






1 ElasticSearch介绍
1.1、介绍
Elasticsearch 是一个非常强大的搜索引擎。它目前被广泛地使用于各个 IT 公司。Elasticsearch 是由 Elastic 公司创建。它的代码位于 GitHub - elastic/elasticsearch: Free and Open, Distributed, RESTful Search Engine。Elasticsearch 是一个分布式、免费和开放的搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。 Elasticsearch 基于 Apache Lucene 构建,并于 2010 年由 Elasticsearch N.V. 首次发布(现在称为 Elastic)。Elasticsearch 以其简单的 REST API、分布式特性、速度和可扩展性而闻名,是 Elastic Stack 的核心组件,Elastic Stack 是一组用于数据摄取、丰富、存储、分析和可视化的免费开放工具。 通常被称为 ELK Stack。Elastic 公司也同时拥有 Logstash 及 Kibana 开源项目。这个三个项目组合在一起,就形成了 ELK 软件栈。他们三个共同形成了一个强大的生态圈。简单地说,Logstash 负责数据的采集,处理(丰富数据,数据转换等),Kibana 负责数据展示,分析,管理,监督,警报及方案。Elasticsearch 处于最核心的位置,它可以帮我们对数据进行存储,并快速地搜索及分析数据
官方网址:https://www.elastic.co/cn/products/elasticsearch
Github:https://github.com/elastic/elasticsearch
总结:
1、elasticsearch是一个基于Lucene的高扩展的分布式搜索服务器,支持开箱即用。
2、elasticsearch隐藏了Lucene的复杂性,对外提供Restful 接口来操作索引、搜索。
突出优点:
1.扩展性好,可部署上百台服务器集群,处理PB级数据。
2.近实时的去索引数据、搜索数据。
2 原理与应用
2.1索引结构
下图是ElasticSearch的索引结构,下边黑色部分是物理结构,上边黄色部分是逻辑结构,逻辑结构也是为了更好的去描述ElasticSearch的工作原理及去使用物理结构中的索引文件。

逻辑结构部分是一个倒排索引表:
1、将要搜索的文档内容分词,所有不重复的词组成分词列表。
2、将搜索的文档最终以Document方式存储起来。
3、每个词和docment都有关联。
如下:
现在,如果我们想搜索quick brown ,我们只需要查找包含每个词条的文档:

两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单相似性算法,那么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
3 ES对外接口(开发人员关注)
1)JAVA API接口
http://www.ibm.com/developerworks/library/j-use-elasticsearch-java-apps/index.html
2)RESTful API接口
常见的增、删、改、查操作实现:
http://blog.csdn.net/laoyang360/article/details/51931981
4 ES遇到问题怎么办?
1)国外:https://discuss.elastic.co/
5 映射
5.1 映射维护方法
1、查询所有索引的映射:
GET:http://localhost:9200/_mapping
2、创建映射
post 请求:http://localhost:9200/xc_course/doc/_mapping
一个例子:
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text"
},
"studymodel": {
"type": "keyword"
}
}
}3、更新映射
映射创建成功可以添加新字段,已有字段不允许更新。
4、删除映射
通过删除索引来删除映射。
5.2 常用映射类型
5.2.1 text文本字段
下图是ES6.2核心的字段类型如下:
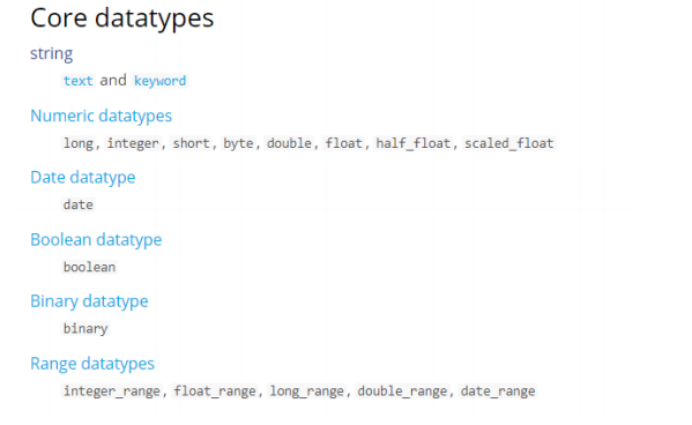
字符串包括text和keyword两种类型:
1、text
1)analyzer
通过analyzer属性指定分词器。
下边指定name的字段类型为text,使用ik分词器的ik_max_word分词模式。
"name": {
"type": "text",
"analyzer": "ik_max_word"
}上边指定了analyzer是指在索引和搜索都使用ik_max_word,如果单独想定义搜索时使用的分词器则可以通过search_analyzer属性。
对于ik分词器建议是索引时使用ik_max_word将搜索内容进行细粒度分词,搜索时使用ik_smart提高搜索精确性。
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}2)index
通过index属性指定是否索引。
默认为index=true,即要进行索引,只有进行索引才可以从索引库搜索到。
但是也有一些内容不需要索引,比如:商品图片地址只被用来展示图片,不进行搜索图片,此时可以将index设置为false。
删除索引,重新创建映射,将pic的index设置为false,尝试根据pic去搜索,结果搜索不到数据
"pic": {
"type": "text",
"index":false
} 5.2.2 keyword关键字字段
上边介绍的text文本字段在映射时要设置分词器,keyword字段为关键字字段,通常搜索keyword是按照整体搜索,所以创建keyword字段的索引时是不进行分词的,比如:邮政编码、手机号码、身份证等。keyword字段通常用于过虑、排序、聚合等。
5.2.2.1测试
更改映射:
{
"properties": {
"studymodel": {
"type": "keyword"
},
"name": {
"type": "keyword"
}
}
}插入文档:
{
"name": "java编程基础",
"description": "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"pic":"group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg",
"studymodel": "201001"
}
根据studymodel查询文档
搜索:http://localhost:9200/xc_course/_search?q=name:java
name是keyword类型,所以查询方式是精确查询。
5.2.3 date日期类型
日期类型不用设置分词器。
通常日期类型的字段用于排序。
1)format
通过format设置日期格式
例子:
下边的设置允许date字段存储年月日时分秒、年月日及毫秒三种格式。
{
"properties": {
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"
}
}
}插入文档:
Post :http://localhost:9200/xc_course/doc/3
{
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"pic":"group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg",
