







MOEA-FCM、RCGAd-FCM、CS-FCM三者介绍及比较
FCM(Fuzzy cognitive maps)
FCM已在之前有所介绍 https://blog.csdn.net/loveC__/article/details/98479162
MOEA-FCM(2013)
文章:Learning of Fuzzy Cognitive Maps with Varying Densities using a Multi-objective Evolutionary Algorithm
摘要
之前学习FCM的算法密度都远高于人类专家建立的FCM,于是将FCM的密度和准确度作为两个目标问题进行建模,MOEA-FCM实验中使用了合成数据和真实数据,使用了不同尺寸(FCM点数目)和稠密程度。实验表明MOEA-FCM不仅能高精度的重建FCM,还能得到不同密度下的Pareto前沿。
介绍
之前自动生成的学习FCM算法密度都超过了90%,而由人类专家知识建立的FCM密度只有40%,只有降低FCM的稀疏程度,才能处理大规模的FCM问题,两个优化的目标分别为:
- 降低输入数据和模拟数据的差别
第一个目标Data_Error,用来评估可用响应序列和生成响应序列的不同
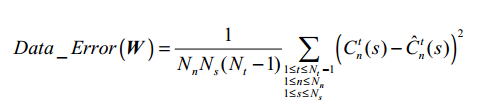
N t N_t Nt是时间序列的长度, N s N_s Ns是响应序列的长度, C n t ( s ) C_{n}^{t}(s) Cnt(s)是第n个点在第s个可用响应序列中第t个状态, C ^ n t ( s ) \hat{C}_{n}^{t}(s) C^nt(s)是第n个点在第s个生成响应序列中第t个状态。 - 降低学习得的FCM的连接密度
第二个目标是Density(稀疏性),评估学习生成的权重矩阵和真实的结构区别
Density ( W ) = M N n × N n \text {Density}(\boldsymbol{W})=\frac{M}{N_{n} \times N_{n}} Density(W)=Nn×NnM
关于符合多目标的讨论:在多目标中,目标应该互相冲突,实验表明,密度增加时,Data_Error会增长缓慢,稠密模型的Data_Error比稀疏模型更接近真实模型的Data_Error,如果以Data_Error作为单一目标进行优化,得到的模型将具有加高的密度,将比实际真实的FCM稠密的多。所以Density和Data_Error将成为两个冲突的目标,应采用多目标技术进行优化。
算法介绍
实质上该算法使用NSGA-II对FCM进行了学习,降低了稀疏性的同时,提高了模型的精确度,因为NSGA-II对两目标问题表现出较好的性能
为使算法适合EA,将其转换为
Maximize
f
1
(
W
)
=
h
(
Data
−
Error
(
W
)
)
Maximize
f
2
(
W
)
=
h
(
Density
(
W
)
)
\begin{array}{ll}{\text { Maximize }} & {f_{1}(\boldsymbol{W})=h\left(\text {Data}_{-} \operatorname{Error}(\boldsymbol{W})\right)} \\ {\text { Maximize }} & {f_{2}(\boldsymbol{W})=h(\text {Density}(\boldsymbol{W}))}\end{array}
Maximize Maximize f1(W)=h(Data−Error(W))f2(W)=h(Density(W))
其中
h
(
x
)
=
1
1
+
α
x
h(x)=\frac{1}{1+\alpha x}
h(x)=1+αx1
该算法使用NSGA-II作为EA的框架。其中快速非支配排序、拥挤距离计算、二元锦标赛选择、模拟二进制交叉和变异方法都和NSGA-II算法一致。
算法流程:
Step1:初始化种群 ,
t
t
t为0,
P
t
P_t
Pt和N个染色体,每个染色体的值在[-1,1]。
Step2:使用非支配快速排序,
F
←
fast-nondominated-sort
(
P
t
)
F \leftarrow \text { fast-nondominated-sort }\left(P_{t}\right)
F← fast-nondominated-sort (Pt)。
Step3:根据排序后的
P
t
P_t
Pt的秩和拥挤距离,采用二元锦标赛选择法从排序后的
P
t
P_t
Pt中选择染色体,并对所选染色体进行交叉和变异操作,生成大小为N的后代群体
Q
t
Q_t
