







任务调度系统
序
在有了各种数据统计任务之后,就产生了任务调度需求,我们需要把任务管理起来统一调度,保证任务之间上下游的依赖关系,监控任务运行状态,异常情况下及时告警,尽可能自动化处理异常,调度系统高可用,使每天的数据统计任务按时执行完成。
这里我们采用了自研的方式来开发任务调度系统,保证系统的高度可控,以及后续功能扩展性。
当然也有一些开源比较好用的调度系统可以直接使用,比如:azkaban、xxl-job 等,可以参考这些开源的架构做调度系统设计。
系统目标
整个任务调度系统需要完成以下功能:
- 任务信息管理
- 依赖关系维护
- 任务调度
- 调度器高可用
- 任务异常告警
- 任务血缘关系管理
架构设计
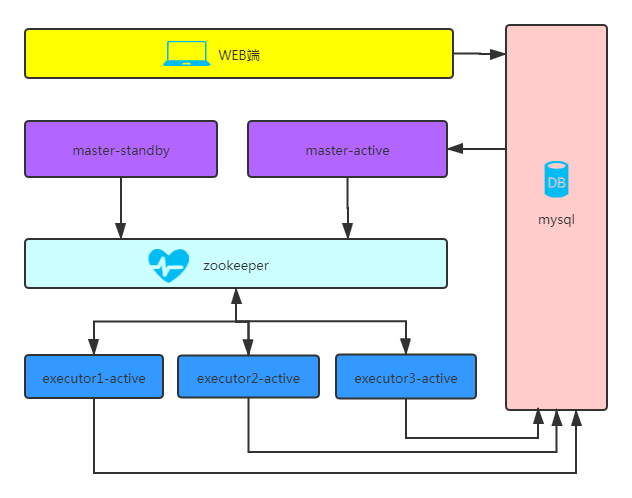
目前整体架构如上图所示,各个部分的功能如下。
web端:负责各类任务信息的配置与维护,包括基本信息管理、依赖关系管理、输入输出管理、调度信息配置、报警信息配置等;
mysql:负责保存任务配置信息、任务调度执行计划信息等相关任务信息;
master-active:调度器主节点,主要负责任务的触发、依赖检查、任务发布至zookeeper、任务报警等模块;
master-standby:调度器主节点备用节点,通过zookeeper完成主备识别与自动切换容灾;
zookeeper:负责主备切换、管理可执行任务信息;
executor:任务执行器,包括任务的解析器、执行器、yarn资源感知、任务信息管理、任务报警等模块。
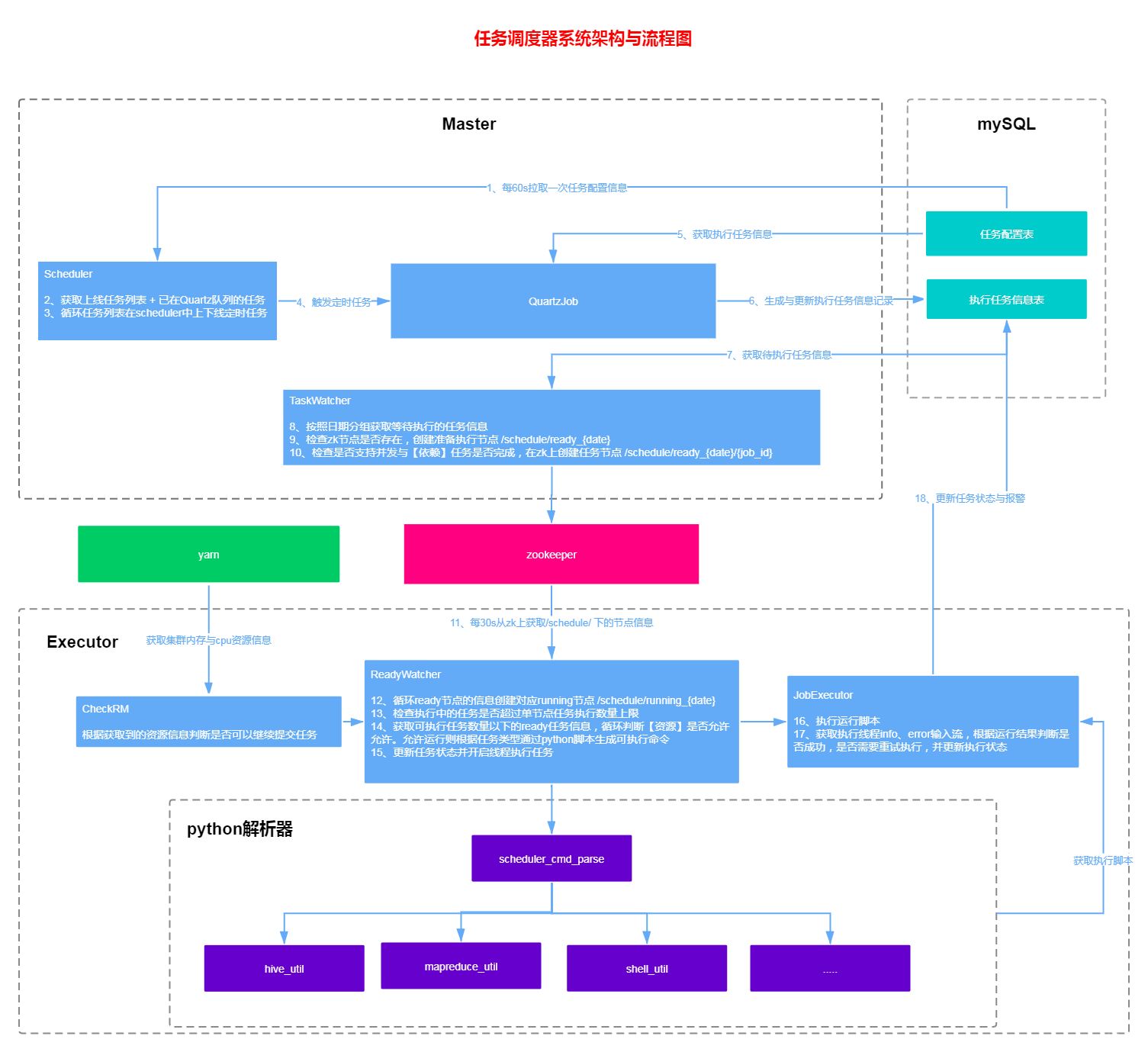
这个图描述了任务整体的调度流程,整体流程大致分为以下几个部分
- master-scheduler[主节点-调度解析]
step1:每60s拉取一次任务配置信息
step2:获取上线任务列表 + 已在Quartz队列的任务
step3:循环任务列表在scheduler中上下线定时任务
step4:触发任务 - master-quartzJob[主节点-执行计划解析]
step5:获取执行任务信息
step6:生成与更新执行任务信息记录至mysql表 - master-taskWatcher[主节点-执行计划观察者]
step7:获取待执行任务信息
step8:按照日期分组获取等待执行的任务信息
