







文章目录
如何评估?
简单线性回归 的 目标是找到 a 和 b 使得 ∑ i = 1 m ( y t r a i n ( i ) − a x t r a i n ( i ) − b ) 2 \sum^m_{i=1} (y_{train}^{(i)} - ax_{train}^{(i)} - b )^2 ∑i=1m(ytrain(i)−axtrain(i)−b)2 尽可能小。
这个式子也可以表示为 ∑ i = 1 m ( y t r a i n ( i ) − y ^ t r a i n ( i ) ) 2 \sum^m_{i=1} ( y_{train}^{(i)} - \hat{y}_{train}^{(i)} )^2 ∑i=1m(ytrain(i)−y^train(i))2
训练完成后得到 y ^ t r a i n ( i ) = a x t e s t ( i ) + b \hat{y}_{train}^{(i)} = ax_{test}^{(i)} + b y^train(i)=axtest(i)+b
MSE
所以衡量回归问题的标准可以是(m 是测试数据集的个数):
1 m ∑ i = 1 m ( y t e s t ( i ) − y ^ t e s t ( i ) ) 2 \frac{1}{m} \sum^m_{i=1} ( y_{test}^{(i)} - \hat{y}_{test}^{(i)} )^2 m1∑i=1m(ytest(i)−y^test(i))2
这个标准也叫 均方误差MSE(Mean Squared Error);
RMSE
MSE 的问题是,得到的数值是 量纲的平方,所以需要开根号,得到的公式称为 均方根误差 RMSE(Root Mean Squared Error )
1 m ∑ i = 1 m ( y t e s t ( i ) − y ^ t e s t ( i ) ) 2 = M S E t e s t \sqrt{ \frac{1}{m} \sum^m_{i=1} ( y_{test}^{(i)} - \hat{y}_{test}^{(i)} )^2 } = \sqrt{ MSE_{test} } m1∑i=1m(ytest(i)−y^test(i))2=MSEtest
MSE 和 RMSE 区别不大,主要看对量纲的敏感性。
线性回归还有另一个评测方法:平均绝对误差 MAE (Mean Absolute Error)
1 m ∑ i = 1 m ∣ y t e s t ( i ) − y ^ t e s t ( i ) ∣ \frac{1}{m} \sum^m_{i=1} | y_{test}^{(i)} - \hat{y}_{test}^{(i)} | m1∑i=1m∣ytest(i)−y^test(i)∣
绝对值不是处处可导,所以没有用在损失函数中;但绝对值完全可以用来评价。
评价一个算法的标准 和 训练模型使用的最优化函数的标准 是可以完全不一致的。
RMSE & MAE
RMSE 得到的值一般比 MAE 大;
RMSE 有平方操作,会放大样本中预测结果和真实结果 较大误差 的趋势。MAE 没有这个趋势。
所以一般来讲,让 RMSE 尽量小(比 MAE )意义更大,因为这意味着 样本的错误中,最大的错误值 相应的比较小。
R Square
分类问题的评估 比较简单,主要看 分类的准确度,在 0–1 之间进行取值。
但 RMSE 和 MAE 没有这种性质,R Square (也可读作 R方)这个方法解决了这个问题。
R 方比较重要,使用比较广泛。
公式:
R
2
=
1
−
S
S
r
e
s
i
d
u
a
l
S
S
t
o
t
a
l
=
1
−
∑
i
(
y
^
(
i
)
−
y
(
i
)
)
2
∑
i
y
‾
(
i
)
−
y
(
i
)
)
2
R^2 = 1 - \frac{ SS_{residual} }{ SS_{total} } = 1 - \frac{ \sum_i ( \hat{y}^{(i)} - y^{(i)} )^2 }{ \sum_i \overline{y}^{(i)} - y^{(i)} )^2 }
R2=1−SStotalSSresidual=1−∑iy(i)−y(i))2∑i(y^(i)−y(i))2
= 1 − ( ∑ i ( y ^ ( i ) − y ( i ) ) 2 ) / m ( ∑ i y ‾ ( i ) − y ( i ) ) 2 ) / m = 1 − M S E ( y ^ , y ) V a r ( y ) = 1 - \frac{ (\sum_i ( \hat{y}^{(i)} - y^{(i)} )^2 )/m }{ (\sum_i \overline{y}^{(i)} - y^{(i)} )^2)/m } = 1 - \frac{MSE( \hat{y}, y )}{ Var(y) } =1−(∑iy(i)−y(i))2)/m(∑i(y^(i)−y(i))2)/m=1−Var(y)MSE(y^,y)
residual:Residual Sum of Squares
total:Total Sum of Squares
