







一、残差神经网络——ResNet的综述
深度学习网络的深度对最后的分类和识别的效果有着很大的影响,所以正常想法就是能把网络设计的越深越好,
但是事实上却不是这样,常规的网络的堆叠(plain network)在网络很深的时候,效果却越来越差了。其中原因之一
即是网络越深,梯度消失的现象就越来越明显,网络的训练效果也不会很好。 但是现在浅层的网络(shallower network)
又无法明显提升网络的识别效果了,所以现在要解决的问题就是怎样在加深网络的情况下又解决梯度消失的问题。
(二)残差模块——Residual bloack
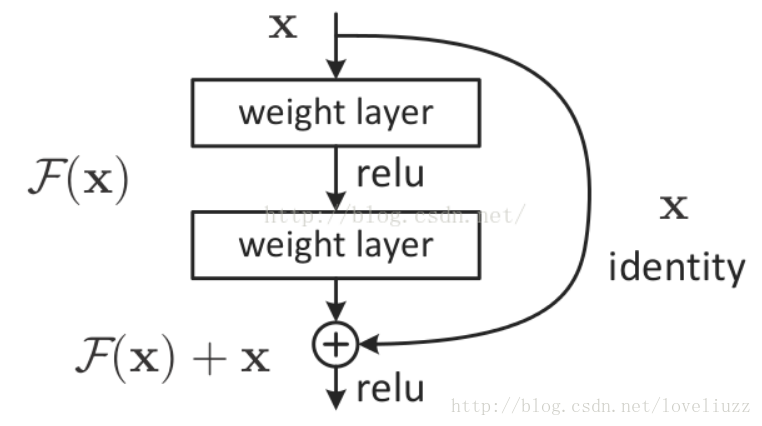
通过在一个浅层网络基础上叠加 y=x 的层(称identity mappings,恒等映射),可以让网络随深度增加而不退化。
这反映了多层非线性网络无法逼近恒等映射网络。但是,不退化不是我们的目的,我们希望有更好性能的网络。
resnet学习的是残差函数F(x) = H(x) - x, 这里如果F(x) = 0, 那么就是上面提到的恒等映射。事实上,
resnet是“shortcut connections”的在connections是在恒等映射下的特殊情况,它没有引入额外的参数和计算复杂度。
假如优化目标函数是逼近一个恒等映射, 而不是0映射, 那么学习找到对恒等映射的扰动会比重新学习一个映射函数要容易。
残差函数一般会有较小的响应波动,表明恒等映射是一个合理的预处理。


残差模块小结:
非常深的网络很难训练,存在梯度消失和梯度爆炸问题,学习 skip connection它可以从某一层获得激活,然后迅速反馈给另外一层甚至更深层,利用 skip connection可以构建残差网络ResNet来训练更深的网络,ResNet网络是由残差模块构建的。
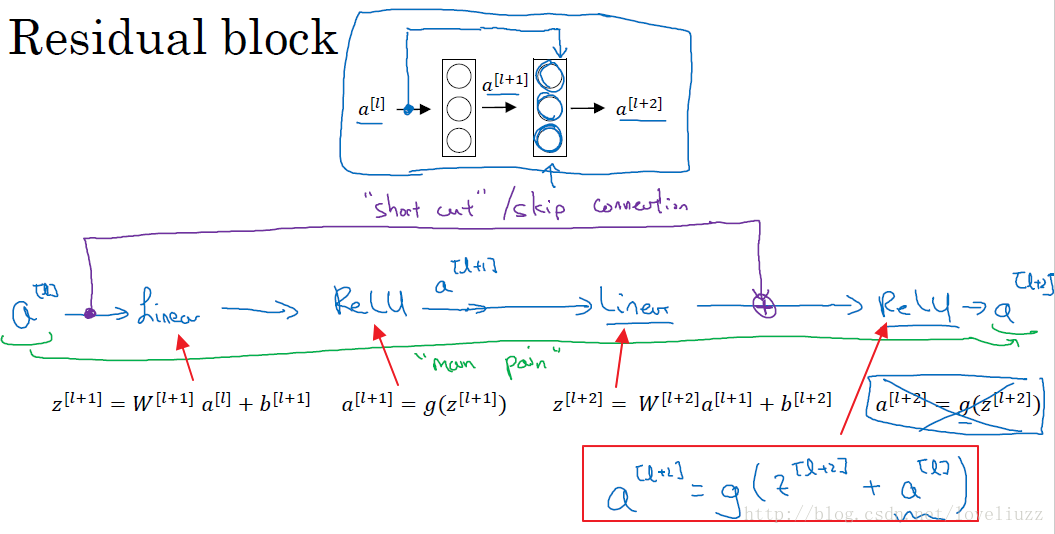
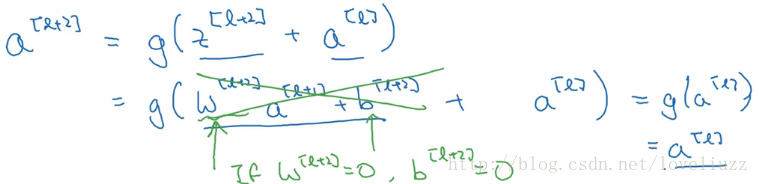
上图中,是一个两层的神经网络,在l层进行激活操作,得到a[l+1],再次进行激活得到a[l+2]。由下面公式:
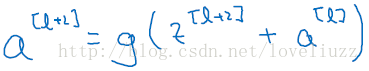
a[l+2] 加上了 a[l]的残差块,即:残差网络中,直接将a[l]向后拷贝到神经网络的更深层,在ReLU非线性激活前面
加上a[l],a[l]的信息直接达到网络深层。使用残差块能够训练更深层的网络,构建一个ResNet网络就是通过将很多
这样的残差块堆积在一起,形成一个深度神经网络。
(三)残差网络——ResNet
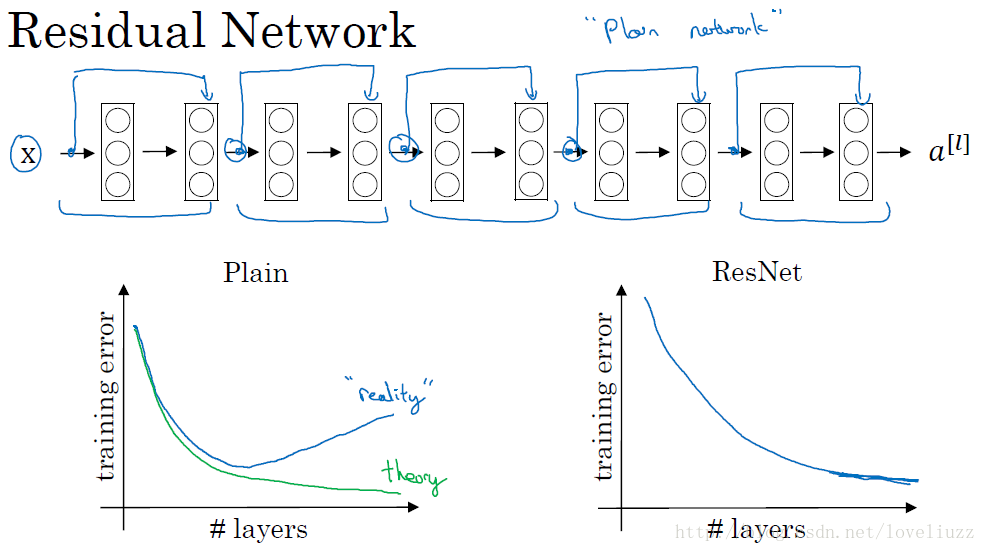
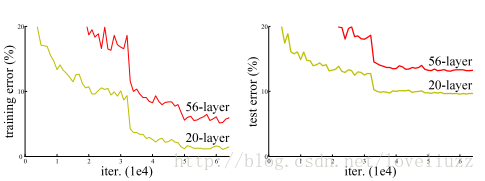
上图中是用5个残差块连接在一起构成的残差网络,用梯度下降算法训练一个神经网络,若没有残差,会发现
随着网络加深,训练误差先减少后增加,理论上训练误差越来越小比较好。而对于残差网络来讲,随着层数增加,
训练误差越来越减小,这种方式能够到达网络更深层,有助于解决梯度消失和梯度爆炸的问题,让我们训练更深网络
同时又能保证良好的性能。
残差网络有很好表现的原因举例:
假设有一个很大的神经网络,输入矩阵为X,输出激活值为a[l],加入给这个网络额外增加两层,最终输出结果为a[l+2],
可以把这两层看做一个残差模块,在整个网络中使用ReLU激活函数,所有的激活值都大于等于0。
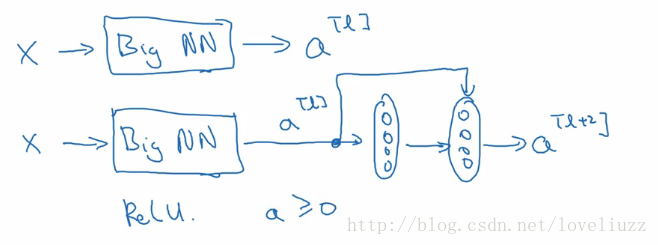
对于大型的网络,无论把残差块添加到神经网络的中间还是末端,都不会影响网络的表现。
残差网络起作用的主要原因是:It's so easy for these extra layers to learn the itentity function.
这些残差块学习恒等函数非常容易。可以确定网络性能不受影响,很多时候甚至可以提高学习效率。
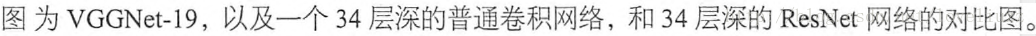
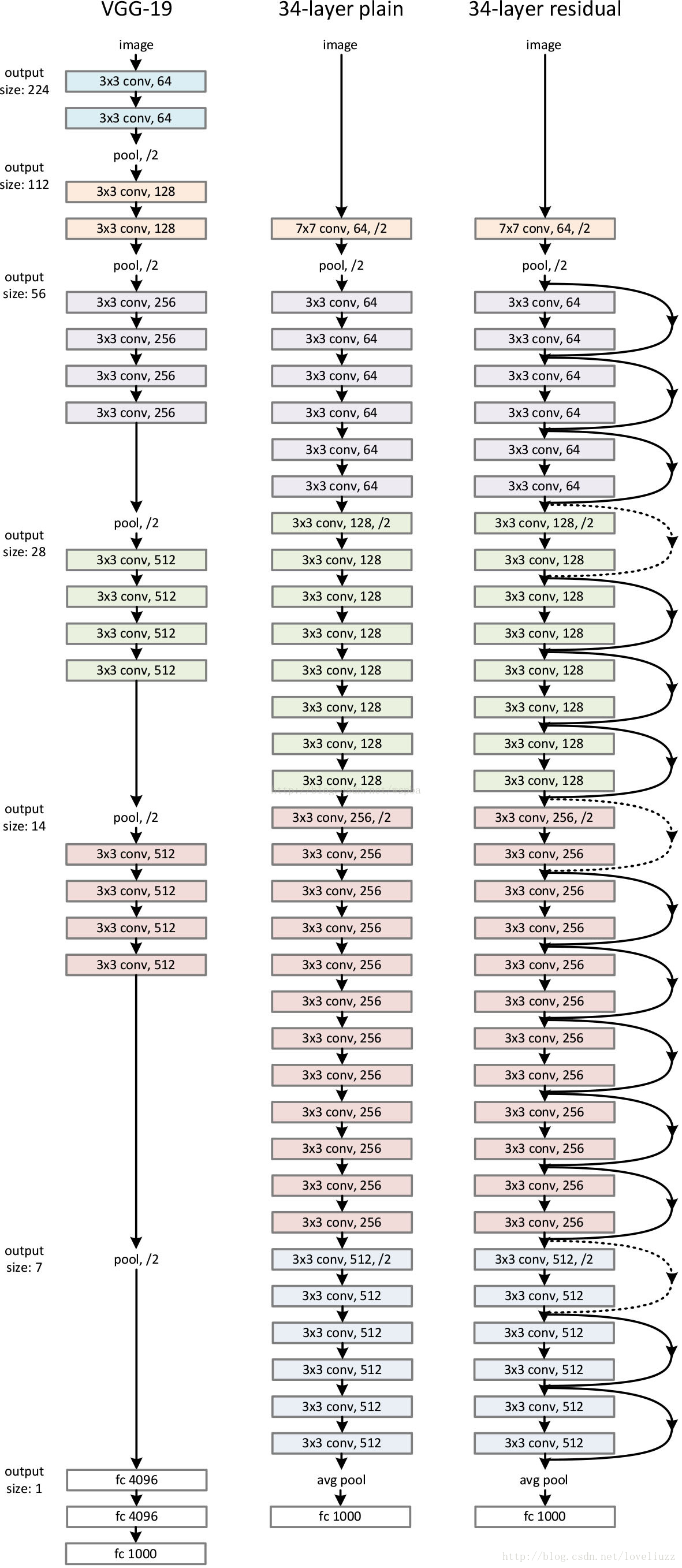

模型构建好后进行实验,在plain上观测到明显的退化现象,而且ResNet上不仅没有退化,34层网络的效果反而比18层的更好,而且不仅如此,ResNet的收敛速度比plain的要快得多。
