






代码
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.impute import SimpleImputer as Sim
from sklearn.preprocessing import OrdinalEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import roc_auc_score, recall_score, plot_roc_curve, confusion_matrix
'''获取数据'''
weather = pd.read_csv(r'weatherAUS5000.csv', index_col=0) # dataframe结构,index_col表示哪一列作为行索引
X = weather.iloc[:,:-1] # 获取样本
Y = weather.iloc[:,-1] # 获取标签
X.info() # 获取特征信息,查看空缺情况、数据类型
Y.isnull().sum() #获取标签缺失数量
# 划分训练集和数据集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X, Y, test_size=0.3, random_state=420) # test_size表示测试集所占比例
'''编码标签'''
encoder = LabelEncoder().fit(Ytrain) # 训练编码器
Ytrain = pd.DataFrame(encoder.transform(Ytrain))
Ytest = pd.DataFrame(encoder.transform(Ytest))
'''处理Rainfall数据列'''
Xtrain['Rainfall'].isnull().sum() # 获取缺失值数量
Xtrain.loc[Xtrain.loc[:,'Rainfall']>=1, 'Raintoday'] = 'Yes' # 大于等于1赋值为下雨
Xtrain.loc[Xtrain.loc[:,'Rainfall']<1, 'Raintoday'] = 'No' # 小于1赋值为不下雨
Xtrain.loc[Xtrain.loc[:,'Rainfall'] == np.nan, 'Raintoday'] = np.nan
# 测试集执行相同操作
Xtest.loc[Xtest.loc[:,'Rainfall']>=1, 'Raintoday'] = 'Yes'
Xtest.loc[Xtest.loc[:,'Rainfall']<1, 'Raintoday'] = 'No'
Xtest.loc[Xtest.loc[:,'Rainfall'] == np.nan, 'Raintoday'] = np.nan
'''简化处理,删除无关数据列Date,Location,Rainfall '''
Xtrain = Xtrain.drop(columns=['Date','Location','Rainfall'])
Xtest = Xtest.drop(columns=['Date','Location','Rainfall'])
'''填补分类型数据'''
cate = Xtrain.columns[Xtrain.dtypes == 'object'].tolist() # 寻找那些列是分类型特征
cate = cate + ['Cloud9am','Cloud3pm'] # Cloud9am,Cloud3pm虽为数字,本质上仍为分类型特征
# 对于分类型特征,利用众数填充缺失值
s1 = Sim(missing_values=np.nan, strategy='most_frequent')
s1.fit(Xtrain.loc[:,cate]) # 训练
