







 本文深入解析混淆矩阵在机器学习中的应用,阐述其衍生指标如准确率、召回率、F1分数等,帮助读者理解分类模型的性能评估。
本文深入解析混淆矩阵在机器学习中的应用,阐述其衍生指标如准确率、召回率、F1分数等,帮助读者理解分类模型的性能评估。
秒懂Confusion Matrix之混淆矩阵详解
Wiki:
在机器学习领域和统计分类问题中,混淆矩阵(英语:confusion matrix)是
可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。矩阵的
每一列代表一个类的实例预测,而每一行表示一个实际的类的实例。
之所以如此命名,是因为通过这个矩阵可以方便地看出机器是否将
两个不同的类混淆了(比如说把一个类错当成了另一个)。
混淆矩阵(也称误差矩阵[1])是一种特殊的, 具有两个维度的(实际和预测)列联表(英语:contingency table),并且两维度中都有着一样的类别的集合。
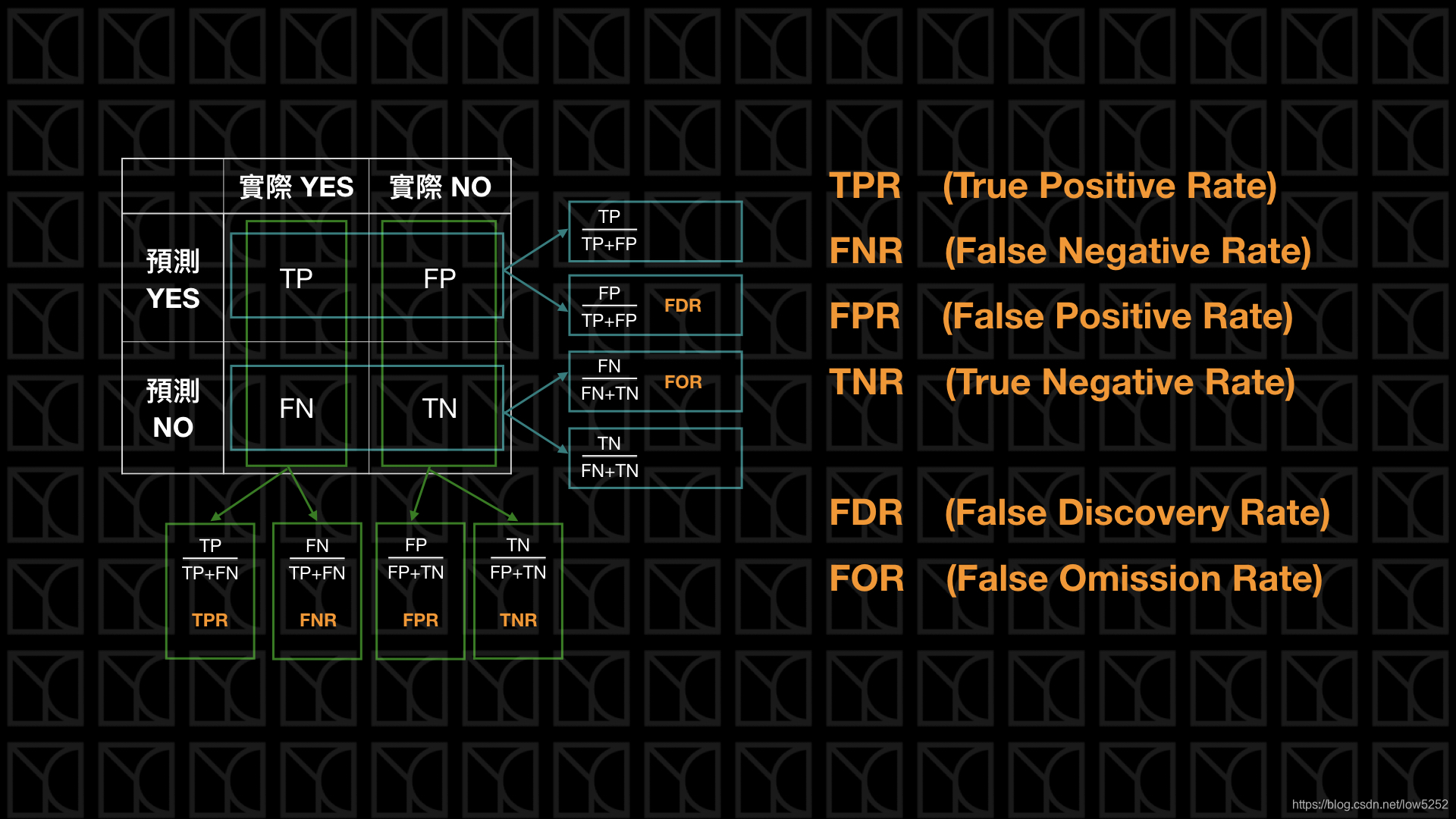
本篇介绍包含Confusion Matrix, True Positive, False Negative, False Positive, True Negative, Type I Error, Type II Error, Prevalence, Accuracy, Precision, Recall, F1 Measure, F Measure, Sensitivity, Specificity, ROC Curve, AUC, TPR, FNR, FPR, TNR, FDR, FOR, PPV, NPV, 算数平均, 几何平均, 调和平均。
有时要鉴别一个模型的好或坏,并不能简单的看出来,所以我们需要用一些指标去判定它的好坏,也作为我们挑选模型的依据。如果你稍微查一下有哪些指标,你就会发现指标多到让人家眼花撩乱,一堆名词就摊在那边,让人无从下手。