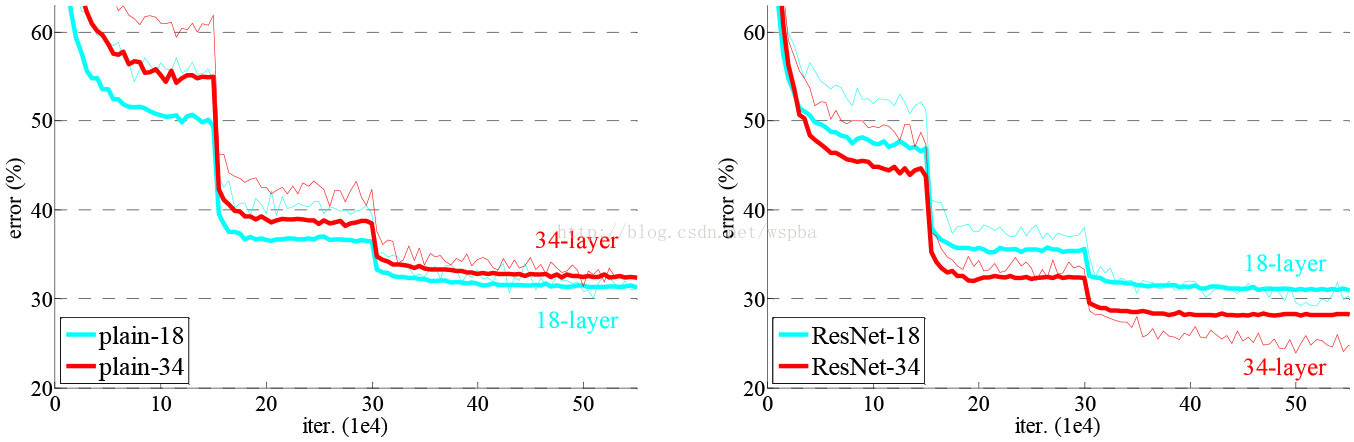

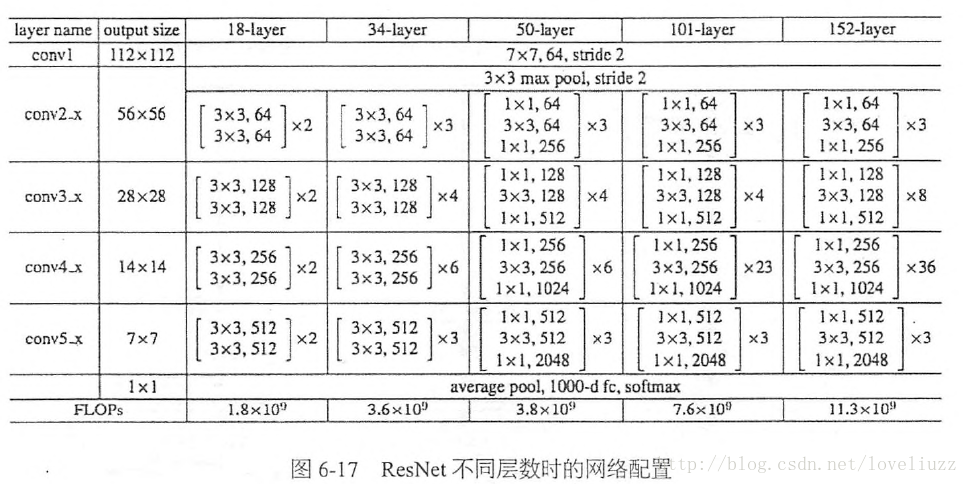
这相当于对于相同数量的层又减少了参数量,因此可以拓展成更深的模型。于是作者提出了50、101、152层的ResNet,而且不仅没有出现退化问题,错误率也大大降低,同时计算复杂度也保持在很低的程度。
这个时候ResNet的错误率已经把其他网络落下几条街了,但是似乎还并不满足,于是又搭建了更加变态的1202层的网络,对于这么深的网络,优化依然并不困难,但是出现了过拟合的问题,这是很正常的,作者也说了以后会对这个1202层的模型进行进一步的改进。

二、ResNet在Keras框架下的实现
(一)概况
利用残差神经网络ResNet构建一个很深度的卷积神经网络。理论上,很深的神经网络代表着复杂的函数,实际上它们很难训练,而ResNet比其他很深的神经网络训练起来更加实际可行。
1、构建基本的ResNet模块。
2、把这些ResNet模块集成在一起,实现和训练一个用于图像分类的最先进的神经网络。
3、该ResNet网络在深度学习框架 Keras下构建完成。
近年来,神经网络已变得更深,与最先进的网络从几层(如AlexNet)到一百层。一个非常深的网络的主要好处是:它可以代表非常复杂的函数。它还可以从许多不同层次的抽象中学习特征,从边缘(在较低的层)到非常复杂的特性(在更深的层次)。然而,使用更深层的网络并不总是有用的。训练它们巨大的障碍就是梯度消失:很深的网络往往梯度信号变为零的速度快,从而使梯度下降法非常地慢。更特别的是,在梯度下降,当你从最后一层BackProp回到第一层,每一步乘以权重矩阵,从而梯度以指数方式迅速减为为零(或者,在罕见的情况下,成倍的增长,迅速“爆炸”为非常大的值)。
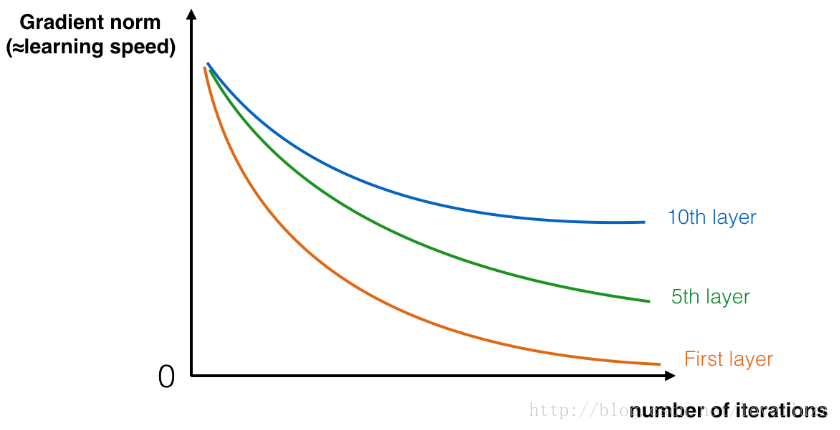
在训练过程中,可能会看到前面层的梯度的量级或标准减小到零的速度很快,如下图所示:
(二)、构建残差块