分子 ∑ i ( y ^ ( i ) − y ( i ) ) 2 \sum_i ( \hat{y}^{(i)} - y^{(i)} )^2 ∑i(y^(i)−y(i))2 代表使用我们的模型来预测,产生的错误;
分母 ∑ i y ‾ ( i ) − y ( i ) ) 2 \sum_i \overline{y}^{(i)} - y^{(i)} )^2 ∑iy(i)−y(i))2 ,也可以看做一个模型,代表使用 $ y = \overline{y} $ 预测产生的错误。这是个很朴素的预测结果,在统计学领域称为 基准模型(Baseline Model);这个模型预测的错误率是比较高的。
使用 1 来减去这个分数,相当于 我们的模型没有产生错误的比率。
R 方特性
- R^2<= 1
- R^2 越大越好。当我们的预测模型不犯任何错误时,R^2 取得最大值1;
- 当我们的模型等于基准模型时,R^2为0,是最差的情况;
- 如果R^2< 0,说明我们学习到的模型还不如基准模型。此时,很有可能我们的数据不存在任何线性关系。
示例:SKLearn 预测boston 房价数据并评估
读取、查看数据特征
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
boston = datasets.load_boston()
boston.keys()
# dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])
boston.DESCR
# 有 13 个特征
boston.feature_names
# array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT'], dtype='<U7')
boston.data
'''
array([[6.3200e-03, 1.8000e+01, 2.3100e+00, ..., 1.5300e+01, 3.9690e+02,
4.9800e+00],
...,
[6.0760e-02, 0.0000e+00, 1.1930e+01, ..., 2.1000e+01, 3.9690e+02, 5.6400e+00],
[4.7410e-02, 0.0000e+00, 1.1930e+01, ..., 2.1000e+01, 3.9690e+02, 7.8800e+00]])
'''
x = boston.data[:,5] # 取第五列数据,使用房间数量这个特征
x.shape # (506,)
y = boston.target
y # array([24. , 21.6, 34.7, 33.4, 36.2, 28.7, 22.9, 27.1, 16.5, 18.9, 15. , 20.6, 21.2, 19.1, 20.6, 15.2, 7. , 8.1,...20.6, 23.9, 22. , 11.9])
先做一个简单线性回归
## 看看数据分布
plt.scatter(x, y)
# 最上方分布的点,贴近最大值,可能是异常点,采集的时候计量的限制值。
去除异常值
# 确认有最大值
np.max(y) # 50.0
# 删除最大值的点
x = x[y < 50.0]
y = y[y < 50.0]
plt.scatter(x, y)
# 这里就没有上述的边缘点了

训练数据
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split( x, y, test_size=0.2, random_state=42)
x_train.shape, x_test.shape # ((392,), (98,))
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
x_train = x_train.reshape(-1, 1)
y_train = y_train.reshape(-1, 1)
lr.fit(x_train, y_train)
# LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
# 斜率,权重列表
lr.coef_ # array([[8.24882251]])
# 截距 bias值
lr.intercept_ # array([-29.6721626])
plt.scatter(x_train, y_train)
plt.plot(x_train, lr.predict(x_train), color='r')
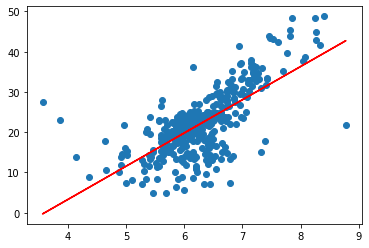
预测并评估
# 预测
y_predict = lr.predict(x_test.reshape(-1,1))
y_test = y_test.reshape(-1,1)
## 计算 MSE
mse_test = np.sum((y_predict - y_test)**2) / len(y_test)
mse_test # 31.763084786207326
