







伪分布式安装
进入hadoop2.7.2的配置文件夹目录hadoop2.7.2/etc
STEP 1:
vi hadoop-env.sh
修改export JAVA_HOME=(写你的JAVA_HOME值)
STEP2:
vi core-site.xml
<configuration>
<!-- 用来指定namenode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ubuntu:9000</value>
</property>
<!-- 用来指定hadoop运行时产生的文件的存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop2.7.2</value>
</property>
</configuration>STEP3:
vi hdfs-site.xml
<!-- 指定hdfs副本保存数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>STEP4:
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<!-- 以后mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>STEP5:
vi yarn-site.xml
<property>
<!-- nodemanager获取数据的方式是shuffle的方式 -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- 指定yarn的resourcemanager的地址 -->
<name>yarn.resourcemanager.hostname</name>
<value>ubuntu</value>
</property>STEP6:
将HADOOP_HOME添加至环境变量
vi /etc/profile
添加完成后
source /etc/profile
STEP7:
初始化hdfs,格式化文件系统
以前hadoop namenode -forma
新的方式:
hdfs namenode -format
就第一次启动的时候格式化一下,后面再格式化会把数据格式化丢了
INFO common.Storage: Storage directory /opt/hadoop2.7.2/dfs/name has been successfully formatted.
STEP8:
cd sbin
./start-all.sh
因为之前安装1.x的时候配置过免密码登陆,所以没有输入密码
root@ubuntu:/app/bigdata/hadoop-2.7.2/sbin# ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [ubuntu]
ubuntu: starting namenode, logging to /app/bigdata/hadoop-2.7.2/logs/hadoop-root-namenode-ubuntu.out
localhost: starting datanode, logging to /app/bigdata/hadoop-2.7.2/logs/hadoop-root-datanode-ubuntu.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /app/bigdata/hadoop-2.7.2/logs/hadoop-root-secondarynamenode-ubuntu.out
starting yarn daemons
starting resourcemanager, logging to /app/bigdata/hadoop-2.7.2/logs/yarn-root-resourcemanager-ubuntu.out
localhost: starting nodemanager, logging to /app/bigdata/hadoop-2.7.2/logs/yarn-root-nodemanager-ubuntu.out
root@ubuntu:/app/bigdata/hadoop-2.7.2/sbin# jps
10341 NameNode -- 伪分布式一个,2.x集群多个
10635 SecondaryNameNode -- 协助namenode做事
10444 DataNode -- hdfs的小弟
10921 Jps
8453 Bootstrap
10884 NodeManager -- yarn的小弟
10780 ResourceManager -- yarn的老大上面显示This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
可见start-all.sh也过时了。。。。
使用start-dfs.sh 和start-yarn.sh代替
STEP9:
验证:
ubuntu:50070(hdfs管理界面)
ubuntu:8088(yarn管理界面)
测试hdfs:
将本地的一个文件存储到hdfs系统上
root@ubuntu:/app/bigdata/hadoop-2.7.2/sbin# hadoop fs -put slaves.sh hdfs://ubuntu:9000/test
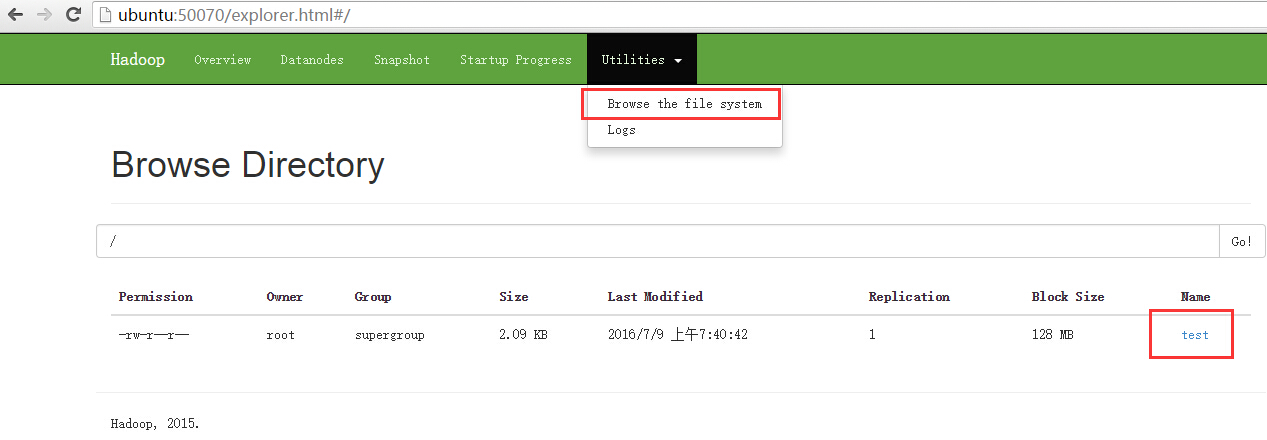
test就是上传的slaves.sh文件
上传成功
命令下载:
hadoop fs -get hdfs://ubuntu:9000/test /本地路径
测试mapreduce:
root@ubuntu:/app/bigdata/hadoop-2.7.2/share/hadoop/mapreduce# vi words
root@ubuntu:/app/bigdata/hadoop-2.7.2/share/hadoop/mapreduce# wc words
9 12 63 words -- 9行,12个单词,63个字符
root@ubuntu:/app/bigdata/hadoop-2.7.2/share/hadoop/mapreduce# cat words
hadoop hello
hello dfs dfs
hadoop
dfs
tom
tom
hello
hadoop
root@ubuntu:/app/bigdata/hadoop-2.7.2/share/hadoop/mapreduce# hadoop jar hadoop-mapreduce-examples-2.7.2.jar -- 显示示例程序
An example program must be given as the first argument.