Qt。
Step4:将父代和子代合并至
R
t
R_t
Rt,
R
t
←
P
t
∪
Q
t
R_{t} \leftarrow P_{t} \cup Q_{t}
Rt←Pt∪Qt。
Step5:对
R
t
R_t
Rt使用快速非支配排序,
F
←
fast-nondominated-sort
(
R
t
)
F \leftarrow \text { fast-nondominated-sort }\left(R_{t}\right)
F← fast-nondominated-sort (Rt)。
Step6:令下一代种群
P
t
+
1
P_{t+1}
Pt+1为空,
令
i
=
1
令i=1
令i=1。
Step7:
I
f
∣
P
t
+
1
∣
+
∣
F
i
∣
<
N
,
t
h
e
n
P
t
+
1
←
P
t
+
1
∪
F
i
,
i
←
i
+
1
,
g
o
t
o
S
t
e
p
7
If |P_t+1|+|F_i|<N, then P_t+1←P_t+1∪ F_i, i←i+1, go to Step7
If∣Pt+1∣+∣Fi∣<N,thenPt+1←Pt+1∪Fi,i←i+1,gotoStep7这一步的作用是从之前非支配快速排序得到的F中,选出
i
i
i个元素组成
P
t
+
1
P_{t+1}
Pt+1。
Step8:通过拥挤度分配,根据拥挤距离对
F
i
F_i
Fi进行降序排序。
Step9:将
F
i
F_i
Fi根据排序与
P
t
+
1
P_{t+1}
Pt+1合并成N个染色体组成的新一代种群
P
t
+
1
P_{t+1}
Pt+1。
Step10:t = t +1。
Step11:如果达到最大迭代数,则输出当前种群,否则则转去Step3。
实验
实验中使用了合成数据和真实世界数据;
交叉率为:0.9
变异率为0.5
目标评价次数为
3
×
1
0
6
3 \times 10^{6}
3×106
实验的其他评价标准:
- Model_Error:比较学习到的FCM和目标FCM的权重。
Model − Error = 1 N n 2 ∑ i = 1 N n ∑ j = 1 N n ∣ w i j − w ^ i j ∣ \text {Model}_{-} \text { Error }=\frac{1}{N_{n}^{2}} \sum_{i=1}^{N_{n}} \sum_{j=1}^{N_{n}}\left|w_{i j}-\hat{w}_{i j}\right| Model− Error =Nn21i=1∑Nnj=1∑Nn∣wij−w^ij∣ - Out_of_Sample_Error:评价模型处理过拟合的能力,10个随机初始化的向量作为输入,计算真实模型的响应序列和已经获得的模型生成的响应序列的差值。
Out − of − Sample − Error ( W ) = 1 N s ⋅ ( N t − 1 ) ⋅ N n ∑ t = 1 N s ∑ t = 1 N t − 1 ∣ C n t ( s ) − C ^ n t ( s ) ∣ \text {Out }_{-} \text { of }-\text { Sample }_{-} \text { Error }(W)=\frac{1}{N_{s} \cdot\left(N_{t}-1\right) \cdot N_{n}} \sum_{t=1}^{N_{s}} \sum_{t=1}^{N_{t}-1}\left|C_{n}^{t}(s)-\hat{C}_{n}^{t}(s)\right| Out − of − Sample − Error (W)=Ns⋅(Nt−1)⋅Nn1t=1∑Nst=1∑Nt−1∣∣∣Cnt(s)−C^nt(s)∣∣∣ - SS Mean:为了预测两个概念点之间是否存在连接。
S S Mean = 2 × Specificity × Sensitivity Specificity + Sensitivity S S \text { Mean }=\frac{2 \times \text { Specificity } \times \text { Sensitivity }}{\text { Specificity }+\text { Sensitivity }} SS Mean = Specificity + Sensitivity 2× Specificity × Sensitivity
Specificity = N T P N T P + N F N \text {Specificity}=\frac{N_{T P}}{N_{T P}+N_{F N}} Specificity=NTP+NFNNTP