## RMSE
rmse_test = np.sqrt(mse_test)
rmse_test # 5.6358748022119265
# MAE
mae_test = np.sum( np.abs(y_predict - y_test)) / len(y_test)
mae_test # 3.9395943900511363
# R Square
rsquare = 1 - mean_squared_error(y_test, y_predict)/ np.var(y_test)
rsquare # 0.37823504497807936
使用 sklearn.metrics 中的方法进行评估
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# mse
mean_squared_error(y_test, y_predict) # 31.763084786207326
# mae
mean_absolute_error(y_test, y_predict) # 3.9395943900511363
# R Square
r2_score(y_test, y_predict) # 0.37823504497807936
PyTorch 中的损失函数
mse
import torch.nn as nn
import torch
mse = nn.MSELoss()
t1 = torch.randn(5, requires_grad=True)
t2 = torch.randn(5, requires_grad=True)
# t1 tensor([-0.5326, -2.1040, -0.0849, 0.0078, -0.3299], requires_grad=True)
# t2 tensor([-0.3427, 0.5773, -0.8011, -0.6496, -0.9095], requires_grad=True)
mse(t1, t2)
# tensor(1.7013, grad_fn=<MseLossBackward>)
二分类 bce
t1 = torch.randn(5, requires_grad=True)
# t1 tensor([ 0.3398, 0.8650, -1.2867, -1.4845, 0.6145], requires_grad=True)
# 分类标签概率值
t1s = torch.sigmoid(t1) # 求 sigmoid 函数,转化为 (0,1) 之间的概率
# t1s tensor([0.5841, 0.7037, 0.2164, 0.1847, 0.6490], grad_fn=<SigmoidBackward>)
# 目标数据值;随机生成 0,1 的整数序列,并转化为浮点数
t2 = torch.randint(0, 2, (5, )).float()
# t2 tensor([1., 0., 1., 1., 0.])
bce = nn.BCELoss()
bce(t1s, t2) # 计算二分类的交叉熵;接收的两个参数都必须是浮点数
# tensor(1.2041, grad_fn=<BinaryCrossEntropyBackward>)
# 对数(Logits)交叉损失函数;可以直接省略 sigmoid 计算部分;自动在函数内部添加 sigmoid 激活函数;
# 在训练时,使用这个函数可以增加计算数值的稳定性。
bce_logits = nn.BCEWithLogitsLoss()
bce_logits(t1, t2) # 与上方结果一致
# tensor(1.2041, grad_fn=<BinaryCrossEntropyWithLogitsBackward>)
多分类
N = 10 # 分类数目
t1 = torch.randn(5, N, requires_grad=True)
t2 = torch.randint(0, N, (5, ))
# t2 tensor([7, 5, 3, 2, 5])
t1s = nn.functional.log_softmax(t1, -1)
# 负对数似然函数。
# 根据预测值(经过 softmax 的计算和对数计算) 和目标值(使用独热编码)计算这两个值 按照一一对应的乘积,然后对乘积求和,并取负值。
# 使用它之前,必须先计算 softmax 函数取对数的结果。
n11 = nn.NLLLoss()
n11(t1s, t2)
# tensor(2.3953, grad_fn=<NllLossBackward>)
# 可以避免 LogSoftmax 计算
# 在损失函数中整合 Softmax 输出概率,以及对概率取对数输出损失函数
ce = nn.CrossEntropyLoss()
ce(t1, t2)
# tensor(2.3953, grad_fn=<NllLossBackward>)



















 2504
2504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











