







7.数据智能
一、序
在有了实时离线的数据之后,我们终于可以使用数据进行业务分析了,基本解决了数据what阶段。对于一个指标我们可以清晰的在数据上发现数据的变化,反应业务的变化情况。但是往往业务是复杂的,经常会有如下这样的疑问:
场景1:今天的支付订单增加了,到底是哪个业务维度、品类维度、城市维度所带来的增长呢?
场景2:以现在的用户增长率、订单增长率,未来的某段时间我们用户量会达到多少?订单是多少?
针对场景1的离线场景,我们开发了一套离线根因分析系统,来帮助用户快速的定位到造成数据变化的根本原因,提高数据分析的效率。
针对场景2的实时场景,我们开发了一套基于时序预测的系统,根据以往的历史数据实时预测未来的数据,并支持预测数据与真实数据实时进行对比分析,用来判断数据是否存在异常情况等。
接下来将分别大致介绍一下,离线根因分析、实时预测系统的设计原理与一些实践尝试的经验,来解决数据WHY的问题。
二、离线根因分析
离线根因分析的方法很多,可以做的很复杂也可以做的很简单,比如:
1、我们简单计算每个维度的变化率,根据变化率倒序排序找出指标变化具体是受哪个维度的影响;
2、基于决策树等机器学习模型来快速的分析出来引起数据变化的最大的维度组合;
而我们采用了一个基于基尼系数来判断维度变化情况的方式来进行维度的分析,首先我们先了解一下什么是基尼系数,以下解释来自百度。
基尼系数(英文:Gini index、Gini Coefficient)是指国际上通用的、用以衡量一个国家或地区居民收入差距的常用指标。
基尼系数最大为“1”,最小等于“0”。基尼系数越接近0表明收入分配越是趋向平等。国际惯例把0.2以下视为收入绝对平均,0.2-0.3视为收入比较平均;0.3-0.4视为收入相对合理;0.4-0.5视为收入差距较大,当基尼系数达到0.5以上时,则表示收入悬殊。
基尼指数最早由意大利统计与社会学家Corrado Gini在1912年提出。

基尼系数是根据洛伦兹曲线判断收入分配公平程度的指标,在根因分析的项目里我们加以修改,用于衡量各维度内维度值变化的公平程度。在收入分配的情景下,使用用户数占比作为X轴,收入占比作为Y轴。而在本项目中,使用维度值占比作为X轴,变化值占比作为Y轴。
