









额。。。本人菜鸡一只,强行记录点东西,分享一下,也怕自己脑子不好使,忘记了~如果有说错的,还请大家指出批评!!
前言:spark的运行模式有很多,通过--master这样的参数来设置的,现在spark已经有2.3.0的版本了,运行模式有mesos,yarn,local,更好的是他可以和多种框架做整合,2.3的版本也新增了Kubernetes。。。
言归正传,讲下我所做的测试:
测试的代码如下(用的是spark1.6的版本):
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by 略略略 on 2018.
*/
object Hive_Row_Number {
def main(args: Array[String]) {
//1、创建spark上下文
val conf = new SparkConf()
.setAppName("Hive_Row_Number")
//设置这个值,避免sql的shuffle分区数为默认的200,就会很慢
.set("spark.sql.shuffle.partitions", "5");
//这里如果是local运行就把注释解开,
//如果打成jar包,服务器运行,一定要注释掉,
//否则client模式会变成local(就是任务不会提交到yarn上去计算)
//cluster模式运行会有结果,但是会报错
//.setMaster("local[*]")
val sc = SparkContext.getOrCreate(conf)
//这里要考虑是否要读取hive的数据,或者使用HQL
//如果需要:就使用HiveContext,如果不需要,就使用SQLContext
//如果使用HiveContext并且在本地做的测试,很可能需要添加-XX:PermSize=128M -XX:MaxPermSize=256M 来避免内存溢出
//因为构建HiveContext的时候,会加载不少hive默认的jar包,类,对象,
//在1.6版本这两个对象还是分开的,但是2.0以上的版本就是统一到SparkSession这个对象上了
val sqlContext = new HiveContext(sc)
val df = sqlContext.sql("select deptno,sal,ename,row_number() over (partition by deptno order by sal desc) as rnk from test.emp")
//取rnk为前三的
df.show()
df.registerTempTable("tmp")
println("=============注册成临时表的方法=================")
sqlContext.sql("select deptno,sal,ename,rnk from tmp where rnk <= 3").show()
println("=============子查询嵌套的方法=================")
sqlContext.sql(
"""
|SELECT
|deptno,sal,ename,rnk
|FROM
|(SELECT
|deptno,sal,ename,
|ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY sal DESC) as rnk
|FROM class19.emp) a
|WHERE rnk <= 3
""".stripMargin).show()
}
}
这个代码呢,你要告诉你的spark应用程序,从哪里去读取元数据信息,也就是hive-site.xml这个文件
一、连接元数据信息有两种方式:
-1.可以使用hive提供的metastore服务
-2.可以直接通过hive-site.xml中给定的mysql数据库连接信息,连接上mysql上的hive的元数据信息库
这里附上我的,不用配置很多东西,我使用的是hive提供的metastore服务
记得要开启 bin/hive --service metastore
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://bigdata-01:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://bigdata-01:8020/user/hive/warehouse</value>
</property>
</configuration>具体怎么操作,就不说了吧,这不是这篇文章的重点。
二、运行什么模式,配置参数可以有三个地方给定:
1、代码中给定,例如 val conf = new SparkConf().setMaster(XXX)
2、提交job的时候,就是在写那个spark-submit脚本的时候可以给定 --master XXX
3、在spark-env,或者spark-defaults.conf等这类的配置文件中提前写好
优先级:3<2<1,也就是说,如果你在三个地方都写了相同的参数,给定了不同的值,那么最后那个值为代码中给定的值
三、local模式
这也不是想要说的重点,运行的时候,要记得添加一下hive-site.xml(和hive/conf目录下的hive-site.xml配置保持一致)到项目的resource中,例如:
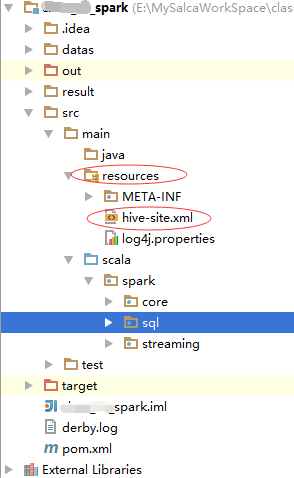
然后,直接运行main方法,搞定!
