







本文转载自:使用 SpeechT5 进行语音合成、识别和更多功能 (发表于 2023年2月8日)
https://huggingface.co/blog/zh/speecht5
我们很高兴地宣布,SpeechT5 现在可用于 🤗 Transformers (一个开源库,提供最前沿的机器学习模型实现的开源库)。
SpeechT5 最初见于微软亚洲研究院的这篇论文 SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing。论文作者发布的 官方检查点 可在 Hugging Face Hub 上找到。
如果您想直接尝试,这里有一些在 Spaces 上的演示:
一、SpeechT5 介绍
SpeechT5 不是一种,也不是两种,而是一种架构中的三种语音模型。
它可以做:
- 语音到文本 用于自动语音识别或说话人识别;
- 文本转语音 用于合成音频;
- 语音到语音 用于在不同语音之间进行转换或执行语音增强。
SpeechT5 背后的主要思想是在文本到语音、语音到文本、文本到文本和语音到语音数据的混合体上预训练单个模型。这样,模型可以同时从文本和语音中学习。这种预训练方法的结果是一个模型,该模型具有由文本和语音共享的隐藏表示的 统一空间。
SpeechT5 的核心是一个常规的 Transformer 编码器 - 解码器 模型。就像任何其他 Transformer 一样,编码器 - 解码器网络使用隐藏表示对序列到序列的转换进行建模。这个 Transformer 骨干对于所有 SpeechT5 任务都是一样的。
为了使同一个 Transformer 可以同时处理文本和语音数据,添加了所谓的 pre-nets 和 post-nets。per-nets 的工作是将输入文本或语音转换为 Transformer 使用的隐藏表示。post-nets 从 Transformer 获取输出并将它们再次转换为文本或语音。
下图展示了 SpeechT5 的架构 (摘自 原始论文)。
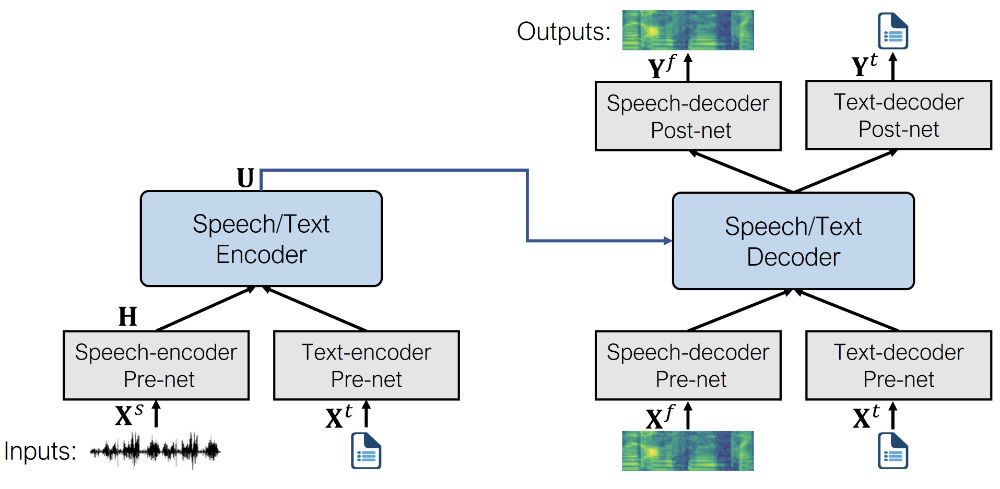
在预训练期间,同时使用所有的 per-nets 和 post-nets 。预训练后,整个编码器 - 解码器主干在单个任务上进行微调。这种经过微调的模型仅使用特定于给定任务的 per-nets 和 post-nets 。例如,要将 SpeechT5 用于文本到语音转换,您需要将文本编码器 per-nets 交换为文本输入,将语音解码器 per-nets 和 post-nets 交换为语音输出。
注意: 即使微调模型一开始使用共享预训练模型的同一组权重,但最终版本最终还是完全不同。例如,您不能采用经过微调的 ASR 模型并换掉 per-nets 和 post-nets 来获得有效的 TTS 模型。SpeechT5 很灵活,但不是 那么 灵活。
二、文字转语音
SpeechT5 是我们添加到 🤗 Transformers 的 第一个文本转语音模型,我们计划在不久的将来添加更多的 TTS 模型。
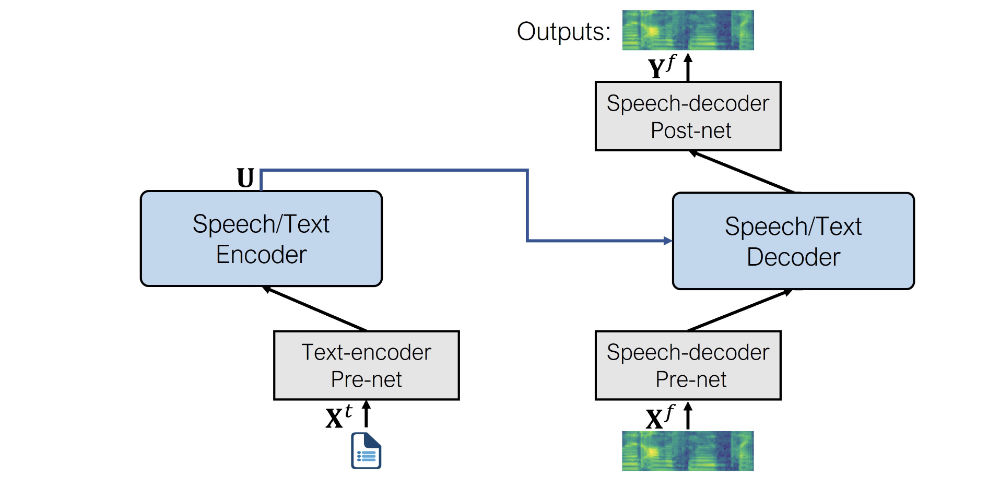
对于 TTS 任务,该模型使用以下 per-net 和 post-net:
- 文本编码器 per-net。 一个文本嵌入层,将文本标记映射到编码器期望的隐藏表示。类似于 BERT 等 NLP 模型中发生的情况。
- 语音解码器 per-net。 这将对数梅尔频谱图作为输入,并使用一系列线性层将频谱图压缩为隐藏表示。此设计取自 Tacotron 2 TTS 模型。
- 语音解码器 post-net。 这预测了一个残差以添加到输出频谱图中并用于改进结果,同样来自 Tacotron 2。