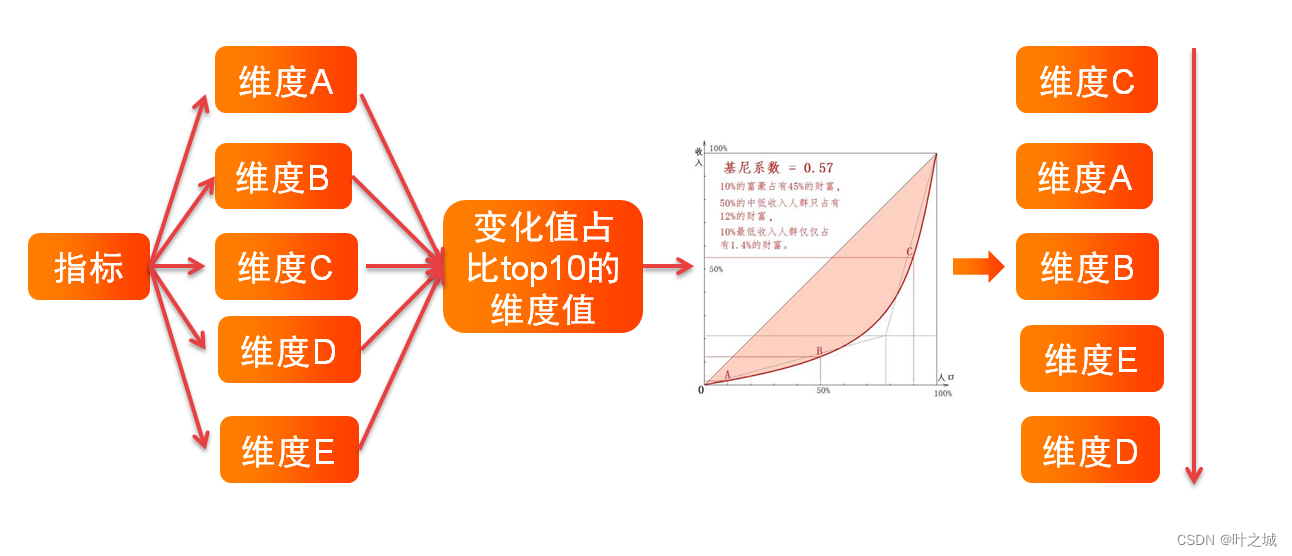
整体分析步骤如下:
1.数据读取
从元数据信息管理系统中获取指定指标信息,从而拿到对应的当前时间和对比时间数据
2.生成维度值比和变化值比
维度值比 = (当前值+对比值)/总值,总值为每一个维度的当前值和对比值的总和
变化值比 = (当前值-对比值)/变化总值,变化总值为每一个维度的变化值之和
3.根据变化值比倒排
根据基尼系数的构造方式,需要将每个群体的收入占比从小到大排序,最终才能构造出洛伦兹曲线。所以在本项目中,将变化值占比从小到达排序,最终获得已排序的变化值比的数组,以及对应的维度值比数组。
4.基尼系数计算
计算基于极限原理,在X轴间隔足够小的时候,更趋近于真实值。计算结果比真实值偏小,X轴间隔越大,偏差程度越大。其中涉及到一些特殊异常情况下异常值的处理,来更加合理的计算处理维度对应的基尼系数。
根据各个维度的基尼系数,我们可以很容易得出维度对变化的影响,然后再根据各个维度下的值的变化率等其他指标来找出维度下具体哪个维度影响的大小。如下图,我们确定维度C下的具体值1影响最大,怎么找出其他维度的组合呢,就是限制维度C的值等于值1的情况下,对其他维度进行分析,用了找出维度与维度组合的最终原因。
整体上该方案适合多维情况下的根因分析,最终效果基本满足日常分析需求。
三、实时预测告警
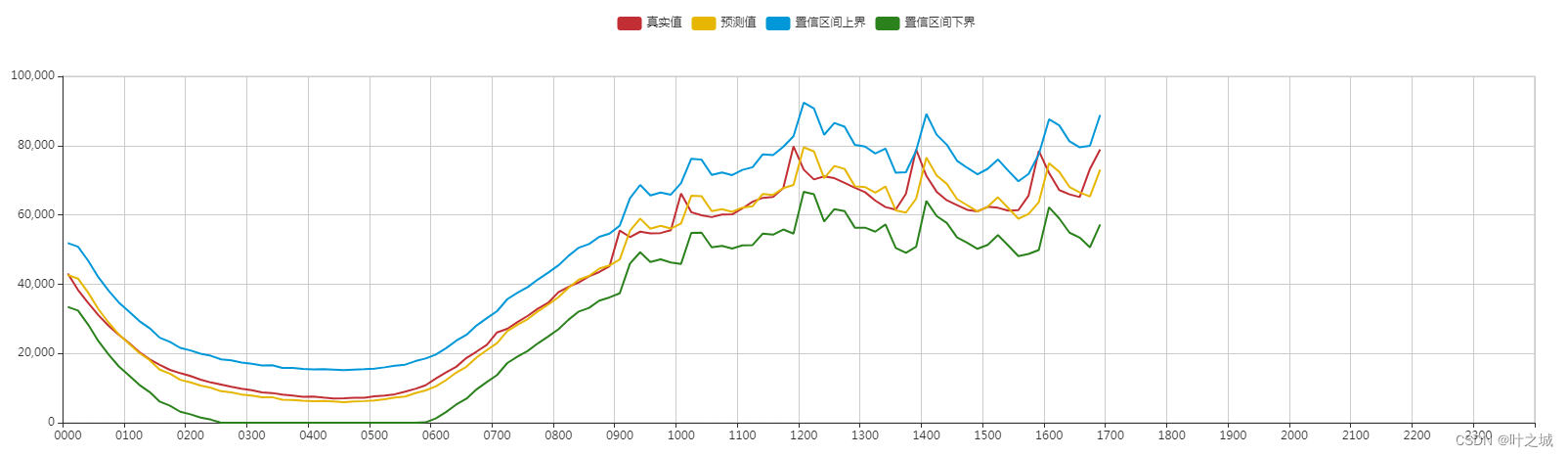
场景
目前有很多实时指标用于监控业务状态,如何准确、及时地发现实时数据异常,并分析异常原因,是本项目需要解决的问题。
- 及时:在数据出现异常时,尽快发现异常,能够最大程度减小损失。
- 准确:频繁误报会使相关人员对告警失去信任,从而不能及时处理。
异常识别方法
在异常的判定中,最常用的就是使用同比或环比,但这两种方式都有一个明显的缺陷。
- 同比:当前值和上一周期的值进行比较,如果当天数据整体上涨或下降,那么会有非常频繁的告警。
- 环比:当前值和上一个值进行比较,如果数据出现周期性波动,也会出现误报,并且环比变化最大的,也不一定就是异常的数据。
- 同比 + 环比:即便单独使用同比或环比都不行,那么把两个结合起来一起使用是否可以呢?理论上来说是能够解决一定问题的,但是加权平均的权重如何确定?这也是一个难以获得准确结果的问题。
