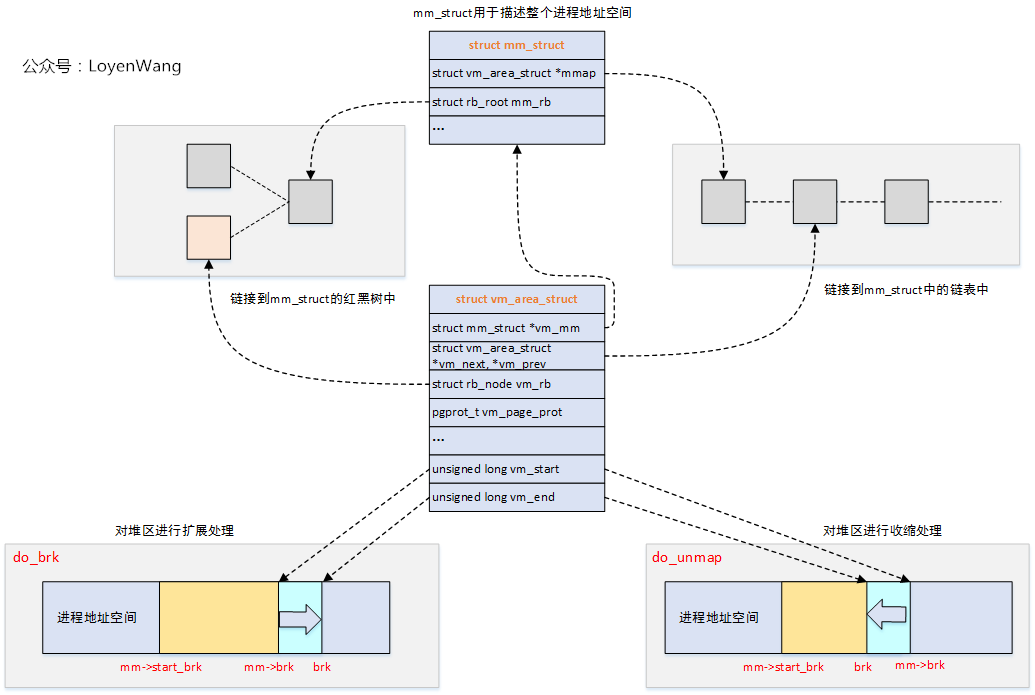
整个过程看起来就比较清晰和简单了,每个进程都用struct mm_struct来描述自身的进程地址空间,这些空间都是一些vma区域,通过一个红黑树和链表来管理。因此针对malloc的处理,会去动态的调整brk的位置,具体的大小则由struct vm_area_struct结构中的vm_start ~ vm_end来指定。在实际过程中,会根据请求分配区域是否与现有vma重叠的情况来进行处理,或者重新申请一个vma来描述这段区域,并最终插入到红黑树和链表中。
完成这段申请后,只是开辟了一段区域,通常还不会立马分配物理内存,物理内存的分配会发生在访问时出现缺页异常后再处理,这个后续也会有文章来进一步分析。
4. mmap
mmap用于内存映射,也就是将一段区域映射到自己的进程地址空间中,分为两种:
- 文件映射: 将文件区域映射到进程空间,文件存放在存储设备上;
- 匿名映射:没有文件对应的区域映射,内容存放在物理内存上;
同时,针对其他进程是否可见,又分为两种:
- 私有映射:将数据源拷贝副本,不影响其他进程;
- 共享映射:共享的进程都能看到;
根据排列组合,就存在以下几种情况了:
- 私有匿名映射: 通常分配大块内存时使用,堆,栈,bss段等;
- 共享匿名映射:常用于父子进程间通信,在内存文件系统中创建
/dev/zero设备; - 私有文件映射:常用的比如动态库加载,代码段,数据段等;
- 共享文件映射:常用于进程间通信,文件读写等;
常见的prot权限和flags如下:
#define PROT_READ 0x1 /* page can be read */
#define PROT_WRITE 0x2 /* page can be written */
#define PROT_EXEC 0x4 /* page can be executed */
#define PROT_SEM 0x8 /* page may be used for atomic ops */
#define PROT_NONE 0x0 /* page can not be accessed */
#define PROT_GROWSDOWN 0x01000000 /* mprotect flag: extend change to start of growsdown vma */
#define PROT_GROWSUP 0x02000000 /* mprotect flag: extend change to end of growsup vma */
#define MAP_SHARED 0x01 /* Share changes */
#define MAP_PRIVATE 0x02 /* Changes are private */
#define MAP_TYPE 0x0f /* Mask for type of mapping */
#define MAP_FIXED 0x10 /* Interpret addr exactly */
#define MAP_ANONYMOUS 0x20 /* don't use a file */
#define MAP_GROWSDOWN 0x0100 /* stack-like segment */
#define MAP_DENYWRITE 0x0800 /* ETXTBSY */
#define MAP_EXECUTABLE 0x1000 /* mark it as an executable */
#define MAP_LOCKED 0x2000 /* pages are locked */
#define MAP_NORESERVE 0x4000 /* don't check for reservations */
#define MAP_POPULATE 0x8000 /* populate (prefault) pagetables */
#define MAP_NONBLOCK 0x10000 /* do not block on IO */
#define MAP_STACK 0x20000 /* give out an address that is best suited for process/thread stacks */
#define MAP_HUGETLB 0x40000 /* create a huge page mapping */
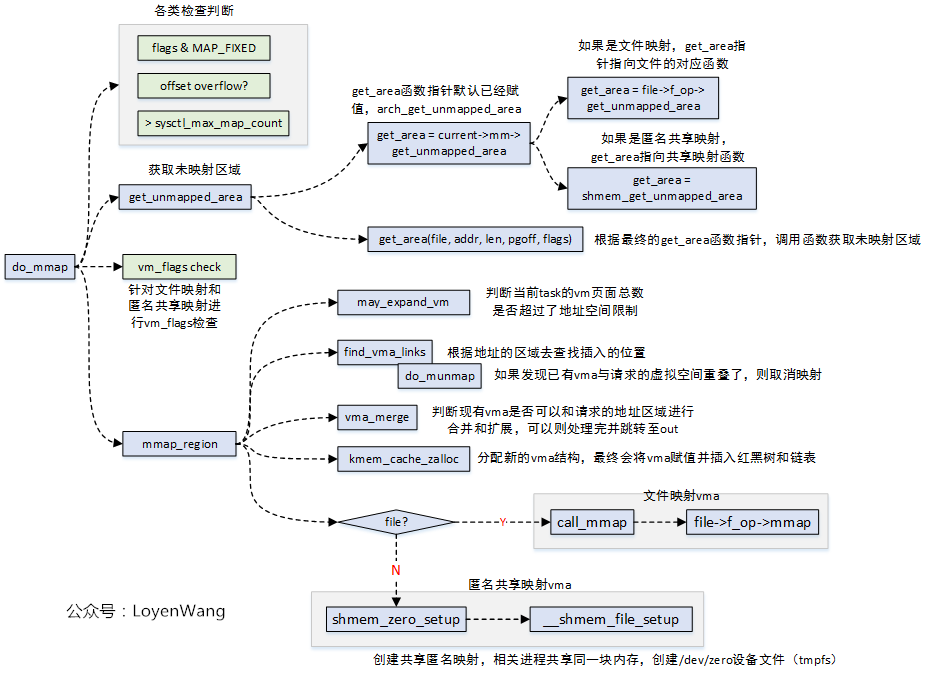
mmap的操作,最终会调用到do_mmap函数,最后来一张调用图:
目录
1. 前言
2. do_mmap函数说明
总体参数说明
prot参数说明
flags参数说明
file参数说明
3. 映射类型
4. do_mmap
|- -根据flags和prot作边界处理
|- -根据flags和prot来修正vm_flags标志
|- -mmap_region
5. 小结
参考文档
1. 前言
本专题我们开始学习内存管理部分,本文为进程地址空间的学习笔记。本文主要参考了《奔跑吧, Linux内核》、ULA、ULK的相关内容。
mmap/munmap接口是用户空间最常用的一个系统调用接口,主要用于:用户空间分配内存、读写大文件、链接动态库文件,多进程间共享内存。mmap最终底层调用的的内核函数是do_mmap,本文主要介绍do_mmap的执行过程。
kernel版本:5.10
平台:arm64
2. do_mmap函数说明
unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot, unsigned long flags,
unsigned long pgoff, unsigned long *populate, struct list_head *uf);
1
2
3
总体参数说明
file/pgoff
如果新的线性区vma将把一个文件映射到内存,则使用文件描述符指针file和文件偏移量pgoff,通过file参数可以看出是否与文件关联,用以区分匿名映射和文件映射
addr:
指定映射到进程地址空间的起始地址,一般设置为null, 让内核选择一个合适的地址
len:
线性地址区间的长度
prot:
指定这个线性区所包含的访问权限
flags:
设置内存映射的属性,如共享映射、私有映射等
prot参数说明
指定这个线性区所包含的访问权限,它最终转换为页表项pte的权限标志
//include/uapi/asm-generic/mman-common.h
#define PROT_READ 0x1 /* page can be read */
#define PROT_WRITE 0x2 /* page can be written */
#define PROT_EXEC 0x4 /* page can be executed */
#define PROT_SEM 0x8 /* page may be used for atomic ops */
#define PROT_NONE 0x0 /* page can not be accessed */
#define PROT_GROWSDOWN 0x01000000 /* mprotect flag: extend change to start of growsdown vma */
#define PROT_GROWSUP 0x02000000 /* mprotect flag: extend change to end of growsup vma *
1
2
3
4
5
6
7
8
flags参数说明
设置内存映射的属性,如共享映射、私有映射等
//include/uapi/asm-generic/mman-common.h
/* 0x01 - 0x03 are defined in linux/mman.h */
#define MAP_TYPE 0x0f /* Mask for type of mapping (OSF/1 is _wrong_) */
#define MAP_FIXED 0x100 /* Interpret addr exactly */
#define MAP_ANONYMOUS 0x10 /* don't use a file */
/* not used by linux, but here to make sure we don't clash with OSF/1 defines */
#define _MAP_HASSEMAPHORE 0x0200
#define _MAP_INHERIT 0x0400
#define _MAP_UNALIGNED 0x0800
/* These are linux-specific */
#define MAP_GROWSDOWN 0x01000 /* stack-like segment */
#define MAP_DENYWRITE 0x02000 /* ETXTBSY */
#define MAP_EXECUTABLE 0x04000 /* mark it as an executable */
#define MAP_LOCKED 0x08000 /* lock the mapping */
#define MAP_NORESERVE 0x10000 /* don't check for reservations */
#define MAP_POPULATE 0x20000 /* populate (prefault) pagetables */
#define MAP_NONBLOCK 0x40000 /* do not block on IO */
#define MAP_STACK 0x80000 /* give out an address that is best suited for process/thread stacks */
#define MAP_HUGETLB 0x100000 /* create a huge page mapping */
#define MAP_FIXED_NOREPLACE 0x200000/* MAP_FIXED which doesn't unmap underlying mapping *
//include/uapi/linux/mman.h
#define MAP_SHARED 0x01 /* Share changes */
#define MAP_PRIVATE 0x02 /* Changes are private */
#define MAP_SHARED_VALIDATE 0x03 /* share + validate extension flags */
1
2
3
4
file参数说明
通过file参数可以看出是否与文件关联,用以区分匿名映射和文件映射
在Linux中映射可以分为两种:
匿名映射:没有映射对应的相关文件,匿名映射的内存区域的内容会初始化为0;
文件映射:映射和实际文件相关联,通常把文件内容映射到进程地址空间,这样应用就可以通过操作进程地址空间读写文件
3. 映射类型
根据文件关联性和映射区域是否共享等属性,mmap映射类型分为4类:
私有匿名映射(fd==-1且flags=MAP_ANONYMOUS | MAP_PRIVATE)
创建的mmap映射是私有匿名映射
用途:在glibc中分配大块内存,需要分配的内存大于MMAP_THRESHOLD(128kb),glibc会使用mmap代替brk来分配内存
共享匿名映射(fd==-1且flags=MAP_ANONYMOUS | MAP_SHARED)
用途:让相关进程共享一块内存区域,通常用于父子进程之间通信
私有文件映射(fd为文件句柄,flags=MAP_PRIVATE)
用途:加载动态共享库
共享文件映射(fd为文件句柄,flags=MAP_SHARED)
如果prot参数指定了PROT_WRITE,那么打开文件时需要指定O_RDWR标志位。
用途:
(1)读写文件
文件映射到进程地址空间,同时对映射的内容作了修改,内核的回写机制最终会将修改的内容同步到磁盘中。
(2)进程间通信
多个进程同时映射到一个相同的文件,就实现了多个进程的共享内存通信。
4. do_mmap
do_mmap(file, addr,len, prot, flags, pgoff, populate, uf)
|--根据flags和prot作边界处理
|--addr = get_unmapped_area(file, addr, len, pgoff, flags)
| //组合新线性区标志
|--vm_flags = calc_vm_prot_bits(prot, pkey) | calc_vm_flag_bits(flags)|
| mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC
| //判断是否超过进程锁住不能换出的页数的阀值rlim_cur
|--mlock_future_check(mm, vm_flags, len)
|--根据flags和prot来修正vm_flags标志
|--addr = mmap_region(file, addr, len, vm_flags, pgoff, uf)
do_mmap为addr,addr+len的区间查找或分配一个vma, 并对其进行初始化
get_unmapped_area:在进程地址空间中寻找一个可以使用的线性地址区间,它返回一段没有映射过的空间的起始地址
vm_flags:组合新线性区标志
mlock_future_check:判断是否超过进程锁住不能换出的页数的阀值rlim_cur
根据flags和prot来修正vm_flags标志
mmap_region:为addr,addr+len的区间分配一个vma, 并对其进行初始化