Xtrain.loc[:,cate] = s1.transform(Xtrain.loc[:,cate]) # transform
Xtest.loc[:,cate] = s1.transform(Xtest.loc[:,cate])
# 将分类型变量编码为数字
oe = OrdinalEncoder()
oe = oe.fit(Xtrain.loc[:,cate])
Xtrain.loc[:,cate] = oe.transform(Xtrain.loc[:,cate])
Xtest.loc[:,cate] = oe.transform(Xtest.loc[:,cate])
'''填补连续型数据'''
# 寻找连续型变量
col = Xtrain.columns.tolist()
for i in cate: # 删除分类型变量即为连续型变量
col.remove(i)
# 用平均值填补数据
s2 = Sim(missing_values=np.nan, strategy='mean')
s2 = s2.fit(Xtrain.loc[:,col]) # fit
Xtrain.loc[:,col] = s2.transform(Xtrain.loc[:,col]) # transform
Xtest.loc[:,col] = s2.transform(Xtest.loc[:,col])
'''无量纲化处理'''
s3 = StandardScaler()
s3 = s3.fit(Xtrain.loc[:,col]) # fit
Xtrain.loc[:,col] = s3.transform(Xtrain.loc[:,col]) # transform
Xtest.loc[:,col] = s3.transform(Xtest.loc[:,col])
'''SVM算法'''
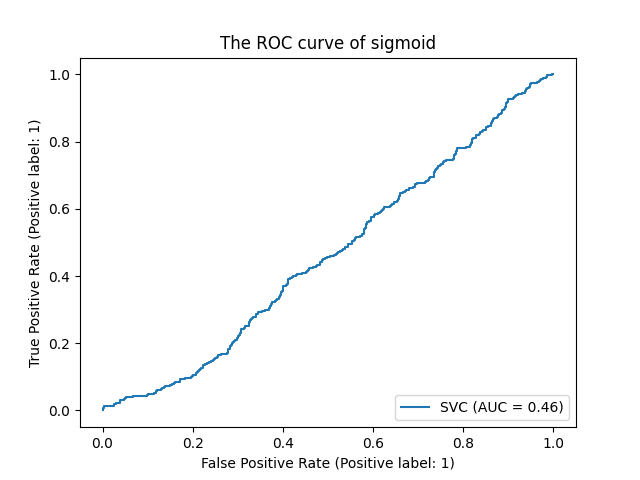
for kernel in ['linear','poly','rbf','sigmoid']:
clf = SVC(kernel=kernel,gamma='auto',degree=1,cache_size=5000).fit(Xtrain,Ytrain)
res = clf.predict(Xtest) # 测试结果
score = clf.score(Xtest,Ytest) # 返回准确率
recall = recall_score(Ytest,res) # 返回召回率
auc = roc_auc_score(Ytest, clf.decision_function(Xtest)) # 返回auc面积
# display = plot_roc_curve(clf,Xtest,Ytest) # ROC曲线
# plt.title('The ROC curve of %s'%(kernel))
# plt.show()
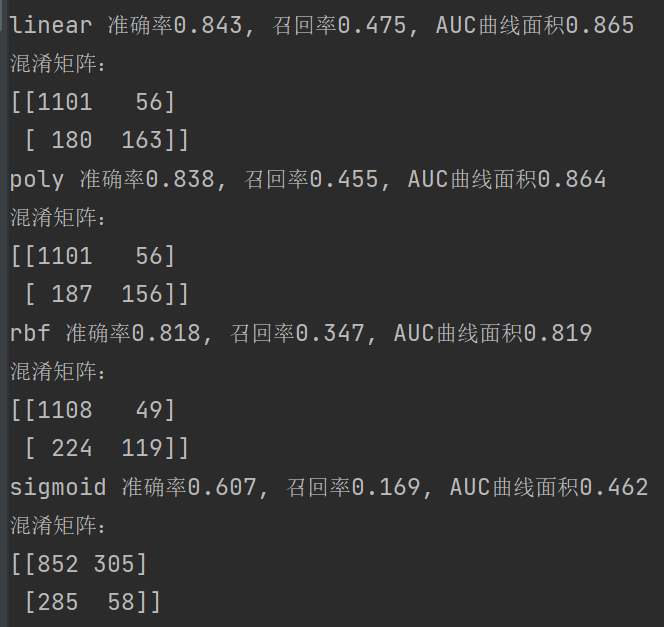
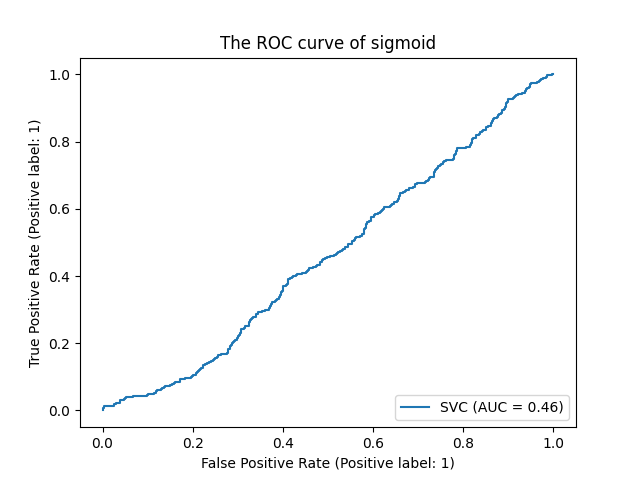
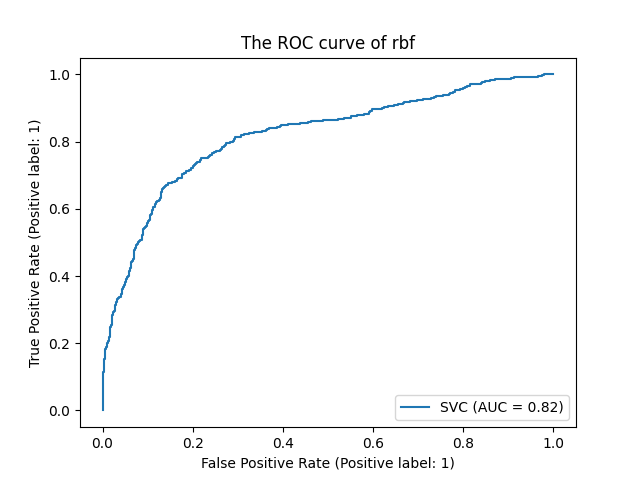
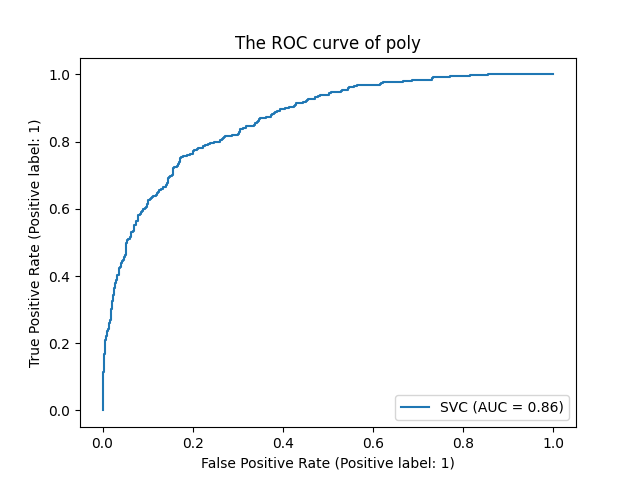
print('%s 准确率%.3f, 召回率%.3f, AUC面积%.3f'%(kernel,score,recall,auc))
print('混淆矩阵:')
print(confusion_matrix(Ytest,res))
控制台结果
ROC曲线














 557
557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