在同比或环比的判断中,仅使用了前一个点或前一个周期点两个时间点的数据,并没有充分利用整个时间序列的变化趋势,所以为了解决这类问题,我们采用时间序列预测算法三次指数平滑来预测数据,并与真实值进行比较来达到异常告警的目的。
时序预测-三次指数平滑
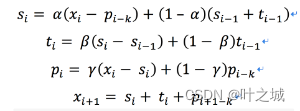
使用时序预测模型之前,我们要根据自己的数据特定来选择适合的模型,我们可以先观察数据是否有趋势性、周期性等。
Hot-Winters是指数平滑法,属于调和平均的一种方式。历史数据时间越久,对当前预测值的影响比重呈指数递减,但所有的历史数据都会对当前预测值产生影响,这样就能够利用整个时间序列的变化趋势。
实际上我们只需要根据业务调整α β γ三个参数,使整体预测数据与真实数据的均方差最小即可,最终我们的值分别取(0.8,0.2,0.2),可以根据预测数据的特性,使用不用的参数值来预测数据。
预测区间与异常判断
得到预测值与真实值之后,我们需要判断数据是否异常。由于预测数值存在一定的误差,所以我们允许真实值在一定范围内波动,因为预测区间基于误差值获得,当误差较小的时候,预测区间很小,会造成一定程度的误报。根据对预测结果进行分析,当计算出来的误差预测区间为[a*真实值, b*真实值] 时,最终选择的误差预测区间为[min(-0.06,a)*真实值, max(0.06,b)*真实值],来放大误差较小情况下的预测区间,减少误报的情况。
在发现数据异常之后,我们需要实时分析出来实时数据异常的原因,这里我们预设了一些指标的分析维度,采用同比、环比等简单的方式快速分析可能的原因。
总结
基于以上理论,我们大致解决了离线的根因分析与实时数据异常告警分析。每个公司业务和资源的不同可以采用不同的分析方法,可以根据资源使用简单的方式 ,也可以使用机器学习等等相对复杂的分析办法。具体实现并不是越复杂越好,简单的方式方法也可能比较准确高效。
以后可能有更多的数据智能化场景,整体都离不开降本增效,提升数据使用效率,大道至简。















 604
604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