"timestamp":"2018‐07‐04 18:28:58"
} 6 数值类型
下边是ES支持的数值类型

1、尽量选择范围小的类型,提高搜索效率
2、对于浮点数尽量用比例因子,比如一个价格字段,单位为元,我们将比例因子设置为100这在ES中会按分存储,映射如下:
"price": {
"type": "scaled_float",
"scaling_factor": 100
}由于比例因子为100,如果我们输入的价格是23.45则ES中会将23.45乘以100存储在ES中。
如果输入的价格是23.456,ES会将23.456乘以100再取一个接近原始值的数,得出2346。
使用比例因子的好处是整型比浮点型更易压缩,节省磁盘空间。
如果比例因子不适合,则从下表选择范围小的去用:

7 环境搭建(创建搜索工程)
1.搜索工程pom.xml
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.2.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.2.1</version>
</dependency>2.配置文件
es:
host: 127.0.0.1:9200
server:
port: 1400
3.配置类
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticsearchConfig {
@Value("${xc.elasticsearch.hostlist}")
private String hostlist;
@Bean
public RestHighLevelClient restHighLevelClient() {
//解析hostlist配置信息
String[] split = hostlist.split(",");
//创建HttpHost数组,其中存放es主机和端口的配置信息
HttpHost[] httpHostArray = new HttpHost[split.length];
for (int i = 0; i < split.length; i++) {
String item = split[i];
httpHostArray[i] = new HttpHost(item.split(":")[0], Integer.parseInt(item.split(":")[1]), "http");
}
//创建RestHighLevelClient客户端
return new RestHighLevelClient(RestClient.builder(httpHostArray));
}
//项目主要使用RestHighLevelClient,对于低级的客户端暂时不用
@Bean
public RestClient restClient() {
//解析hostlist配置信息
String[] split = hostlist.split(",");
//创建HttpHost数组,其中存放es主机和端口的配置信息
HttpHost[] httpHostArray = new HttpHost[split.length];
for (int i = 0; i < split.length; i++) {
String item = split[i];
httpHostArray[i] = new HttpHost(item.split(":")[0], Integer.parseInt(item.split(":")[1]), "http");
}
return RestClient.builder(httpHostArray).build();
}
}4 商品搜索创建映射
4.1使用请求发送创建索引库
{
"properties": {
"sn": {
"type": "text"
},
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"price": {
"type": "float"
},
"num": {
"type": "integer"
},
"alert_num": {
"type": "integer"
},
"image": {
"type": "text"
},
"images": {
"type": "text"
},
"weight": {
"type": "integer"
},
"create_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"
},
"update_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"
},
"spu_id": {
"type": "text"
},
"category_id": {
"type": "integer"
},
"category_name": {
"type": "keyword"
},
"brand_name": {
"type": "keyword"
},
"spec": {
"type": "keyword"
},
"sale_num": {
"type": "integer"
},
"comment_num": {
"type": "integer"
},
"status": {
"type": "keyword"
},
"version": {
"type": "integer"
},
"specMap":{
"properties":{
"test":{
"type": "keyword"
}
}
}
}
}4.2使用代码创建索引库
public void createIndex() throws Exception {
CreateIndexRequest request = new CreateIndexRequest("tb_sku", Settings.builder().put("number_of_shards", "1").put("number_of_replicas", "0").build());
request.mapping("doc", "{\n" +
"\t\"properties\": {\n" +
"\t\t\"sn\": {\n" +
"\t\t\t\"type\": \"text\"\n" +
"\t\t},\n" +
"\t\t\"name\": {\n" +
"\t\t\t\"type\": \"text\",\n" +
"\t\t\t\"analyzer\": \"ik_max_word\",\n" +
"\t\t\t\"search_analyzer\": \"ik_smart\"\n" +
"\t\t},\n" +
"\t\t\"price\": {\n" +
"\t\t\t\"type\": \"float\"\n" +
"\t\t},\n" +
"\t\t\"num\": {\n" +
"\t\t\t\"type\": \"integer\"\n" +
"\t\t},\n" +
"\t\t\"alert_num\": {\n" +
"\t\t\t\"type\": \"integer\"\n" +
"\t\t},\n" +
"\t\t\"image\": {\n" +
"\t\t\t\"type\": \"text\"\n" +
"\t\t},\n" +
"\t\t\"images\": {\n" +
"\t\t\t\"type\": \"text\"\n" +
"\t\t},\n" +
"\t\t\"weight\": {\n" +
"\t\t\t\"type\": \"integer\"\n" +
"\t\t},\n" +