微调模型的架构如下所示。
以下是如何使用 SpeechT5 文本转语音模型合成语音的完整示例。您还可以在 交互式 Colab 笔记本 中进行操作。
SpeechT5 在最新版本的 Transformers 中尚不可用,因此您必须从 GitHub 安装它。还要安装附加的依赖语句,然后重新启动运行。
pip install git+https://github.com/huggingface/transformers.git
pip install sentencepiece
首先,我们从 Hub 加载 微调模型,以及用于标记化和特征提取的处理器对象。我们将使用的类是 SpeechT5ForTextToSpeech。
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")
接下来,标记输入文本。
inputs = processor(text="Don't count the days, make the days count.", return_tensors="pt")
SpeechT5 TTS 模型不限于为单个说话者创建语音。相反,它使用所谓的 speaker embeddings 来捕捉特定说话者的语音特征。我们将从 Hub 上的数据集中加载这样一个 Speaker Embeddings。
from datasets import load_dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
import torch
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
speaker embeddings 是形状为 (1, 512) 的张量。这个特定的 Speaker Embeddings 描述了女性的声音。使用 此脚本 从 CMU ARCTIC 数据集获得嵌入 /utils/prep_cmu_arctic_spkemb.py,任何 X-Vector 嵌入都应该有效。
现在我们可以告诉模型在给定输入标记和 Speaker Embeddings 的情况下生成语音。
spectrogram = model.generate_speech(inputs["input_ids"], speaker_embeddings)
这会输出一个形状为 (140, 80) 的张量,其中包含对数梅尔谱图。第一个维度是序列长度,它可能在运行之间有所不同,因为语音解码器 per-net 总是对输入序列应用 dropout。这为生成的语音增加了一些随机变化。
要将预测的对数梅尔声谱图转换为实际的语音波形,我们需要一个 vocoder。理论上,您可以使用任何适用于 80-bin 梅尔声谱图的声码器,但为了方便起见,我们在基于 HiFi-GAN 的 Transformers 中提供了一个。此 声码器的权重,以及微调 TTS 模型的权重,由 SpeechT5 的原作者友情提供。
加载声码器与任何其他 🤗 Transformers 模型一样简单。
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
要从频谱图中制作音频,请执行以下操作:
with torch.no_grad():
speech = vocoder(spectrogram)
我们还提供了一个快捷方式,因此您不需要制作频谱图的中间步骤。当您将声码器对象传递给 generate_speech 时,它会直接输出语音波形。
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)
最后,将语音波形保存到文件中。SpeechT5 使用的采样率始终为 16 kHz。
