







5.实时离线统计系统
一、序
在有了日志等数据之后,我们需要根据业务方的需求来统计各类数据报表以供业务分析使用。这里我们分两个方向离线和实时,都是从零到一随着技术的发展逐步建设和发展完善起来的。由于都是通过一定的模型进行统计,统称为模型化统计系统。
**原始阶段:**在各种技术刚刚起步的阶段,对于各种需求基本都是手动编码去做一下定制化统计与展示;
**初始阶段:**离线和实时的数据统计,在没有指标系统之前,都是通过抽象日志,形成对应的统计规则,然后统计程序根据配置的规则进行解析与统计;
**发展阶段:**通过多维数仓、实时技术的发展,与各种分析组件打通,比如kylin、druid、clickhouse完成数据的统计与分析;
**指标系统阶段:**由实时离线统计系统,解析指标管理系统的配置信息,进行数据的统计工作,从而保证数据口径的一致。
二、离线
大多数公司,都是从定制化开发开始做数据分析的工作,比如最开始针对不同的数据分析需求编写对应的MapReduce程序;针对对应的报表写hive sql统计成结果表,再抽取到mysql进行数据分析与展示…很多情况下都是烟囱式开发,缺点明显:1、维护开发成本高;2、不成体系,逻辑无法复用;3、计算资源的浪费。