







 探讨了新高考模式下,遗传算法如何有效解决排课问题,包括避免学生、教师和教室的时间冲突,以及满足连堂和上下午课程安排的需求。
探讨了新高考模式下,遗传算法如何有效解决排课问题,包括避免学生、教师和教室的时间冲突,以及满足连堂和上下午课程安排的需求。
新高考模式下遗传算法在排课问题中的应用
背景: 随着新高考改革在各个省份的推行,提出了“3+3模式”,即高中阶段的学生,不再区分文理科目,学生可以自主的从政治、历史、地理、物理、化学、生物和技术这7门课程里任选3门作为高考的考试科目。
学校将班级分为行政班与教学班两类,行政班则于传统教学模式的班级相同,教学班是为不同行政班学生上选修课程组成的临时班级。一个学生的课程由行政班课程和选修课程组成,行政班课程由其所在的行政班开设,教学班课程则需要不同的行政班学生走到特定教室上课,此种上课方式在本文中统称为“走班制”,本文重点讨论排课问题,走班制的分班策略不在这里进行讨论。
需要解决的问题:
-
硬约束
1. 学生上课不能冲突:即行政班与教学班课程上课时间不能重合
2. 教师上课不能冲突:教师不能在同时段给不同的班带课
3. 教室分配不能冲突:行政班在本班上课,主要针对教学班和特殊课程(如技术)不同班使用不能冲突,且不能超出教室容量上限。 -
软约束
1. 课程连堂:同一天同一个午别(上午/下午)一个班的n个相邻课安排为相同的科目
2. 上下午不能连续上课:以老师的角度观察,每天上午最后一节课和下午第一节不能同时有课
基于二维染色体的遗传算法解决排课问题
二维实数编码
本文遗传算法的染色体由一个二维数组表示,其行数和列数分别代表班级总数和教学课时总数,染色体C++语言定义如下:
class individual
{
public:
vector<vector<int>> chromo; //二维编码
double fitness; //适应度
double cal_fitness; //累积适应度,用于轮盘赌
int generation; //进化代数
}
每个单元格(基因)构成一个课程单元,课程单元记录了年级ID、班级ID、班级类型、课程ID、教室ID、教室容量、教师ID等信息,染色体和课程单元C++语言定义如下:
struct course_elem
{
int grade_id; //年级ID
int class_id; //班级ID
int class_type; //1-教学班,2-走班
int course_id; //课程ID
int teacher_id; //老师ID
int room_id; //教室ID
int capacity; //教室容量
int period_B; //两节连堂数
int period_C; //三节连堂数
};
染色体中填充为每个单元格的序号,故算法使用二维实数编码方式,这样的编码方式则可以很好的将设计应用到时间维上,将时间维划分为几个区块,如上午、下午等,可以更好的实施课程对时间段的要求,假设一天为上午5节课、下午4节课、一周5天,如下表所示。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | … | 44 | 45 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 行政1班 | ||||||||||
| 行政2班 | ||||||||||
| 行政3班 | ||||||||||
| … | ||||||||||
| 行政N班 | ||||||||||
| 教学1班 | ||||||||||
| 教学2班 | ||||||||||
| … | ||||||||||
| 教学N班 |
适应度函数
f
i
f_i
fi表示个体
i
i
i的硬约束条件冲突数,个体在当前排课方案中每违背一次约束条件,
f
i
f_i
fi值就加1。
g
i
g_i
gi表示个体
i
i
i软约束的冲突数。对于一个可行的排课方案,硬约束条件必须得到满足,而软约束条件可以满足,也可以不满足。因此硬约束的在适应度函数中所占权重要远大于软约束的权重。则适应度函数可以表示为:
F
i
=
f
i
2
+
g
i
,
i
=
1
,
2
,
3......