import soundfile as sf
sf.write("tts_example.wav", speech.numpy(), samplerate=16000)
输出听起来 像这样:
T这就是 TTS 模型!使这个声音好听的关键是使用正确的 speaker embeddings。
您可以在 Spaces 上进行 交互式演示。
三、语音转语音的语音转换
从概念上讲,使用 SpeechT5 进行语音转语音建模与文本转语音相同。只需将文本编码器 per-net 换成语音编码器 per-net 即可。模型的其余部分保持不变。
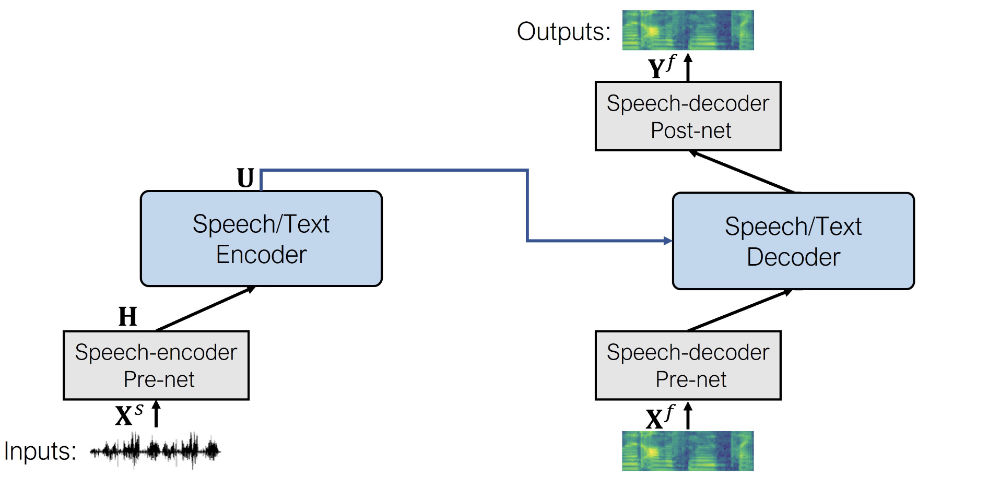
语音编码器 per-net 与 wav2vec 2.0 中的特征编码模块相同。它由卷积层组成,这些卷积层将输入波形下采样为一系列音频帧表示。
作为语音到语音任务的示例,SpeechT5 的作者提供了一个 微调检查点 用于进行语音转换。要使用它,首先从 Hub 加载模型。请注意,模型类现在是 SpeechT5ForSpeechToSpeech。
from transformers import SpeechT5Processor, SpeechT5ForSpeechToSpeech
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_vc")
model = SpeechT5ForSpeechToSpeech.from_pretrained("microsoft/speecht5_vc")
我们需要一些语音音频作为输入。出于本示例的目的,我们将从 Hub 上的小型语音数据集加载音频。您也可以加载自己的语音波形,只要它们是单声道的并且使用 16 kHz 的采样率即可。我们在这里使用的数据集中的样本已经采用这种格式。
from datasets import load_dataset
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
dataset = dataset.sort("id")
example = dataset[40]
接下来,对音频进行预处理,使其采用模型期望的格式。
sampling_rate = dataset.features["audio"].sampling_rate
inputs = processor(audio=example["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
与 TTS 模型一样,我们需要 speaker embeddings。这些描述了目标语音听起来像什么。
import torch
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
我们还需要加载声码器以将生成的频谱图转换为音频波形。让我们使用与 TTS 模型相同的声码器。
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
现在我们可以通过调用模型的 generate_speech 方法来执行语音转换。
speech = model.generate_speech(inputs["input_values"], speaker_embeddings, vocoder=vocoder)
import soundfile as sf
sf.write("speech_converted.wav", speech.numpy(), samplerate=16000)
更改为不同的声音就像加载新的 Speaker Embeddings 一样简单。您甚至可以嵌入自己的声音!