Sensitivity = N T N N T N + N F P \text {Sensitivity}=\frac{N_{T N}}{N_{T N}+N_{F P}} Sensitivity=NTN+NFPNTN

可以从实验数据看出,MOEA-FCM(37%)大部分的数据优于其他的算法。其中37%是从Pareto最优解中,选出的密度为37%的值。
RCGAd-FCM(2015)
文章:Inferring Causal Networks using Fuzzy Cognitive Maps and Evolutionary Algorithms with Application to Gene Regulatory Network Reconstruction
摘要
该算法从基因表达数据基于分解的GA算法,学习大规模的模糊认知图。将该算法与蚁群优化,差分进化和粒子群优化在一个分解框架中进行了比较。比较结果表明,该算法在数据量小、网络规模大或存在噪声的数据集上具有一定的优越性。
算法介绍
该算法主要应用在适应基因表达数据进行基因调控网络的重建(GRNs),该算法基于实数编码的遗传算法,采用锦标赛的选择方法,采用分解的方式来学习大规模的FCM,从而应用于基因调控网络重建问题上。GA、PSO、DE、ACO和基于梯度的优化算法,这些算法成功应用在没有专家干预学习FCM方面,从而解决了一部分问题如,时间序列预测、工程控制问题和分类问题。
分解前的目标函数,带有稀疏惩罚因子
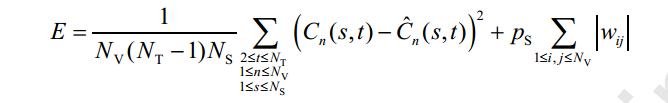
其中
N
V
N_V
NV是FCM节点数目,
N
S
N_S
NS是时间序列的个数,
N
T
N_T
NT是每个时间序列的长度,
P
S
P_S
PS是稀疏惩罚因子,
C
n
(
s
,
t
)
C_n(s,t)
Cn(s,t)是第s个时间序列,第t个时间点,第n个节点的观测数据(已知的输入数据),
C
^
n
(
s
,
t
)
\hat{C}_{n}(s, t)
C^n(s,t)是第s个时间序列,第t个节点,第n个节点的仿真数据(计算得到的)
C
^
n
(
s
,
t
)
=
f
n
(
∑
i
=
1
N
V
w
i
n
C
n
(
s
,
t
−
1
)
)
\hat{C}_{n}(s, t)=f_{n}\left(\sum_{i=1}^{N_{\mathrm{V}}} w_{i n} C_{n}(s, t-1)\right)
C^n(s,t)=fn(i=1∑NVwinCn(s,t−1))
对于每一个节点n的激活函数是
f
n
(
x
)
=
1
1
+
e
−
λ
n
x
f_{n}(x)=\frac{1}{1+e^{-\lambda_{n} x}}
fn(x)=1+e−λnx1
C
^
n
(
s
,
t
)
\hat{C}_{n}(s, t)
C^n(s,t)的计算依赖
λ
n
\lambda _n
λn和第n列的权值矩阵
W
n
W_n
Wn
W
n
=
[
w
1
n
,
w
2
n
,
…
,
w
N
N
,
n
]
T
\mathbf{W}_{n}=\left[w_{1 n}, w_{2 n}, \dots, w_{N_{\mathrm{N}}, n}\right]^{\mathrm{T}}
Wn=[w1n,w2n,…,wNN,n]T
因此分解后目标函数E变成如下
E
n
=
1
(
N
T
−
1
)
N
S
∑
i
=
2
N
T
∑
s
=
1
N
S
(
C
n
(
s
,
t
)
−
C
^
n
(
s
,
t
)
)
2
+
p
S
∑
i
=
1
N
N
∣
w
i
n
∣
E_{n}=\frac{1}{\left(N_{\mathrm{T}}-1\right) N_{\mathrm{S}}} \sum_{i=2}^{N_{\mathrm{T}}} \sum_{s=1}^{N_{\mathrm{S}}}\left(C_{n}(s, t)-\hat{C}_{n}(s, t)\right)^{2}+p_{\mathrm{S}} \sum_{i=1}^{N_{\mathrm{N}}}\left|w_{i n}\right|
En=(NT−1)NS1i=2∑NTs=1∑NS(Cn(s,t)−C^n(s,t))2+pSi=1∑NN∣win∣
可以对比看出分解前和分解后主要是目标函数的变化,原来的目标函数计算的是所有节点的综合,目标函数缺少了
N
V
N_V
NV,现在目标函数结算单个列值作为评价函数。整个优化算法优化的列数n从1到
N
N
N_N
NN的
λ
n
\lambda_n
λn和
W
n
W_n
Wn。
W
=
[
W
1
,
W
2
,
.
.
.