四、服务器或者虚拟机运行模式:
1、就需要将项目打包,打包方式有很多,简单描述下,这也不是我要说的重点:
-1、打成胖包,就是打包的时候把相关依赖全部打进jar,会导致jar文件比较大,也有可能遇到jar包冲突的问题
-2、打成瘦包,就是只把resource目录下的配置和代码打进jar中,相反,有可能会遇到jar缺失,找不到的问题
-3.开发工具直接打包
myeclipse的叫export,idea的叫build,myeclipse默认的export不能添加外部依赖(就是不能打成胖包),但是idea可以
-4.maven打包
maven打包如果要打胖包,可以使用assembly插件,如果不打胖包就无所谓了
-5.以上的打包方式一定要注意一点,就是要把resource里面的配置文件打入,不然运行代码的时候,创建HiveContext,不知道去哪里连接metastore服务!
-6.然后,我做了两个测试:
打了两个包,一个有hive-site.xml,一个没有,然后我会进行如下两种模式的测试!
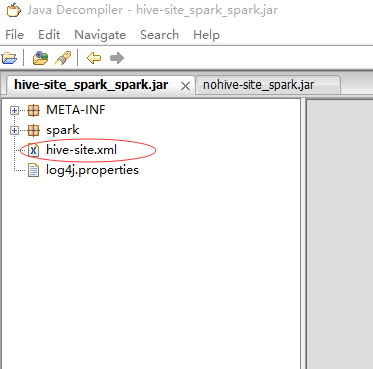
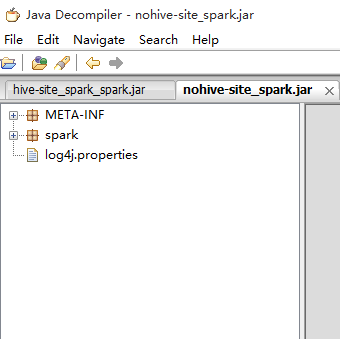
2、yarn-client模式
概念:使用这种方式提交的话,spark的driver就会在提交的机器上开启,driver就是用来构建spark上下文,和DAG的流程图,等到有action的操作的时候,才把一个个task任务甩到executor上去执行,所有的executor的task信息等乱七八糟有的没的的log信息,都会返回到driver端,因此client模式,可以看到这个spark的application运行期间是否出现问题,有问题能够对症下药。但是这种模式有个问题,就是当前机器的driver要接收非常多的消息,非常多的连接,导致当前机器性能下降(而且我们并不知道当前机器有没有能力承受这么大的压力)
执行命令:
bin/spark-submit \
--master yarn \
--deploy-mode client \
--class spark.sql.Hive_Row_Number \
--queue QUEUE_NAME \
/usr/datas/nohive-site_spark.jar但是我想要把回显的所有信息存在一个文本当中,让我今后查看,因此(使用nohup命令):