,
p
o
p
s
i
z
e
F_i = f_i^2 + g_i , i = 1,2,3......,popsize
Fi=fi2+gi,i=1,2,3......,popsize
选择
轮盘赌,又称为比例选择方法,其基本思想是:各个个体被选中的概率与其适应度大小成正比。
- 计算每个个体的适应度F;
- 计算每个个体的遗传概率;
P ( x i ) = f ( x i ) ∑ j = 1 N f ( x j ) P(x_i) =\frac {f(x_i)} { \sum_{j=1}^Nf(x_j)} P(xi)=∑j=1Nf(xj)f(xi) - 计算每个个体的累积概率;
q i = ∑ j = 1 i P ( x j ) q_i= \sum_{j=1}^iP(x_j) qi=j=1∑iP(xj) - 在[0,1]区间内产生一个均匀分布的伪随机数r;
- 若r<q[1],则选择个体1,否则,选择个体k,使得:q[k-1]<r≤q[k] 成立;
- 重复(4)、(5)共N次。
轮盘赌的特点是,数值大的扇区,其被选中的概率大。可以实现种群中个体被选中的概率与个体适应值成正比。
在遗传操作的过程中,适应度值大的个体有较大的几率被选中,适应度低的个体则可能被淘汰。在种群的进化中,这样的选择算法保留了适应度好的接近目标解的个体。
交叉
交叉操作采用分块小基因交叉算法,即每个班的课程单元只能在相同的班级进行交叉操作,而不能跨班(行)进行交叉。例如两个个体进行交叉时,只能个体1的1班行基因与个体2的1班行基因进行交换。这样的操作不会破坏班级对课程和课时的要求。
为保证交换后各班的基因(课程单元)不重复,使用TSP实数编码的染色体交叉方法。下面举例说明交叉运算的过程。
- 任意选择一对染色体i,j作为父代的个体1和父代个体2;
- 生成一个随机数p,与交叉概率 进行比较,若p小于 则进行交叉操作(3),否则直接将父代1与父代2直接复制到自带种群中;
- 随机产生两个随机数 与 , 为该班基因编号的左边界, 为右边界。 与 中间的部分即为要交换的基因段。假设 =3, =5如下图所示。
父代个体1
| 2 | -1 | 3 | 0 | 1 | 4 | 5 | -2 | -6 | -7 |
父代个体2
| 0 | 1 | 3 | 2 | 5 | 7 | -2 | -1 | -4 | 6 |
父代个体1
| 0 | -1 | 3 | 2 | 5 | 4 | 1 | -2 | -6 | -7 |
父代个体2
| 2 | 5 | 3 | 0 | 1 | 7 | -2 | -1 | 4 | 6 |
变异
变异的过程是针对每个染色体个体内部的,为保证每个班级的既定的课程课时所以同交叉相同,变异操作限制在每个班级的基因段中。下图是变异前的染色体块,生成一个随机数p,与变异概率 p m p_m pm比较,若p< p m p_m pm则对该染色体个体进行变异操作。
变异前染色体块
| 24 | -1 | 25 | 23 | 20 | 24 | 22 | -2 | -3 | 21 |
变异后染色体块
| 24 | -1 | 25 | -2 | 20 | 24 | 22 | 23 | -3 | 21 |
算法流程
软硬约束冲突检测
代码皆为matlab伪代码
- 检测学生上课冲突
算法 1: 检测学生上课冲突
输入:
stu(学生选课信息);
stu_num:学生人数
popsize:种群大小;
length:个体一周的课时数;
Adm_num:行政班数量;
Edu_num:教学班数量;
输出:
Stu_conflict:学生上课冲突数;
t←1;
while (t < popsize) do
for i=1 to stu_num do
得到学生教学班班号Edu_ClassCode
得到学生教学班班号Adm_ClassCode
for j=1 to Edu_num do
if(教学班班号 == ClassCode) then
for k=1 to Adm_num do
if(行政班班号 == Adm_ClassCode) then
判断该列对应行政班的课程单元编号是否为负
if(课程单元编号 > -1)
Stu_conflict++;
end if;
end if;
k←k+1;
end for;
end if;
j←j+1;
end for;
i←i+1;
end for;
t←t+1;
end while.
- 教师上课冲突
算法 2: 教师上课冲突
输入:
Individual(个体信息);
popsize:种群大小;
length:个体一周的课时数;
All_num:全部班数量;
输出:
Tesc_conflict: 教师上课冲突数;
t←1;
while (t < popsize) do
for i=1 to length do
for j=1 to All_num do
将所有的班级及其对应的课程ID存入新的二维矩阵record中
j←j+1;
end for;
将每个record的重复内容进行统计并赋值给Num
Tesc_conflict = Tesc_conflict + Num
i←i+1;
end for;
t←t+1;
end while.