Valid program names are:
aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files.
aggregatewordhist: An Aggregate based map/reduce program that computes the histogram of the words in the input files.
bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi.
dbcount: An example job that count the pageview counts from a database.
distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi.
grep: A map/reduce program that counts the matches of a regex in the input.
join: A job that effects a join over sorted, equally partitioned datasets
multifilewc: A job that counts words from several files.
pentomino: A map/reduce tile laying program to find solutions to pentomino problems.
pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method.
randomtextwriter: A map/reduce program that writes 10GB of random textual data per node.
randomwriter: A map/reduce program that writes 10GB of random data per node.
secondarysort: An example defining a secondary sort to the reduce.
sort: A map/reduce program that sorts the data written by the random writer.
sudoku: A sudoku solver.
teragen: Generate data for the terasort
terasort: Run the terasort
teravalidate: Checking results of terasort
wordcount: A map/reduce program that counts the words in the input files.
wordmean: A map/reduce program that counts the average length of the words in the input files.
wordmedian: A map/reduce program that counts the median length of the words in the input files.
wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files.
root@ubuntu:/app/bigdata/hadoop-2.7.2/share/hadoop/mapreduce# hadoop jar hadoop-mapreduce-examples-2.7.2.jar wordcount
Usage: wordcount <in> [<in>...] <out>
-- 输入输出都在dfs上
root@ubuntu:/app/bigdata/hadoop-2.7.2/share/hadoop/mapreduce# hadoop fs -put words hdfs://ubuntu:9000/words
root@ubuntu:/app/bigdata/hadoop-2.7.2/share/hadoop/mapreduce# hadoop fs -ls hdfs://ubuntu:9000/
Found 2 items
-rw-r--r-- 1 root supergroup 2145 2016-07-09 07:40 hdfs://ubuntu:9000/test
-rw-r--r-- 1 root supergroup 63 2016-07-09 07:55 hdfs://ubuntu:9000/words
root@ubuntu:/app/bigdata/hadoop-2.7.2/share/hadoop/mapreduce# hadoop jar hadoop-mapreduce-examples-2.7.2.jar wordcount hdfs://ubuntu:9000/words hdfs://ubuntu:9000/wcout
16/07/09 07:57:08 INFO client.RMProxy: Connecting to ResourceManager at ubuntu/172.17.0.1:8032
16/07/09 07:57:09 INFO input.FileInputFormat: Total input paths to process : 1
16/07/09 07:57:09 INFO mapreduce.JobSubmitter: number of splits:1
16/07/09 07:57:09 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1468020180179_0001
16/07/09 07:57:10 INFO impl.YarnClientImpl: Submitted application application_1468020180179_0001
16/07/09 07:57:10 INFO mapreduce.Job: The url to track the job: http://ubuntu:8088/proxy/application_1468020180179_0001/
16/07/09 07:57:10 INFO mapreduce.Job: Running job: job_1468020180179_0001
16/07/09 07:57:23 INFO mapreduce.Job: Job job_1468020180179_0001 running in uber mode : false
16/07/09 07:57:23 INFO mapreduce.Job: map 0% reduce 0%
16/07/09 07:57:33 INFO mapreduce.Job: map 100% reduce 0%
16/07/09 07:57:42 INFO mapreduce.Job: map 100% reduce 100%
16/07/09 07:57:42 INFO mapreduce.Job: Job job_1468020180179_0001 completed successfully
16/07/09 07:57:42 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=61
FILE: Number of bytes written=234853
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=152
HDFS: Number of bytes written=35
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=6159
Total time spent by all reduces in occupied slots (ms)=6461
Total time spent by all map tasks (ms)=6159
Total time spent by all reduce tasks (ms)=6461
Total vcore-milliseconds taken by all map tasks=6159
Total vcore-milliseconds taken by all reduce tasks=6461
Total megabyte-milliseconds taken by all map tasks=6306816
Total megabyte-milliseconds taken by all reduce tasks=6616064
Map-Reduce Framework
Map input records=9
Map output records=12
Map output bytes=111
Map output materialized bytes=61
Input split bytes=89
Combine input records=12
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=61
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=160
CPU time spent (ms)=1540
Physical memory (bytes) snapshot=303501312
Virtual memory (bytes) snapshot=1324359680
Total committed heap usage (bytes)=168497152
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=63
File Output Format Counters
Bytes Written=35
root@ubuntu:/app/bigdata/hadoop-2.7.2/share/hadoop/mapreduce# hadoop fs -ls hdfs://ubuntu:9000/wcout
Found 2 items
-rw-r--r-- 1 root supergroup 0 2016-07-09 07:57 hdfs://ubuntu:9000/wcout/_SUCCESS
-rw-r--r-- 1 root supergroup 35 2016-07-09 07:57 hdfs://ubuntu:9000/wcout/part-r-00000
root@ubuntu:/app/bigdata/hadoop-2.7.2/share/hadoop/mapreduce# hadoop fs -cat hdfs://ubuntu:9000/wcout/part-r-00000
dfs 3
hadoop 3
hello 3
tom 2
woo 1














 162
162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