nohup bin/spark-submit \
--master yarn \
--deploy-mode client \
--class spark.sql.Hive_Row_Number \
--queue QUEUE_NAME \
/usr/datas/nohive-site_spark.jar >> nohive-site.log 2>&1 &这样就会自动在当前目录下生成一个nohive-site.log文件,就可以查看了
这里就截取部分信息来说明
1)classpath
首先,我在spark-env.sh中添加了SPARK_CLASSPATH,把我需要的一些基础的依赖放到了external_jars这个目录中,因此我发现yarn-client模式也会自动加载这个目录下面的所有jar包
但是这种方式,在我的1.6的版本是过时的,不过还是生效的
提示你,应该使用如下的方式:
-1-、先将spark-env.sh中的SPARK_CLASSPATH注释掉(不注释会报错,在下面的测试三的第四种有截图)
-2-、再将executor所有需要的jar包考到一个文件里(XXXX/XXX里)
-3-、然后在spark-default中设定参数:spark.executor.extraClassPath=XXXX/XXX/* (设置executor端jar)
-4-、最后在执行:
nohup bin/spark-submit \
--master yarn \
--deploy-mode client \
--class spark.sql.Hive_Row_Number \
--queue QUEUE_NAME \
--driver-class-path /usr/jars/mysql-connector-java-5.1.34-bin.jar(设置driver端需要的jar) \
/opt/datas/nohive-site_spark.jar >> nohive-site.log 2>&1 &本文后面,会归纳一些jar包读取不到(添加jar包的方式)的解决方法
2)hive-site到底读没读到
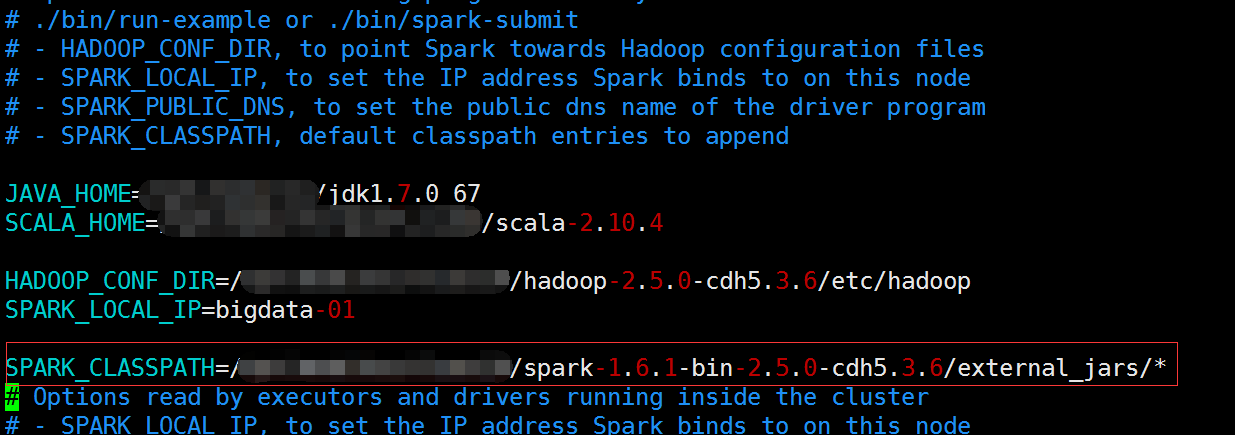

jar中没有hive-site.xml
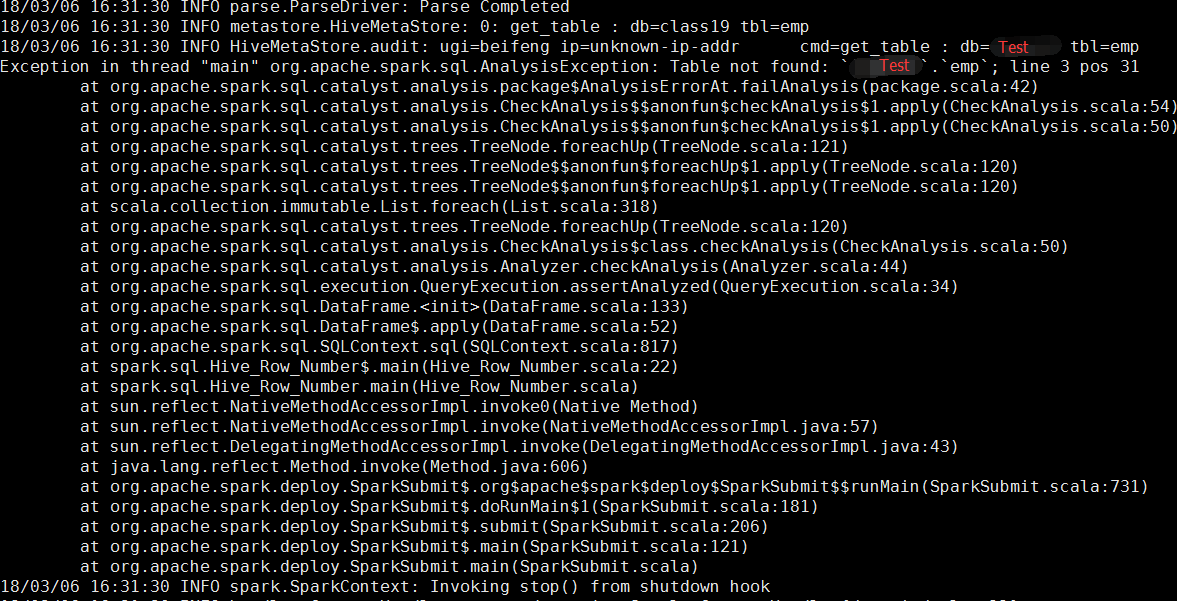