|- -根据flags和prot作边界处理
根据flags和prot作边界处理
| //应用假定PROT_READ隐含PROT_EXEC,一种情况除外:如果文件系统以noexec方式mount, 此假定不成立
|--if ((prot & PROT_READ) && (current->personality & READ_IMPLIES_EXEC))
| if (!(file && path_noexec(&file->f_path)))
| prot |= PROT_EXEC
|--if (flags & MAP_FIXED_NOREPLACE)
| flags |= MAP_FIXED
|--if (!(flags & MAP_FIXED))
| addr = round_hint_to_min(addr)
|--if ((pgoff + (len >> PAGE_SHIFT)) < pgoff)//overflow处理
| return -EOVERFLOW
|--if (mm->map_count > sysctl_max_map_count) //Too many mappings
| return -ENOMEM
|- -根据flags和prot来修正vm_flags标志
根据flags和prot来修改vm_flags标志
|-------//>>>>>>文件映射,将请求内存的种类(flags中指定)与打开文件时指定的标志进行比较
|--if (file)
| struct inode *inode = file_inode(file)
| file_mmap_ok(file, inode, pgoff, len)
| switch (flags & MAP_TYPE)
| case MAP_SHARED: /*共享映射*/
| /*如果请求的是共享可写内存映射,检查文件是为写入而不是追加模式打开*/
| if (IS_APPEND(inode) && (file->f_mode & FMODE_WRITE))
| return -EACCES
| /*如果请求的是共享内存映射,检查文件上没有强制锁*/
| if (locks_verify_locked(inode))
| return -EAGAIN
| vm_flags |= VM_SHARED | VM_MAYSHARE;
| /*如果是不可写共享内存映射,VM_MAYWRITE,VM_SHARED清零*/
| if (!(file->f_mode & FMODE_WRITE))
| vm_flags &= ~(VM_MAYWRITE | VM_SHARED)
| case MAP_PRIVATE: /*私有映射*/
| /*任何映射种类,都要检查文件是为读操作而打开*/
| if (!(file->f_mode & FMODE_READ))
| return -EACCES;
|------//>>>>>>> 匿名映射
|--else
| switch (flags & MAP_TYPE) {
| case MAP_SHARED:
| if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP))
| return -EINVAL
| vm_flags |= VM_SHARED | VM_MAYSHARE;
| case MAP_PRIVATE:
| pgoff = addr >> PAGE_SHIFT;
| /*Set 'VM_NORESERVE' if we should not account for the memory use of this mapping*/
|--if (flags & MAP_NORESERVE)
vm_flags |= VM_NORESERVE|- -mmap_region
mmap_region(file, addr, len, vm_flags, pgoff, uf)
| //Check against address space limit
|--may_expand_vm(mm, vm_flags, len >> PAGE_SHIFT)
|--munmap_vma_range(mm, addr, len, &prev, &rb_link, &rb_parent, uf)
|--accountable_mapping(file, vm_flags)
| //是否可以扩展旧的vma,如果不能则分配新的
|--vma_merge(mm, prev, addr,addr+len,vm_flags,...)
| //分配一个新的vma
|--vma = vm_area_alloc(mm)
| //初始化vma
|--vma->vm_start = addr;
| vma->vm_end = addr + len;
| vma->vm_flags = vm_flags;
| vma->vm_page_prot = vm_get_page_prot(vm_flags);
| vma->vm_pgoff = pgoff;
|-------//>>>>>>>文件映射
|--if (file)
| if (vm_flags & VM_DENYWRITE)//映射的文件不允许写入
| deny_write_access(file)//排除常规的文件操作
| if (vm_flags & VM_SHARED)
| mapping_map_writable(file->f_mapping)//共享文件映射允许其他进程可见, 标记文件为可写
| //对映射文件执行mmap方法,大多数文件系统为generic_file_mmap,对于f2fs为f2fs_file_mmap
| call_mmap(file, vma)
| |--file->f_op->mmap(file, vma);
| addr = vma->vm_start
| vm_flags = vma->vm_flags
|-------//>>>>>>共享匿名映射
| else if (vm_flags & VM_SHARED)
| shmem_zero_setup(vma) //指定映射文件是/dev/zero
|------//>>>>>>私有匿名映射
| else
| vma_set_anonymous(vma) //设置vma->vm_ops为null,vma->vm_ops往往是匿名映射和文件映射的区分标志?
|--vma_link(mm, vma, prev, rb_link, rb_parent)//将申请的新vma加入mm中的vma链表
\--vma_set_page_prot(vma);//Update vma->vm_page_prot to reflect vma->vm_flags
mmap_region为addr,addr+len的区间分配一个vma, 并对其进行初始化
may_expand_vm:检查调用进程是否在扩展新的地址空间后,是否会超过进程空间限制值
munmap_vma_range:unmap覆盖addr开始len大小的所有vma的页面
accountable_mapping:Private writable mapping: check memory availability?
vma_merge:查询以addr为起始地址,大小为len的区间是否可以和已有的vma进行合并,如果可以合并,返回合并后的vma
vm_area_alloc: 如果vma_merge不能合并,将调用此函数分配新的vma
call_mmap:底层调用了file->f_op->mmap回调,对映射文件执行mmap方法,大多数文件系统为generic_file_mmap,对于f2fs为f2fs_file_mmap,f2fs_file_mmap会设置vma->vm_ops = &f2fs_file_vm_ops,其中的f2fs_file_vm_ops->fault就是_do_fault文件映射缺页中断时执行的,用于将文件内容读到page
vma_link:将申请的新vma加入mm中的vma链表
vma_set_page_prot: 根据vma->vm_flags更新vma->vm_page_prot
5. 小结
https://blog.csdn.net/lggbxf/article/details/94012088
通过分析mmap的源码我们发现在调用mmap()的时候仅仅申请一个vm_area_struct来建立文件与虚拟内存的映射,并没有建立虚拟内存与物理内存的映射。Linux并不在调用mmap()时就为进程分配物理内存空间,直到下次真正访问地址空间时发现数据不存在于物理内存空间时,触发Page Fault即缺页中断,Linux才会将缺失的Page换入内存空间。
参考文档
————————————————
版权声明:本文为CSDN博主「HZero.chen」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/jasonactions/article/details/114652007
目录
1. 前言
2. SYSCALL_DEFINE1(brk, unsigned long, brk)
|- -__do_munmap
|- -do_brk_flags
|- - -get_unmapped_area
|- - -munmap_vma_range
|- -mm_populate
|- - -populate_vma_page_range
|- - - -__get_user_pages
|- - - - - follow_page_mask
|- - - - - faultin_page
参考文档
1. 前言
本专题我们开始学习内存管理部分,本文为进程地址空间的学习笔记。本文主要参考了《奔跑吧, Linux内核》、ULA、ULK的相关内容。
malloc函数是C函数库封装的一个核心函数,C函数库会做一些处理后调用系统调用brk,如果把malloc想想成零售,brk就是代理商。malloc函数的实现为用户进程维护一个本地小仓库,当进程需要使用更多的内存时就向这个小仓库要货,小仓库存量不足时就通过代理商brk向内核批发。
下面是在学习过程中记录的几个问题:
Q: malloc函数返回的内存是否马上分配物理内存?
A: 在真正使用这段内存时才通过缺页中断来分配
Q: 实际使用时,malloc分配100字节,实际上内核分配多少?
A: 按页对齐,最少分配一个页
Q:如果两个进程的地址相同,会有冲突吗?
A:不会冲突,每个进程维护自己的页表,两个相同的地址分别属于不同的VMA
Q:vm_normal_page函数返回什么样的页面?
只返回normal mapping页面的page,它们可以被回收或合并,其它特定页面不返回
Q:get_user_page函数的作用?
A: 为用户空间的地址创建页表,分配页面
Q:follow_page函数的作用?
A:根据虚拟地址返回物理页面
kernel版本:5.10
平台:arm64
2. SYSCALL_DEFINE1(brk, unsigned long, brk)
如下为进程地址空间的灵活布局方式的一个示例, 本文以此种布局进行介绍(区别于传统布局):
brk系统调用主要实现在mm/mmap.c中
SYSCALL_DEFINE1(brk, unsigned long, brk)
| //动态堆分配区的新边界地址
|--newbrk = PAGE_ALIGN(brk)
| //动态堆分配区当前边界地址
|--oldbrk = PAGE_ALIGN(mm->brk)
|-------//>>>>>>情形1:释放堆内存
| //如果动态堆分配区新的边界地址小于当前边界地址,表示进程请求释放堆空间
|--if (brk <= mm->brk)
| //更新动态堆分配区当前边界地址为新边界地址
| mm->brk = brk
| //unmap [newbrk,oldbrk]空间
| __do_munmap(mm, newbrk, oldbrk-newbrk, &uf, true)
| goto success
|------//>>>>>>情形2:申请堆内存
|--next = find_vma(mm, oldbrk)
|--if (next && newbrk + PAGE_SIZE > vm_start_gap(next))
| goto out;
| //以老边界oldbrk开始,以(newbrk-oldbrk)大小分配vma
|-- if (do_brk_flags(oldbrk, newbrk-oldbrk, 0, &uf) < 0)
| goto out;
| //分配成功后更新动态分配区当前边界
|--mm->brk = brk
|--populate = newbrk > oldbrk && (mm->def_flags & VM_LOCKED) != 0
\--if (populate)
mm_populate(oldbrk, newbrk - oldbrk)
newbrk 为动态分配区的新边界地址,是用户进程要求分配内存大小与当前动态分配区底部边界地址的和。而mm_struct有个数据成员brk用于记录动态分配区当前的底部边界地址,它是动态分配区起始地址与当前使用的动态分配区大小的和
oldbrk记录了动态分配区当前底部边界地址
如果动态分配区新的边界地址小于当前边界地址,表示进程请求释放堆内存,则调用__do_munmap执行空间释放
如果动态分配区新的边界地址大于当前边界地址,就是申请堆内存,以动态分配区的当前边界地址oldbrk开始查找是否有一块vma与[oldbrk,newbrk]的区域有重叠(find_vma加上下面的代码判断等价于find_vma_intersection),如果有重叠说明以老边界oldbrk开始的地址空间已经在使用了,直接将老边界返回给用户空间,退出函数?
