







 本文深入探讨Spark Standalone运行模式,分析AppClient与Master、Master与Worker、Driver Client与Master以及Driver与Executor之间的交互。文章详细讲解了应用注册流程、Master的高可靠性以及Driver和Executor的通信机制。
本文深入探讨Spark Standalone运行模式,分析AppClient与Master、Master与Worker、Driver Client与Master以及Driver与Executor之间的交互。文章详细讲解了应用注册流程、Master的高可靠性以及Driver和Executor的通信机制。
Spark Standalone采用的是Master/Slave架构,主要涉及到的类包括:
类:org.apache.spark.deploy.master.Master
说明:负责整个集群的资源调度及Application的管理。
消息类型:
接收Worker发送的消息
1. RegisterWorker
2. ExecutorStateChanged
3. WorkerSchedulerStateResponse
4. Heartbeat
向Worker发送的消息
1. RegisteredWorker
2. RegisterWorkerFailed
3. ReconnectWorker
4. KillExecutor
5.LaunchExecutor
6.LaunchDriver
7.KillDriver
8.ApplicationFinished
向AppClient发送的消息
1. RegisteredApplication
2. ExecutorAdded
3. ExecutorUpdated
4. ApplicationRemoved
接收AppClient发送的消息
1. RegisterApplication
2. UnregisterApplication
3. MasterChangeAcknowledged
4. RequestExecutors
5. KillExecutors
向Driver Client发送的消息
1.SubmitDriverResponse
2.KillDriverResponse
3.DriverStatusResponse
接收Driver Client发送的消息
1.RequestSubmitDriver
2.RequestKillDriver
3.RequestDriverStatus
类org.apache.spark.deploy.worker.Worker
说明:向Master注册自己并启动CoarseGrainedExecutorBackend,在运行时启动Executor运行Task任务
消息类型:
向Master发送的消息
1. RegisterWorker
2. ExecutorStateChanged
3. WorkerSchedulerStateResponse
4. Heartbeat
接收Master发送的消息
1. RegisteredWorker
2. RegisterWorkerFailed
3. ReconnectWorker
4. KillExecutor
5.LaunchExecutor
6.LaunchDriver
7.KillDriver
8.ApplicationFinished
类org.apache.spark.deploy.client.AppClient.ClientEndpoint
说明:向Master注册并监控Application,请求或杀死Executors等
消息类型:
向Master发送的消息
1. RegisterApplication
2. UnregisterApplication
3. MasterChangeAcknowledged
4. RequestExecutors
5. KillExecutors
接收Master发送的消息
1. RegisteredApplication
2. ExecutorAdded
3. ExecutorUpdated
4. ApplicationRemoved