测试一:在spark/conf下放置了hive-site.xml,程序能正常运行
虽然能看到中间有一段在连接默认自带的derby,并且还有个warn,不过后面又有:INFO hive.metastore: Trying to connect to metastore with URI thrift://bigdata-01:9083这么一段信息,最后结果也出来,证明spark on yarn 也会自动加载spark的conf目录下的配置文件,那么我就放心了
测试二:然后我将spark/conf下面的hive-site.xml删除,结果再次运行果然报错了,报的错是:
这报错一看就知道,这个sparksql加载的derby,所以找不到我在hive里面放的那个emp表
测试三:
我尝试了
第一种:--conf hive.metastore.uris=thrift://bigdata-01:9083
--conf hive.metastore.warehouse.dir=hdfs://bigdata-01:8020/user/class19/warehouse
第二种:--files /spark-1.6.1-bin-2.5.0-cdh5.3.6/conf/a/hive-site.xml
第三种:--properties-file /spark-1.6.1-bin-2.5.0-cdh5.3.6/conf/a/hive-site.xml
第四种:--driver-class-path /opt/modules/class19/spark-1.6.1-bin-2.5.0-cdh5.3.6/conf/a/hive-site.xml
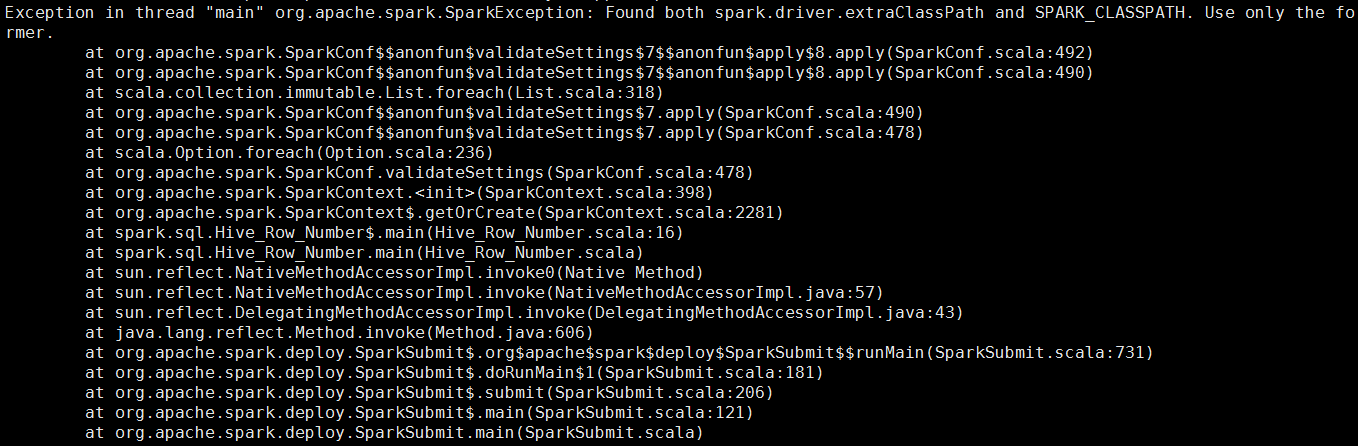
均不可行,并且第四种,因为--driver-class-path,spark.executor.extraClassPath会和SPARK_CLASSPATH冲突,而报如下的错:
测试四:使用自带hive-site.xml的jar包
bin/spark-submit
--master yarn \
--deploy-mode client \
--class spark.sql.Hive_Row_Number \/opt/datas/hive-site_spark.jar
完美运行!