do_brk_flags以老边界oldbrk开始分配vma,覆盖newbrk-oldbrk大小的空间
mm_populate:应用可能会使用mlokall()系统调用把进程中全部的进程虚拟空间加锁,防止内存被交换,此时mm->def_flags会置位VM_LOCKED, 此时会调用mm_populate立刻分配物理内存并建立映射关系
|- -__do_munmap
__do_munmap(mm, newbrk, oldbrk-newbrk, &uf, true)//start为newbrk,len为oldbrk-newbrk
|--vma = find_vma(mm, start)
|--prev = vma->vm_prev
|--if (start > vma->vm_start)//start地址位于vma线性区
| __split_vma(mm, vma, start, 0) //如下图,拆分成vma和new1两个线性区
|--last = find_vma(mm, end)
|--if (last && end > last->vm_start)//end位于last线性区
| __split_vma(mm, last, end, 1)//如下图,拆分成last和new2两个线性区
|--unlock any mlock()ed ranges before detaching vmas
|--detach_vmas_to_be_unmapped(mm, vma, prev, end)
|--unmap_region(mm, vma, prev, start, end)//删除与线性区对应的页表项并释放相应的页框
\--remove_vma_list(mm, vma) //vma上挂载者所有的待删除线性区
1
__do_munmap就是删除用户空间地址newbrk到newbrk~oldbrk的vma线性区,并删除vma线性区对应的页表项,释放相应的页
detach_vmas_to_be_unmapped:vma上挂载着所有的待删除线性区,从内存描述符的mm_rb删除从vma开始(图示new1)的线性区,一直删除到end地址(图示end)所在的线性区
unmap_region:删除vma开始的所有的待删除线性区对应的页表项并释放相应的页框
remove_vma_list: 删除vma开始的所有的待删除线性区,此处根据线性区回调执行一些预处理,然后释放其占用的slab缓存
unmap_region(mm, vma, prev, start, end) //删除vma开始的所有的待删除线性区对应的页表项并释放相应的页框
|--lru_add_drain()
|--tlb_gather_mmu(&tlb, mm, start, end)
|--update_hiwater_rss(mm)
|--unmap_vmas(&tlb, vma, start, end)
| |--for ( ; vma && vma->vm_start < end_addr; vma = vma->vm_next)
| unmap_single_vma(tlb, vma, start_addr, end_addr, NULL)
|--free_pgtables(&tlb, vma,...)
|--tlb_finish_mmu(&tlb, start, end)
|--mm_tlb_flush_nested(tlb->mm) //刷新TLB
|--tlb_flush_mmu(tlb) // 释放page
|--tlb_flush_mmu_tlbonly(tlb)
|--tlb_flush_mmu_free(tlb)
unmap_region删除vma开始的所有的待删除线性区对应的页表项并释放相应的页框
unmap_vmas: 参数vma为要unmap的线性区链表的首个线性区,此处unmap线性区链表所覆盖的page,地址范围为start~end,主要是清空对应的pte页表项
free_pgtables: 因为删除了一些映射,会造成一个pte页表空闲的情况,回收这些页表所占的空间
tlb_finish_mmu: 结束unmap_region的工作,主要刷新了mmu, 释放了页框,tlb_flush_mmu_free的实现较为复杂(TODO)
unmap_single_vma(tlb, vma, start_addr, end_addr, NULL)//unmap一个线性区vma的所覆盖的所有page
|--unmap_page_range(tlb, vma, start, end, details) //unmap地址范围start~end的page
|--pgd = pgd_offset(vma->vm_mm, addr)
|--do {
next = pgd_addr_end(addr, end)
next = zap_p4d_range(tlb, vma, pgd, addr, next, details)
} while (pgd++, addr = next, addr != end)
1
2
3
4
5
6
7
unmap一个线性区vma的所覆盖的所有page
zap_p4d_range(tlb, vma, pgd, addr, next, details)
|--p4d = p4d_offset(pgd, addr)
|--do {
next = p4d_addr_end(addr, end)
next = zap_pud_range(tlb, vma, p4d, addr, next, details)
} while (p4d++, addr = next, addr != end)
zap_pud_range(tlb, vma, p4d, addr, next, details)
|--pud = pud_offset(p4d, addr)
|--do {
next = pud_addr_end(addr, end)
next = zap_pmd_range(tlb, vma, pud, addr, next, details)
} while (pud++, addr = next, addr != end)
1
2
3
4
5
6
zap_pmd_range(tlb, vma, pud, addr, next, details)
|--pmd = pmd_offset(pud, addr)
|--do {
next = pmd_addr_end(addr, end)
next = zap_pte_range(tlb, vma, pmd, addr, next, details)
} while (pmd++, addr = next, addr != end)
1
2
3
4
5
6
zap_pte_range(tlb, vma, pmd, addr, next, details)
|--start_pte = pte_offset_map_lock(mm, pmd, addr, &ptl)
|--pte = start_pte
|--do {
| pte_t ptent = *pte
| if (pte_present(ptent)) {//相应的页在主存中(pte有效,页面未回收)
| page = vm_normal_page(vma, addr, ptent)
| ptent = ptep_get_and_clear_full(mm, addr, pte,tlb->fullmm)//清空addr对应的pte
| if (!PageAnon(page))
| if (pte_dirty(ptent))//页面被修改过
| force_flush = 1
| set_page_dirty(page)
| if (pte_young(ptent)//页面被刚刚访问过
| mark_page_accessed(page)
| continue;
| }
|
| entry = pte_to_swp_entry(ptent)
| if (is_device_private_entry(entry)) {
| struct page *page = device_private_entry_to_page(entry);
| pte_clear_not_present_full(mm, addr, pte, tlb->fullmm)
| rss[mm_counter(page)]--
| page_remove_rmap(page, false)
| put_page(page)
| continue;
| }
|
| pte_clear_not_present_full(mm, addr, pte, tlb->fullmm)//清空addr对应的pte
| } while (pte++, addr += PAGE_SIZE, addr != end)
|--add_mm_rss_vec(mm, rss)
\--arch_leave_lazy_mmu_mode()
vm_normal_page根据pte来返回normal paging页面的struct page结构。
from:https://www.cnblogs.com/arnoldlu/p/8329283.html
一些特殊映射的页面是不会返回struct page结构的,这些页面不希望被参与到内存管理的一些活动中,如页面回收、页迁移和KSM等。
内核尝试用pte_mkspecial()宏来设置PTE_SPECIAL软件定义的比特位,主要用途有:
1.内核的零页面zero page
2.大量的驱动程序使用remap_pfn_range()函数来实现映射内核页面到用户空间。这些用户程序使用的VMA通常设置了(VM_IO|VM_PFNMAP|VM_DONTEXPAND|VM_DONTDUMP)
3.vm_insert_page()/vm_insert_pfn()映射内核页面到用户空间
vm_normal_page()函数把page页面分为两阵营,一个是normal page,另一个是special page。
normal page通常指正常mapping的页面,例如匿名页面、page cache和共享内存页面等。
special page通常指不正常mapping的页面,这些页面不希望参与内存管理的回收或者合并功能,比如:
1.VM_IO:为IO设备映射
2.VM_PFN_MAP:纯PFN映射
3.VM_MIXEDMAP:固定映射
|- -do_brk_flags
如果不是释放空间,而是申请堆空间则调用do_brk_flags
do_brk_flags(addr, len, flags, uf)
|--mapped_addr = get_unmapped_area(NULL, addr, len, 0, MAP_FIXED)
|--munmap_vma_range(mm, addr, len, &prev, &rb_link, &rb_parent, uf)
|--vma = vma_merge(mm, prev, addr, addr + len, flags,
| NULL, NULL, pgoff, NULL, NULL_VM_UFFD_CTX)
| //create a vma struct for an anonymous mapping
|--vma = vm_area_alloc(mm)
|--vma_set_anonymous(vma) //vma->vm_ops = NULL
|--vma->vm_start = addr //初始化vma
| vma->vm_end = addr + len
| vma->vm_pgoff = pgoff
| vma->vm_flags = flags
| //vm_get_page_prot通过flags获取pte的相关属性
| vma->vm_page_prot = vm_get_page_prot(flags)
| vma_link(mm, vma, prev, rb_link, rb_parent)
\--mm->total_vm += len >> PAGE_SHIFT
mm->data_vm += len >> PAGE_SHIFT
do_brk_flags以addr查找或创建一个vma并插入到rb_tree
get_unmapped_area:在进程地址空间中寻找一个可以使用的线性地址区间,它返回一段没有映射过的空间的起始地址
munmap_vma_range:遍历用户红黑树中的VMA,然后根据addr来查找最合适插入红黑树的节点, rb_link指针指向最合适节点的rb_left或rb_right指针本身的地址
vma_merge:检查有没有办法合并addr附近的vma , 如果有则直接合并,并goto out;
vm_area_alloc: 如果不能合并则创建一个新的vma,新的vma的地址为[addr, addr+len]
|- - -get_unmapped_area
get_unmapped_area(NULL, addr, len, 0, MAP_FIXED)
|--arch_get_unmapped_area_topdown(NULL, addr, len, 0, MAP_FIXED)
|--mmap_end = arch_get_mmap_end(addr) //为TASK_SIZE
1
2
3
在load elf文件时会通过setup_new_exec->arch_pick_mmap_layout来初始化mm->get_unmapped_area,对于arm64就是arch_get_unmapped_area_topdown
|- - -munmap_vma_range
munmap_vma_range(mm, addr, len, &prev, &rb_link, &rb_parent, uf)//addr为start,rb_link为link,rb_parent为parent
|--while (find_vma_links(mm, start, start + len, pprev, link, parent))
do_munmap(mm, start, len, uf)
1
2
3
find_vma_links:遍历用户红黑树中的VMA,然后根据addr来查找最合适插入红黑树的节点, rb_link指针指向最合适节点的rb_left或rb_right指针本身的地址,如果返回0表示找到最合适插入的节点
如果find_vma_links返回-NOMEM,表示和现有的VMA重叠,会调用do_munmap释放这段重叠的空间
|- -mm_populate
mm_populate(addr, len)
|--__mm_populate(addr, len, 1)
|--for (nstart = start; nstart < end; nstart = nend) {
/*查找vma*/
vma = find_vma(mm, nstart)
if (!vma || vma->vm_start >= end)
break;
nend = min(end, vma->vm_end)
if (nstart < vma->vm_start)
nstart = vma->vm_start
/*制造缺页异常并完成地址映射*/
ret = populate_vma_page_range(vma, nstart, nend, &locked)
nend = nstart + ret * PAGE_SIZE
ret = 0
}
__mm_populate通过一个for循环遍历[addr,addr+len]区间的所有vma,通过populate_vma_page_range对vma所描述的地址区间,通过人为制造缺页异常完成物理页面分配和地址映射。
|- - -populate_vma_page_range
populate_vma_page_range(vma,start, end, locked)
|--gup_flags = FOLL_TOUCH | FOLL_POPULATE | FOLL_MLOCK
|--if (vma->vm_flags & VM_LOCKONFAULT)
| gup_flags &= ~FOLL_POPULATE
|--if ((vma->vm_flags & (VM_WRITE | VM_SHARED)) == VM_WRITE)
| gup_flags |= FOLL_WRITE;
|--if (vma_is_accessible(vma))
| gup_flags |= FOLL_FORCE;
|--__get_user_pages(mm, start, nr_pages, gup_flags,NULL, NULL, locked)
gup_flags:设置分配掩码标志位
__get_user_pages:为进程地址空间分配物理内存并建立映射关系
|- - - -__get_user_pages
__get_user_pages(mm, start, nr_pages, gup_flags,NULL, NULL, locked)
|--do {
vma = find_extend_vma(mm, start);
page = follow_page_mask(vma, start, foll_flags, &ctx)
if (!page) //vma没有被分配物理内存,也没有创建映射
faultin_page(vma, start, &foll_flags, locked)
} while (nr_pages);
__get_user_pages为用户空间分配内存并创建映射
find_extend_vma: 查找新的vma的start相邻的vma,并将vma->start与新的vma的start比较,如果vma->start大于新的vma的 start,考虑将vma进行扩容到新的vma的start
follow_page_mask:查看vma是否已经被分配了物理内存,如果已经映射,返回page