在ResNet中,"shortcut" 或 "skip connection" 使得梯度反向传播到更前面的层:下图中左边的图片展示了神经网络的主路径“main path”,右侧的图片为“main path”添加了一个“short cut”,通过堆叠这些ResNet模块,可以构建很深的神经网络。

带有“shortcut”的ResNet模块,使得它对每一个模块很容易学习到恒等函数“identy function”,这意味着你可以叠加额外ResNet模块而对训练集的性能产生风险小的危害。还有一些证据表明,学习恒等函数“identy function” 甚至比"skip connection" 对于梯度消失问题更有帮助,且更能说明ResNets表现出色。在ResNet中使用两种主要类型的模块,主要取决于输入/输出尺寸是相同还是不同。
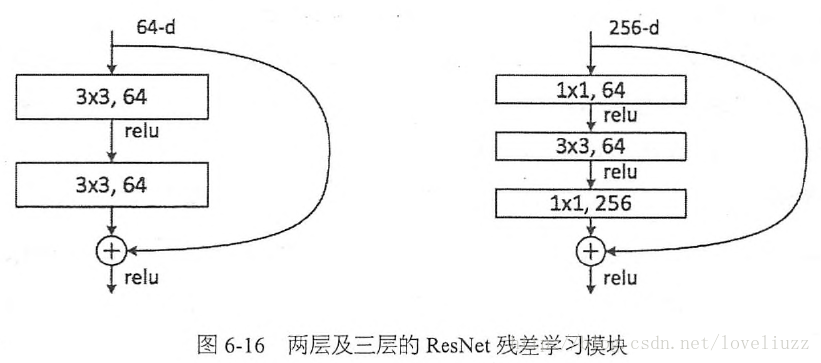
1、恒等残差块——The identity block
The identity block是ResNets中使用的标准块,对应于输入激活(例如 a [1])与输出激活具有相同维度(例如a [l +2])。
(1)、两层恒等残差块
下图展示了ResNets的两层的恒等残差块 identity block:
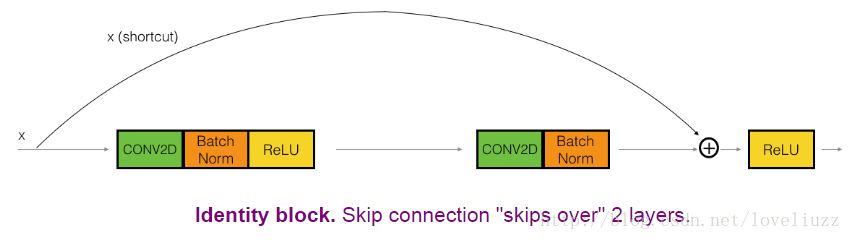
上面的路径是“shortcut path”,下面的路径是“main path”,在这个图中,同样也进行了CONV2D和ReLU操作,为了加速训练的速度也加入了Batch正则化“Batch Norm”,Batch Norm在Keras框架中就一句代码。
(2)、三层恒等残差块
在下面的这个例子中,将实际上实现一个略微更强大的版本,这个跳转连接“跳过”3个隐藏层而不是2层。
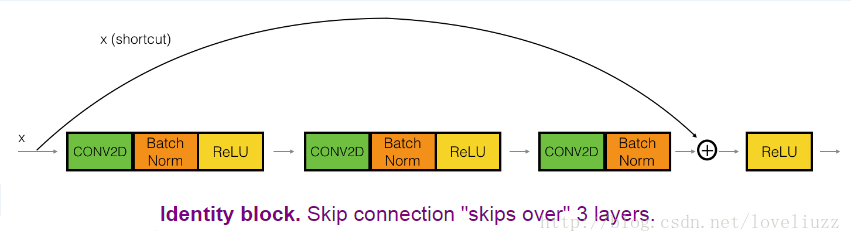
(3)、下面是细节的步骤:
a、主路径的第一部分:
第一个CONV2D的过滤器F1大小是(1*1),步长s大小为(1*1),卷积填充padding="valid"即无填充卷积。
将这一部分命名为conv_name_base+'2a',初始化时利用种子为seed=0。
第一个BatchNorm是在通道/厚度的轴上进行标准化,并命名为bn_name_base+'2a'.