3、yarn-cluster模式
概念:实际项目运行的时候,请使用这种模式,因为这种模式会有资源管理者(resourcemanager)来分配driver开启在哪一台机器上,人为是不可控的,因此你也看不到程序运行的时候是否报错,有什么回显信息。好处就是你不用管当前(提交任务的)机器是否有能力承受大数据量的回显信息。standalone集群也是一样的。
测试一:使用自带hive-site.xml的jar包运行
第一种:要么运行成功(我是成功的)!
第二种:要么运行会有报错(这里就提供报错解决方案)
例如:报错如下
这样的报错,估计神仙都看不懂吧。。。
首先,尝试在yarn的8088页面上查看应用的history(前提是historyserver服务已经正常开启),发现看不了:
报错如下
Configuration Local logs Server stacks Server metrics java.lang.Exception: Unknown container. Container either has not started or has already completed or doesn't belong to this node at all.
但是其实无所谓,因为如果你的yarn有开启日志聚合,那么肯定有记录日志信息
日志聚合开启:在yarn-site.xml里面配置
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
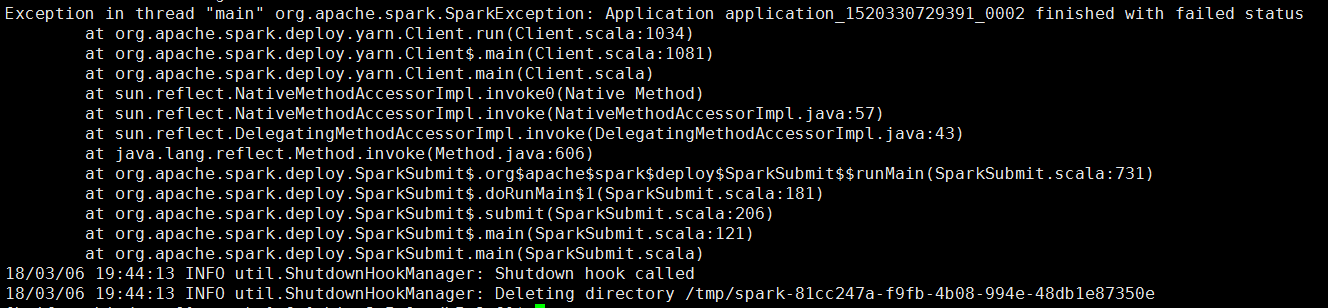
</property>所以可以尝试在hadoop中使用:bin/yarn logs -applicationId application_1520330729391_0002
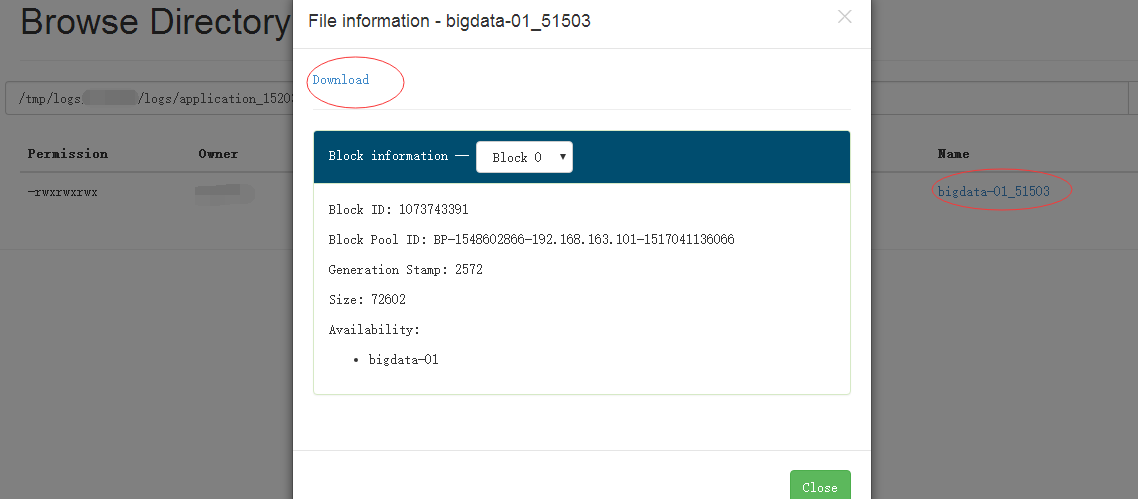
就可以回显日志出来,但是有时候日志太长,有可能就会看不全,因此也可以下载下来,默认是在HDFS的:/tmp/logs/${用户名}/logs下可以找到对应的appid,然后下载下来(别问我怎么下载的。。。)打开!就可以看到里面相关的报错信息,一般来说是解决的了。
如何下载看下图:
好了,到这里已经把我要说的东西和测试的东西将完了,再提一点:就是实际运行的时候,有几个参数要考虑清楚!