faultin_page:如果vma没有映射,人为触发缺页中断,分配内存,建立映射
|- - - - - follow_page_mask
follow_page_mask(vma, address, flags, ctx)
| //处理巨页情况
|--page = follow_huge_addr(mm, address, flags & FOLL_WRITE)
| //通过地址找到当前进程页表的pgd目录项
|--pgd = pgd_offset(mm, address)
| //遍历p4d,Linux支持5级页表,arm64支持4级
|--follow_p4d_mask(vma, address, pgd, flags, ctx)
| //通过地址找到当前进程页表的p4d目录项
|--p4d = p4d_offset(pgdp, address)
| //遍历pud
|--follow_pud_mask(vma, address, p4d, flags, ctx)
| //通过地址找到当前进程页表的pud目录项
|--pud = pud_offset(p4dp, address)
| //遍历pmd
|--follow_pmd_mask(vma, address, pud, flags, ctx)
| //通过地址找到当前进程页表的pmd目录项
|--pmd = pmd_offset(pudp, address)
| //遍历pte
|--follow_page_pte(vma, address, pmd, flags, &ctx->pgmap)
follow_page_mask最终根据address和内存描述符返回normal page物理页面的struct page结构
follow_page_pte(vma, address, pmd, flags, &ctx->pgmap)
| //通过pmd和address获取pte页表项
|--ptep = pte_offset_map_lock(mm, pmd, address, &ptl)
|--pte = *ptep;
| //根据pte来返回normal paging物理页面的struct page结构
|--page = vm_normal_page(vma, address, pte)
|--if (!pte_present(pte)) //页表项无效
| if (likely(!(flags & FOLL_MIGRATION)))
| goto no_page;
| if (pte_none(pte)) //页表项为空
| goto no_page
| entry = pte_to_swp_entry(pte)
| if (!is_migration_entry(entry))
| goto no_page
| migration_entry_wait(mm, pmd, address);
| //处理设备映射
|--if (!page && pte_devmap(pte) && (flags & (FOLL_GET | FOLL_PIN)))
| *pgmap = get_dev_pagemap(pte_pfn(pte), *pgmap)
| if (*pgmap)
| page = pte_page(pte)
| //标记页面是活跃的,页面回收的核心辅助函数
|--if (flags & FOLL_TOUCH)
mark_page_accessed(page);
follow_page_pte根据pte返回normal paging物理页面的struct page结构,此page可能存在也可能不存在,如果不存在则通过下面的faultin_page来人为触发缺页中断
|- - - - - faultin_page
faultin_page(vma, start, &foll_flags, locked)
|--if (*flags & FOLL_WRITE)
| fault_flags |= FAULT_FLAG_WRITE;
| if (*flags & FOLL_REMOTE)
| fault_flags |= FAULT_FLAG_REMOTE;
| if (locked)
| fault_flags |= FAULT_FLAG_ALLOW_RETRY | FAULT_FLAG_KILLABLE;
| if (*flags & FOLL_NOWAIT)
| fault_flags |= FAULT_FLAG_ALLOW_RETRY | FAULT_FLAG_RETRY_NOWAIT;
| if (*flags & FOLL_TRIED)
| fault_flags |= FAULT_FLAG_TRIED;
|--handle_mm_fault(vma, address, fault_flags, NULL)
1
缺页异常
1. 概述
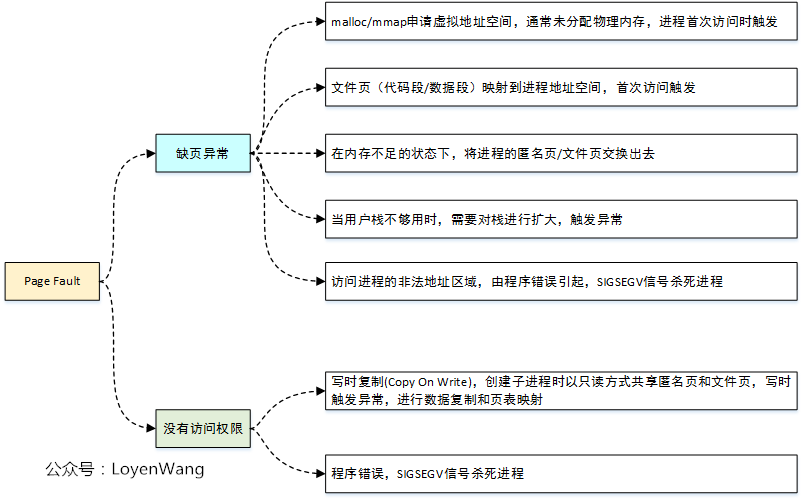
上篇文章分析到malloc/mmap函数中,内核实现只是在进程的地址空间建立好了vma区域,并没有实际的虚拟地址到物理地址的映射操作。这部分就是在Page Fault异常错误处理中实现的。
Linux内核中的Page Fault异常处理很复杂,涉及的细节也很多,malloc/mmap的物理内存映射只是它的一个子集功能,下图大概涵盖了出现Page Fault的情况:
下边就开始来啃啃硬骨头吧。
2. Arm64处理
目录
1. 前言
2. page fault的底层处理
3. el1_sync
|- -do_mem_abort
参考文档
1. 前言
本专题我们开始学习内存管理部分,本文为缺页中断处理相关学习笔记。本文主要参考了《奔跑吧, Linux内核》、ULA、ULK的相关内容。
Linux的缺页异常(page fault)必须区分两种情况:由编程错误引发的异常;由引用属于进程地址空间但尚未分配物理页框的页引起的异常。具体发生page fault的情况:
1.如果写地址落在VMA区域,且权限合法
访问地址落在VMA区域且权限为R+W,页表权限为R,则第一次写时会发生page fault ,内核会修改页表权限为R+W,并为之申请一页内存;
2.如果访问地址落在VMA区域,但是访问权限不合法
如果访问地址没有写权限,写入会引发page fault, 且内核发出SIGV
3.如果访问地址落在非法区域
如果访问地址落在空白区域,即不在任何一个VMA,则引发page fault且发出SEGV,杀死进程
在之前介绍brk系统调用和mmap系统调用时,它们只是建立了进程地址空间(VMA),用户空间可以看到虚拟内存,但是没有建立虚拟内存与物理内存之间的映射,即没有创建相应的页表项。当进程访问这些还没有建立映射关系的虚拟内存时,处理器自动触发一个缺页异常(也称缺页中断),Linux会处理此异常,它依赖于处理器架构,缺页异常底层的处理流程在内核代码中特定体系架构的部分。
kernel版本:5.10
平台:arm64
2. page fault的底层处理
esr_el1为arm64异常综合信息寄存器,寄存器结构如上,其中bit31-26为异常类型(EC), bit24-0为具体的异常指令编码(ISS),不同的异常类型ISS有不同的编码方式
可以根据esr.EC简单判断异常的类型,ESR支持几十种不同的异常类型,page fault为数据异常,此处以发生在EL1的数据异常为例
对于esr寄存器不同的异常类型EC有不同的ISS表(bit24-0),本例中对于数据异常种类,ISS表结构如下:
其中DFSC为Data Fault Status Code的缩写,指示了访问权限错误或页表转换错误等。Linux内核定义了fault_info结构体,指示了不同的DFSC对应了不同的回调函数。
far寄存器是Fault Address Register的缩写,这个寄存器保存了发生异常的虚拟地址
综上,arm64处理数据异常的底层逻辑如下:
arm64异常分为同步异常和异步异常,当数据异常发生时,会跳转到arm64同步异常向量处理;
通过读取esr寄存器,进一步通过esr.ec来确定异常分类,确定分类处理函数;
不同的异常分类EC对应不同的ISS结构,对于数据异常也对应特定的结构,此时ISS的DFSC描述了不同的数据异常编码;
arm64针对不同的DFSC编码,定义了fault_info表,表中针对每种数据异常,都定义了回调函数。
3. el1_sync
page fault作为arm64的一种同步异常而被处理,其主要的异常处理函数位于arch/arm64/kernel/entry.S, 其异常处理向量为el1_sync->el1_sync_handler
el1_sync
|--el1_sync_handler
|--esr = read_sysreg(esr_el1)
|--switch (ESR_ELx_EC(esr)) {
case ESR_ELx_EC_DABT_CUR:
case ESR_ELx_EC_IABT_CUR:
el1_abort(regs, esr);
|--far = read_sysreg(far_el1)
|--far = untagged_addr(far)
|--do_mem_abort(far, esr, regs)
break;
...
}
1
2
3
4
5
6
7
8
9
10
11
12
13
esr_el1:为arm64异常综合信息寄存器, esr为读取的寄存器的值
ESR_ELx_EC(esr): ESR_ELx_EC(esr)可以根据esr.EC简单判断异常的类型,ESR支持几十种不同的异常类型,此处以发生在EL1的数据异常ESR_ELx_EC_DABT_CUR(EC为0x25)为例,处理函数为el1_abort
el1_abort:读取far寄存器,far寄存器是Fault Address Register的缩写,这个寄存器保存了发生异常的虚拟地址
do_mem_abort:根据发生异常的虚拟地址addr进行处理
|- -do_mem_abort
do_mem_abort的参数far为读取的far_el1寄存器,保存了发生异常的虚拟地址,esr为esr_el1寄存器,为异常综合信息寄存器,regs为发生异常时的pt_regs指针,对于esr寄存器不同的异常类型EC有不同的ISS表(bit24-0),本例中对于数据异常种类,其中DFSC为Data Fault Status Code的缩写,指示了访问权限错误或页表转换错误等。Linux内核定义了fault_info结构体,指示了不同的DFSC对应了不同的回调函数。
do_mem_abort(far, esr, regs)
|--const struct fault_info *inf = esr_to_fault_info(esr);
|--inf->fn(addr, esr, regs)
1
2
3
esr_to_fault_info:当发生数据异常时,根据esr寄存器的ISS字段获取到DFSC字段,对于DFSC的每一个数据异常码都对应了一个struct fault_info结构体变量,所有的struct fault_info结构体变量形成一个fault_info表,通过DFSC就可以获取到对应的struct fault_info,从而得到相应的回调函数。
inf->fn(addr, esr, regs):针对缺页异常有常见的几种修复方案,fault_info中相应的回调函数主要包括:
#arch/arm64/mm/fault.c
static const struct fault_info fault_info[] = {
.......
{ do_bad, SIGKILL, SI_KERNEL, "level 1 address size fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 1 translation fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 1 access flag fault" },
{ do_alignment_fault, SIGBUS, BUS_ADRALN, "alignment fault" },
{ do_sea, SIGKILL, SI_KERNEL, "level 1 synchronous parity error (translation table walk)" }, // Reserved when RAS is implemented
1
2
3
4
5
6
7
8
do_translation_fault:处理页表转换相关的异常错误
do_page_fault:处理页表访问或权限相关的异常错误
do_alignment_fault:处理与对齐相关的异常错误
do_bad:处理与位置的错误或硬件相关的错误,如TLB冲突等
do_sea:
后续将以do_page_fault为例,说明缺页异常的主要过程。
————————————————
版权声明:本文为CSDN博主「HZero.chen」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/jasonactions/article/details/114763962
Page Fault的异常处理,依赖于体系结构,因此有必要来介绍一下Arm64的处理。
代码主要参考:arch/arm64/kernel/entry.S。
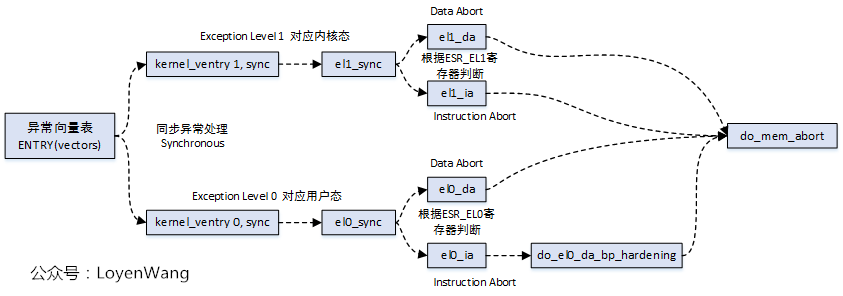
Arm64在取指令或者访问数据时,需要把虚拟地址转换成物理地址,这个过程需要进行几种检查,在不满足的情况下都能造成异常:
- 地址的合法性,比如以39有效位地址为例,内核地址的高25位为全1,用户进程地址的高25位为全0;
- 地址的权限检查,这里边的权限位都位于页表条目中;
从上图中可以看到,最后都会调到do_mem_abort函数,这个函数比较简单,直接看代码,位于arch/arm64/mm/fault.c:
/*
* Dispatch a data abort to the relevant handler.
*/
asmlinkage void __exception do_mem_abort(unsigned long addr, unsigned int esr,
struct pt_regs *regs)
{
const struct fault_info *inf = esr_to_fault_info(esr);
struct siginfo info;
if (!inf->fn(addr, esr, regs))
return;
pr_alert("Unhandled fault: %s (0x%08x) at 0x%016lx\n",
inf->name, esr, addr);
mem_abort_decode(esr);
info.si_signo = inf->sig;
info.si_errno = 0;
info.si_code = inf->code;
info.si_addr = (void __user *)addr;
arm64_notify_die("", regs, &info, esr);
}
该函数中关键的处理:根据传进来的esr获取fault_info信息,从而去调用函数。struct fault_info用于错误状态下对应的处理方法,而内核中也定义了全局结构fault_info,存放了所有的情况。
主要的错误状态和处理函数对应如下:
static const struct fault_info fault_info[] = {
{ do_bad, SIGBUS, 0, "ttbr address size fault" },
{ do_bad, SIGBUS, 0, "level 1 address size fault" },
{ do_bad, SIGBUS, 0, "level 2 address size fault" },
{ do_bad, SIGBUS, 0, "level 3 address size fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 0 translation fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 1 translation fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 2 translation fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 3 translation fault" },
{ do_bad, SIGBUS, 0, "unknown 8" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 1 access flag fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 2 access flag fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 3 access flag fault" },
{ do_bad, SIGBUS, 0, "unknown 12" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 1 permission fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 2 permission fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 3 permission fault" },
...