应用ReLU激活函数,这里没有超参数。
b、主路径的第二部分:
第二个CONV2D的过滤器F2大小是(f*f),步长s大小为(1*1),卷积填充padding="same"即相同卷积。
将这一部分命名为conv_name_base'2b',初始化时利用种子为seed=0。
第二个BatchNorm是在通道/厚度的轴上进行标准化,并命名为bn_name_base+'2b'.
应用ReLU激活函数,这里没有超参数。
c、主路径的第三部分:
第三个CONV2D的过滤器F3大小是(1*1),步长s大小为(1*1),卷积填充padding="valid"即无填充卷积。
将这一部分命名为conv_name_base+'2c',初始化时利用种子为seed=0。
第三个BatchNorm是在通道/厚度的轴上进行标准化,并命名为bn_name_base +'2c'.
这一部分中没有应用ReLU激活函数。
d、最后部分:
将shortcut和输入一起添加到模块中,然后再应用ReLU激活函数,这里没有超参数。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
#构建50层的ResNet神经网络实现图像的分类
#深度学习框架 Keras中实现
import numpy as np
import tensorflow as tf
from keras import layers
from keras.layers import Input,Add,Dense,Activation,ZeroPadding2D,\
BatchNormalization,Flatten,Conv2D,AveragePooling2D,MaxPooling2D,GlobalMaxPooling2D
from keras.models import Model,load_model
from keras.preprocessing import image
from keras.utils import layer_utils
from keras.utils.data_utils import get_file
from keras.applications.imagenet_utils import preprocess_input
from keras.utils.vis_utils import model_to_dot
from keras.utils import plot_model
from keras.initializers import glorot_uniform
import pydoc
from IPython.display import SVG
from resnets_utils import *
import scipy.misc
from matplotlib.pyplot import imshow
import keras.backend as K
K.set_image_data_format("channels_last")
K.set_learning_phase(1)
#恒等模块——identity_block
def identity_block(X,f,filters,stage,block):
"""
三层的恒等残差块
param :
X -- 输入的张量,维度为(m, n_H_prev, n_W_prev, n_C_prev)
f -- 整数,指定主路径的中间 CONV 窗口的形状(过滤器大小)
filters -- python整数列表,定义主路径的CONV层中的过滤器
stage -- 整数,用于命名层,取决于它们在网络中的位置
block --字符串/字符,用于命名层,取决于它们在网络中的位置
return:
X -- 三层的恒等残差块的输出,维度为:(n_H, n_W, n_C)
"""
#定义基本的名字
conv_name_base = "res"+str(stage)+block+"_branch"
bn_name_base = "bn"+str(stage)+block+"_branch"
#过滤器
F1,F2,F3 = filters
#保存输入值,后面将需要添加回主路径
X_shortcut = X
#主路径第一部分
X = Conv2D(filters=F1,kernel_size=(1,1),strides=(1,1),padding="valid",
name=conv_name_base+"2a",kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3,name=bn_name_base+"2a")(X)
X = Activation("relu")(X)
# 主路径第二部分
X = Conv2D(filters=F2,kernel_size=(f,f),strides=(1,1),padding="same",
name=conv_name_base+"2b",kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3,name=bn_name_base+"2b")(X)
X = Activation("relu")(X)
# 主路径第三部分
X = Conv2D(filters=F3,kernel_size=(1,1),strides=(1,1),padding="valid",
name=conv_name_base+"2c",kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3,name=bn_name_base+"2c")(X)
# 主路径最后部分,为主路径添加shortcut并通过relu激活
X = layers.add([X,X_shortcut])
X = Activation("relu")(X)
return X
tf.reset_default_graph()
with tf.Session() as sess:
np.random.seed(1)
A_prev = tf.placeholder("float",shape=[3,4,4,6])
X = np.random.randn(3,4,4,6)
A = identity_block(A_prev,f=2,filters=[2,4,6],stage=1,block="a")
sess.run(tf.global_variables_initializer())
out = sess.run([A],feed_dict={A_prev:X,K.learning_phase():0})
print("out = "+str(out[0][1][1][0]))
#运行结果:
out = [0.19716813 0. 1.3561227 2.1713073 0. 1.3324987 ](1)、综述
ResNet的convolutional_block是另一种类型的残差块,当输入和输出尺寸不匹配时,可以使用这种类型的块。
与identity block恒等残差块不同的地方是:在shortcut路径中是一个CONV2D的层。
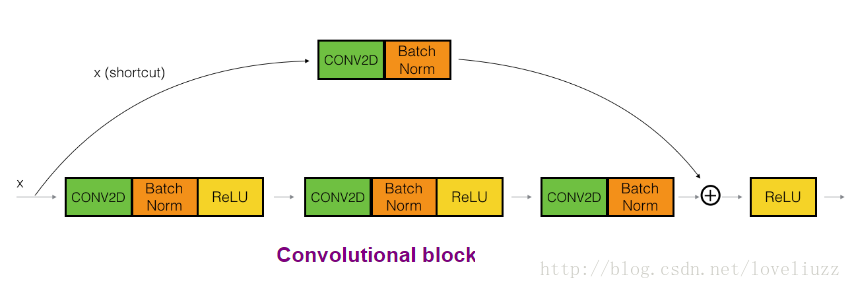
shortcut路径中的CONV2D层用于将输入x调整为不同的尺寸,以便在添加shortcut残差块的值返回到主路径时需要最后添加的尺寸相匹配(与矩阵Ws的作用相同)。例如,要将激活值维度的高度和宽度缩小2倍,可以使用步长为2的1x1卷积。shortcut路径上的CONV2D层路径不使用任何非线性激活函数。 它的主要作用是只应用一个(学习的)线性函数来减小输入的尺寸,使得尺寸匹配后面的添加步骤。
a、主路径第一部分
第一个CONV2D的过滤器F1大小是(1*1),步长s大小为(s*s),卷积填充padding="valid"即无填充卷积。
将这一部分命名为conv_name_base+'2a'。
第一个BatchNorm是在通道/厚度的轴上进行标准化,并命名为bn_name_base+'2a'.