| --queue QUEUE_NAME | 你所在的小组提交spark任务提交到yarn的哪个队列中 |
| --driver-cores NUM | driver的核心数,默认为1,不用给多,因为他不处理数据 |
| --driver-memory MEM | driver的内存数,默认是1024M就是1G,这个值不用给太大,可以先使用默认的试试,报错了再增加 |
| --num-executors NUM | executor的总数,executor是实际处理数据的 |
| --executor-cores NUM | 每个executor的核心数,核心数决定了并行数,核心越多,就有越多的task(分区)可以一起运行,一般为分区数的一半,或者三分之一,如果资源够,想要加快运行速度,就增加这个值,增加分区数 |
| --executor-memory MEM | 每个executor的内存数,和上面描述的一样,内存越多,处理越快,越不会报内存溢出,理论上是有多少资源给多少 |
| --conf spark.yarn.executor.memoryOverHead=2048 | 特别提下这个参数,是堆外内存,堆外内存的使用总量 = jvmOverhead(off heap) + directMemoryOverhead(direct memory) + otherMemoryOverhead,部分内存溢出的情况,可以尝试在submit脚本中增加这个值,转载一个大神的文章:http://blog.csdn.net/bitcarmanlee/article/details/78793823 |
然后再说说,测试时候遇到的一些报错和解决方法:
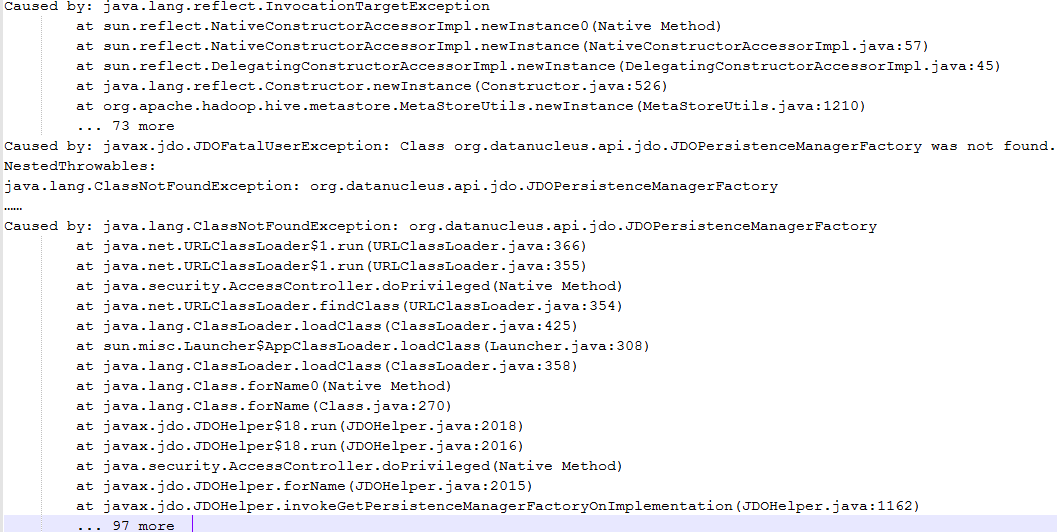
报错一:java.lang.ClassNotFoundException: org.datanucleus.api.jdo.JDOPersistenceManagerFactory
解决:就是类找不到嘛!有很多方式添加jar包,百度之后,发现这个类是datanucleus-api中的,并且这里是连接数据库出的问题,因此我想,hive中应该有这个jar包!