};
从代码中可以看出:
- 出现0/1/2/3级页表转换错误时,会调用
do_translation_fault,实际中do_translation_fault最终也会调用到do_page_fault; - 出现1/2/3级页表访问权限的时候,会调用
do_page_fault; - 其他的错误则调用
do_bad,其中未列出来的部分还包括do_sea等操作函数;
do_translation_fault
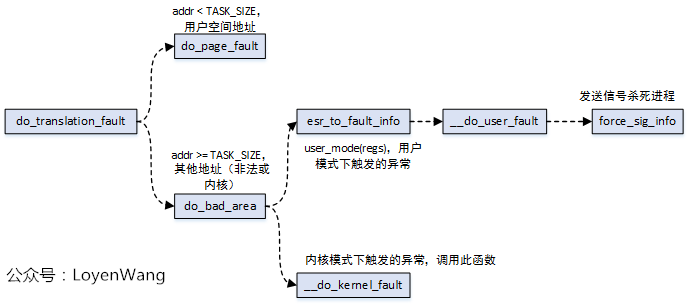
do_page_fault
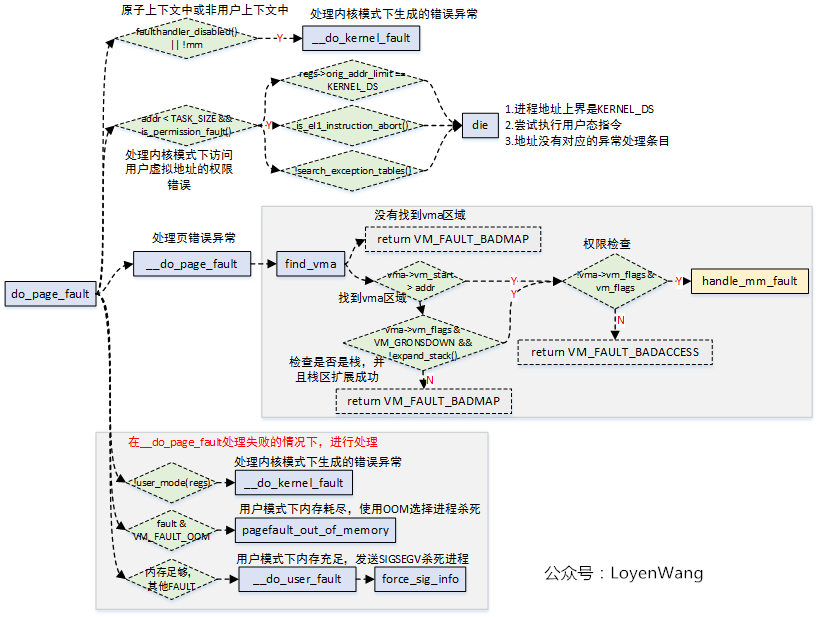
do_page_fault函数为页错误异常处理的核心函数,与体系结构相关,上图中的handle_mm_fault函数为通用函数,也就是不管哪种处理器结构,最终都会调用到该函数。
3. handle_mm_fault
handle_mm_fault用于处理用户空间的页错误异常:
- 进程在用户模式下访问用户虚拟地址,触发页错误异常;
- 进程在内核模式下访问用户虚拟地址,触发页错误异常;
从do_page_fault函数的流程图中也能看出来,当触发异常的虚拟地址属于某个vma,并且拥有触发页错误异常的权限时,会调用到handle_mm_fault函数,而handle_mm_fault函数的主要逻辑是通过__handle_mm_fault来实现的。
流程如下图:
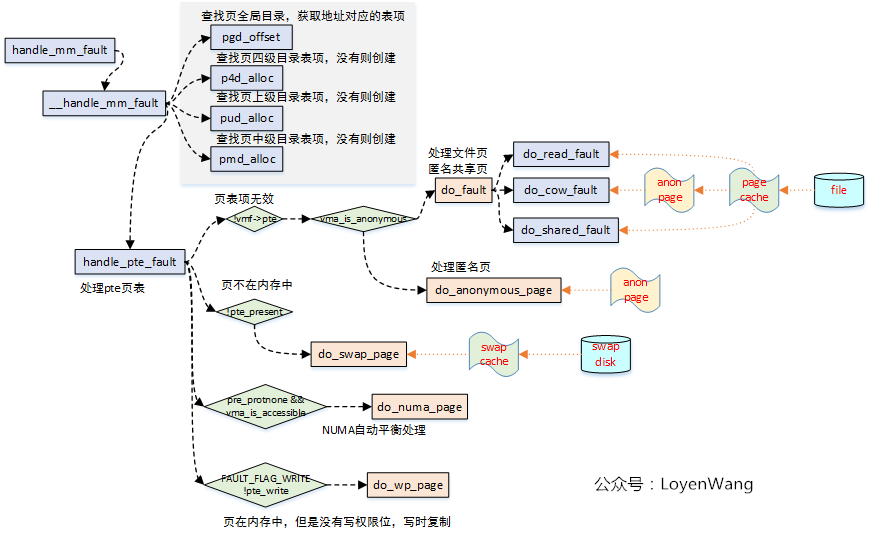
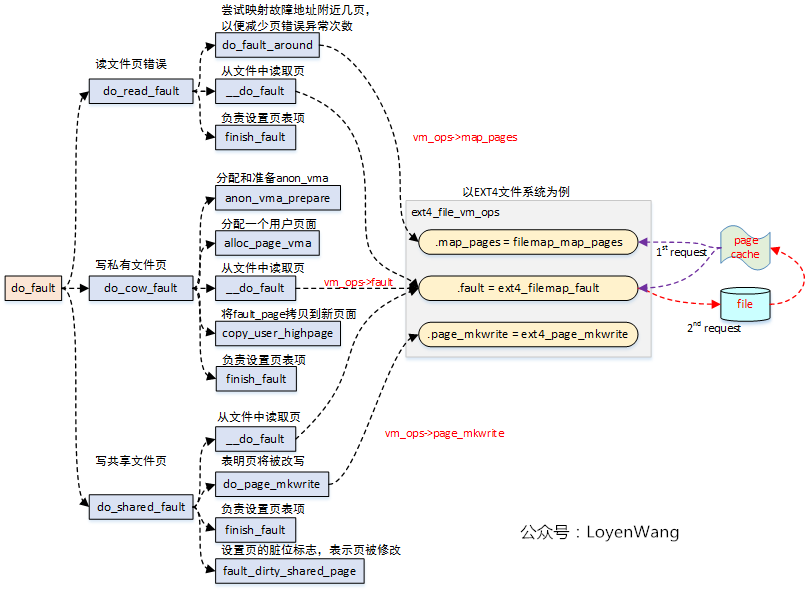
3.1 do_fault
do_fault函数用于处理文件页异常,包括以下三种情况:
- 读文件页错误;
- 写私有文件页错误;
- 写共享文件页错误;
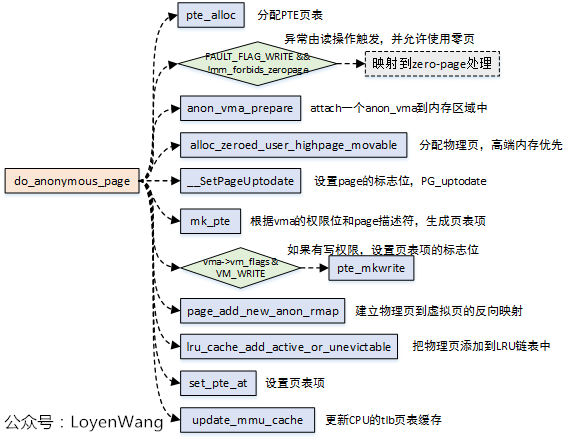
3.2 do_anonymous_page
匿名页的缺页异常处理调用本函数,在以下情况下会触发:
- malloc/mmap分配了进程地址空间区域,但是没有进行映射处理,在首次访问时触发;
- 用户栈不够的情况下,进行栈区的扩大处理;
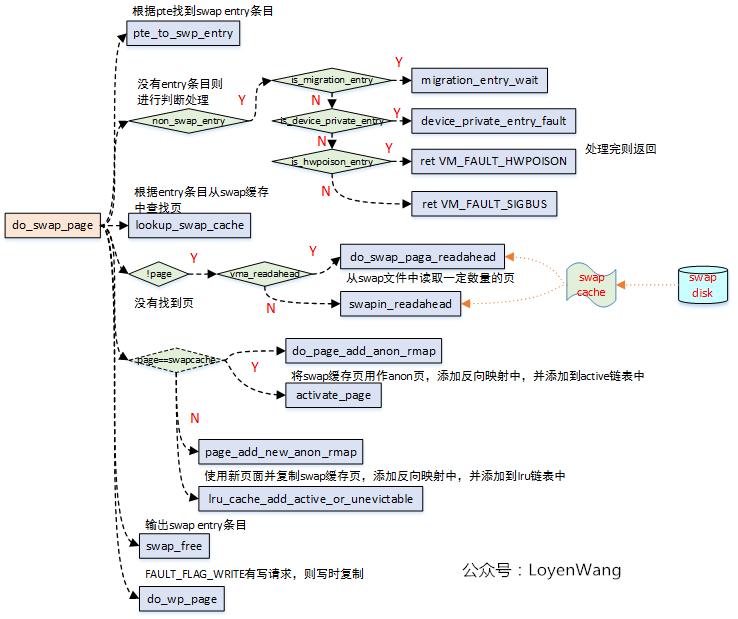
3.3 do_swap_page
如果访问Swap页面出错(页面不在内存中),则从Swap cache或Swap文件中读取该页面。
由于在4.14内核版本中,do_swap_page调用的很多函数都是空函数,无法进一步的了解,大体的流程如下图:
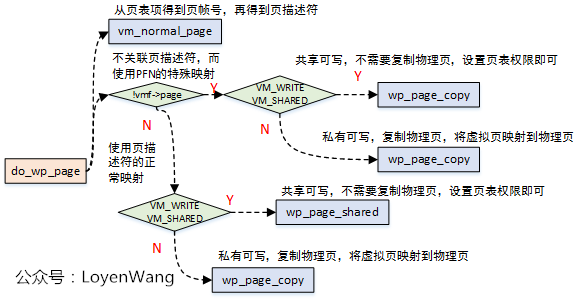
3.4 do_wp_page
do_wp_page函数用于处理写时复制(copy on write),会在以下两种情况处理:
- 创建子进程时,父子进程会以只读方式共享私有的匿名页和文件页,当试图写的时候,触发页错误异常,从而复制物理页,并创建映射;
- 进程创建私有文件映射,读访问后触发异常,将文件页读入到
page cache中,并以只读模式创建映射,之后发生写访问后,触发COW;
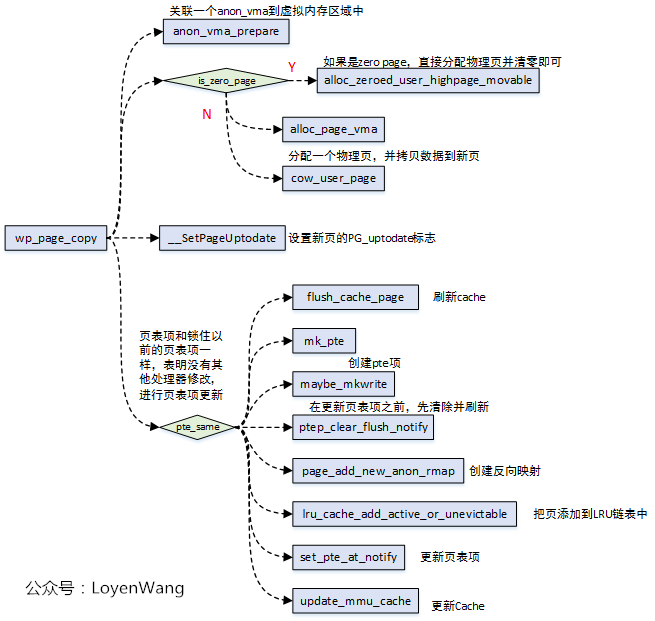
关键的复制工作是由wp_page_copy完成的:
Linux内存管理宏观篇(七)虚拟内存
前面知道了物理内存,物理内存是实打实的,我只有这么多,用的时候你只能用这么多。
为了解决一些问题,产生虚拟内存,通过虚拟内存可以让我们每个进程都能拥有虚拟的3GB用户态地址空间,同时与硬件层屏蔽后还可以增加我们程序的移植性。以及众多好处,这里在前面认识内存的时候讲过,移植性,保护内存安全等等。
我觉得最重要的是我们可以通过地址虚拟赋予每个进程更大的内存使用空间,当然这就涉及到不断地映射与释放。而我们的进程基本上不会实实在在的得到3GB的物理内存。
咱们常用的malloc()是内存分配的接口
而mmap()是用户态用来建立文件映射或者匿名映射的函数。
知道了
虚拟内存是什么?
