







八、Spark 部署模式
1、Local本地模式:运行于本地
spark-shell --master local[2] (local[2]是说,执行Application需要用到CPU的2个核)
2、Standalone独立模式:Spark自带的一种集群模式
Spark自己管理集群资源,此时只需要将Hadoop的HDFS启动
Master节点有master,Slave节点上有worker
启动 ./bin/spark-shell --master spark://master:7077
3、YARN模式
Spark自己不管理资源,向YARN申请资源,所以必须保证YARN是启动起来的
操作步骤:
启动Hadoop:到Hadoop目录执行start-all.sh
到Spark目录, ./bin/spark-shell --master yarn-client(yarn-cluster)
4、IDEA中生成Jar包,使用IDEA编译class文件,同时将class打包成Jar文件。
1》File——Project Structure,弹性“Project Structure”的设置对话框
2》选择左边的Artifacts,点击上方的“+”按钮
3》在弹出的对话框中选择“Jar”——“from moduls with dependencies”
4》选择要启动的类,然后确定
5》应用之后选择菜单“Build”——“Build Artifacts”,选择“Build”或“Rebuild”即可生成
5、Spark提交Job
./spark-submit \
--class spark.SparkCore.WordCount \
--master yarn-cluster \
/home/hadoop/jar/spark.jar