应用ReLU激活函数,这里没有超参数。
b、主路径第二部分
第二个CONV2D的过滤器F2大小是(f*f),步长s大小为(1*1),卷积填充padding="same"即相同卷积。
将这一部分命名为conv_name_base+'2b',初始化时利用种子为seed=0。
第二个BatchNorm是在通道/厚度的轴上进行标准化,并命名为bn_name_base+'2b'.
应用ReLU激活函数,这里没有超参数。
c、主路径第三部分
第三个CONV2D的过滤器 F3大小是(1*1),步长s大小为(1*1),卷积填充padding="valid"即无填充卷积。
将这一部分命名为 conv_name_base+'2c',初始化时利用种子为seed=0。
第三个BatchNorm是在通道/厚度的轴上进行标准化,并命名为bn_name_base+'2c'.
这一部分中没有应用ReLU激活函数。
d、shortcut 路径
该部分CONV2D的过滤器 F3大小是(1*1),步长s大小为(s*s),卷积填充 padding="valid"即无填充卷积。
将这一部分命名为conv_name_base+'1'。
该部分BatchNorm是在通道/厚度的轴上进行标准化,并命名为bn_name_base+'1'
e、最后部分
将shortcut和输入一起添加到模块中,然后再应用ReLU激活函数,这里没有超参数。
#卷积残差块——convolutional_block
def convolutional_block(X,f,filters,stage,block,s=2):
"""
param :
X -- 输入的张量,维度为(m, n_H_prev, n_W_prev, n_C_prev)
f -- 整数,指定主路径的中间 CONV 窗口的形状(过滤器大小)
filters -- python整数列表,定义主路径的CONV层中的过滤器
stage -- 整数,用于命名层,取决于它们在网络中的位置
block --字符串/字符,用于命名层,取决于它们在网络中的位置
s -- 整数,指定使用的步幅
return:
X -- 卷积残差块的输出,维度为:(n_H, n_W, n_C)
"""
# 定义基本的名字
conv_name_base = "res" + str(stage) + block + "_branch"
bn_name_base = "bn" + str(stage) + block + "_branch"
# 过滤器
F1, F2, F3 = filters
# 保存输入值,后面将需要添加回主路径
X_shortcut = X
# 主路径第一部分
X = Conv2D(filters=F1, kernel_size=(1, 1), strides=(s, s), padding="valid",
name=conv_name_base + "2a", kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + "2a")(X)
X = Activation("relu")(X)
# 主路径第二部分
X = Conv2D(filters=F2, kernel_size=(f, f), strides=(1, 1), padding="same",
name=conv_name_base + "2b", kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + "2b")(X)
X = Activation("relu")(X)
# 主路径第三部分
X = Conv2D(filters=F3, kernel_size=(1, 1), strides=(1, 1), padding="valid",
name=conv_name_base + "2c", kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + "2c")(X)
#shortcut路径
X_shortcut = Conv2D(filters=F3,kernel_size=(1,1),strides=(s,s),padding="valid",
name=conv_name_base+"1",kernel_initializer=glorot_uniform(seed=0))(X_shortcut)
X_shortcut = BatchNormalization(axis=3,name=bn_name_base+"1")(X_shortcut)
# 主路径最后部分,为主路径添加shortcut并通过relu激活
X = layers.add([X, X_shortcut])
X = Activation("relu")(X)
return X
tf.reset_default_graph()
with tf.Session() as test:
np.random.seed(1)
A_prev = tf.placeholder("float", [3, 4, 4, 6])
X = np.random.randn(3, 4, 4, 6)
A = convolutional_block(A_prev, f = 2, filters = [2, 4, 6], stage = 1, block = 'a')
test.run(tf.global_variables_initializer())
out = test.run([A], feed_dict={A_prev: X, K.learning_phase(): 0})
print("out = " + str(out[0][1][1][0]))
#运行结果:
out = [0.09018463 1.2348977 0.46822017 0.0367176 0. 0.65516603]三、在Keras框架下构建50层的残差卷积神经网络ResNet
50层的残差卷积神经网络ResNet的细节部分:
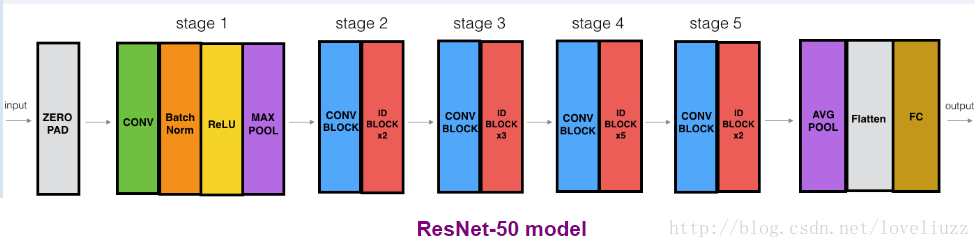
0、为输入224*224*3填充大小为(3*3)的zero_padding。
1、第一阶段,输出大小为:56*56*64

2、第二阶段,输出大小为:56*56*256

3、第三阶段,输出大小为:28*28*512

4、第四阶段,输出大小为:14*14*1024

5、第五阶段,输出大小为:7*7*2048

6、最后阶段,输出6个类别

注意:
(1)正如在Keras教程中所看到的,在事先训练模型之前,需要通过编译模型来配置学习过程。
(2)模型训练20次epches,批样本数目batch_size = 32,在单个CPU上运行大概每个epoch需5分钟。
(3)当训练足够数量的迭代时,ResNet50是一个强大的图像分类模型。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
#构建50层的ResNet神经网络实现图像的分类
#深度学习框架 Keras中实现
import numpy as np
import tensorflow as tf
from keras import layers
from keras.layers import Input,Add,Dense,Activation,ZeroPadding2D,\
BatchNormalization,Flatten,Conv2D,AveragePooling2D,MaxPooling2D,GlobalMaxPooling2D
from keras.models import Model,load_model
from keras.preprocessing import image
from keras.utils import layer_utils
from keras.utils.data_utils import get_file
from keras.applications.imagenet_utils import preprocess_input
from keras.utils.vis_utils import model_to_dot