,
W
N
V
]
W = [W_1, W_2,...,W_{N_V}]
W=[W1,W2,...,WNV]
λ
=
[
λ
1
,
λ
2
,
.
.
.
,
λ
N
v
]
\lambda = [\lambda_1, \lambda_2,...,\lambda_{N_v} ]
λ=[λ1,λ2,...,λNv]
基于这种分解方法,将整个计算分解为n个节点,优化过程从
N
V
(
N
V
+
1
)
N_V(N_V+1)
NV(NV+1)to
N
V
+
1
N_V+1
NV+1,这是能够学习大规模FCM的主要因素。
算法流程:

初始化种群:解的形式为
x
j
=
[
W
1
n
,
W
2
n
,
.
.
.
,
W
N
N
,
λ
n
]
x_j=[W_{1n},W_{2n},...,W_{N_N},\lambda_n]
xj=[W1n,W2n,...,WNN,λn]
选择算子:采用二元锦标赛
交叉算子:单点交叉
变异算子:非均匀变异
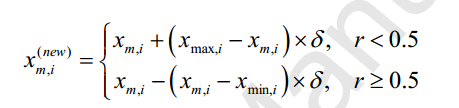
实验
实验数据

其中关于FCM应用在GRN问题上,DREAM数据较为常用。
交叉率:0.6
变异率:0.3
种群大小:100
最大迭代次数:15000
稀疏罚值稀疏在超过100大规模的数据集中设为0.2,在小规模的数据集中设为0
不同算法AUC和AUPR在DREAM4数据集上的表现

可以忽略粗体的数字,只看阴影的值,其中阴影的值是在同一条件下,诸多算法中表现最好的算法。从图中可以直观的得出,RCGAd在学习大规模FCM时有较好的表现。
在大规模的网络上进行比较

同样可以看出在300个节点时,该算法的性能优于其他算法。
CS-FCM(2017)
问章:Learning Large-Scale Fuzzy Cognitive Maps Based on Compressed Sensing and Application in Reconstructing Gene Regulatory Networks
摘要
本文旨在解决基于数据驱动,没有任何先验知识的情况下,学习大规模的稀疏FCM的问题,大量现有的方法速度较慢且在处理大规模FCM问题时有较大的的困难。本文介绍了一种基于压缩感知(CS)的凸规划方法来学习大规模的稀疏FCM(CS-FCM)。则该问题转换为稀疏信号重建问题。CS-FCM可以学习稀疏FCM至1000个节点甚至更多,本文最后用GRN的DREAM3和DREAM4数据进行了测试。
压缩感知(CS)
这边文章对压缩感知写的简单易懂,图文并茂,不一定严谨但容易理解,传送门https://blog.csdn.net/qq_42570457/article/details/82179065

算法介绍
目前自动学习FCM算法的限制
- 准确度较低
- 学习得FCM规模较小
- 计算复杂度高
- 学习得图结构密度太高
所以,快速学习一个高精度大规模稀疏的FCM仍然是一个挑战的问题。
压缩感知(CS)是用一种用在信号和图像处理上的稀疏重建方法。将FCM的稀疏重建问题转换为了稀疏信号的重建问题,由于CS具有数据要求极低、收敛到最优解的严格保证等显著特点,CS-FCM具有较高的精度和效率。
与现有学习不超过500个节点的FCMs方法相比,CS-FCM可以学习1000个节点甚至更多的大规模稀疏FCMs,计算量小,学习的FCMs比现有方法更精确。
首先,将问题分解成节点个体学习局部的连接,因为FCM的稀疏性,所以从时间序列恢复局部结构可以转换稀疏信号重建问题,该问题结合了局部结构的稀疏性和观测数据与模拟数据的差异,即重构误差。
C i ( t + 1 ) = ψ ( ∑ j = 1 N w j i C j ( t ) ) C_{i}(t+1)=\psi\left(\sum_{j=1}^{N} w_{j i} C_{j}(t)\right) Ci(t+1)=ψ(j=1∑NwjiCj(t))
可将上述FCM的公式变为
ψ − 1 ( C i ( t + 1 ) ) = ∑ j = 1 N w j i C j ( t ) \psi^{-1}\left(C_{i}(t+1)\right)=\sum_{j=1}^{N} w_{j i} C_{j}(t) ψ−1(Ci(t+1))=j=1∑NwjiCj(t)