虚拟内存为什么?
那么对于虚拟内存是怎么管理的?
进程的地址空间管理,内核使用了struct vm_area_struct数据结构来描述(又是通过一个结构体,或者说是对象):VMA,中文名可以称为进程地址空间或者进程线性区。
因为进程的地址空间肯定是进程的元素,因此在进程的管理结构体 struct mm_struct也会有进程地址空间属性,这个属性就是管理VMA。
下面就来看看进程地址空间。
1、进程地址空间
1、是什么?
是进程可以寻址的虚拟空间地址
2、有多大?
32位的是4GB
3、都能操作?
不得行,只有3GB的用户地址可以,内核地址需要通过系统调用。而用户空间的进程地址空间则可以被合法访问,地址空间称为内存区域(memory area)。
4、怎么去操作?
进程可以通过内核的内存管理机制动态地添加和删除这些内存区域,这些内存区域在Linux内核采用VMA数据结构来抽象描述。
5、去了错的地方,做了错的事情怎么办?
不可能,内存的区域权限不同,每个进程有自己的相应的内存区域。任何不安全的行为都会报警。严重的会报告“Segment Fault”段错误并终止该进程
6、内存区域有什么?
代码段映射,可执行文件中包含只读并可执行的程序头,如代码段和init段等。
数据段映射,可执行文件中包含可读可写的程序头,如数据段和bss段等。
用户进程的栈。通常是在用户空间的最高地址,从上往下延伸。它包含栈帧,里面包含了局部变量和函数调用参数等。注意不要和内核栈混淆,进程的内核栈独立存在并有内核维护,主要用于上下文切换。
MMAP 映射区域。位于用户进程栈下面,主要用于 mmap 系统调用,比如映射一个文件的内容到进程地址空间等。
堆映射区域。malloc()函数分配的进程虚拟地址就是这段区域。
7、虚拟内存大家都是3GB,要是小红和小绿搞到一起怎么办?
不可能的,因为虚拟地址分配的值一样,但是每个进程都有自己的页表,页表是独一份,因此每个进程能访问的区域都是相互隔离的。各有不同。(你以为给了你全世界,实际上只是一个角)
下面来看看内存描述符是什么?
2、内存描述符 mm_struct
对于进程的内存区域和对应的页表映射,内核采用抽象一个数据结构来管理。然后在进程控制块(PCB)结构task_struct中有一个指针mm是指向这个mm_struct数据结构的。
task_struct(mm)–>mm_struct–>VMA
mm_struct数据结构定义在include/linux/mm_types.h文件中,下面是它的主要成员。
之前我们从进程的角度看过内存,这里可以结合一起看一下。
下面看看VMA
3、VMA管理
VMA数据结构定义在mm_types.h文件中。[include/linux/mm_types.h]
进一步看看mm_struct,struct mm_struct数据结构是描述进程内存管理的核心数据结构,该数据结构也提供了管理VMA所需要的信息,这些信息概况如下。
[include/linux/mm_types.h]
struct mm_struct {
struct vm_area_struct *mmap;
struct rb_root mm_rb;
…
};
每个VMA都要连接到mm_struct中的链表和红黑树中,以方便查找。mmap 形成一个单链表,进程中所有的 VMA 都链接到这个链表中,链表头是mm_struct->mmap。
mm_rb是红黑树的根节点,每个进程有一棵VMA的红黑树。
VMA按照起始地址以递增的方式插入mm_struct->mmap链表。当进程拥有大量的VMA时,扫描链表和查找特定的VMA是非常低效的操作,例如在云计算的机器中,所以内核中通常要靠红黑树来协助,以便提高查找速度。从VMA的角度来观察进程的内存管理,如图7.20所示。(当年特么的学的算法终于用上了)
1.查找VMA
通过虚拟地址addr来查找VMA是内核中常用的操作。内核提供一个API函数来实现这个查找操作。
struct vm_area_struct *find_vma(struct mm_struct *mm, unsigned long addr)
struct vm_area_struct *find_vma_prev(struct mm_struct *mm, unsigned long addr,struct vm_area_struct **pprev)
static inline struct vm_area_struct * find_vma_intersection(struct mm_struct * mm,unsigned long start_addr, unsigned long end_addr)
find_vma()函数根据给定地址addr查找满足如下条件之一的VMA,如图7.21所示。addr在VMA空间范围内,即 vma->vm_start <= addr < vma->vm_end。距离addr最近,并且VMA的结束地址大于addr的一个VMA。(说明了什么?)
2.插入VMA
insert_vm_struct()是内核提供的插入VMA的核心API函数。
int insert_vm_struct(struct mm_struct *mm, struct vm_area_struct *vma)
1
insert_vm_struct()函数向VMA链表和红黑树插入一个新的VMA。参数mm是进程的内存描述符,vma是要插入的线性区VMA。(这个链表和红黑树的关系是什么?)
3.合并VMA
在新的 VMA 被加入进程的地址空间时,内核会检查它是否可以与一个或多个现存的VMA进行合并。vma_merge()函数实现将一个新的VMA和附近的VMA合并。变成一个更大的连续的空间。
struct vm_area_struct *vma_merge(struct mm_struct *mm,struct vm_area_struct *prev, unsigned long addr,unsigned long end, unsigned long vm_flags,struct anon_vma *anon_vma, struct file *file,pgoff_t pgoff, struct mempolicy *policy)
1
vma_merge()函数参数多达9个。其中,mm是相关进程的struct mm_struct数据结构。prev是紧接着新VMA前继节点的VMA,一般通过find_vma_links()函数来获取。add和end是新VMA的起始地址和结束地址。vm_flags是新VMA的标志位。如果新VMA属于一个文件映射,则参数file指向该文件struct file数据结构。参数proff指定文件映射偏移量。参数anon_vma是匿名映射的struct anon_vma数据结构。
4、malloc背后的男人
malloc()函数是C语言中的内存分配函数。假设系统中有进程A和进程B,分别使用testA和testB函数分配内存。
void testA(void){
char * bufA = malloc(100);
…
*bufA = 100;
…
}
//进程B分配内存
void testB(void){
char * bufB = malloc(100);
mlock(bufB, 100);
…
}
其实在内存这方面的函数,经常会问到的就是这个是否会立即分配内存?这个分配的内存在哪里呢?
假设不考虑libc的因素,malloc分配100字节,那么实际上内核是为其分配100字节吗?(那不然呢?骗纸?)
假设使用printf打印指针bufA和bufB指向的地址是一样的,那么在内核中这两块虚拟内存是否“打架”了呢?(这打印的是虚拟地址还是物理地址诶?)
malloc()函数是C语言标准库里封装的一个核心函数。C标准库做一些处理后调用Linux内核系统去调用brk。也许读者并不太熟悉brk的系统调用,原因在于很少有人会直接使用系统调用 brk 向系统申请内存,而总是通过 malloc()之类的 C 标准库的 API 函数。如果把malloc()想象成零售,那么 brk 就是代理商。malloc 函数的实现为用户进程维护一个本地小仓库,当进程需要使用更多的内存时就向这个小仓库“要货”,小仓库存量不足时就通过代理商brk向内核“批发”。
(我不太认可这里的比喻,其实我们分配内存的申请一发生,我的映像是立马就深入到系统调用了,这里零售说明,我能屯点货,但是malloc最多就是个中间人,把你要给我的东西通过他转交给我,而没有这个缓存的属性。我觉得中间人更合适,但是这是因为我对malloc的认识很浅薄,继续保持疑问往下看。)
brk系统调用定义如下。
SYSCALL_DEFINE1(brk, unsigned long, brk)
1
在32位Linux内核中,每个用户进程拥有3GB的虚拟空间。内核如何为用户空间划分这3GB的虚拟空间呢?
3GB的用户空间怎么划分?
用户进程的可执行文件由代码段和数据段组成,数据段包括所有的静态分配的数据空间,例如全局变量和静态局部变量等。这些空间在可执行文件装载时,内核就为其分配好这些空间,包括虚拟地址和物理页面,并建立好二者的映射关系。
如图7.22所示,用户进程的用户栈从3GB虚拟空间的顶部开始,由顶向下延伸,而brk分配的空间是从数据段的顶部end_data到用户栈的底部。动态分配空间是从进程的end_data开始,每次分配一块空间,就把这个边界往上推进一段,同时内核和进程都会记录当前的边界的位置。
malloc函数其实是为用户空间分配进程地址空间的,用内核术语就是分配一块VMA,相当于一个空的纸箱子。因为VMA还没和具体物理地址挂钩呢。相当于一个空的纸箱子。
那什么时候才往纸箱子里装东西呢?
一是到了真正使用箱子时才往里面装东西;(声明未初始化)
二是分配箱子时就装了你想要的东西。(声明初始化)
进程A中的testA函数就是第一种情况。当使用这段内存时,CPU去查询页表,发现页表为空,CPU触发缺页异常,然后在缺页异常里一页一页地分配内存,需要一页给一页。(这个缺页异常据说很精彩)
进程B里面的testB函数是第二种情况,直接分配已装满的纸箱子,你要的虚拟内存都已经分配了物理内存并建立了页表映射。
假设不考虑C语言标准库的因素,malloc分配100字节,那么内核会分配多少字节呢?处理器的MMU硬件单元处理最小单元是页,所以内核分配内存、建立虚拟地址和物理地址映射关系都以页为单位,PAGE_ALIGN(addr)宏让地址addr按页面大小对齐。
那就是1024字节。
还有个问题就是malloc相同的虚拟地址会打架吗?