from keras.utils import plot_model
from keras.initializers import glorot_uniform
import pydoc
from IPython.display import SVG
from resnets_utils import *
import scipy.misc
from matplotlib.pyplot import imshow
import keras.backend as K
K.set_image_data_format("channels_last")
K.set_learning_phase(1)
#恒等模块——identity_block
def identity_block(X,f,filters,stage,block):
"""
三层的恒等残差块
param :
X -- 输入的张量,维度为(m, n_H_prev, n_W_prev, n_C_prev)
f -- 整数,指定主路径的中间 CONV 窗口的形状
filters -- python整数列表,定义主路径的CONV层中的过滤器数目
stage -- 整数,用于命名层,取决于它们在网络中的位置
block --字符串/字符,用于命名层,取决于它们在网络中的位置
return:
X -- 三层的恒等残差块的输出,维度为:(n_H, n_W, n_C)
"""
#定义基本的名字
conv_name_base = "res"+str(stage)+block+"_branch"
bn_name_base = "bn"+str(stage)+block+"_branch"
#过滤器
F1,F2,F3 = filters
#保存输入值,后面将需要添加回主路径
X_shortcut = X
#主路径第一部分
X = Conv2D(filters=F1,kernel_size=(1,1),strides=(1,1),padding="valid",
name=conv_name_base+"2a",kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3,name=bn_name_base+"2a")(X)
X = Activation("relu")(X)
# 主路径第二部分
X = Conv2D(filters=F2,kernel_size=(f,f),strides=(1,1),padding="same",
name=conv_name_base+"2b",kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3,name=bn_name_base+"2b")(X)
X = Activation("relu")(X)
# 主路径第三部分
X = Conv2D(filters=F3,kernel_size=(1,1),strides=(1,1),padding="valid",
name=conv_name_base+"2c",kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3,name=bn_name_base+"2c")(X)
# 主路径最后部分,为主路径添加shortcut并通过relu激活
X = layers.add([X,X_shortcut])
X = Activation("relu")(X)
return X
tf.reset_default_graph()
with tf.Session() as sess:
np.random.seed(1)
A_prev = tf.placeholder("float",shape=[3,4,4,6])
X = np.random.randn(3,4,4,6)
A = identity_block(A_prev,f=2,filters=[2,4,6],stage=1,block="a")
sess.run(tf.global_variables_initializer())
out = sess.run([A],feed_dict={A_prev:X,K.learning_phase():0})
print("out = "+str(out[0][1][1][0]))
#卷积残差块——convolutional_block
def convolutional_block(X,f,filters,stage,block,s=2):
"""
param :
X -- 输入的张量,维度为(m, n_H_prev, n_W_prev, n_C_prev)
f -- 整数,指定主路径的中间 CONV 窗口的形状(过滤器大小,ResNet中f=3)
filters -- python整数列表,定义主路径的CONV层中过滤器的数目
stage -- 整数,用于命名层,取决于它们在网络中的位置
block --字符串/字符,用于命名层,取决于它们在网络中的位置
s -- 整数,指定使用的步幅
return:
X -- 卷积残差块的输出,维度为:(n_H, n_W, n_C)
"""
# 定义基本的名字
conv_name_base = "res" + str(stage) + block + "_branch"
bn_name_base = "bn" + str(stage) + block + "_branch"
# 过滤器
F1, F2, F3 = filters
# 保存输入值,后面将需要添加回主路径
X_shortcut = X
# 主路径第一部分
X = Conv2D(filters=F1, kernel_size=(1, 1), strides=(s, s), padding="valid",
name=conv_name_base + "2a", kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + "2a")(X)
X = Activation("relu")(X)
# 主路径第二部分
X = Conv2D(filters=F2, kernel_size=(f, f), strides=(1, 1), padding="same",
name=conv_name_base + "2b", kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + "2b")(X)
X = Activation("relu")(X)
# 主路径第三部分
X = Conv2D(filters=F3, kernel_size=(1, 1), strides=(1, 1), padding="valid",
name=conv_name_base + "2c", kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + "2c")(X)
#shortcut路径
X_shortcut = Conv2D(filters=F3,kernel_size=(1,1),strides=(s,s),padding="valid",
name=conv_name_base+"1",kernel_initializer=glorot_uniform(seed=0))(X_shortcut)
X_shortcut = BatchNormalization(axis=3,name=bn_name_base+"1")(X_shortcut)
# 主路径最后部分,为主路径添加shortcut并通过relu激活
X = layers.add([X, X_shortcut])
X = Activation("relu")(X)
return X
tf.reset_default_graph()
with tf.Session() as test:
np.random.seed(1)
A_prev = tf.placeholder("float", [3, 4, 4, 6])
X = np.random.randn(3, 4, 4, 6)
