









论文题目:Graph Convolutional Networks with Argument-Aware Pooling for Event Detection
论文出处:AAAI 2018
论文地址:https://ix.cs.uoregon.edu/~thien/pubs/graphConv.pdf
论文概要
该论文提出一个基于句法依存树的图卷积(Graph Convolutional Networks,GCN)神经网络模型用于事件检测。在神经网络中引入句法结构特征,在句法依存图上执行卷积操作。在做事件检测,关系抽取等任务时,一般都是讲序列根据词嵌入等方法转为连续的向量,没有使用句子的结构信息。这篇文章提供了做此类任务时的另一种思路,并在公开数据集上取得了不错的结果。
论文pipeline
整个论文的pipeline很值得借鉴,这里从原始输入到输出详细梳理一下。
首先,事件检测任务可以表述为一种序列标注任务。
以下面这个贯穿全文的例子来讲。

我们的输入是一段文本序列及其语法结构(句法依存树),以及其命名实体识别结果。
我们的输出目标是识别序列中对应各种事件的触发点(event trigger)。
以上面的例子来讲,第一个fired 对应为事件类型 attack 的 trigger , 第二个fired 对应为时间类型 End-Position 的 trigger。
其他的单词(token)位置输出可以设定为“others”。
下面按照from bottom to top的方式梳理一下整个任务的pipeline
- 原始输入: 输入序列,输入序列的句法依存树,输入序列的NER标签
- embedding: embedding层由三部分组成,分别是word embedding,position embedding,entity embedding。
首先对输入文本序列进行词嵌入处理(word2vec方法等),转化为分布式向量表示,即为词嵌入部分。
位置嵌入部分,因为是序列标注,我们每次需要加入待标注token的位置信息,实现方式是增加一个位置嵌入矩阵,随机初始化,通过与待遇测的token位置的距离在位置嵌入矩阵中进行look-up,得到对应的位置矩阵。举个例子,我们预测句子中的第一个fired时,这个fired的位置索引为0,前面的who的索引为-1,后面into的索引为1,以此类推。这个思路和关系提取经典论文PCNNs中的位置嵌入基本是一致的。
第三部分,实体类型嵌入,就是增加一个实体类型矩阵,随机初始化,根据各个token的实体识别标签,分别去look-up对应的向量。
将以上三部分embedding进行级联,即为后续的输入。 - bi-lstm编码:因为后面的图卷积处理捕捉的距离范围受卷积层数K影响,通过bi-lstm扩大感受域。将3中的embedding序列经过双向lstm编码后,将对应两个方向的隐状态级联作为后续输入。
- 图卷积网络:这里开始进入重头戏。
首先,我们要讲输入序列的句法依存树转化为图结构,方便后续处理。

上面是论文中的描述。既然要转化为图,两个要素就是节点和边,论文中额外维护了第三个要素,就是边的label,因为如示例中的依存树所示,各个连接的关系是不同的,对应不同的语法关系,如图中的case、det、nmod等。实际的转化方式就是,序列中的每个token对应图中的节点,序列在依存树中的连接关系转化为图中的边,并另外存储下各个边的label。
然后这里对这个原始图中的连接进行了两种扩充,这个貌似也是做图卷积神经网络之前的一种常见操作,
就是添加self-loop(也就是节点自己和自己的连接)和反向连接,添加了反向连接后,有向图转化为了无向图,
上述的操作对应下面这个公式:
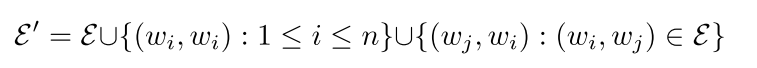
对于这些扩充的边的label进行如下处理:自连接标记为loop,反向连接在原来关系的基础上加一个标记(可以理解为后缀,比如原来方向连接的关系为nmod,现在反向的关系就标记为 nmod_reverse)
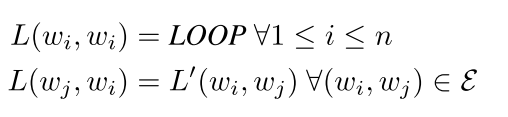
完成上述的准备工作后,
就可以将输入序列进行图卷积了,
如下面公式所示:

实际进行k层的图卷积,上面描述了第k层的卷积过程。
首先,第一层卷积的输入是步骤3中经过bi-lstm层后的编码特征。后面k+1卷积层的输入是第k层的输出。
上面的公式表达的很清晰,实际的卷积方式就是,对于每个序列来讲,将所有邻居节点(也就是与其有连接的节点)进行卷积后求和,作为当前序列的输出(从这里也能理解,为什么要在之前节点连接中添加self-loop,因为节点自身的信息也很重要,如果不添加self-loop,在卷积时就无法利用目标token自身的编码向量了)。
这里有一个细节,之前的节点连接的label信息如何利用呢?
实际上处理方式很简单,对各个label单独维护卷积层权重矩阵(也就是单独设定卷积核),实际卷积时,对应连接属于哪一类,就使用哪个权重矩阵。
然而文中的实际操作比上述更简单,实际只维护了三种label,自连接,正向连接(也就是原始树中的连接)和反向连接(也就是后添加的反向连接)。
这里的操作原文描述是为了Limiting the capacity,我的理解:可以降低模型的过拟合风险,同时相对对依存树的标注更鲁棒。毕竟实际树结构的标注有可能出现错误。
这里还有最后一个细节,就是目前的卷积中各个边的权重都是一样的,但实际上序列之间连接的重要性是不一样的。
下文中举了个例子。

然后,为了让不同边具有不同的权重,文中给出了一种简单粗暴的方法,设置一个权重层,让它自己学习怎么赋权重吧(为什么感觉隐约嗅到了attention的味道)。
嗯,加上权重后,之前的卷积公式转化为下面这个:

作者提到,这种加权操作还有助于降低错误的依存关系标注对模型的影响。
呼,至此,图卷积模块终于结束了,实际卷积可以有多层,这里作者为了模型结构的便利,设置输入输出维度相同。
5.pooling:经过上面的图卷积操作后,我们得到整个序列的输出特征,也就是{
h
1
k
h^{k}_1
h1k,
h
2
k
h^{k}_2
h2k,…,
h
m
k
h^{k}_m
hmk}
我们需要进行pool操作,固定长度,然后输入分类层中。
文中首先说了几种经典操作:

第一种,anchor pooling,就是说我们待预测的token是哪个,就保留对应的特征输出,其他的直接舍弃。
第二种,overall pooling,对整个序列进行位置维度的max pooling。
第三种,根据待预测token位置把序列输出切割为两部分,把这两部分分别进行max pooling 然后级联。
以上三种策略各有优缺点,文中提出了一种提升方案:

作者称为entity mention-based pooling,
其实很好理解,输入序列有对应的实体识别的标签,我们只保留待预测token以及具有特定实体类别的token(也就是舍弃类别为‘O’的token),将这些保留下来的token对应的输出特征求max pooling。
6.分类层:将pooling后的输出给入分类层,输出待预测label,任务完成!
最后,总结一下整个模型的pipeline:

实验结果
文中使用了两个数据集进行评测:
ACE 2005 dataset 和 TAC KBP 2015 dataset。
关于具体的实验设定细节和超参数这里就不详细叙述了,感兴趣的同学可以去原文查找。
只列出几个关键点:

1,卷积层数为2时效果最好,可能K继续增大会引入较多干扰信息。
2.k=3时,不加bi-lstm效果反而更好,这里可以理解为增加卷积层数和双向lstm都是为了捕捉远距离依赖的信息,这里可能两者的作用有些重叠,引入了过多干扰信息。
下面是各种pooling层的效果比对:

与之前的sota模型的效果比对:

论文总结
这篇论文提供了 一个 句法依存树 与 图卷积网络 结合的很好的方案,并且取得了可观的结果。
不过这种方案对句法依存树和命名实体的标注质量要求还是较高的,如果这两种标注中有较多噪声,对模型效果势必有较大影响。
而实际使用中句法依存树这类标注的成本很高,可能只能使用自动标注工具,所以这种情况下可能模型效果会打折扣。
目前我的经验还有限,如果上述有表述不清或者错误的地方,欢迎交流,指正~














 2604
2604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