有一种分类问题常用的指标称之为Confusion Matrix,这个命名很有趣,这个表格的确是很让人感到很困惑啊!至少在看完这篇之前。 Confusion Matrix是用于分类问题的一种常用的指标,它衍生很多不同的指标,下面这张图我将Confusion Matrix画出来,并把一些比较重要的衍生指标给标出来。

我猜想,你一定看得很模糊吧!没关系我在这篇文章中会带大家认识这个图里的各个名词。
一开始我们从下面这个表格开始讲起,这个表格就是所谓的Confusion Matrix,前面的True和False代表预测本身的结果是正确还是不正确的,而后面的Positive和Negative则是代表预测的方向是正向还是负向的。

举iphone当例子,iphone具有指纹识别解锁系统,假如iphone判定这个指纹是属于使用者的,它就会解锁,所以今天如果你按压了,而iphone也顺利解锁了,那这种情形就属于左上角的情况,称为True Positive,也就是「正确的正向预测」,如果不幸的你按压iphone,结果iphone认不得你的指纹,这就是左下角的情况,称为False Negative,也就是「错误的负向预测」,接下来找你朋友一起来测试,正常情形下你朋友的指纹应该没办法让iphone解锁,这是右下角的情况,称为True Negative,也就是「正确的负向预测」,如果令人意外的是你的朋友把你的手机解锁了,那你最好改成用密码锁…,这种情况就是右上角的状况,称为False Positive,也就是「错误的正向预测」。
从上面的描述,我们当然希望我们的模型True Positive和True Negative都可以多多出现,而False Positive和False Negative可以尽量不要出现,因此这两种状况就称之为Error,又各自又命名为Type I Error和Type II Error,这两种错误,错的很不一样,如果今天指纹辨识不是放在iphone,而是放在你家大门锁上,那你最不希望发生哪类错误?当然是Type I Error,也就是False Positive,此时机器会把陌生人当成主人的开门,这是我们不想看到的,我们宁可被关在门外(Type II Error)!