- 教室使用冲突
输入:
Individual(个体信息);
popsize:种群大小;
length:个体一周的课时数;
All_num:全部班数量;
输出:
Room_conflict: 教室使用冲突数;
t←1;
while (t < popsize) do
for i=1 to length do
for j=1 to All_num do
将所有的班级及其对应的教室ID存入新的二维矩阵record中
j←j+1;
end for;
将每个record的重复内容进行统计并赋值给Num
Room_conflict = Tesc_conflict + Num
i←i+1;
end for;
t←t+1;
end while.
- 连堂设置冲突
算法 4: 连堂设置冲突
输入:
Individual(个体信息);
popsize:种群大小;
Course_num:每个行政班包含的课程数量;
Edu_num:教学班数量;
Period_B:该课既定的二连堂数
Period_C:该课既定的三连堂数
输出:
Con_conflict: 连堂冲突数;
t←1;
while (t < popsize) do
for i=1 to Edu_num do
for j=1 to Course_num do
times←1;
p1←0;
p2←0;
period_Btimes←0;
period_Ctimes←0;
获取当前课程courseID
for k=1 to length do
if(course_id == courseID) then
if(times == 1)
p1 = j;
end if;
times←times+1;
else
if(times >1)
p2=j;
if(p2 – p1 >2)
period_Btimes++;
else if(p2-p1 > 2)
period_Ctimes++;
end if;
times =1;
end if;
end if;
k←k+1;