为了解决这些问题,我们开发了一个MapReduce的离线统计系统,就是下面所述的单维模型统计系统。
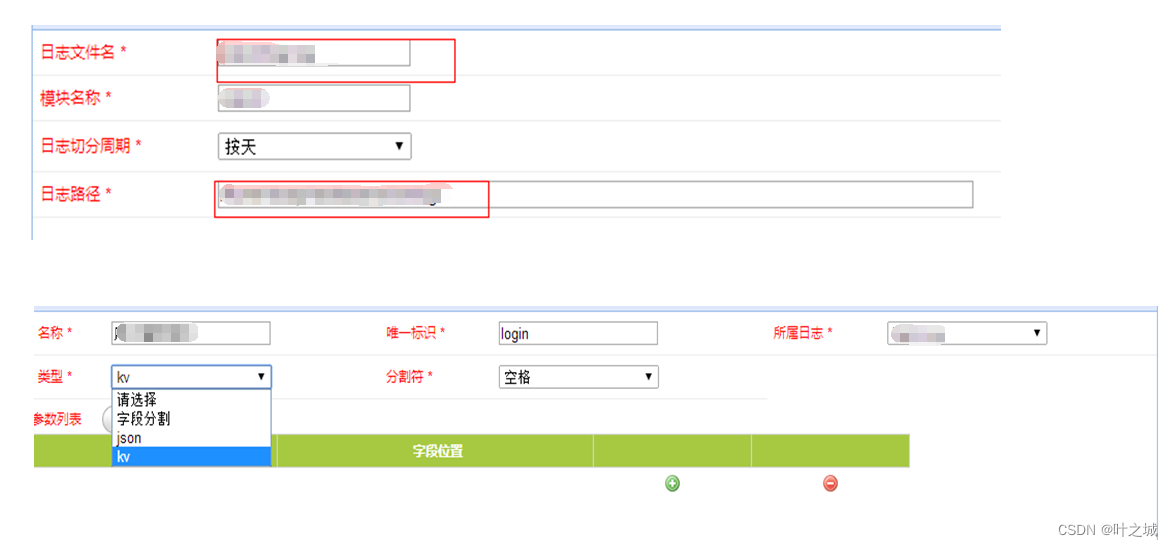
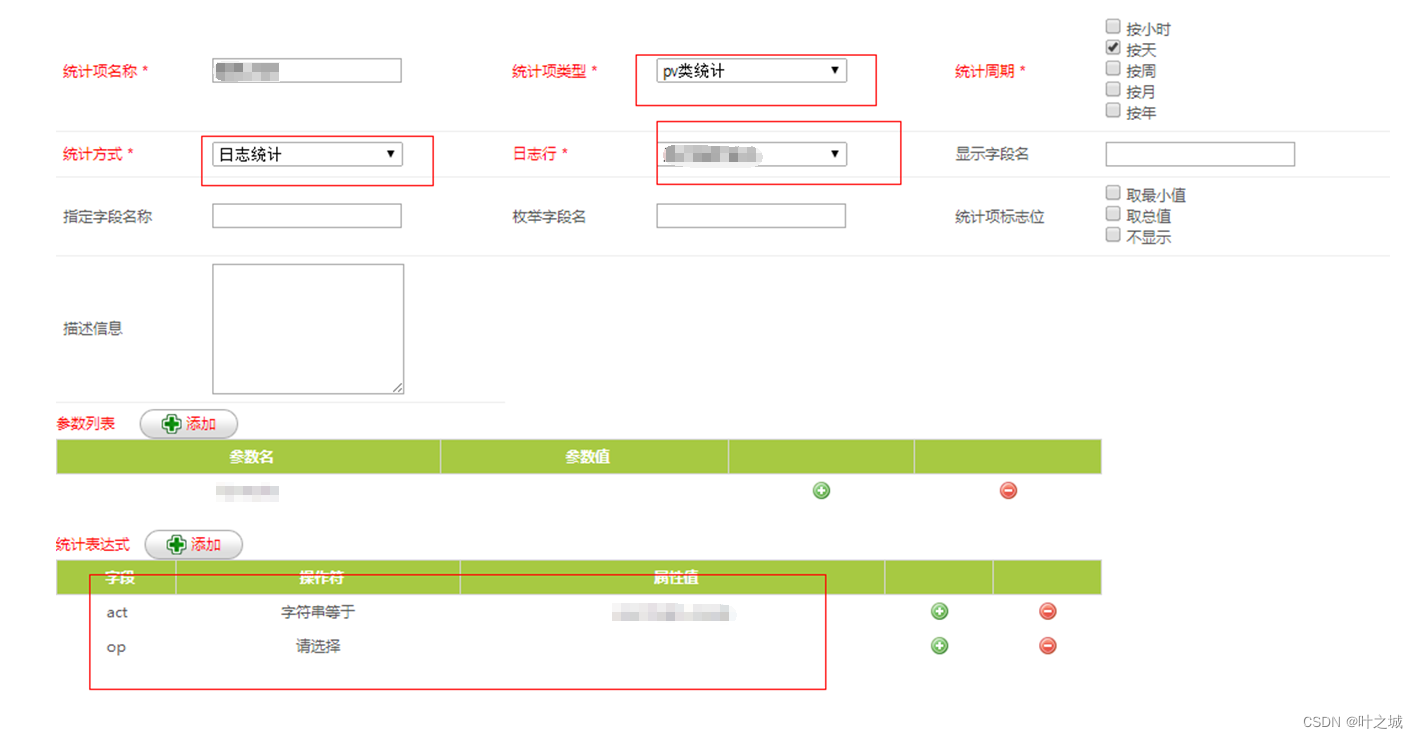
为了解决一些常见的离线的数据统计,首先我们定义了一个后端日志、前端日志的统计模型,在这个模型的基础之上去定义指标,在该系统下只能对一个指标只能做确定性的维度精选统计,比如统计品类下A、B的数据,我们需要配置成2个指标来进行统计,指标支持pv、uv、sum、top统计。这样在后端统计程序上可以相对简单的实现对应的统计,减少了后端复杂度,增加了可靠性。
我们统计好了数据之后,有对应的展示系统来做数据的展示,我们可以通过组合各种指标来形成对应的报表。这套系统在前中期为我们解决了一部分普通的统计需求。
当然,这个系统也是有局限性的,1、对多维分析支持的不够友好 2、展示的单一性 3、整体上不够灵活,在一定范围内实现了配置化统计。这种模式基本也就是实现了告诉你数据是怎样的,不能够进行探索式分析,充分的发掘数据价值。