其实每个用户进程有自己的一份页表,mm_struct 数据结构中有一个pgd成员指向这个页表的基地址,在用fork()函数创建新进程时会初始化一份页表。每个进程有一个mm_struct数据结构,包含一个属于进程自己的页表、一个管理VMA的红黑树和链表。进程本身的VMA会挂入属于自己的红黑树和链表,所以即使进程A和进程B使用malloc分配内存返回的相同的虚拟地址,它们也是两个不同的VMA,分别被不同的两套页表来管理。
简言之:数据结构里有页表,页表基地址不同,还有各种不同,进程有很多自己独特的数据结构,因此最后的物理地址是不一样的。
所以即使进程A和进程B使用malloc分配内存返回的相同的虚拟地址,它们也是两个不同的VMA,分别被不同的两套页表来管理。
(得写写libc这个东西的作用)
6、mmap背后故事
mmap/munmap 接口函数是用户空间最常用的两个系统调用接口,无论是在用户程序中分配内存、读写大文件、链接动态库文件,还是多进程间共享内存,都可以看到mmap/munmap的身影。mmap/munmap函数声明如下。
#include <sys/mman.h>void *mmap(void *addr, size_t length, int prot, int flags,int fd, off_t offset);
int munmap(void *addr, size_t length);
最后根据文件关联性和映射区域是否共享等属性,mmap又可以分成如下4种情况,如表7.7所示。
1.私有匿名映射
当参数fd=−1且flags= MAP_ANONYMOUS | MAP_PRIVATE时,创建的mmap映射是私有匿名映射。私有匿名映射最常见的用途是在glibc分配大块的内存中,当需要分配的内存大于MMAP_THREASHOLD(128KB)时,glibc会默认使用mmap代替brk来分配内存。
2.共享匿名映射
当参数fd=−1且flags= MAP_ANONYMOUS | MAP_SHARED时,创建的mmap映射是共享匿名映射。共享匿名映射让相关进程共享一块内存区域,通常用于父子进程之间通信。
创建共享匿名映射有如下两种方式。
1)fd=−1 且 flags= MAP_ANONYMOUS | MAP_SHARED。在这种情况下,do_mmap_pgoff()->mmap_region()函数最终会调用shmem_zero_setup()打开一个“/dev/zero”特殊的设备文件。
2)直接打开“/dev/zero”设备文件,然后使用这个文件句柄来创建mmap。
上述两种方式最终都会调用到shmem模块来创建共享匿名映射。
3.私有文件映射
创建文件映射时,flags的标志位被设置为MAP_PRIVATE,此时就会创建私有文件映射。私有文件映射最常用的场景是加载动态共享库。
4.共享文件映射
创建文件映射时,flags的标志位被设置为MAP_SHARED,此时就会创建共享文件映射。如果prot参数指定了PROT_WRITE,那么打开文件时需要指定O_RDWR标志位。共享文件映射通常有如下两个场景。
1)读写文件。把文件内容映射到进程地址空间,同时对映射的内容做修改,内核的回写机制最终会把修改的内容同步到磁盘中。
2)进程间通信。进程之间的进程地址空间相互隔离,一个进程不能访问到另一个进程的地址空间。如果多个进程都同时映射到一个相同文件时,就实现了多进程间的共享内存通信。如果一个进程对映射内容做了修改,那么另一个进程是可以看到的。
mmap机制在Linux内核中实现的代码框架和brk机制非常类似,mmap机制如图7.24所示,其中有很多关于VMA的操作。另外,mmap机制和缺页异常机制结合在一起会变得复杂很多。
小结
这一章讲了一下虚拟内存,虚拟内存主要从进程的角度去将虚拟内存,因为虚拟内存的目的和出发点当时就是为了解决进程的地址问题。然后说了一下这里面涉及到的关键的几个数据结构。 mm_struct、vm_area_struct。然后讲了vma的管理(查找、插入、合并),搞清楚这些操作的用处在哪里很重要。我觉得vma这个部分的算法数据结构思想还是蛮不错的,需要的话可以研究,在数据库里也涉及到了红黑树,可见内核的算法和思想,对于软件的设计架构还是通用的。
最后介绍了malloc、mmap。这两个重要的函数的流程与功能。这里我也浅浅的粗略瞟了一眼,等后面需要了再来详细读。
堆的内存怎么从内核中申请
怎么有效地进行堆内存管理
1. malloc简介
malloc函数使C/C++中常用内存分配库函数,使用malloc时,需包含头文件<stdlib.h>,函数原型如下
void* malloc(size_t size);
1
功能:分配长度为size的内存块,一般为系统堆上的可用内存上找到一块长度大于size的连续内存空间。如果分配成功,则返回指向分配内存的指针,否则返回空指针NULL。
返回值:类型为void *,表示未确定类型指针,它可以强制转换为任意其他类型的指针
当内存不再使用时,应用free函数将内存块释放。将之前malloc分配的空间还给操作系统,释放传入指针指向的那块内存区域。指针本身的数值没有变,释放后,指向的内容是垃圾内容,所以最好将这块内存的指针再指向NULL,防止后面的程序误用。
而对于进程的堆,并不是直接建立在Linux的内核的内存分配策略上的,而是建立在glibc的堆管理策略上的(也就是glibc的动态内存分配策略上),堆的管理是由glibc进行的。所以我们调用free对malloc得到的内存进行释放的时候,并不是直接释放给操作系统,而是还给了glibc的堆管理实体,而glibc会在把实际的物理内存归还给系统的策略上做一些优化,以便优化用户任务的动态内存分配过程。
malloc的调用规律(该过程可以通过系统调用接口strace命令跟踪)
即分配一块小型内存(小于或等于128kb),malloc()会调用brk()调高断点(brk是将数据段(.data)的最高地址指针_edata往高地址推),分配的内存在堆区域。
当分配一块大型内存(大于128kb),malloc()会调用mmap2()分配一块内存(mmap是在进程的虚拟地址空间中(一般是堆和栈中间)找一块空闲的空间。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r99YHEfE-1605195380068)(D:\学习总结\内存管理单元\image-20201108230656508.png)]](https://img-blog.csdnimg.cn/2020111223364851.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTI0ODkyMzY=,size_16,color_FFFFFF,t_70#pic_center)
小于128K的堆内存分配方式
stack的内存地址是向下增长的,heap的内存地址是向上增长
glibc对于heap内存申请大于128k的内存申请,glibc采用mmap的方式向内核申请内存,这不能保证内存地址向上增长;小于128k的则采用brk,对于它来讲是正确的。128k的阀值,可以通过glibc的库函数进行设置
1.1 brk
1,进程启动的时候,其(虚拟)内存空间的初始布局如图所示
2,进程调用A=malloc(30K)以后,,将_edata指针往高地址推30K,就完成虚拟内存分配,内存空间如图:
3,进程调用 free© 以后,如下图所示,C对应的虚拟内存和物理内存都没有释放,因为只有一个 _edata 指针,如果往回推,那么 C 这块内存怎么办呢?当然,B 这块内存是可以重用的,如果这个时候再来一个 30K 的请求,那么 malloc 很可能就将 B 这块内存返回的。
4,进程调用 free(A) 以后,如下图所示,C 和 A 连接起来变成一块70K 的空闲内存。当最高地址空间的空闲内存超过128K(可由 M_TRIM_THRESHOLD 选项调节)时,执行内存紧缩操作(trim)。在上一个步骤 free 的时候,发现最高地址空闲内存超过128K,于是内存紧缩,如下图所示。

事实是:_edata+30K只是完成虚拟地址的分配,A这块内存现在还是没有物理页与之对应的,等到进程第一次读写A这块内存的时候,发生缺页中断,这个时候,内核才分配A这块内存对应的物理页。也就是说,如果用malloc分配了A这块内容,然后从来不访问它,那么,A对应的物理页是不会被分配的。
同时brk 分配的内存需要等到高地址内存释放以后才能释放(例如,在 C 释放之前,A 是不可能释放的,这就是内存碎片产生的原因),而 mmap 分配的内存可以单独释放。
1.2 mmap
使用mmap分配内存。在堆和栈之间找一块空闲内存分配(对应独立内存,而且初始化为0)
进程调用B=malloc(200K)以后,内存空间如图4 ,默认情况下,malloc函数分配内存,如果请求内存大于128K(可由M_MMAP_THRESHOLD选项调节),那就不是去推_edata指针了,而是利用mmap系统调用,从堆和栈的中间分配一块虚拟内存。
进程调用free(B)以后,B对应的虚拟内存和物理内存一起释放

默认情况下,malloc函数分配内存,如果请求内存大于128K(可由M_MMAP_THRESHOLD选项调节),那就不是去推_edata指针了,而是利用mmap系统调用,从堆和栈的中间分配一块虚拟内存
brk分配的内存需要等到高地址内存释放以后才能释放(例如,在B释放之前,A是不可能释放的,因为只有一个_edata 指针,这就是内存碎片产生的原因,什么时候紧缩看下面),而mmap分配的内存可以单独释放。
2 . 源码分析
malloc用于用户空间堆扩展的函数接口。该函数是C库,属于封装了相关系统调用(brk())的glibc库函数。而不是系统调用(系统可没有sys_malloc()。如果谈及malloc函数涉及的系统内核的那些操作,那么总体可以分为用户空间层面和内核空间层面,本章主要是讲解内核空间。
malloc和free是在用户层工作的,该接口为用户提供一个比较方便管理堆的接口。它的主要工作是维护一个空闲的堆空间缓冲区链表。该缓冲区可以用如下数据结构表述,详细的过程见glibc源码
struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
每当用户进程调用malloc,首先会在该堆缓冲区寻找足够大小的内存块分配给进程。如果从缓冲区无法找到满足需求的内存块时,那么malloc就会根据相应的内存大小调用系统调用brk或者mmap。我们以sys_brk为例,这个时候,才真正的进入到内核空间。
在32位linux内核中,每个用户进程拥有3GB的虚拟地址空间,那么内核如何为用户空间划分这3GB的虚拟地址空间呢?由上一章讲解,用户进程的可执行文件由text、data、bss段组成。如下图所示
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nAeOK5Zy-1605195380074)(D:\学习总结\内存管理单元\image-20201109231032809.png)]](https://img-blog.csdnimg.cn/20201113232309805.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTI0ODkyMzY=,size_16,color_FFFFFF,t_70#pic_center)
用户进程的用户栈从3GB的虚拟空间的顶部开始,由顶向下延伸
brk分配的空间是从数据段的顶部end_data到用户栈的地步,所以动态分配空间是从用户栈的地步。
下面我们看看内核关于brk的代码实现,详细见(mm/mmap.c),其主要的实现流程图如下图所示,最终是调用了do_brk来实现内存的分配
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W7452kJS-1605195380076)(D:\学习总结\内存管理单元\image-20201109232631208.png)]](https://img-blog.csdnimg.cn/20201113232346330.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTI0ODkyMzY=,size_16,color_FFFFFF,t_70#pic_center)
由于这个函数既可以用来分配空间,即把动态分配区地步的边界往上推;也可以用来释放,即归还空间。因此,它的代码也大致可以分为两部分。首先是第一部分:收缩数据区,伸长操作。我们分为两种情况来分析。对于第一部分,内存映射一起学习,这部分主要是第二部分do_brk。
static unsigned long do_brk(unsigned long addr, unsigned long len)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
unsigned long flags;
struct rb_node **rb_link, *rb_parent;
pgoff_t pgoff = addr >> PAGE_SHIFT;
int error;
len = PAGE_ALIGN(len);
if (!len)
return addr;
flags = VM_DATA_DEFAULT_FLAGS | VM_ACCOUNT | mm->def_flags;
error = get_unmapped_area(NULL, addr, len, 0, MAP_FIXED); ----------------------------(1)
if (offset_in_page(error))
return error;
error = mlock_future_check(mm, mm->def_flags, len);
if (error)
return error;
/*
* mm->mmap_sem is required to protect against another thread
* changing the mappings in case we sleep.
*/
verify_mm_writelocked(mm);
/*
* Clear old maps. this also does some error checking for us
*/
while (find_vma_links(mm, addr, addr + len, &prev, &rb_link, ----------------------------(2)
&rb_parent)) {
if (do_munmap(mm, addr, len))
return -ENOMEM;
}
/* Check against address space limits *after* clearing old maps... */
if (!may_expand_vm(mm, len >> PAGE_SHIFT))
return -ENOMEM;
if (mm->map_count > sysctl_max_map_count)
return -ENOMEM;
if (security_vm_enough_memory_mm(mm, len >> PAGE_SHIFT))
return -ENOMEM;
/* Can we just expand an old private anonymous mapping? */
vma = vma_merge(mm, prev, addr, addr + len, flags, ---------------------------(3)
NULL, NULL, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma)
goto out;
/*
* create a vma struct for an anonymous mapping
*/
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL); ---------------------------(4)
if (!vma) {
vm_unacct_memory(len >> PAGE_SHIFT);
return -ENOMEM;
}
INIT_LIST_HEAD(&vma->anon_vma_chain);
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_pgoff = pgoff;
vma->vm_flags = flags;
vma->vm_page_prot = vm_get_page_prot(flags);
vma_link(mm, vma, prev, rb_link, rb_parent);
out:
perf_event_mmap(vma);
mm->total_vm += len >> PAGE_SHIFT;
if (flags & VM_LOCKED)
mm->locked_vm += (len >> PAGE_SHIFT);
vma->vm_flags |= VM_SOFTDIRTY;
return addr;
}do_brk()有两个参数,addr是要开展的目标区域的开始地址,len是目标区域的长度,其实质也应该是处理vm_erea,目标是在进程空间中有一个匿名vm_erea能映射到[addr, len)这段区域中。下面是代码主要的分析
1.**get_unmapped_area()**函数在当前进程的用户空间中查找一个符合len大小的线性地址区域。PAGE_MASK的值为0xFFFFF000,因此,如果 (error & ~PAGE_MASK)为非0,说明addr最低12位非0,addr就不是一个有效的地址,就以这个地址作为返回值;否则,addr就是一个有效的地址(最低12位为0)
2.通过**find_vma_links()**在当前进程的所有线性区组成的红黑树中依次遍历每个vma,以确定上一步找到的新区域之前线性区对象位置。如果addr位于某个现存的vma中,则调用do_munmap删去这个线性区。主要是找到合适的VMA的插入点。
3.经过2,已经找到了一个合适大小的空闲线性区,接下来通过vma_merge去试着将当前的线性区与临近的线性区进行合并,确认这个新节点是否能够与现有树中的节点进行合并,如果地址是连续的,就能够合并,则不用创建新的vm_eara_struct了,直接跳出out,更新统计值即可。
struct vm_area_struct *vma_merge(struct mm_struct *mm,
struct vm_area_struct *prev, unsigned long addr,
unsigned long end, unsigned long vm_flags,
struct anon_vma *anon_vma, struct file *file,
pgoff_t pgoff, struct mempolicy *policy,
struct vm_userfaultfd_ctx vm_userfaultfd_ctx)
mm:描述添加新区域进程的内存空间
prev:指向当前区域之前的一个内存区
addr:表示新区域的起始地址
end:表示新区域的结束地址
vm_flag:表示该区域的标志,如果该新区域映射了一个磁盘文件,则file结构表示该文件
pgoff:表示文件映射的偏移量
4.如果不能合并,则通过kmem_cache_zalloc创建新的vm_erea_struct,加到anon_vma_chain链表中,也将新创建的VMA加入到mm->mmap链表和红黑树中
到这里malloc就结束了,从以上可看出malloc在完成调用后并没有立马分配物理内存,而是在需要在进程需要访问此虚拟内存块时才会产生缺页中断,才会分配物理内存,并建立虚拟内存到物理内存的映射。以上情况除了当分配flag带有VM_MLOCK时需要立即调用mm_populate来分配物理内存,其实现为mm_populate,其代码实现如下
int __mm_populate(unsigned long start, unsigned long len, int ignore_errors)
{
struct mm_struct *mm = current->mm;
unsigned long end, nstart, nend;
struct vm_area_struct *vma = NULL;
int locked = 0;
long ret = 0;
VM_BUG_ON(start & ~PAGE_MASK);
VM_BUG_ON(len != PAGE_ALIGN(len));
end = start + len;
for (nstart = start; nstart < end; nstart = nend) { ---------------------(1)
/*
* We want to fault in pages for [nstart; end) address range.