end for;
j←j+1;
con_conflict +=abs(Period_B - period_Btimes)+abs(Period_B - period_Btimes);
end for;
i←i+1;
end for;
t←t+1;
end while.
- 上下午排课冲突
输入:
Individual(个体信息);
popsize:种群大小;
Edu_num:教学班数量;
Day_num:一周需要上课的天数;
Up_num:上午需要上课数;
Down_num:下午需要上课数;
输出:
Uad_conflict: 上下午排课冲突数;
t←1;
while (t < popsize) do
for i=1 to Edu_num do
for j=1 to Day_num do
for k=1 to Up_num do
获得上午当前的课程upcourse_id;
for m=1 to Down_num do
获得下午当前的课程downcourse_id;
if(upcourse_id == downcourse_id) then
Uad_num++;
end if;
m←m+1;
end for;
k←k+1;
end for;
j←j+1;
end for;
i←i+1;
end for;
t←t+1;
end while.
结果分析
- 二元锦标赛与轮盘赌选择对比
二元锦标赛每次随机选择2个个体(放回的采样),从种群中随机选择2个个体,根据适应度值,选择适应度值最好的个体进入下一代种群。这使得适应值好的个体有更大的“生存机会”,而适应度差的被选中的机会很小,这样很容易产生超级个体,从而收敛速度比较快。
轮盘赌选择利用各个个体适应度所占的比例大小决定其子孙保留的可能性,为了选择子代个体,需要进行多轮选择,每一轮产生一个[0,1]均匀随机数,将该随机数作为选择指针来确定被选个体。由于随机操作的原因,这种选择方法的选择误差也比较大,有时连适应度较高的个体也选择不上。