但如果今天这个辨别系统是用在Google广告,Google Ad会预测一个产品的潜在客户,并做广告投放,这个时候反而是较不希望Type II Error发生,也就是False Negative,这叫做宁可错杀一百个也不要放过一个潜在客户。所以下次在训练你的模型时想清楚你不想要Type I Error还是Type II Error (鳌拜:我全都要…),并且用一些方法来放掉另一种错误,来降低这个我们不希望发生的错误。
Confusion Matrix还有衍生很多形形色色的指标,我接下来就一一的介绍。
我们把所有正确的情况,也就是True Positive和True Negative,把它加总起来除上所有情形个数,那就是Accuracy,这也是最常用的指标,但是在某些情形下这个指标会失效,如果今天实际正向的例子很少,譬如有一个信用卡盗刷侦测机器人,看了一个月的信用卡纪录,其中真正是盗刷的资料笔数是相当少的,那我只要简单一步来设计我的模型就可以使它Accuracy达到99%以上,你猜到了吗?那就是通通预测没有盗刷的情况发生,所以显然我们需要别种指标来应对这种情况。
Precision(准确率)和Recall(召回率)这个时候就派上用场了,Precision和Recall同时关注的都是True Positive(都在分子),但是角度不一样,Precision看的是在预测正向的情形下,实际的「精准度」是多少,而Recall则是看在实际情形为正向的状况下,预测「能召回多少」实际正向的答案。一样的,如果是门禁系统,我们希望Precision可以很高,Recall就相较比较不重要,我们比较在意的是预测正向(开门)的答对多少,比较不在意实际正向(是主人)的答对多少。如果是广告投放,则Recall很重要,Precision就显得没这么重要了,因为此时我们比较在意的是实际正向(是潜在客户)的答对多少,而相对比较不在意预测正向(广告投出)答对多少。