现在更多的情况是采用数仓明细表+数据分析的各种组件组合这样的方式,这样我们充分的发挥了数据仓库的价值,保证了逻辑的复用口径的统一,由于kylin、clickhouse的特点不同,我们可以针对不同需求数据的特定选择接入到不同的分析组件下,来实现快速的OLAP数据分析。由于这些计算分析的组件,基本都支持sql化的查询,为后续的数据统一的展示对接打下了较好的基础。
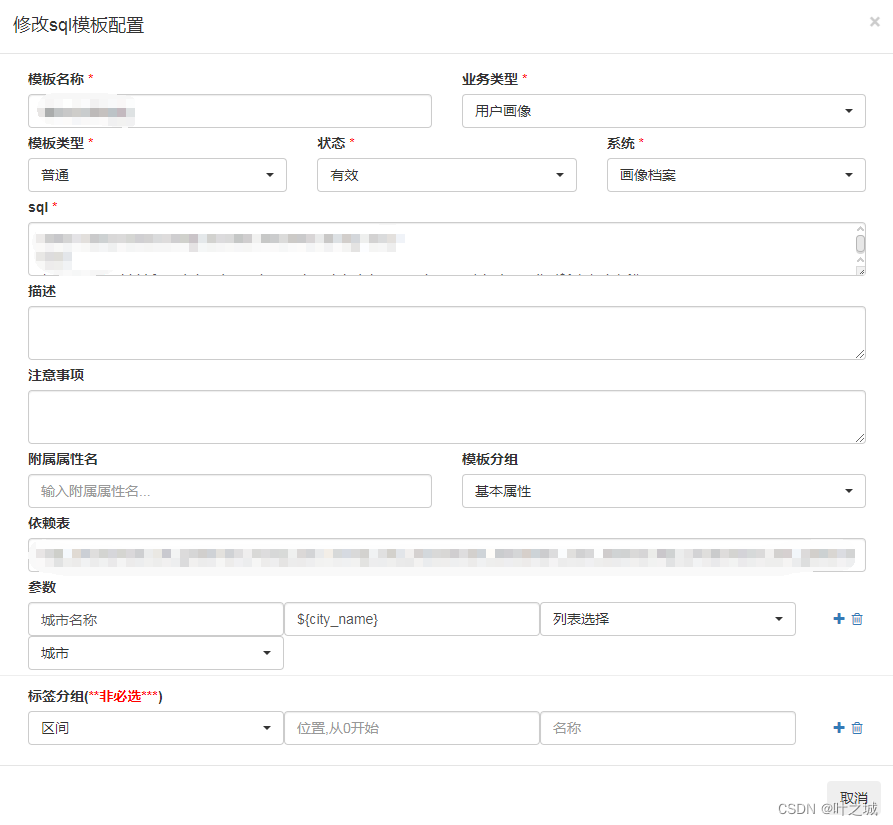
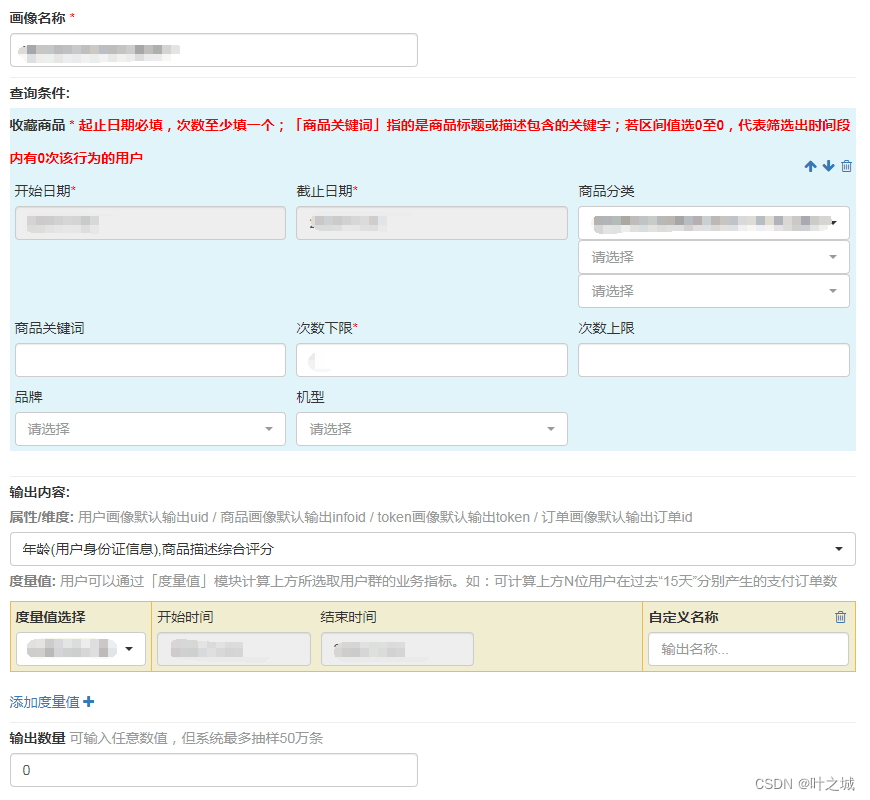
这套系统是针对业务运营、产品人员快速的提取数据所设计的。本质上是通过预先配置好的SQL模板,来帮助不会写sql的运营、产品完成数据统计SQL逻辑的开发。相当于用户标签画像的雏形前期阶段。后续根据这套统计系统扩展了留存、漏斗、标签模型的计算。
SQL模板的定义:配置一个SQL模板,描述对应的sql需要填写哪些参数,使用对应的占位符进行填充,指定对应的占位符使用哪个维度来解析,比如:是日期、品类、城市,这样可以通过下拉框来确定具体执行的sql。
