







文章:
https://arxiv.org/abs/2402.13616
训练和推理教程:
How to Train YOLOv9 on a Custom Dataset
继承YOLOv7的代码风格
使用可编程梯度信息
0. 摘要:
1.当下研究关注设计最合适的目标函数。
2.问题:特征提取过程会丢失大量信息。
3.提出可编程梯度信息(PGI),可以提供完整的输入信息。
4.设计了一种基于梯度路径规划的轻量级网络结构-GELAN
5.结果:GELAN有更好的参数利用率,PGI可以获取完整信息。
1. 介绍:
COCO数据集上的表现(图片来自原文),在小体量模型中表现最佳
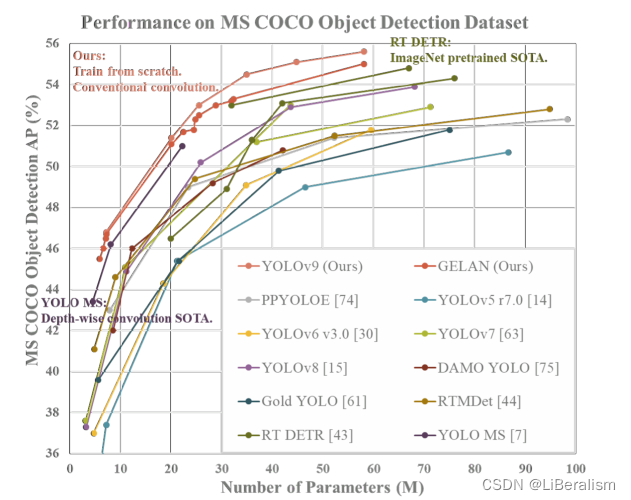
已有的工作:
1. 目标函数层面的创新(损失函数,标签分配,辅助监督)
2. 缓解前馈过程数据丢失问题:
(1)可逆架构:利用重复输入;
(2)掩模建模:重构损失最大化提取特征。
(3)深度监督:预先建立浅层特征到目标层的映射。
本文工作:
3. 提出概念:可编程梯度信息(PGI)
思想:通过辅助可逆分支生成可靠的梯度,使深层特征仍能保持关键特征以执行目标任务
4. 改进网络结构:GELAN
使用常规的卷积达到了更高的效率。
2. 相关工作:
1. 实时检测器:
DETR系列目标检测器缺少其他领域的预训练模型,难以迁移到其他领域。因此目前应用最广的实时目标检测器仍然以YOLO为主。
2.可逆架构:
思想:由于前向传播存在非线性层,反向传播无法还原输入数据,因此提出可逆架构。
常见的可逆架构操作:逆卷积、逆池化、逆正则化。
本文工作:设计了可逆分支,在PGI中引入可逆信息。
3. 辅助监督:
思想:神经网络的训练是通过最终输出与标签之间的误差来进行的,这被称为主要监督信号。辅助监督就是在中间层添加额外输出用来反馈误差,可以对输入数据有更好的理解。
其他工作只能用在大模型上,PGI可以将辅助监督用在轻量化模型(YOLO)上。
3. 问题陈述:
神经网络存在收敛慢的问题,深度网络会丢失信息。
通过可视化,网络保留重要信息的比例和准确率正相关。

1. 信息瓶颈原理(Information Bottleneck Principle):
思路:在学习过程中保留对于输出的关键信息,同时最大限度地减少输入数据中不相关或冗余的信息。通过优化目标函数来实现这一目标。这个目标函数通常表示为最小化输入和输出之间的互信息。
(1)数据丢失:每层神经网络会造成信息损失
(2)宽度比深度重要:
更宽的神经网络层能够用更丰富的参数降低前馈过程中的损失。
2. 可逆功能:
映射变换不改变互信息。
根据信息瓶颈原理有以下公式:
X是数据,Y是目标,关键在于如何从I(X,X)中最大程度地提取I(X,Y)
4. 方法:
1. 可编程梯度信息(PGI):

(a)PAN:路径聚合;
(b)RevCol:可逆列;
(c)Deep Supervision:传统深度监督;
在中间层把输出引出来和真值作比较得到反向传播梯度,然后和主分支的反向传播梯度联合更新网络参数。
(d)PGI:主分支(正向推理);辅助可逆分支(生成可靠梯度);多级辅助信息(辅助主分支学习多级语义信息)
辅助可逆分支和多级辅助信息不参与推理过程
辅助可逆分支:解决网络加深带来的梯度不可靠问题;
多级辅助信息:解决误差累计带来的问题。
(1)辅助可逆分支:(d图中深蓝色框)
思路:引入可逆体系来提高网络对于输入的信息提取能力,但是可逆体系在推理过程中会产生较大的资源消耗,因此可逆体系仅在训练阶段用于生成可靠的梯度信息,不参与推理。
不要求主分支能够提取到良好的信息,靠辅助分支来提取可靠信息来驱动参数学习,这样做可以应用在浅层网络。
(2)多级辅助信息:(d图中紫色框)
思路:在特征金字塔层插入集成网络,组合不同预测头(黑色框)的返回梯度,传递给主分支然后更新参数。
有点类似于传统深度监督的方式,多了一个聚合梯度的操作。
2. GELAN:
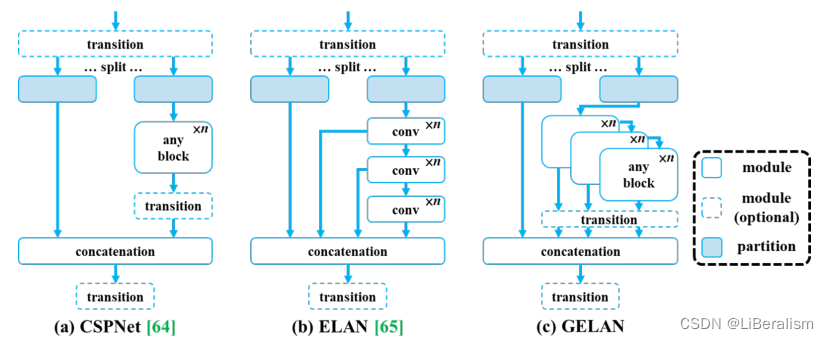
新网络架构,结合了CSPNet和ELAN,可以看做是ELAN的推广。
(网络的改进就是它只要能提点就不要问为啥)
5. 实验:
看原文 5. Experiments 部分。















 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