Precision和Recall都不去考虑True Negative,因为通常True Negative会是答对的Null Hypothesis,简单讲就是最无聊的正确结果。在门禁的解锁问题就是陌生人按压且门不开;在广告投放的例子中就是广告不投,结果那个人也不是潜在客户:在信用卡盗刷的例子,机器人认为正常的刷卡纪录,其实也正是正常的。在通常的命题之下,实际是正向的结果是比负向少的,理所当然预测正向的结果也要比负向少,所以True Negative通常是量最多的,也是最无聊的。
补充:Null Hypothesis通常代表比较常见的情况,在统计上我们要验证某种概念成立,我们通常会假设一个最普通的Null Hypothesis当作正常情况,然后尝试着利用实验数据去否定这个Null Hypothesis,举例:你要证明一种药物是有效的,那你要先假设一个Null Hypothesis,譬如说给患者吃个安慰剂(可能是一颗糖果),你的药要有办法和Null Hypothesis产生显著的差异,你才能证明你的药是有效的。所以用在机器学习的例子当中,通常会把最普通的情况当作Negative,也就是当作Null Hypothesis来看待。
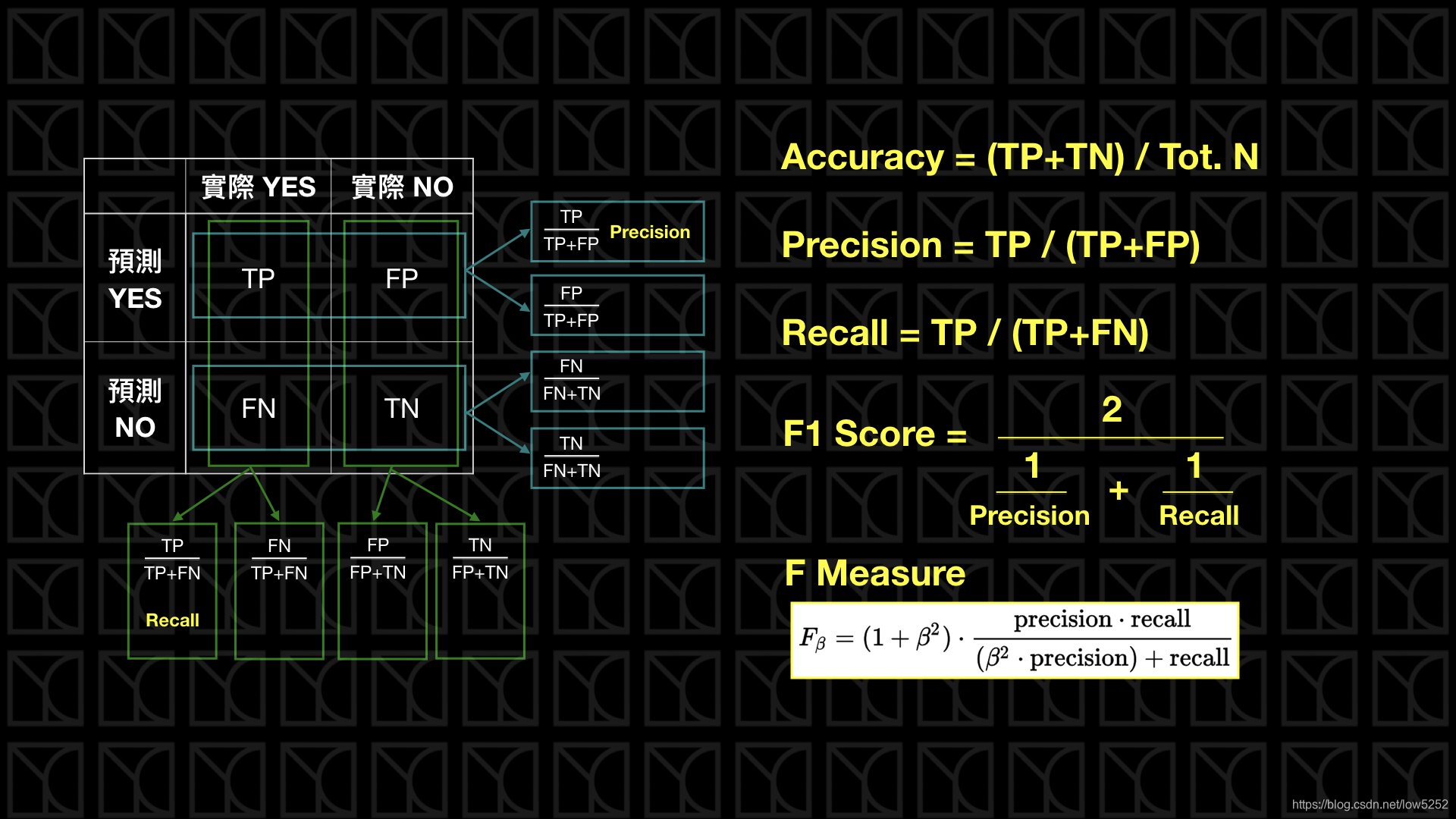
如果今天我觉得Precision和Recall都同等重要,我想要用一个指标来统合标志它,这就是F1 Score或称F1 Measure,它是F Measure的一个特例,当belta=1时就是F1 Measure,代表Precision和Recall都同等重要,那如果我希望多看中一点Precision,那belta就可以选择小一点,当belta=0时,F Measure就是Precision;如果我希望多看中一点Recall,那belta就可以选择大一点,当belta无限大时,F Measure就是Recall`。