模板关系:通过配置各个模板SQL所筛选出来的人群,可以对各个模板的人群做交集、或集等集合逻辑运算,最终获取到对应满足条件的人群。
数据的计算:在参数与关系确定的情况下,我们通过hive JDBC的方式控制任务的执行与数据的下载。
这个套系统解决了业务人员提取数据的需求,是帮助不会写sql的人员用图形化的方式完成业务sql逻辑的编写。当然这个套系统也有着明显的缺点:
1、完成了sql模板的复用,但是重复性计算,浪费了计算资源
2、逻辑相对黑盒,无法沉淀成对应的数据仓库表,导致sql模板在一定程度上的局限,不能把数据沉淀下来
3、业务逻辑变化时需要更新对应模板
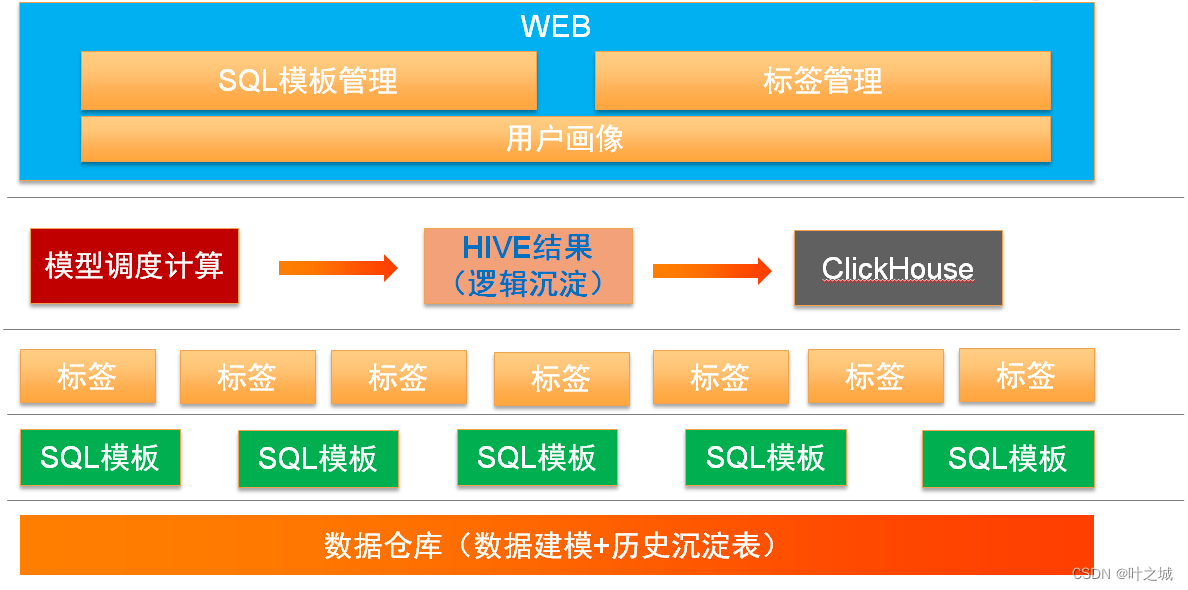
在此基础上我们后续重新设计开发了用户标签系统,做了如下的改进
1、保留了sql模板,不过这个模板是为了可以对接各个业务方的标签数据,比如:搜索推荐的标签库、风控的标签、也可以比较方便的对接到已在数仓的标签表。相对来说用sql模板保留了扩展性。