* Find first corresponding VMA.
*/
if (!locked) {
locked = 1;
down_read(&mm->mmap_sem);
vma = find_vma(mm, nstart);
} else if (nstart >= vma->vm_end)
vma = vma->vm_next;
if (!vma || vma->vm_start >= end)
break;
/*
* Set [nstart; nend) to intersection of desired address
* range with the first VMA. Also, skip undesirable VMA types.
*/
nend = min(end, vma->vm_end);
if (vma->vm_flags & (VM_IO | VM_PFNMAP))
continue;
if (nstart < vma->vm_start)
nstart = vma->vm_start;
/*
* Now fault in a range of pages. populate_vma_page_range()
* double checks the vma flags, so that it won't mlock pages
* if the vma was already munlocked.
*/
ret = populate_vma_page_range(vma, nstart, nend, &locked); ---------------------(2)
if (ret < 0) {
if (ignore_errors) {
ret = 0;
continue; /* continue at next VMA */
}
break;
}
nend = nstart + ret * PAGE_SIZE;
ret = 0;
}
if (locked)
up_read(&mm->mmap_sem);
return ret; /* 0 or negative error code */
}
1.以start为起始地址,先通过find_vma()查找VMA,如果没有找到VMA,则退出循环
2.调用populate_vma_page_range为VMA分配物理内存,最终会调用__get_user_pages为进程地址空间分配物理内存并且建立映射关系。
至此,已经为这块进程地址空间VMA分配了物理页面,并建立了映射关系。对于malloc函数使为用户空间分配进程地址空间,其实现流程如下:

至此上面过程,malloc返回了一个线性地址,如果此时用户地址访问这个线性地址,那么就会发生缺页异常,内核才会真正的为虚拟地址分配实际的物理内存。所以实际在用户空间,如果我们通过malloc(4096),申请4k的地址空间,当我们不去使用的时候,是不会申请到实际的物理地址。其分配流程如下图

3.总结
malloc() 是 C 标准库提供的内存分配函数,对应到系统调用上,有两种实现方式,即 brk() 和 mmap()。
分配方式 特点 优点 缺点
brk/sbrk 对小块内存(小于 128K),通过移动堆顶的位置来分配内存 内存释放后并不会立刻归还系统,而是被缓存起来,这样就可以重复使用,可以减少缺页异常的发生,提高内存访问效率 由于这些内存没有归还系统,在内存工作繁忙时,频繁的内存分配和释放会造成内存碎片
mmap 大块内存(大于 128K),也就是在文件映射段找一块空闲内存分配出去 分配的内存,会在释放时直接归还系统,每次 mmap 都会发生缺页异常 在内存工作繁忙时,频繁的内存分配会导致大量的缺页异常,使内核的管理负担增大。这也是 malloc 只对大块内存使用 mmap 的原因
进程向 OS 申请和释放地址空间的接口 sbrk/mmap/munmap 都是系统调用,频繁调用系统调用都比较消耗系统资源的。并且, mmap 申请的内存被 munmap 后,重新申请会产生更多的缺页中断。例如使用 mmap 分配 1M 空间,第一次调用产生了大量缺页中断 (1M/4K 次 ) ,当munmap 后再次分配 1M 空间,会再次产生大量缺页中断。缺页中断是内核行为,会导致内核态CPU消耗较大。另外,如果使用 mmap 分配小内存,会导致地址空间的分片更多,内核的管理负担更大。
同时堆是一个连续空间,并且堆内碎片由于没有归还 OS ,如果可重用碎片,再次访问该内存很可能不需产生任何系统调用和缺页中断,这将大大降低 CPU 的消耗。 因此, glibc 的 malloc 实现中,充分考虑了 sbrk 和 mmap 行为上的差异及优缺点,默认分配大块内存 (128k) 才使用 mmap 获得地址空间,也可通过 mallopt(M_MMAP_THRESHOLD, ) 来修改这个临界值。
MMAP基本概念实现
1. mmap 基础概念
mmap 即 memory map,也就是内存映射。
mmap 是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用 read、write 等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。如下图所示:
mmap 具有如下的特点:
mmap 向应用程序提供的内存访问接口是内存地址连续的,但是对应的磁盘文件的 block 可以不是地址连续的;
mmap 提供的内存空间是虚拟空间(虚拟内存),而不是物理空间(物理内存),因此完全可以分配远远大于物理内存大小的虚拟空间(例如 16G 内存主机分配 1000G 的 mmap 内存空间);
mmap 负责映射文件逻辑上一段连续的数据(物理上可以不连续存储)映射为连续内存,而这里的文件可以是磁盘文件、驱动假造出的文件(例如 DMA 技术)以及设备;
mmap 由操作系统负责管理,对同一个文件地址的映射将被所有线程共享,操作系统确保线程安全以及线程可见性;
mmap 的设计很有启发性。基于磁盘的读写单位是 block(一般大小为 4KB),而基于内存的读写单位是地址(虽然内存的管理与分配单位是 4KB)。换言之,CPU 进行一次磁盘读写操作涉及的数据量至少是 4KB,但是进行一次内存操作涉及的数据量是基于地址的,也就是通常的 64bit(64 位操作系统)。mmap 下进程可以采用指针的方式进行读写操作,这是值得注意的。
2. mmap 的 I/O 模型
mmap 也是一种零拷贝技术,其 I/O 模型如下图所示:
mmap 技术有如下特点:
利用 DMA 技术来取代 CPU 来在内存与其他组件之间的数据拷贝,例如从磁盘到内存,从内存到网卡;
用户空间的 mmap file 使用虚拟内存,实际上并不占据物理内存,只有在内核空间的 kernel buffer cache 才占据实际的物理内存;
mmap() 函数需要配合 write() 系统调动进行配合操作,这与 sendfile() 函数有所不同,后者一次性代替了 read() 以及 write();因此 mmap 也至少需要 4 次上下文切换;
mmap 仅仅能够避免内核空间到用户空间的全程 CPU 负责的数据拷贝,但是内核空间内部还是需要全程 CPU 负责的数据拷贝;
利用 mmap() 替换 read(),配合 write() 调用的整个流程如下:
用户进程调用 mmap(),从用户态陷入内核态,将内核缓冲区映射到用户缓存区;
DMA 控制器将数据从硬盘拷贝到内核缓冲区(可见其使用了 Page Cache 机制);
mmap() 返回,上下文从内核态切换回用户态;
用户进程调用 write(),尝试把文件数据写到内核里的套接字缓冲区,再次陷入内核态;
CPU 将内核缓冲区中的数据拷贝到的套接字缓冲区;
DMA 控制器将数据从套接字缓冲区拷贝到网卡完成数据传输;
write() 返回,上下文从内核态切换回用户态。
3. mmap 的优势
1.简化用户进程编程
在用户空间看来,通过 mmap 机制以后,磁盘上的文件仿佛直接就在内存中,把访问磁盘文件简化为按地址访问内存。这样一来,应用程序自然不需要使用文件系统的 write(写入)、read(读取)、fsync(同步)等系统调用,因为现在只要面向内存的虚拟空间进行开发。
但是,这并不意味着我们不再需要进行这些系统调用,而是说这些系统调用由操作系统在 mmap 机制的内部封装好了。
(1)基于缺页异常的懒加载
出于节约物理内存以及 mmap 方法快速返回的目的,mmap 映射采用懒加载机制。具体来说,通过 mmap 申请 1000G 内存可能仅仅占用了 100MB 的虚拟内存空间,甚至没有分配实际的物理内存空间。当你访问相关内存地址时,才会进行真正的 write、read 等系统调用。CPU 会通过陷入缺页异常的方式来将磁盘上的数据加载到物理内存中,此时才会发生真正的物理内存分配。
(2)数据一致性由 OS 确保
当发生数据修改时,内存出现脏页,与磁盘文件出现不一致。mmap 机制下由操作系统自动完成内存数据落盘(脏页回刷),用户进程通常并不需要手动管理数据落盘。
2.读写效率提高:避免内核空间到用户空间的数据拷贝
简而言之,mmap 被认为快的原因是因为建立了页到用户进程的虚地址空间映射,以读取文件为例,避免了页从内核空间拷贝到用户空间。
3.避免只读操作时的 swap 操作
虚拟内存带来了种种好处,但是一个最大的问题在于所有进程的虚拟内存大小总和可能大于物理内存总大小,因此当操作系统物理内存不够用时,就会把一部分内存 swap 到磁盘上。
在 mmap 下,如果虚拟空间没有发生写操作,那么由于通过 mmap 操作得到的内存数据完全可以通过再次调用 mmap 操作映射文件得到。但是,通过其他方式分配的内存,在没有发生写操作的情况下,操作系统并不知道如何简单地从现有文件中(除非其重新执行一遍应用程序,但是代价很大)恢复内存数据,因此必须将内存 swap 到磁盘上。
4.节约内存
由于用户空间与内核空间实际上共用同一份数据,因此在大文件场景下在实际物理内存占用上有优势。
4. mmap 不是银弹
mmap 不是银弹,这意味着 mmap 也有其缺陷,在相关场景下的性能存在缺陷:
由于 mmap 使用时必须实现指定好内存映射的大小,因此 mmap 并不适合变长文件;
如果更新文件的操作很多,mmap 避免两态拷贝的优势就被摊还,最终还是落在了大量的脏页回写及由此引发的随机 I/O 上,所以在随机写很多的情况下,mmap 方式在效率上不一定会比带缓冲区的一般写快;
读/写小文件(例如 16K 以下的文件),mmap 与通过 read 系统调用相比有着更高的开销与延迟;同时 mmap 的刷盘由系统全权控制,但是在小数据量的情况下由应用本身手动控制更好;
mmap 受限于操作系统内存大小:例如在 32-bits 的操作系统上,虚拟内存总大小也就 2GB,但由于 mmap 必须要在内存中找到一块连续的地址块,此时你就无法对 4GB 大小的文件完全进行 mmap,在这种情况下你必须分多块分别进行 mmap,但是此时地址内存地址已经不再连续,使用 mmap 的意义大打折扣,而且引入了额外的复杂性;
5. mmap 的适用场景
mmap 的适用场景实际上非常受限,在如下场合下可以选择使用 mmap 机制:
多个线程以只读的方式同时访问一个文件,这是因为 mmap 机制下多线程共享了同一物理内存空间,因此节约了内存。案例:多个进程可能依赖于同一个动态链接库,利用 mmap 可以实现内存仅仅加载一份动态链接库,多个进程共享此动态链接库。
mmap 非常适合用于进程间通信,这是因为对同一文件对应的 mmap 分配的物理内存天然多线程共享,并可以依赖于操作系统的同步原语;
mmap 虽然比 sendfile 等机制多了一次 CPU 全程参与的内存拷贝,但是用户空间与内核空间并不需要数据拷贝,因此在正确使用情况下并不比 sendfile 效率差;
————————————————
版权声明:本文为CSDN博主「Young丶」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/agonie201218/article/details/123791047















 5112
5112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