如果你仔细看F1 Measure,你会发现它的平均方法是「调和平均」,带大家go-through三种平均方法,你就能明白为什么要使用调和平均了。下图列出了三种平均方法的使用时机,我们要去了解资料或数列的特性,我们才能知道要采取哪种平均方法较为恰当,大多情况算数平均都可以使用,因为我们都假设有线性关系存在,譬如说平均距离;几何平均常用于人口计算,因为人口增加是成比例增加的;调和平均常用于计算平均速率,在固定距离下,所花时间就是平均速率,这数据成倒数关系,而F1 Measure也同样是这样的数据特性,在固定TP的情况下,有不同的分母,所以这里使用调和平均较为适当。

下图的名词看一下有印象就好。
最后这页来讲一下医学上常用的指标,首先是Prevalence(盛行率),如果以人口当作所有的样本,实际得病的患者所占的比例就代表这个病的盛行情况。
如果今天有一个诊断方法可以判定病人是否有得此病,有两个指标可以看,那就是Sensitivity和Specificity,Sensitivity就是Recall,它代表的是诊断方法是否够灵敏可以将真正得病的人诊断出来,其实就是真正有病症的患者有多少可以被侦测出来,而Specificity则代表实际没病症的人有多少被检验正确的。两种指标都是越高越好。
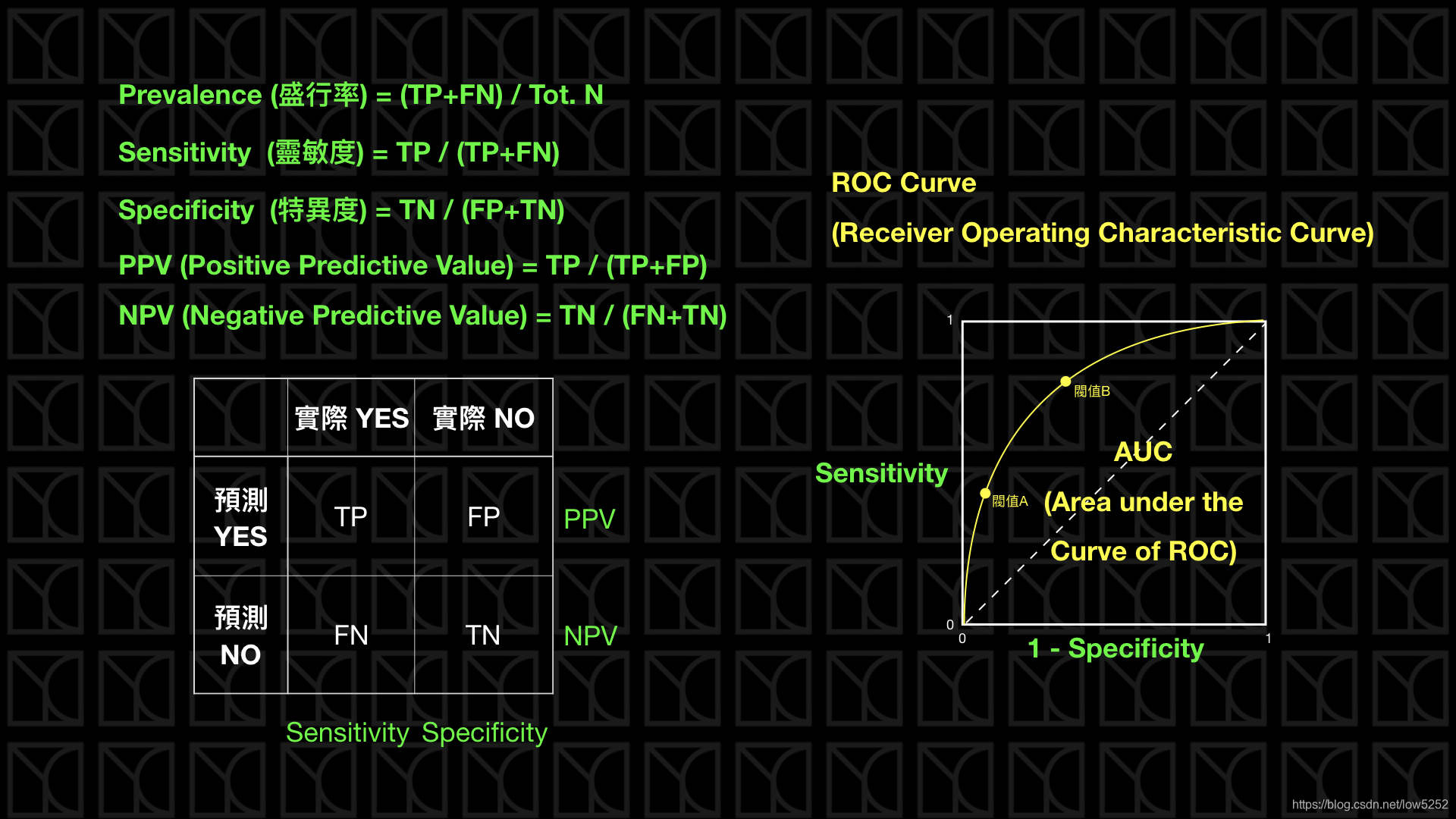
通常在医学上,会通过一些阀值来断定病人是否有得此病,而这个阀值就会影响Sensitivity和Specificity,这个不同阀值Sensitivity和Specificity的分布情况可以画成ROC Curve,而ROC Curve底下的面积称为AUC,AUC越大越好。
想必这个时候你再回去看第一张图就更加了解了,有了这些指标,我们就多一把尺来评断我们的分类模型究竟是做的好还是不好。
举例:
混淆矩阵是一个表,经常用来描述分类模型(或“分类器”)在已知真实值的一组测试数据上的性能。混淆矩阵本身比较容易理解,但是相关术语可能会令人混淆。
让我们从一个二进制分类器的混淆矩阵示例开始(尽管它可以很容易地扩展到两个以上的类):
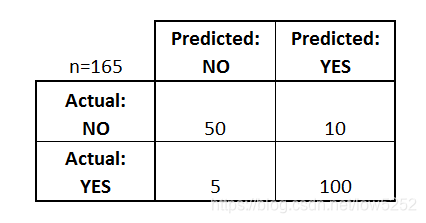
我们能从这个矩阵中了解到什么?