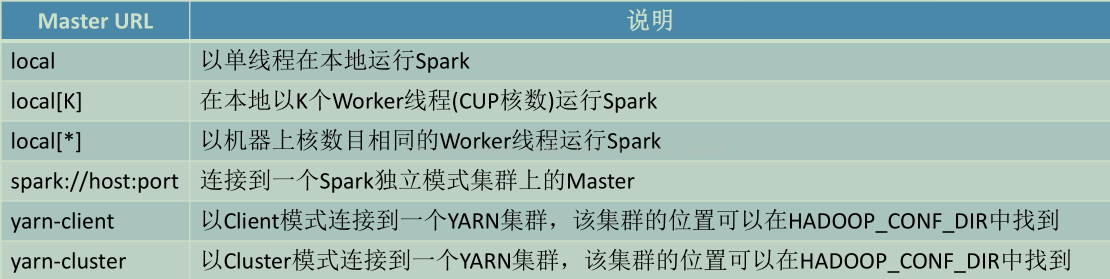
注:Master URL格式及说明:
九、写脚本启动集群及提交任务
#!/bin/bash
case $1 in
start)
echo "Spark online..."
sh ${SPARK_HOME}/sbin/
start-all.sh;;
shell)
sh ${SPARK_HOME}/bin/spark-shell;;
submit)
sh ${SPARK_HOME}/bin/spark-submit $2;;
stop)
sh ${SPARK_HOME}/sbin/
stop-all.sh
echo "Spark offline.";;
*)
echo "Need parameters!";;
esac
然后,切换root用户把脚本放进/bin下
例:sh xxx.sh submit "--class core.SparkCore --master yarn-client /home/raven/jars/SparkTest.jar"
十、RDD弹性分布式数据集
1、总述
RDD是Spark提供的核心抽象,全称为Resillient Distributed Dataset,即弹性分布式数据集。
RDD在抽象上来说是一种元素集合,包含了数据。它是被分区的,分为多个分区。每个分区分布在集群中的不同节点上,从而让RDD中的数据可以被并行操作。(分布式数据集)。
RDD通常通过Hadoop上的文件,即HDFS文件或者Hive表,来进行创建,也可以通过应用程序中的集合来创建。
RDD最重要的特性就是,提供了容错性,可以自动从节点失败中恢复过来。如果某个节点上的RDD partition,因为节点故障,导致数据丢了,那么RDD会自动通过数据来源重新计算该partition。
RDD的数据默认情况下存放在内存中的,但是在内存资源不足时,Spark会自动将RDD数据写入磁盘。(弹性)
2、RDD的定义
一个RDD对象,包含如下5个核心属性:
1》一个分区列表,每个分区里是RDD的一部分数据(或称数据块);
2》一个依赖列表,存储依赖的其他RDD;
3》一个名为computer的计算函数,用于计算RDD各分区的值;
4》分区器(可选),用于键/值类型的RDD,比如某个RDD是按散列来分区;
5》计算各分区时优先的位置列表(可选),比如从HDFS上的文件生成RDD时,RDD分区的位置优先选择数据所在的节点,这样可以避免数据移动带来的开销。
3、创建RDD
进行Spark核心编程时,首先要做的第一件事,就是创建一个初始的RDD。该RDD中,通常包含了Spark应用程序的输入源数据。在创建了初始的RDD之后,才可以通过Spark Core提供的transformation算子,对该RDD进行转换获取其他的RDD。
Spark Core提供了三种创建RDD的方式,包括:1》使用程序中的集合创建RDD
2》使用本地文件创建RDD或使用HDFS文件创建RDD 3》RDD通过算子形成新的RDD
经验总结:
1》使用程序中的集合创建RDD,主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构造测试数据,来测试后面的Spark应用的流程。
2》使用本地文件创建RDD,主要用于临时性地处理一些存储了大量数据的文件。
3》使用HDFS文件创建RDD,应该是最常用的生产环境处理方式,主要可以针对HDFS上存储的大数据,进行离线批处理操作。
第一种方式:并行化集合创建RDD
如果要通过并行化集合来创建RDD,需要针对程序中的集合,调用SparkContext的 parallelize() 方法。Spark会将集合中的数据拷贝到集群上去,形成一个分布式的数据集合,也就是一个RDD。
相当于集合中的一部分数据会到一个节点上,而另一部分数据会到其他节点上,然后就可以用并行的方式来操作这个分布式数据集合,即RDD。
案例:1 到10 累加求和
val arr = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val rdd = sc.parallelize(arr)
val sum = rdd.reduce(_ + _)
调用parallelize()时,有一个重要的参数可以指定,就是要将集合切分成多少个partition。
Spark会为每一个partition运行一个task来进行处理。
Spark默认会根据集群的情况来设置partition的数量,但是也可以在调用parallelize()方法时,传入第二个参数,来设置RDD的partition数量。比如parallelize(arr, 10)
第二种方式:、使用本地文件和HDFS创建RDD
Spark是支持使用任何Hadoop支持的存储系统上的文件创建RDD的,比如说HDFS、Cassandra、HBase以及本地文件。通过调用SparkContext的textFile()方法,可以针对本地文件或HDFS文件创建RDD。
注意:Spark的textFile()方法支持针对目录、压缩文件以及通配符进行RDD创建。
Spark默认会为hdfs文件的每一个block创建一个partition,但是也可以通过textFile()的第二个参
数手动设置分区数量,只能比block数量多,不能比block数量少 。
案例:文件字数统计
val rdd = sc.textFile("data.txt")
val wordCount = rdd.map(line => line.length).reduce(_ + _)
注:Spark的textFile()除了可以针对上述几种普通的文件创建RDD之外,
还有一些特列的方法来创建RDD:
1》SparkContext.wholeTextFiles()方法,可以针对一个目录中的大量小文件,
返回<filename, fileContent>组成的pair,作为一个PairRDD,而不是普通的RDD。
普通的textFile()返回的RDD中,每个元素就是文件中的一行文本。
2》SparkContext.sequenceFile[K, V]()方法,可以针对SequenceFile创建RDD,
K和V泛型类型就是SequenceFile的key和value的类型。K和V要求必须是
Hadoop的序列化类型,比如IntWritable、Text等。
3》SparkContext.hadoopRDD()方法,对于Hadoop的自定义输入类型,可以创建
RDD。该方法接收JobConf、InputFormatClass、Key和Value的Class。
4》SparkContext.objectFile()方法,可以针对之前调用RDD.saveAsObjectFile()
创建的对象序列化的文件,反序列化文件中的数据,并创建一个RDD。
十一、transformation和action介绍
Spark支持两种RDD操作:transformation和action。
transformation操作会针对已有的RDD创建一个新的RDD;
action则主要是对RDD进行最后的操作,比如遍历、reduce、保存到文件等,并可以返回结果给Driver程序。
例如:
map就是一种transformation操作,它用于将已有RDD的每个元素传入一个自定义的函数,并获取一个新的元素,然后将所有的新元素组成一个新的RDD。
reduce就是一种action操作,它用于对RDD中的所有元素进行聚合操作,并获取一个最终的结果,然后返回给Driver程序。
transformation的特点就是lazy特性。
lazy特性指的是,如果一个spark应用中只定义了transformation操作,transformation是不会触发Spark程序的执行的,它们只是记录了对RDD所做的操作,但是不会自发的执行。
只有当执行了一个action操作之后,所有的transformation才会执行。
Spark通过这种lazy特性来进行底层的Spark应用执行的优化,避免产生过多中间结果。
action操作执行,会触发一个spark job的运行,从而触发这个action之前所有的transformation的执行,这是action的特性。
案例:统计文件字数
1》这里通过textFile()方法,针对外部文件创建了一个RDD lines,但是实际上,程序执行到这里为止,spark.txt文件的数据是不会加载到内存中的。lines,只是代表了一个指向spark.txt文件的引用。
val lines = sc.textFile("spark.txt")
2》这里对lines RDD进行了map算子,获取了一个转换后的lineLengths RDD,但是这里连数据都没有,当然也不会做任何操作。lineLengths RDD也只是一个概念上的东西而已。
val lineLengths = lines.map(line => line.length)
3》之后,执行了一个action操作,reduce。此时就会触发之前所有transformation操作的执行,Spark会将操作拆分成多个task到多个机器上并行执行,每个task会在本地执行map操作,并且进行本地的reduce聚合。最后会进行一个全局的reduce聚合,然后将结果返回给Driver程序。
val totalLength = lineLengths.reduce(_ + _)
十二、常用算子介绍
1、
常用
transformation
类型的算子介绍

