







书接上回,上一次我们提到函数调用是嵌套在一句语句中性能好还是分成几条调用性能好,在那篇文章中测试代码使用的是String的拼接操作,因为它一个耗时操作。不过在用javap反编译之后,我发现即便是对String使用+拼接,javac也会将其优化,或者说是java里对String的‘+’运算进行了重载,编译成StringBuilder的append方法。这里我就有疑问了。
错误认识
在不知道上述常识之前,我有以下错误认识:
对字符串
String和整型int调用+进行拼接,形如"result is "+i;在执行时会首先对int类型的i进行自动装箱,变成Integer,然后调用Integer的toString方法,得到一个字符串再与前面的String拼接在一起,拼接使用String对‘+’的重载。
实际情况
然而如果javac将字符串拼接优化了的话,上面的认识是完全错误的,因为StringBuilder的append方法有参数为int类型的重载形式,也就是说在编译后会使用如下形式的代码:
StringBuilder sb=new StringBuilder();
sb.append("result is ").append(i).toString();//i 是一个定义过的int型变量实际操作一下,也的确证实,我以前的想法是错的,如下图:
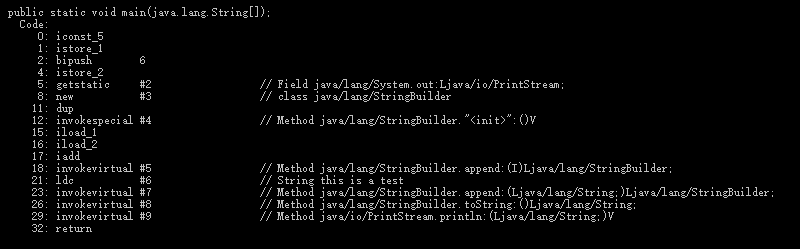
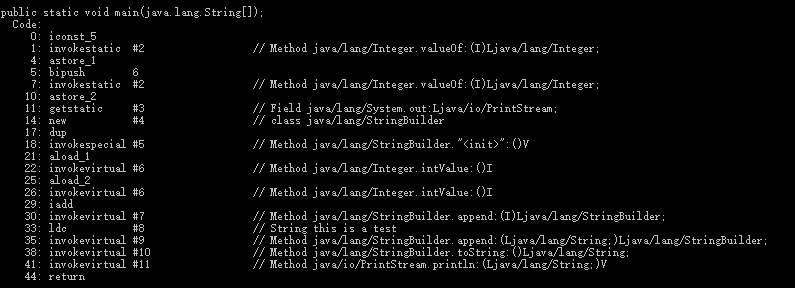
上面,是int和String拼接,下面,是Integer与String拼接的中间代码,从中我们看到Integer与String拼接反而多用了一步intValue转换成int,这就与我们想的调用int装箱和Integer调用toString完全不同了。
那么,在append中是如何将int拼接到String上的呢?是否与上面出现的我的错误想法相差无几?(当然不会了,相差无几那不是效率依旧很低,那还用StringBuilder作甚)
源码解释
接下来我们就通过看源码,了解一下append(int)方法的实现。
值得庆幸,我在我的电脑里找到了在java安装目录下的源码,找到了lang包下的StringBuilder类。结果,发现StringBuilder继承自父类 AbstractStringBuilder,虽然父类写着Abstract,但是一点也不虚,其实大部分方法都是在父类中实现的。
1. StringBuilder的append(int)方法
下面是StringBuilder类的append(int)的实现,就调用了父类:
@Override
public StringBuilder append(int i) {
super.append(i);
return this;
}
所以接下来,我们重点研究AbstractStringBuilder,以下是AbstractStringBuilder的append(int)的源码,我将解释以注释形式和代码写在了一起
2. AbstractStringBuilder的append(int)方法
public AbstractStringBuilder append(int i) {
/* 这里对i==int能表示的无穷小做了特殊处理,
* 因为后面正常处理的核心方法getChars对int的无穷小没用
*/
if (i == Integer.MIN_VALUE) {
append("-2147483648");
return this;
}
//这里处理了负号问题,因为负号在转化成字符串会比int形式的时候多占一位
int appendedLength = (i < 0) ? Integer.stringSize(-i) + 1: Integer.stringSize(i);
int spaceNeeded = count + appendedLength;
/* 这个函数顾名思义,保证StringBuilder维持的缓存足够大
* 不够的话需要扩容,扩容的规则是扩容成以前的两倍+2
* 如果缓存还不够的话,就将其设置为spaceNeeded的大小
*/
ensureCapacityInternal(spaceNeeded);
//核心方法,在这一步int转化到了缓存value中,这里需要注意的是传参spaceNeeded是将int也计算进去的最终大小
Integer.getChars(i, spaceNeeded, value);
//将缓存当前位置更新
count = spaceNeeded;
return this;
}
如上,我们可以看出,StringBuilder的append(int)方法最终通过调用Integer的getChars方法将int转化进StringBuilder的buff里,那么getChars是怎么实现的呢?