A = convolutional_block(A_prev, f = 2, filters = [2, 4, 6], stage = 1, block = 'a')
test.run(tf.global_variables_initializer())
out = test.run([A], feed_dict={A_prev: X, K.learning_phase(): 0})
print("out = " + str(out[0][1][1][0]))
#50层ResNet模型构建
def ResNet50(input_shape = (64,64,3),classes = 6):
"""
构建50层的ResNet,结构为:
CONV2D -> BATCHNORM -> RELU -> MAXPOOL -> CONVBLOCK -> IDBLOCK*2 -> CONVBLOCK -> IDBLOCK*3
-> CONVBLOCK -> IDBLOCK*5 -> CONVBLOCK -> IDBLOCK*2 -> AVGPOOL -> TOPLAYER
param :
input_shape -- 数据集图片的维度
classes -- 整数,分类的数目
return:
model -- Keras中的模型实例
"""
#将输入定义为维度大小为 input_shape的张量
X_input = Input(input_shape)
# Zero-Padding
X = ZeroPadding2D((3,3))(X_input)
# Stage 1
X = Conv2D(64,kernel_size=(7,7),strides=(2,2),name="conv1",kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3,name="bn_conv1")(X)
X = Activation("relu")(X)
X = MaxPooling2D(pool_size=(3,3),strides=(2,2))(X)
# Stage 2
X = convolutional_block(X,f=3,filters=[64,64,256],stage=2,block="a",s=1)
X = identity_block(X,f=3,filters=[64,64,256],stage=2,block="b")
X = identity_block(X,f=3,filters=[64,64,256],stage=2,block="c")
#Stage 3
X = convolutional_block(X,f=3,filters=[128,128,512],stage=3,block="a",s=2)
X = identity_block(X,f=3,filters=[128,128,512],stage=3,block="b")
X = identity_block(X,f=3,filters=[128,128,512],stage=3,block="c")
X = identity_block(X,f=3,filters=[128,128,512],stage=3,block="d")
# Stage 4
X = convolutional_block(X,f=3,filters=[256,256,1024],stage=4,block="a",s=2)
X = identity_block(X,f=3,filters=[256,256,1024],stage=4,block="b")
X = identity_block(X,f=3,filters=[256,256,1024],stage=4,block="c")
X = identity_block(X,f=3,filters=[256,256,1024],stage=4,block="d")
X = identity_block(X,f=3,filters=[256,256,1024],stage=4,block="e")
X = identity_block(X,f=3,filters=[256,256,1024],stage=4,block="f")
#Stage 5
X = convolutional_block(X,f=3,filters=[512,512,2048],stage=5,block="a",s=2)
X = identity_block(X,f=3,filters=[256,256,2048],stage=5,block="b")
X = identity_block(X,f=3,filters=[256,256,2048],stage=5,block="c")
#最后阶段
#平均池化
X = AveragePooling2D(pool_size=(2,2))(X)
#输出层
X = Flatten()(X) #展平
X = Dense(classes,activation="softmax",name="fc"+str(classes),kernel_initializer=glorot_uniform(seed=0))(X)
#创建模型
model = Model(inputs=X_input,outputs=X,name="ResNet50")
return model
#运行构建的模型图
model = ResNet50(input_shape=(64,64,3),classes=6)
#编译模型来配置学习过程
model.compile(optimizer="adam",loss="categorical_crossentropy",metrics=["accuracy"])
#加载数据集
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
# Normalize image vectors
X_train = X_train_orig/255.
X_test = X_test_orig/255.
# Convert training and test labels to one hot matrices
Y_train = convert_to_one_hot(Y_train_orig, 6).T
Y_test = convert_to_one_hot(Y_test_orig, 6).T
print ("number of training examples = " + str(X_train.shape[0]))
print ("number of test examples = " + str(X_test.shape[0]))
print ("X_train shape: " + str(X_train.shape))
print ("Y_train shape: " + str(Y_train.shape))
print ("X_test shape: " + str(X_test.shape))
print ("Y_test shape: " + str(Y_test.shape))
#训练模型
model.fit(X_train,Y_train,epochs=20,batch_size=32)
#测试集性能测试
preds = model.evaluate(X_test,Y_test)
print("Loss = "+str(preds[0]))
print("Test Accuracy ="+str(preds[1]))si四、在tensorflow框架下构建残差卷积神经网络ResNet V2
ResNet V2中的残差学习单元为 bottleneck,与ResNet V1的主要区别在于:
1、在每一层前都使用了Batch Normalization;2、对输入进行preactivation,而不是在卷积进行激活函数处理。
(一)基础知识应用
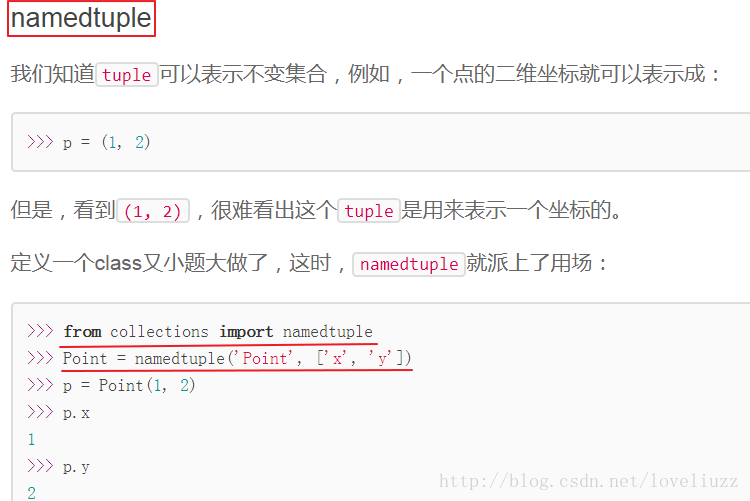
1、Python内建的集合模块——collections


















 2109
2109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