"\t\t\"create_time\": {\n" +
"\t\t\t\"type\": \"date\",\n" +
"\t\t\t\"format\": \"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd\"\n" +
"\t\t},\n" +
"\t\t\"update_time\": {\n" +
"\t\t\t\"type\": \"date\",\n" +
"\t\t\t\"format\": \"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd\"\n" +
"\t\t},\n" +
"\t\t\"spu_id\": {\n" +
"\t\t\t\"type\": \"text\"\n" +
"\t\t},\n" +
"\t\t\"category_id\": {\n" +
"\t\t\t\"type\": \"integer\"\n" +
"\t\t},\n" +
"\t\t\"category_name\": {\n" +
"\t\t\t\"type\": \"keyword\"\n" +
"\t\t},\n" +
"\t\t\"brand_name\": {\n" +
"\t\t\t\"type\": \"keyword\"\n" +
"\t\t},\n" +
"\t\t\"spec\": {\n" +
"\t\t\t\"type\": \"keyword\"\n" +
"\t\t},\n" +
"\t\t\"sale_num\": {\n" +
"\t\t\t\"type\": \"integer\"\n" +
"\t\t},\n" +
"\t\t\"comment_num\": {\n" +
"\t\t\t\"type\": \"integer\"\n" +
"\t\t},\n" +
"\t\t\"status\": {\n" +
"\t\t\t\"type\": \"keyword\"\n" +
"\t\t},\n" +
"\t\t\"version\": {\n" +
"\t\t\t\"type\": \"integer\"\n" +
"\t\t},\n" +
"\t\t\"specMap\":{\n" +
"\t\t\t\"properties\":{\n" +
"\t\t\t\t\"颜色\":{\n" +
"\t\t\t\t\t\"type\": \"keyword\"\n" +
"\t\t\t\t},\n" +
"\t\t\t\t\"版本\":{\n" +
"\t\t\t\t\t\"type\": \"keyword\"\n" +
"\t\t\t\t},\n" +
"\t\t\t\t\"尺码\":{\n" +
"\t\t\t\t\t\"type\": \"keyword\"\n" +
"\t\t\t\t},\n" +
"\t\t\t\t\"内存\":{\n" +
"\t\t\t\t\t\"type\": \"keyword\"\n" +
"\t\t\t\t}\n" +
"\t\t\t}\n" +
"\t\t}\n" +
"\t}\n" +
"}", XContentType.JSON);
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
}4.3从数据库批量存入索引库中
@Override
public void importData() throws Exception {
Class.forName("com.mysql.jdbc.Driver");
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/shop_goods?useSSL=false&useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8", "root", "abc123");
PreparedStatement pstm = connection.prepareStatement("select * from tb_sku");
ResultSet rs = pstm.executeQuery();
while (rs.next()) {
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("sn", rs.getString("sn"));
jsonMap.put("name", rs.getString("name"));
jsonMap.put("price", rs.getFloat("price"));
jsonMap.put("num", rs.getInt("num"));
jsonMap.put("alert_num", rs.getInt("alert_num"));
jsonMap.put("image", rs.getString("image"));
jsonMap.put("images", rs.getString("images"));
jsonMap.put("weight", rs.getInt("weight"));
jsonMap.put("spu_id", rs.getString("spu_id"));
jsonMap.put("category_id", rs.getInt("category_id"));
jsonMap.put("category_name", rs.getString("category_name"));
jsonMap.put("brand_name", rs.getString("brand_name"));
jsonMap.put("create_time", rs.getDate("create_time").toString());
jsonMap.put("update_time", rs.getDate("update_time").toString());
jsonMap.put("spec", rs.getString("spec"));
jsonMap.put("sale_num", rs.getInt("sale_num"));
jsonMap.put("comment_num", rs.getInt("comment_num"));
jsonMap.put("status", rs.getString("status"));
jsonMap.put("version", rs.getInt("version"));
Map specMap = JSON.parseObject(rs.getString("spec"), Map.class);
jsonMap.put("specMap", specMap);
IndexRequest indexRequest = new IndexRequest("tb_sku", "doc", rs.getString("id"));
indexRequest.source(jsonMap);
IndexResponse response = client.index(indexRequest, RequestOptions.DEFAULT);
System.out.println(response);
}
}4.4 使用javaApi方式组合查询
@Override
public Map<String, Object> search(Map<String, String> param) throws Exception {
Map<String, Object> searchMap = new HashMap<>();
SearchRequest searchRequest = new SearchRequest("tb_sku");