本文使用了四个数据集基于遗传算法的排课问题,分别使用二元锦标赛和轮盘赌选择法进行对比,如图4.1所示,其中蓝色折线为轮盘赌选择算子,红色折线为二元锦标赛选择算子。
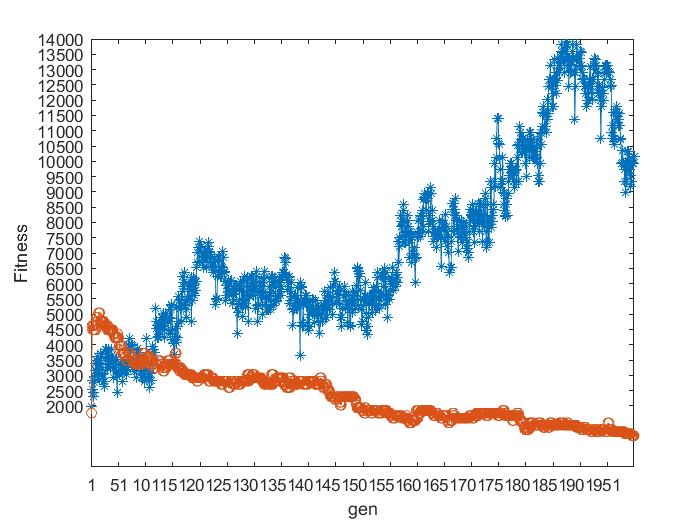
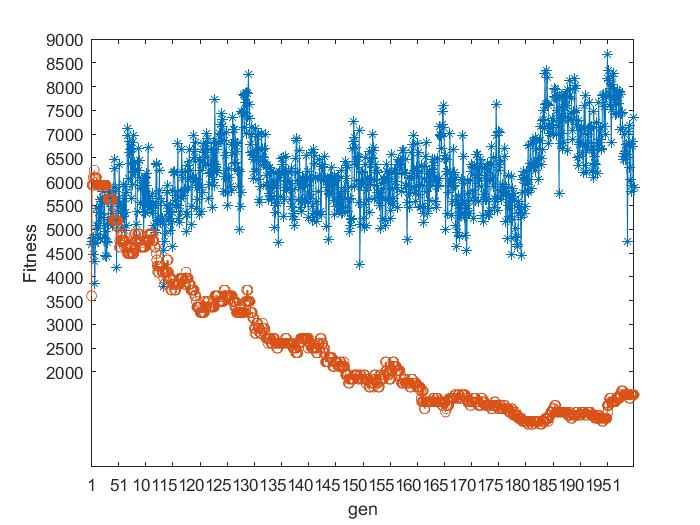
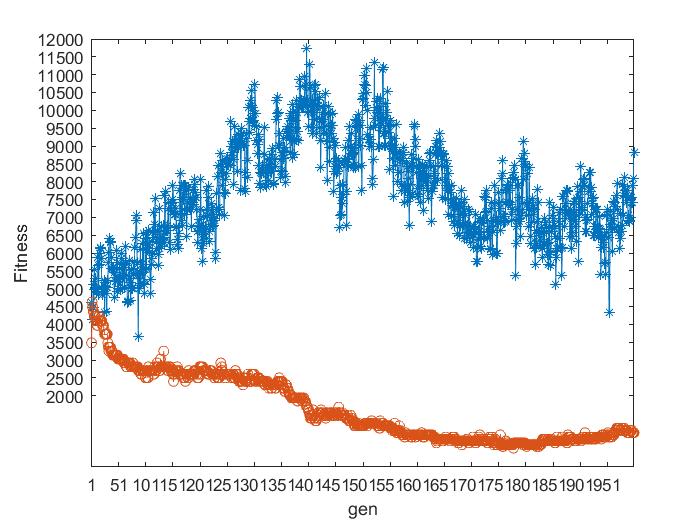
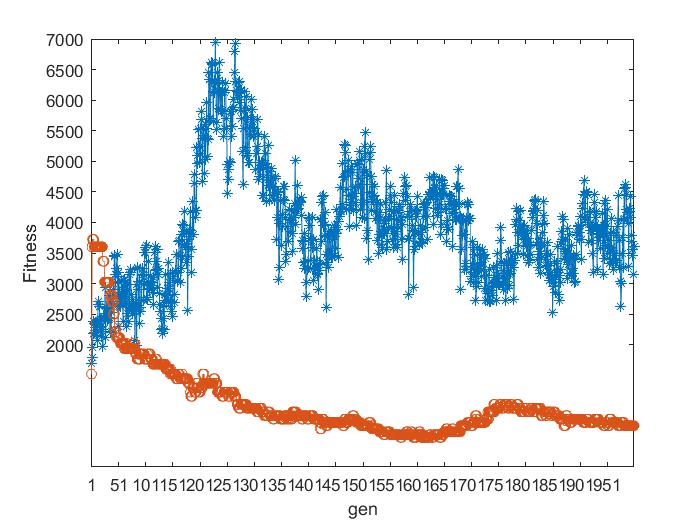
可以看出二元锦标赛选择法是呈收敛趋势,轮盘赌选择算法效果较差,不呈现出收敛的趋势。其中该方法不能全局收敛的主要原因是由于存在统计误差,依据产生的随机数进行选择,有可能会出现不正确反应个体适应度的选择,可能导致适应度高的个体也被淘汰掉。
Rudolph已经采用有限马尔可夫链理论证明了仅采用交叉、变异和选择(轮盘赌选择法)三个遗传算子的标准遗传算法(Canonical Genetic Algorithm CGA),不能收敛到全局最优值。由此需要算法需要引入一个重要的收敛策略-精英保留策略。
2. 个体精英保留策略与群体精英保留策略对比
个体精英保留策略是将父代中适应度最好的个体,不经过变异与交叉操作直接进入子代中,替换子代中适应度最差的个体。
群体精英保留策略是将父代种群和子代种群合并后,选择其中最优的N个(种群大小)个体构成下一代个体。下图为四个数据集基于轮盘赌选择方法采用不同的保留策略的测试结果。
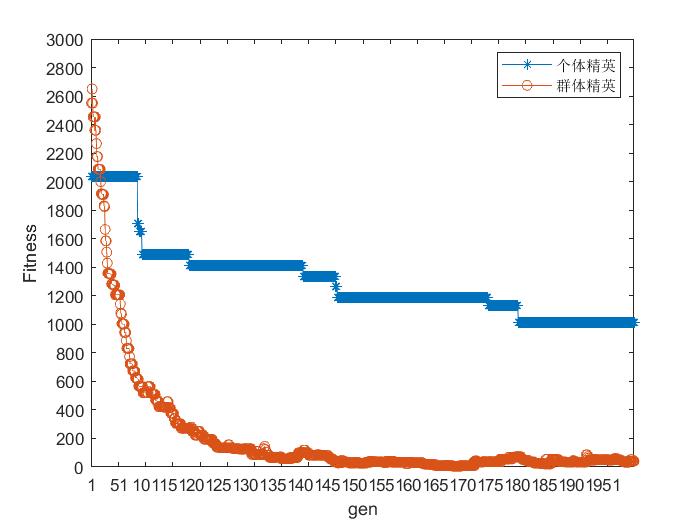
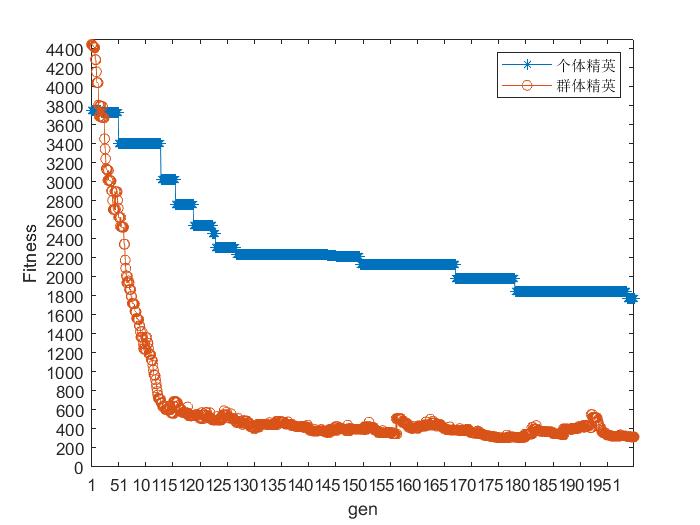
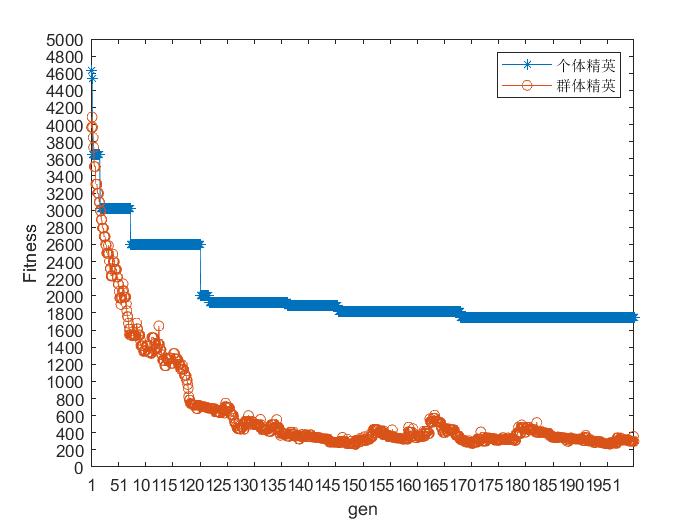

















 1036
1036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