- 有两种可能的预测类:“yes”和“no”。例如,如果我们预测一种疾病的存在,“yes”意味着他们有这种疾病,“no”意味着他们没有这种疾病。
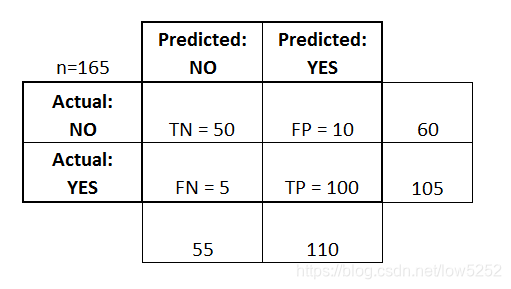
- 分类器总共做出165个预测(例如,165名患者正在接受该疾病存在的测试)。
- 在这165个病例中,分类器预测“yes”110次,“no”55次。
- 事实上,样本中有105名患者患有此病,60名患者没有患病。
现在让我们定义最基本的术语:
- true positives (TP): 在这些情况下,我们预测“yes”(他们有这种病),并且他们确实有这种病。
- true negatives (TN): 我们预测“no”,事实上他们确实没有患病。
- false positives (FP): 我们预测“yes”,但是他们实际上并没有患病。(也称为“第一类错误”。)
- false negatives (FN): 我们预测“no”,但他们确实有这种疾病。(也称为“第二类错误”。)
我已经将这些项添加到混淆矩阵中,并且添加了行和列总数:
这是一个比率的列表,通常是从一个混淆矩阵的二元分类器里得出:
- 准确率(Accuracy):总的来说,分类器的准确率是多少?
(TP+TN)/total = (100+50)/165 = 0.91
- 误分类率(Misclassification Rate):总的来说,错分类的频率是多少?
- (FP+FN)/total = (10+5)/165 = 0.09
- 等于1减去准确率
- 也被称为“错误率(Error Rate)”
- 真阳性率(True Positive Rate):当它实际上是“yes”时,它预测为“yes”的频率是多少?
TP/actual yes = 100/105 = 0.95
也被称为"Sensitivity"或"Recall"
- 假阳性率(False Positive Rate):当它实际上是“no”的时候,它预测为“yes”的频率是多少?
FP/actual no = 10/60 = 0.17
- 真阴性率(True Negative Rate):当它实际上是“no”时,它预测“no”的频率是多少?
- TN/actual no = 50/60 = 0.83
- 等于1减去假阳性率
- 也被称为"特异性(Specificity)"
- 精度(Precision):当它预测“yes”类时,正确预测的概率是多少?
TP/predicted yes = 100/110 = 0.91
- Prevalence:在我们的样本中,“yes”条件实际发生的频率是多少?
actual yes/total = 105/165 = 0.64
还有几个术语也值得一提:
- 零错误率(Null Error Rate): 这是如果你总是预测大多数类,你就会错的频率。(在我们的例子中,零错误率将是60/165=0.36,因为如果你总是预测yes,那么您只会在60个“no”的情况下出错。)这可以作为比较分类器的基准度量。然而,对于一个特定的应用程序,最好的分类器有时会有比零错误率更高的错误率,正如 “Accuracy Paradox(精确度悖论)”所证明的那样。
- Cohen’s Kappa: 这本质上是对分类器的性能的一种度量,与它仅仅是偶然的性能进行比较。换句话说,如果模型的准确率和零错误率之间有很大的差异,那么模型的Kappa分数就会很高。
- F Score:这是真实阳性率(召回率)和正确率的加权平均值。
- ROC曲线:这是一个常用的图表,它总结了分类器在所有可能阈值上的性能。当你改变将观察值分配给给定类的阈值时,通过绘制真阳性率(y轴)与假阳性率(x轴)来生成它。

















 2172
2172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