groupByKey:根据key分组,然后把分组后的value值放到一个集合当中
reduceByKey:首先根据key分组,然后对分组中的value值进行计算
join 分为 leftOuterJoin 和 rightOuterJoin
2、
常用action类型的算子介绍

collect:从集群中将所有的计算结果获取到本地内存,然后展示
take:从集群中将一部分的计算结果获取到本地内存,然后展示
补充:
1、map:一次处理一个分区中的一条记录
mapPartitions:一次处理一个分区中的所有数据
mapPartitionsWithIndex:一次处理一个分区中的所有数据,并返回分区中的索引,索引从0开始
2、mapValues运算
可以针对RDD内每一组(key,value)进行运算, 并且产生另外一个RDD。
例如: 将每一组( key,value) 的value进行平方运算
kvRDD1.mapValues(x => x*x).collect
3、union
union方法( 等价于“++”) 是将两个RDD取并集,
取并集的过程中不会把相同元素去掉
union操作是输入分区与输出分区多对一模式。
4、distinct:distinct方法是将RDD中重复的元素去掉, 只留下唯一的RDD元素。
5、intersection交集运算:intersection方法可以获取两个RDD中相同的数据
6、subtract差集运算
intRDD1.subtract(intRDD2).collect()
intRDD1是List(3,1,2,5,5), 扣除intRDD2 List(5,6)重复的部分5, 所以结果是(1,2,3)
7、aggregateByKey
reduceByKey认为是aggregateByKey的简化版
aggregateByKey最重要的一点是, 多提供了一个函数, Seq Function
可以控制如何对每个partition中的数据进行先聚合, 类似于mapreduce中的map-side-combine, 然后才是对所有partition中的数据进行全局聚合
aggregateByKey, 分为三个参数:
第一个参数是, 每个key的初始值
第二个是个函数, Seq Function, 如何进行shuffle map-side的本地聚合
第三个是个函数, Combiner Function, 如何进行shuffle reduce-side的全局聚合
8、cartesian
cartesian, 中文名笛卡尔乘积
比如说两个RDD, 分别有10条数据, 用了cartesian算子以后,两个RDD的每一条数据都会和另外一个RDD的每一条数据执行一次join,最终组成了一个笛卡尔乘积
9、coalesce
coalesce算子, 功能是将RDD的partition缩减, 将一定量的数据压缩到更少的partition中去。
建议的使用场景, 配合filter算子使用。使用filter算子过滤掉很多数据以后, 比如30%的数据, 出现了很多partition中的数据不均匀的情况,此时建议使用coalesce算子, 压缩rdd的partition数量, 从而让各个partition中的数据都更加的紧凑。
10、repartition
repartition算子, 用于任意将rdd的partition增多或者减少。与coalesce不同之处在于, coalesce仅仅能将rdd的partition变少, 但是repartition可以将rdd的partiton变多
一个很经典的场景, 使用Spark SQL从hive中查询数据时,Spark SQL会根据hive对应的hdfs文件的block数量来决定加载出来的数据rdd中有多少个partition, 这里的partition数量, 是我们根本无法设置的。有时候可能自动设置的partition数量过少, 导致我们后面的算子的运行特别慢;此时就可以在Spark SQL加载hive数据到rdd之后, 立即使用repartition算子,将rdd的partition数量变多。















 657
657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