step9:检查zk节点是否存在,创建准备执行节点 /schedule/ready_{date}
step10:检查是否支持并发与【依赖】任务是否完成,在zk上创建任务节点 /schedule/ready_{date}/{job_id},并在节点上保存关键调度信息 - executor-readyWatcher[执行器-待执行任务观察者]
step11:每30s从zk上获取/schedule/ 下的节点信息
step12:循环ready节点的信息创建对应running节点 /schedule/running_{date}
step13:检查执行中的任务是否超过单节点任务执行数量上限
step14:获取可执行任务数量以下的ready任务信息,循环判断【资源】是否允许允许。允许运行则根据任务类型通过python脚本生成可执行命令
step15:更新任务状态并开启线程执行任务 - executor-jobExecutor[执行器-任务执行]
step16:开启线程执行运行脚本
step17:获取执行线程info、error输入流,根据运行结果判断是否成功,是否需要重试执行,并更新执行状态
其中相对独立的2个模块:
- executor-python解析器
根据任务类型,调用不同的python解析脚本,生成对应任务可执行命令文件,以供调度器实际运行时调度使用。由于该部分频繁的改动各类参数,所以采用python脚本生成的方式。 - executor-yarn资源控制
通过yarn的api接口获取到集群当前资源情况,控制执行器是否能向当前集群继续提交任务
整体操作zookeeper部分采用了Curator分布式锁。
优化升级
在项目上线一段时间之后,后续我们陆续做了一下功能优化:
- 任务通过hash负载均衡到各个executor进行执行
- 任务支持并行执行
- 任务支持配置重试次数
- 延迟告警
- 任务变动通知下游任务
- 支持自定义运行参数
- 任务资源使用率等健康情况监控统计
- 扩展支持更多的任务类型
至此整个任务调度系统暂时开发完成,初步完了任务调度系统所需要的核心功能。














 1323
1323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