上述公式可以写成 Y i = Φ W i Y_i = \varPhi W_i Yi=ΦWi的形式,其中 Y i Y_i Yi代表不同 t t t下的 ψ − 1 ( C i ( t + 1 ) ) \psi^{-1}\left(C_{i}(t+1)\right) ψ−1(Ci(t+1)), Φ \varPhi Φ代表节点的状态 C j ( t ) C_j(t) Cj(t), W i W_i Wi是节点 i i i和所有节点的向量权重。最终得到以下公式:
Y i = Φ [ w 1 i w 2 i ⋮ w N i ] Y_{i}=\Phi\left[\begin{array}{c}{w_{1 i}} \\ {w_{2 i}} \\ {\vdots} \\ {w_{N i}}\end{array}\right] Yi=Φ⎣⎢⎢⎢⎡w1iw2i⋮wNi⎦⎥⎥⎥⎤
C i k ( t ) C_i^k(t) Cik(t)是第 i i i个节点在第 k k k个观测序列的第 t t t代的状态值。
Φ = [ C 1 1 ( 1 ) C 2 1 ( 1 ) ⋯ C N 1 ( 1 ) ⋮ ⋮ ⋱ ⋮ C 1 1 ( M − 1 ) C 2 1 ( M − 1 ) ⋯ C 2 1 ( M − 1 ) ⋮ ⋮ ⋱ ⋮ C 1 l ( 1 ) C 2 l ( 1 ) ⋯ C N l ( 1 ) ⋮ ⋮ ⋱ ⋮ C 1 l ( M − 1 ) C 2 l ( M − 1 ) ⋯ C N l ( M − 1 ) ] \Phi=\left[\begin{array}{cccc}{C_{1}^{1}(1)} & {C_{2}^{1}(1)} & {\cdots} & {C_{N}^{1}(1)} \\ {\vdots} & {\vdots} & {\ddots} & {\vdots} \\ {C_{1}^{1}(M-1)} & {C_{2}^{1}(M-1)} & {\cdots} & {C_{2}^{1}(M-1)} \\ {\vdots} & {\vdots} & {\ddots} & {\vdots} \\ {C_{1}^{l}(1)} & {C_{2}^{l}(1)} & {\cdots} & {C_{N}^{l}(1)} \\ {\vdots} & {\vdots} & {\ddots} & {\vdots} \\ {C_{1}^{l}(M-1)} & {C_{2}^{l}(M-1)} & {\cdots} & {C_{N}^{l}(M-1)}\end{array}\right] Φ=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡C11(1)⋮C11(M−1)⋮C1l(1)⋮C1l(M−1)C21(1)⋮C21(M−1)⋮C2l(1)⋮C2l(M−1)⋯⋱⋯⋱⋯⋱⋯CN1(1)⋮C21(M−1)⋮CNl(1)⋮CNl(M−1)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
由此可得
Y = [ ψ − 1 ( C 1 1 ( 2 ) ) ψ − 1 ( C 2 1 ( 2 ) ) ⋯ ψ − 1 ( C N 1 ( 2 ) ) ⋮ ⋮ ⋱ ⋮ ψ − 1 ( C 1 1 ( M ) ) ψ − 1 ( C 2 1 ( M ) ) ⋯ ψ − 1 ( C N 1 ( M ) ) ⋮ ⋱ ⋮ ψ − 1 ( C 1 1 ( 2 ) ) ψ − 1 ( C 2 l ( 2 ) ) ⋯ ψ − 1 ( C N l ( 2 ) ) ⋮ ⋱ ⋮ ψ − 1 ( C 1 l ( M ) ) ψ − 1 ( C 2 l ( M ) ) ⋮ ψ − 1 ( C N l ( M ) ) ] Y=\left[\begin{array}{cccc}{\psi^{-1}\left(C_{1}^{1}(2)\right)} & {\psi^{-1}\left(C_{2}^{1}(2)\right)} & {\cdots} & {\psi^{-1}\left(C_{N}^{1}(2)\right)} \\ {\vdots} & {\vdots} & {\ddots} & {\vdots} \\ {\psi^{-1}\left(C_{1}^{1}(M)\right)} & {\psi^{-1}\left(C_{2}^{1}(M)\right)} & {\cdots} & {\psi^{-1}\left(C_{N}^{1}(M)\right)} \\ {\vdots} & {} & {\ddots} & {\vdots} \\ {\psi^{-1}\left(C_{1}^{1}(2)\right)} & {\psi^{-1}\left(C_{2}^{l}(2)\right)} & {\cdots} & {\psi^{-1}\left(C_{N}^{l}(2)\right)} \\ {\vdots} & {} & {\ddots} & {\vdots} \\ {\psi^{-1}\left(C_{1}^{l}(M)\right)} & {\psi^{-1}\left(C_{2}^{l}(M)\right)} & {\vdots} & {\psi^{-1}\left(C_{N}^{l}(M)\right)}\end{array}\right] Y=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡ψ−1(C11(2))⋮ψ−1(C11(M))⋮ψ−1(C11(2))⋮ψ−1(C1l(M))ψ−1(C21(2))⋮ψ−1(C21(M))ψ−1(C2l(2))ψ−1(C2l(M))⋯⋱⋯⋱⋯⋱⋮ψ−1(CN1(2))⋮ψ−1(CN1(M))⋮ψ−1(CNl(2))⋮ψ−1(CNl(M))⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
因此面对该问题,为了解决一个节点i到所有节电池的稀疏结构,我们需要建立L1规则化方法,如下
min W i ∥ W i ∥ 1 s.t. Y i = Φ W i ( 1 ) \begin{array}{l}{\min _{W_{i}}\left\|W_{i}\right\|_{1}} \\ {\text { s.t. } Y_{i}=\Phi W_{i}}\end{array} (1) minWi∥Wi∥1 s.t. Yi=ΦWi(1)
算法流程如下:
D为观察数据
Step1:i=1,通过D去获取 Φ 和 Y \Phi和Y Φ和Y;
Step2:对于节点i,建立(1)的目标函数;
Step3: W i ← SIPM ( Φ , Y i ) W_{i} \leftarrow \operatorname{SIPM}\left(\Phi, Y_{i}\right) Wi←SIPM(Φ,Yi),通过 Φ \Phi Φ和Y来得出W, 使用标准内部点方法。
Step4:i=1+1
Step5:如果i>N,则停止;否则转去Step2。
问题变成线性问题后则可以用SIPM来进行求解,比如原对偶路径跟踪内点法
复杂度分析
- 空间复杂度:需要两部分主要的存储空间,首先需要存储D(观察数据),Y(前面有定义)和 Φ \Phi Φ(前面有定义),需要O(MN),第二部分是提供给标准内点法(SIPM),时间复杂度为O(MN),因此空间复杂度为O(MN)。
- 时间复杂度:最主要的算法开销在Step3和Step1,这两者都是线性时间。 根据对SIPM的描述,CS-FCM的总时间复杂度为 O ( M A X I T E R × 2 M N 3 ) O(MAXITER \times 2MN^3) O(MAXITER×2MN3)
实验
评估标准为(上述有详细介绍):Data_Error、Out_of_Sample_Error、Model_Error、SS_Mean。
- 数据长度对CS-FCM的影响
数据长度 N t N_t Nt越大则效果越好,在CS-FC M中即使 N t N_t Nt很小,也能识别出大部分的连接, N t N_t Nt越大则会有更高的SS_Mean(越大越好),更低的Model_Error(越小越好)和更低的Out_of_Sample_Error(越小越好)。Data_Error也可以维持在一个较低的水平。 - 稀疏度对CS-FCM的影响
当密度增加时,SS_Mean减少,Model_Error增加,Out_of_Sample_Error增加,而Data_Error一直维持在一个较低的水平。稠密的FCM比稀疏的FCM需要更大的数据长度 N t N_t Nt。首先,对于致密FCMs、W的稀疏性较差,导致CS的预测误差较大。其次,对于具有大量邻居的节点,其每次受影响的概率都很大。 - 噪声对CS-FCM的影响,实验中加入了不同程度的高斯噪声,实验表明,随着噪声程度的增加,CS-FCM的性能在逐渐降低。
可以看出数据长度 N t N_t Nt越长准确率越高。
算法与LASSO-FCM、dMAGA、ACOrd、D&C RCGA RCGA进行了比较,在小规模和大规模数据中,得到了较好的结果。















 644
644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