原始输入 (下载链接):
转换后的语音: (下载链接):
请注意,此示例中转换后的音频在句子结束前被切断。这可能是由于两个句子之间的停顿导致 SpeechT5 (错误地) 预测已经到达序列的末尾。换个例子试试,你会发现转换通常是正确的,但有时会过早停止。
您可以进行 交互式演示。🔥
四、用于自动语音识别的语音转文本
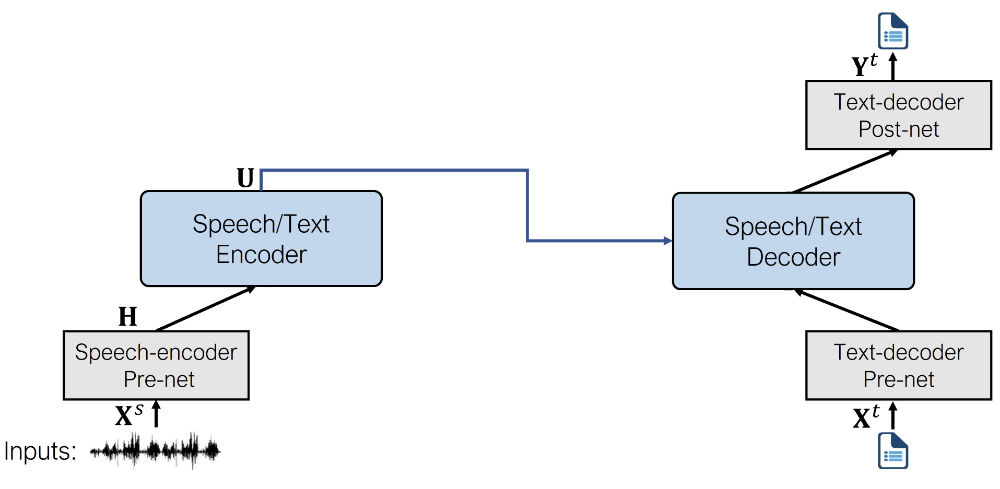
ASR 模型使用以下 pre-nets 和 post-net:
- 语音编码器 per-net。 这是语音到语音模型使用的相同预网,由来自 wav2vec 2.0 的 CNN 特征编码器层组成。
- 文本解码器 per-net。 与 TTS 模型使用的编码器预网类似,它使用嵌入层将文本标记映射到隐藏表示中。(在预训练期间,这些嵌入在文本编码器和解码器预网之间共享。)
- 文本解码器 post-net。 这是其中最简单的一个,由一个线性层组成,该层将隐藏表示投射到词汇表上的概率。
微调模型的架构如下所示。
如果您之前尝试过任何其他 🤗 Transformers 语音识别模型,您会发现 SpeechT5 同样易于使用。最快的入门方法是使用流水线。
from transformers import pipeline
generator = pipeline(task="automatic-speech-recognition", model="microsoft/speecht5_asr")
作为语音音频,我们将使用与上一节相同的输入,任何音频文件都可以使用,因为流水线会自动将音频转换为正确的格式。
from datasets import load_dataset
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
dataset = dataset.sort("id")
example = dataset[40]
现在我们可以要求流水线处理语音并生成文本转录。
transcription = generator(example["audio"]["array"])
打印转录输出:
a man said to the universe sir i exist
听起来完全正确!SpeechT5 使用的分词器非常基础,是字符级别工作。因此,ASR 模型不会输出任何标点符号或大写字母。
当然也可以直接使用模型类。首先,加载 微调模型 和处理器对象。该类现在是 SpeechT5ForSpeechToText。
from transformers import SpeechT5Processor, SpeechT5ForSpeechToText
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_asr")
model = SpeechT5ForSpeechToText.from_pretrained("microsoft/speecht5_asr")
预处理语音输入:
sampling_rate = dataset.features["audio"].sampling_rate
inputs = processor(audio=example["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
最后,告诉模型从语音输入中生成文本标记,然后使用处理器的解码功能将这些标记转换为实际文本。
predicted_ids = model.generate(**inputs, max_length=100)
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
播放 语音到文本任务 的交互式演示。
五、结论
SpeechT5 是一个有趣的模型,因为与大多数其他模型不同,它允许您使用相同的架构执行多项任务。只有 per-net 和 post-net 发生变化。通过在这些组合任务上对模型进行预训练,它在微调时变得更有能力完成每个单独的任务。
目前我们只介绍了语音识别 (ASR)、语音合成 (TTS) 和语音转换任务,但论文还提到该模型已成功用于语音翻译、语音增强和说话者识别。如此广泛的用途,前途不可估量!
2024-07-21(日)



















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