3. Integer的getChars方法
以下是Integer的getChars的注释以及方法,个人写的解释也夹杂在其中
/**
* Places characters representing the integer i into the
* character array buf. The characters are placed into
* the buffer backwards starting with the least significant
* digit at the specified index (exclusive), and working
* backwards from there.
* 这里,方法文档说明了该方法在i==int能表示的最小值时会失败,这就应和了append(int)为何要特殊处理i==int能表示的最小值
* 至于为何失败,我没有完全理解,猜测是下面使用位运算的原因
* Will fail if i == Integer.MIN_VALUE
*/
static void getChars(int i, int index, char[] buf) {
int q, r;//r代表的int的某一位,q只是一个中间变量
int charPos = index;
char sign = 0;
//将int全部转化成正数,符号单独处理
if (i < 0) {
sign = '-';
i = -i;
}
/* 接下来这段比较有意思,在转化正数处理后i>65536才会运行
* 下面这一段的主要意图是当i太大的时候将对i一位一位取出,放入char[]buf的操作变为对i的两位两位的操作,优化加速
* 通过位运算,可以比求余数更快地得到i未处理的后两位数字r
* 然后通过 DigitTens[r],得到r的十位,通过DigitOnes[r]找到r的个位,分别加到buf里
* DigitTens、DigitOnes是Integer的静态成员,
* 其中DigitTens是一个10*10的矩阵,每一行存10个一样的数字,也就是说一个两位数做索引,只要十位一样,得到的结果是一样的
* DigitOnes也是类似,只不过是每一列存10个一样的数字,也就是一个两位数做索引,只要个位一样,得到的结果就是一样的
* 这里就体现了算法当中一个时空权衡的思想,通过空间(花更多内存)换时间(得到更快的运行速度)
*/
// Generate two digits per iteration
while (i >= 65536) {
q = i / 100;
// really: r = i - (q * 100);
r = i - ((q << 6) + (q << 5) + (q << 2));
i = q;
buf [--charPos] = DigitOnes[r];
buf [--charPos] = DigitTens[r];
}
// 下面这段一定会执行,代码思路是取得i的每一位,然后将其加入buf中,位运算加快速度
// Fall thru to fast mode for smaller numbers
// assert(i <= 65536, i);
for (;;) {
q = (i * 52429) >>> (16+3);
r = i - ((q << 3) + (q << 1)); // r = i-(q*10) ...
buf [--charPos] = digits [r];
i = q;
if (i == 0) break;
}
//这里我们看到,当符号位为'-'时,会在buf的中间把‘-’插进去
//因为charPos一直自减,也就是说buf是从尾部填充到中间甚至开头位置的
if (sign != 0) {
buf [--charPos] = sign;
}
}
至此,我们就看到了StringBuilder对于append(int)实现的全貌了,还是比较费工夫的,不过受益颇多。
总结来说:
StringBuilder通过父类AbstractStringBuilder调用父类的append(int),实现将int变成char数组加入缓存,而AbstractStringBuilder的append(int)则通过调用Integer的静态方法getChars,将一个int按位取出,一个一个塞入char的数组中,当然这中间省略了一些性能上的优化和细节处理。
最后,不得不说,源码的书写风格真的好,注释也好,代码风格也好,变量命名也好,舒服!
而且源码里面体现了很多的思想,跟着思考的话一定大有裨益。
以前觉得看Java源码是多么难的一件事情,经此,我觉得源码还是能读的,除了为了性能优化过的算法,其他部分还是很容易理解的
。















 271
271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