searchRequest.types("doc");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
String keyword = param.get("keyword");
if (StringUtils.isEmpty(keyword)) {
keyword = "华为";
}
searchSourceBuilder.aggregation(AggregationBuilders.terms("cateGroup").field("category_name")).size(50);
searchSourceBuilder.aggregation(AggregationBuilders.terms("brandGroup").field("brand_name")).size(50);
searchSourceBuilder.aggregation(AggregationBuilders.terms("specGroup").field("spec")).size(50);
MultiMatchQueryBuilder name = QueryBuilders.multiMatchQuery(keyword, "name");
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(name);
for (String key : param.keySet()) {
if (key.startsWith("spec_")) {
boolQueryBuilder.filter(QueryBuilders.termQuery("specMap." + key.substring(5) + ".keyword", param.get(key)));
}
}
//设置高亮对象
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<div style='color:red;'>");
highlightBuilder.postTags("</div>");
highlightBuilder.fields().add(new HighlightBuilder.Field("name"));
searchSourceBuilder.highlighter(highlightBuilder);
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse search = client.search(searchRequest);
Terms cateTerms = search.getAggregations().get("cateGroup");
List<String> cateGroup = termsLIst(cateTerms);
Terms brandTerms = search.getAggregations().get("brandGroup");
List<String> brandGroup = termsLIst(brandTerms);
Terms specTerms = search.getAggregations().get("specGroup");
Map<String, Set<String>> specMap = termsMap(specTerms);
SearchHits searchHits = search.getHits();
SearchHit[] hits = searchHits.getHits();
List<TbSkuEntity> list = new ArrayList<>();
for (SearchHit hit : hits) {
String id = hit.getId();
Map<String, Object> data = hit.getSourceAsMap();
data.put("id", id);
String json = JSON.toJSONString(data);
TbSkuEntity tbSkuModel = JSON.parseObject(json, TbSkuEntity.class);
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
StringBuffer nameBuf = new StringBuffer();
if (highlightFields != null) {
HighlightField names = highlightFields.get("name");
if (names != null) {
Text[] fragments = names.getFragments();
for (Text fragment : fragments) {
nameBuf.append(fragment.toString());
}
tbSkuModel.setName(nameBuf.toString());
}
}
list.add(tbSkuModel);
}
searchMap.put("data", list);
searchMap.put("cateList", cateGroup);
searchMap.put("brandList", brandGroup);
searchMap.put("specMap", specMap);
return searchMap;
}
private List<String> termsLIst(Terms terms) {
List<String> list = new ArrayList<>();
for (Terms.Bucket bucket : terms.getBuckets()) {
list.add(bucket.getKeyAsString());
}
return list;
}
private Map<String, Set<String>> termsMap(Terms terms) {
Map<String, Set<String>> specMap = new HashMap<>();
List<Map<String, String>> list = new ArrayList<>();
for (Terms.Bucket bucket : terms.getBuckets()) {
String keyAsString = bucket.getKeyAsString();
Map map = JSON.parseObject(keyAsString, Map.class);
list.add(map);
}
for (Map<String, String> map : list) {
for (String key : map.keySet()) {
String value = map.get(key);
Set<String> strings = specMap.get(key);
if (ObjectUtils.isEmpty(strings)) {
strings = new HashSet<>();
}
strings.add(value);
specMap.put(key, strings);
}
}
return specMap;
}8 启动ES
进入bin目录,在cmd下运行:elasticsearch.bat
浏览器输入:http://localhost:9200
显示结果如下(配置不同内容则不同)说明ES启动成功:
9 运行效果图


















 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