类:org.apache.spark.scheduler.cluster.DriverEndpoint
说明:运行时注册Executor并启动Task的运行并处理Executor发送来的状态更新等
消息类型:
向Executor发送的消息
1.LaunchTask
2.KillTask
3.RegisteredExecutor
4.RegisterExecutorFailed
接收Executor发送的消息
1.RegisterExecutor
2.StatusUpdate
类:org.apache.spark.deploy.ClientEndpoint
说明:管理Driver包括提交Driver、Kill掉Driver及获取Driver状态信息
向Master发送的消息
1.RequestSubmitDriver
2.RequestKillDriver
3.RequestDriverStatus
接收Master 发送的消息
1.SubmitDriverResponse
2.KillDriverResponse
3.DriverStatusResponse
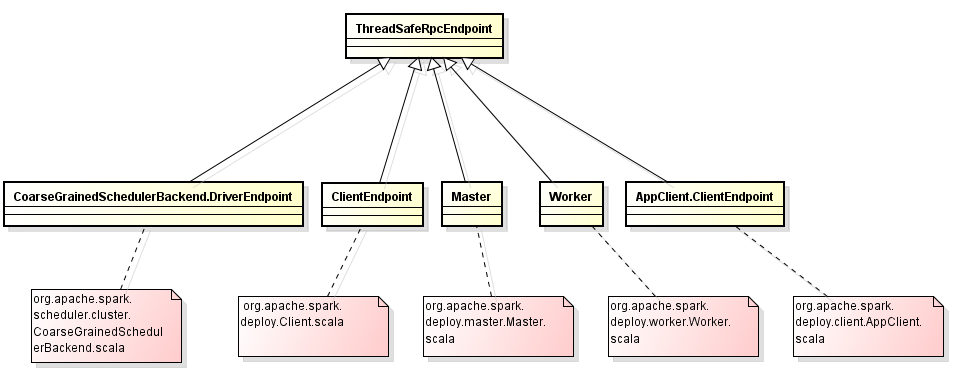
上面所有的类都继承自org.apache.spark.rpc.ThreadSafeRpcEndpoint,其底层实现目前都是通过AKKA来实现的,具体如下图所示:
各类之间的交互关系如下图所示:
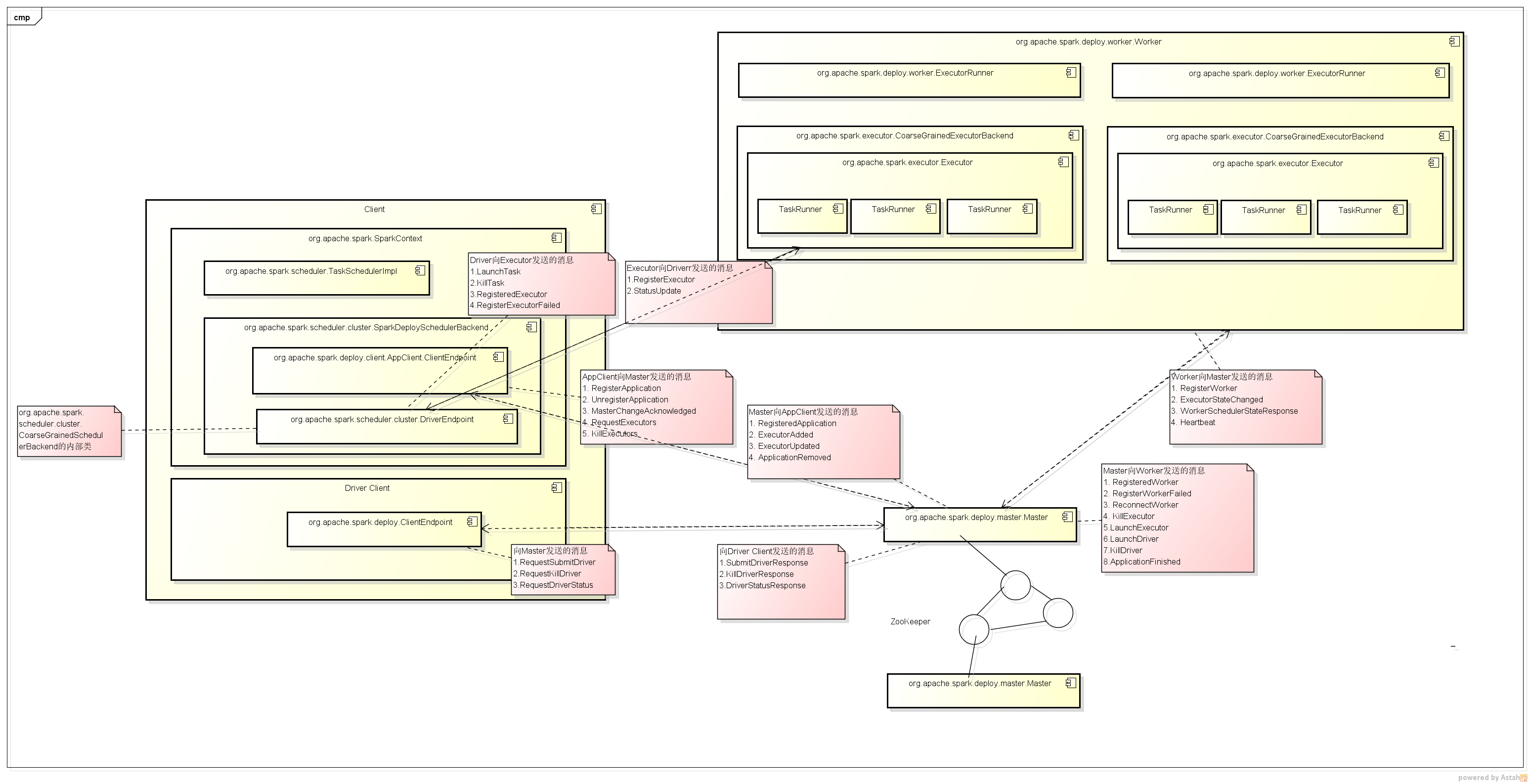
1. AppClient与Master间的交互
SparkContext在创建时,会调用,createTaskScheduler方法创建相应的TaskScheduler及SchedulerBackend
// Create and start the scheduler
val (sched, ts) = SparkContext.createTaskScheduler(this, master)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler‘s
// constructor
_taskScheduler.start()
Standalone运行模式创建的TaskScheduler及SchedulerBackend具体源码如下:
/**
* Create a task scheduler based on a given master URL.
* Return a 2-tuple of the scheduler backend and the task scheduler.
*/
private def createTaskScheduler(
sc: SparkContext,
master: String): (SchedulerBackend, TaskScheduler) = {
//省略其它非关键代码
case SPARK_REGEX(sparkUrl) =>
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
val backend = new SparkDeploySchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
(backend, scheduler)
//省略其它非关键代码
}创建完成TaskScheduler及SchedulerBackend后,调用TaskScheduler的start方法,启动SchedulerBackend(Standalone模式对应SparkDeploySchedulerBackend)
//TaskSchedulerImpl中的start方法
override def start() {
//调用SchedulerBackend的start方法
bac 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1447
1447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









