







本文翻译整理自:https://huggingface.co/docs/transformers/main/en/quantization/awq
一、引言
Activation-aware Weight Quantization (AWQ) 激活感知权重量化 保留了对LLM性能很重要的一小部分权重,以将模型压缩到4位,同时性能下降最小。
有几个使用AWQ算法量化模型的库,如llm-awq、autoawq或 optimum-intel 。
transformers支持加载使用 llm-awq 和 autoawq 库量化的模型。
本指南将向您展示如何加载使用 autoawq 量化的模型,但过程与 llm-awq 量化模型相似。
资源:AWQ演示notebook
了解如何量化模型、将量化模型推送到集线器等的更多示例。
二、加载 autoawq 量化的模型
1、运行下面的命令安装autoawq
AutoAWQ将transformers降级到版本4.47.1。如果您想使用AutoAWQ进行推理,您可能需要在安装AutoAWQ后重新安装您的transformers版本。
pip install autoawq
pip install transformers==4.47.1
2、通过检查 模型的 config.json 文件中 quant_method键,标识 AWQ量化模型。
{
"_name_or_path": "/workspace/process/huggingfaceh4_zephyr-7b-alpha/source",
"architectures": [
"MistralForCausalLM"
],
...
...
...
"quantization_config": {
"quant_method": "awq",
"zero_point": true,
"group_size": 128,
"bits": 4,
"version": "gemm"
}
}
3、使用from_pretrained() 加载AWQ量化模型。
出于性能原因,这会自动将其他权重默认设置为fp16。
使用torch_dtype参数 以不同的格式 加载这些其他权重。
如果模型加载到CPU上,则使用device_map参数将其移动到GPU。
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model = AutoModelForCausalLM.from_pretrained(
"TheBloke/zephyr-7B-alpha-AWQ",
torch_dtype=torch.float32,
device_map="cuda:0"
)
4、使用attn_implementation启用FlashAtention2以进一步加速推理。
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"TheBloke/zephyr-7B-alpha-AWQ",
attn_implementation="flash_attention_2",
device_map="cuda:0"
)
三、Fused modules
融合模块提高了准确性和性能。Llama和Mistral架构的AWQ模块开箱即用支持它们,但您也可以将AWQ模块融合到不受支持的架构中。
融合模块不能与 FlashAccention2 等其他优化技术结合使用。
支持的架构
创建一个AwqConfig并设置参数fuse_max_seq_len和do_fuse=True以启用融合模块。
fuse_max_seq_len参数是总序列长度,它应该包括上下文长度和预期的生成长度。将其设置为更大的值以确保安全。
下面的示例融合了TheBloke/Mistral-7B-OpenOrca-AWQ 模型的AWQ模块。
import torch
from transformers import AwqConfig, AutoModelForCausalLM
quantization_config = AwqConfig(
bits=4,
fuse_max_seq_len=512,
do_fuse=True,
)
model = AutoModelForCausalLM.from_pretrained(
"TheBloke/Mistral-7B-OpenOrca-AWQ",
quantization_config=quantization_config
).to(0)
TheBloke/Mistral-7B-OpenOrca-AWQ 模型的基准测试为batch_size=1,有和没有融合模块。
未融合模块
| Batch Size | Prefill Length | Decode Length | Prefill tokens/s | Decode tokens/s | Memory (VRAM) |
|---|---|---|---|---|---|
| 1 | 32 | 32 | 60.0984 | 38.4537 | 4.50 GB (5.68%) |
| 1 | 64 | 64 | 1333.67 | 31.6604 | 4.50 GB (5.68%) |
| 1 | 128 | 128 | 2434.06 | 31.6272 | 4.50 GB (5.68%) |
| 1 | 256 | 256 | 3072.26 | 38.1731 | 4.50 GB (5.68%) |
| 1 | 512 | 512 | 3184.74 | 31.6819 | 4.59 GB (5.80%) |
| 1 | 1024 | 1024 | 3148.18 | 36.8031 | 4.81 GB (6.07%) |
| 1 | 2048 | 2048 | 2927.33 | 35.2676 | 5.73 GB (7.23%) |
融合模块
| Batch Size | Prefill Length | Decode Length | Prefill tokens/s | Decode tokens/s | Memory (VRAM) |
|---|---|---|---|---|---|
| 1 | 32 | 32 | 81.4899 | 80.2569 | 4.00 GB (5.05%) |