2、数据标签结果可沉淀数仓,这样相当于生成了对应的标签数仓表,各个分析或业务团队可以直接使用与对接,统一标签标准。
3、引入clickhouse组件,加快标签数据提取效率。相对与之前的hive jdbc,也是一个预计算的过程,由于预计算可以实现更快的数据查询与提取。
三、实时
实时统计系统的发展整体上与离线统计的发展类似,实时的流式处理,向着sql化与批流统一的方向不断的进步与发展,从最开始的storm、spark、spark streaming、flink,不断的进步提升性能,解决各种实时问题,增强功能。各种后续相关的系统也随之应运而生。
在这个阶段,我们主要是根据用户的实时需求,按照特定的业务逻辑编写对应的storm程序进行数据统计,最终把结果落地到hbase当中,以供后续查询系统进行查询与数据展示。在实时模型化统计不能支持的情况下,还需要采用这种方式使用flink等对特殊数据进行统计与处理。
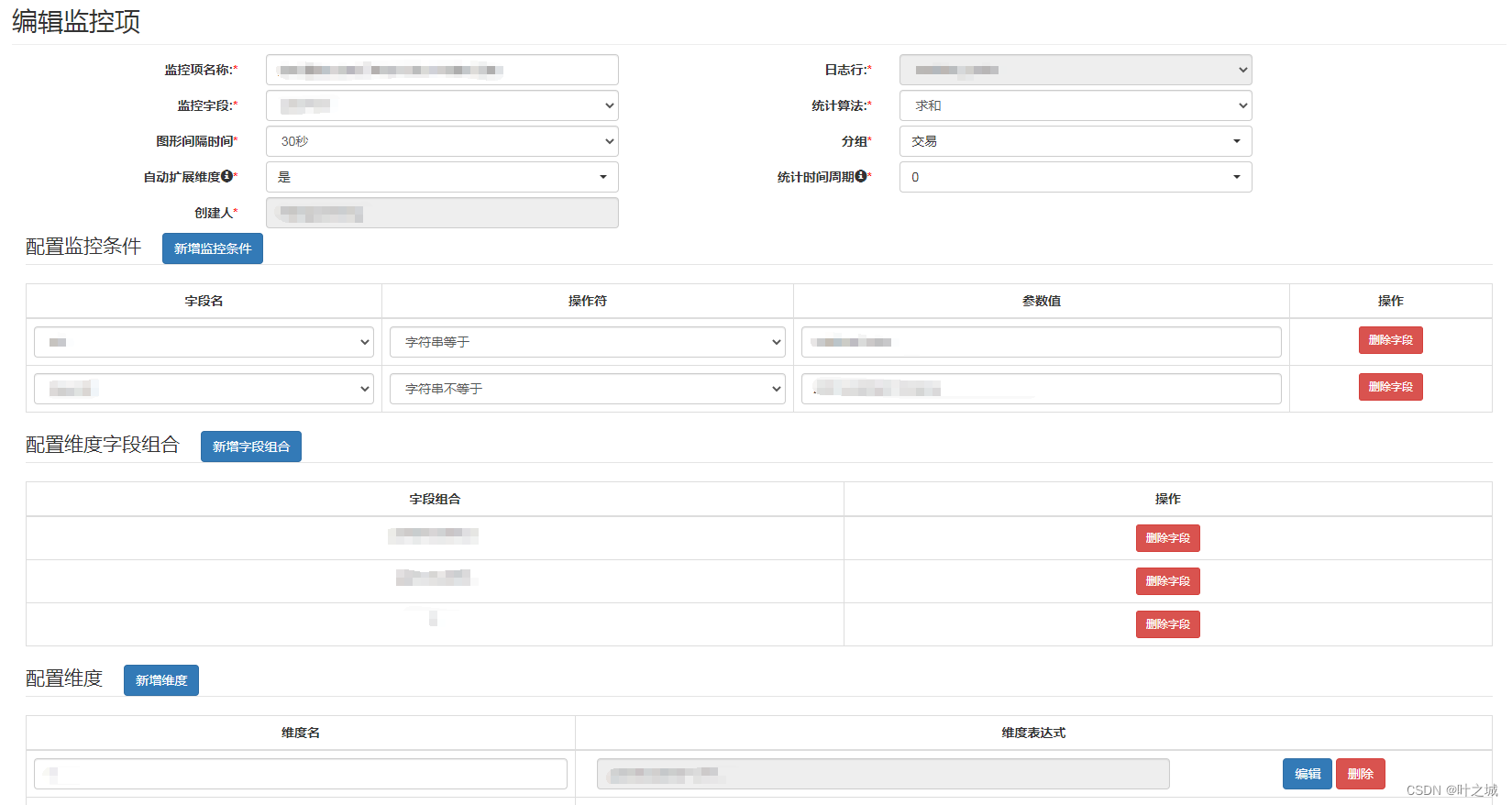
kafka日志抽象:针对不同的topic日志,对日志进行抽象配置,指定分隔符和日志行对应的字段信息等
监控项:通过配置好的日志行,来定义监控项生成对应的统计规则,包括条件、维度组合、维度自动发现等等
数据展示:通过前端平台按照特定的数据逻辑来查询对应实时的数据结果
实时模型化统计,整个后端计算引擎最开始我们使用storm,后续逐步升级spark streaming版本,以及flink版本,根据不同的技术特定引入了新的统计方式的支持,比如flink的join操作等。后续可以扩展结果数据可以写入到不同的目的地当中。
同离线数据一样,实时我们也有着各种多维分析的场景,这里我们使用实时的流式处理技术把数据洗如到druid当中,然后使用druid做实时多维分析的查询与结果数据的展示。
四、展望
- 统一指标模型系统:实时离线统计系统统一对接一套统计模型管理系统,最大程度上保证实时离线数据口径的一致性;
- 批流合一:随着流式处理的发展、实时数仓等建设,逐步实现实时、离线统计系统的合并,只保留一套统计系统,减少各种计算资源的浪费。















 500
500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