| 1 | 64 | 64 | 1756.1 | 106.26 | 4.00 GB (5.05%) |
| 1 | 128 | 128 | 2479.32 | 105.631 | 4.00 GB (5.06%) |
| 1 | 256 | 256 | 1813.6 | 85.7485 | 4.01 GB (5.06%) |
| 1 | 512 | 512 | 2848.9 | 97.701 | 4.11 GB (5.19%) |
| 1 | 1024 | 1024 | 3044.35 | 87.7323 | 4.41 GB (5.57%) |
| 1 | 2048 | 2048 | 2715.11 | 89.4709 | 5.57 GB (7.04%) |
融合和未融合模块的速度和吞吐量也用最佳基准库进行了测试。
前向峰值内存/批量大小
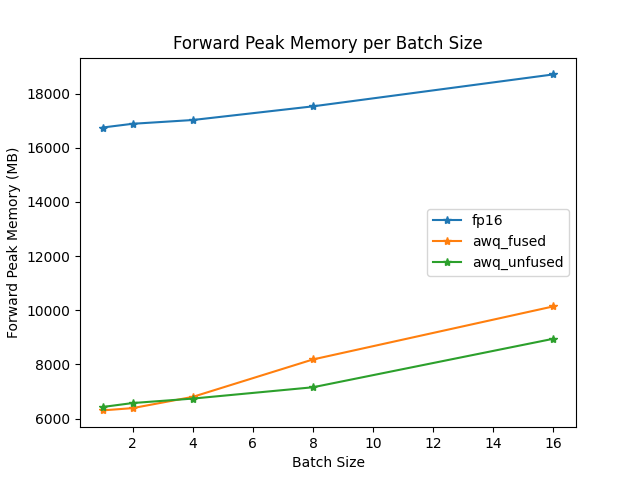
生成吞吐量/批量大小
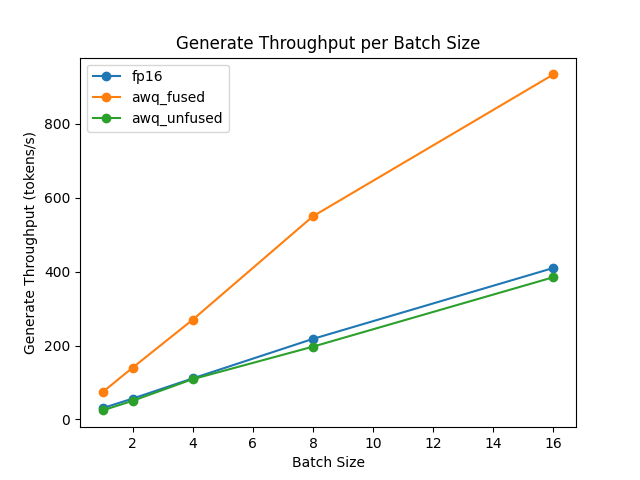
不受支持的架构
对于不支持融合模块的体系结构,创建AwqConfig并在modules_to_fuse中定义自定义融合映射以确定需要融合哪些模块。
下面的示例融合了TheBloke/Yi-AWQ34B模型的AWQ模块。
import torch
from transformers import AwqConfig, AutoModelForCausalLM
quantization_config = AwqConfig(
bits=4,
fuse_max_seq_len=512,
modules_to_fuse={
"attention": ["q_proj", "k_proj", "v_proj", "o_proj"],
"layernorm": ["ln1", "ln2", "norm"],
"mlp": ["gate_proj", "up_proj", "down_proj"],
"use_alibi": False,
"num_attention_heads": 56,
"num_key_value_heads": 8,
"hidden_size": 7168
}
)
model = AutoModelForCausalLM.from_pretrained(
"TheBloke/Yi-34B-AWQ",
quantization_config=quantization_config
).to(0)
参数modules_to_fuse应包括以下键。
"attention":按以下顺序融合的关注层的名称:查询、键、值和输出投影层。如果不想融合这些层,传递一个空列表。"layernorm":要替换为自定义融合LayerNorm的所有LayerNorm层的名称。如果不想融合这些层,请传递一个空列表。"mlp":您要融合到单个MLP层中的MLP层的名称,顺序为:(门(密集、层、关注后)/上/下层)。"use_alibi":如果您的模型使用ALiBi位置嵌入。"num_attention_heads"”:关注头条号数量。"num_key_value_heads"":应用于实现分组查询关注(GQA)的键值头的数量。
| 参数值 | 注意力 |
|---|---|
num_key_value_heads=num_attention_heads | 多头注意力 |
num_key_value_heads=1 | 多查询注意力 |
num_key_value_heads=... | 分组查询注意力 |
"hidden_size":隐藏表示的维度。
四、ExLlamaV2
ExLlamaV2内核支持更快的预填充和解码。运行下面的命令来安装支持ExLlamaV2的最新版本的autoawq。
pip install git+https://github.com/casper-hansen/AutoAWQ.git
在AwqConfig中设置version="exllama"以启用ExLlamaV2内核。
AMD GPU支持ExLlamaV2。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, AwqConfig
quantization_config = AwqConfig(version="exllama")
model = AutoModelForCausalLM.from_pretrained(
"TheBloke/Mistral-7B-Instruct-v0.1-AWQ",
quantization_config=quantization_config,
device_map="auto",
)
五、CPU
Intel Extension for PyTorch (IPEX) 旨在实现英特尔硬件的性能优化。运行下面的命令来安装支持IPEX的最新版本的autoawq。
pip install intel-extension-for-pytorch # for IPEX-GPU refer to https://intel.github.io/intel-extension-for-pytorch/xpu/2.5.10+xpu/
pip install git+https://github.com/casper-hansen/AutoAWQ.git
在version="ipex"中设置AwqConfig以启用 ExLlamaV2 内核。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, AwqConfig
device = "cpu" # set to "xpu" for Intel GPU
quantization_config = AwqConfig(version="ipex")
model = AutoModelForCausalLM.from_pretrained(
"TheBloke/TinyLlama-1.1B-Chat-v0.3-AWQ",
quantization_config=quantization_config,
device_map=device,
)
2025-03-08(六)



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