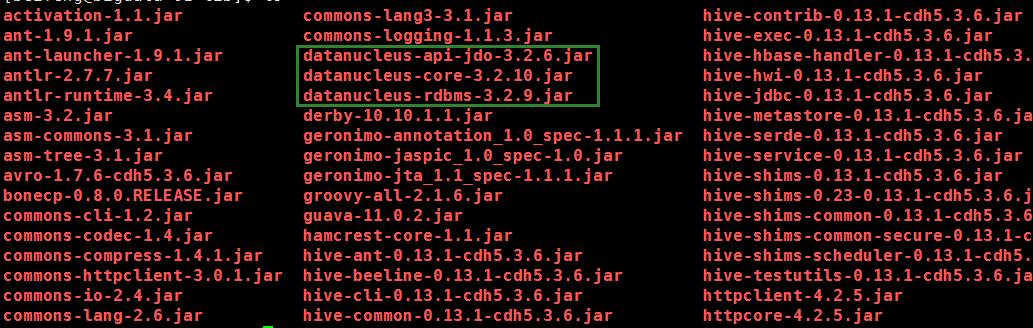
因此我将这几个jar包直接放入${HADOOP_HOME}/share/hadoop/yarn/lib下,然后问题解决
原因:其实是我运行nohive-site_spark.jar(就是读取不到hive-site.xml这个配置的jar包),使用yarn-cluster模式的时候,代码中创建HiveContext不知道要连接metastore服务,所以他就自己连接derby,但是连接的时候需要datanucleus的这几个jar中的方法,但是yarn的环境上又没有,所以报错了,因此我们可以从解决方法中推断,yarn-cluster添加jar包可以通过往${HADOOP_HOME}/share/hadoop/yarn/lib目录下放jar包来解决,并且yarn不用重启
题外话:我在提交的时候使用--jars和--archives添加jar包,发现都不生效,所以,才使用如上的方法,有可能各自环境不同,理论上应该是有效果的,但是。。。。我这里就是不行!
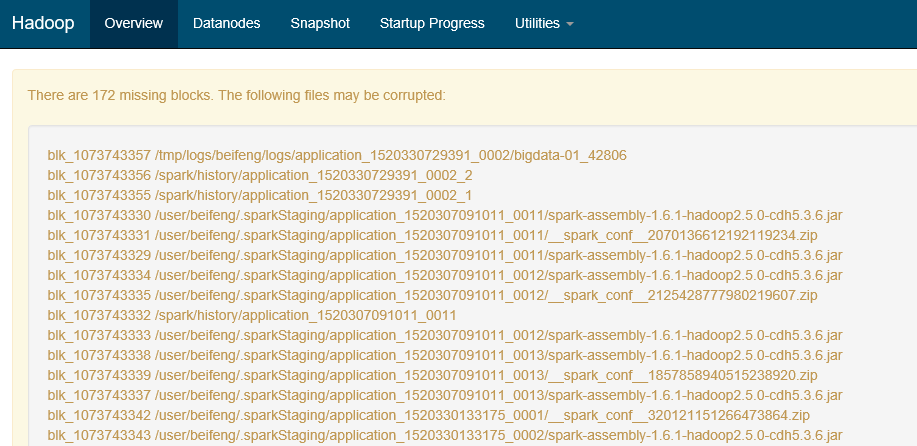
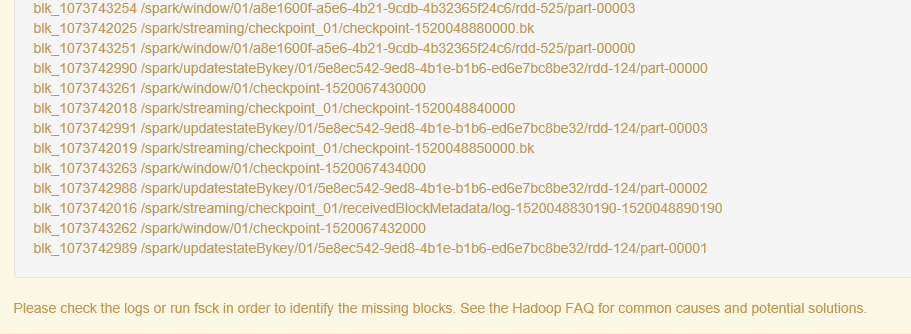
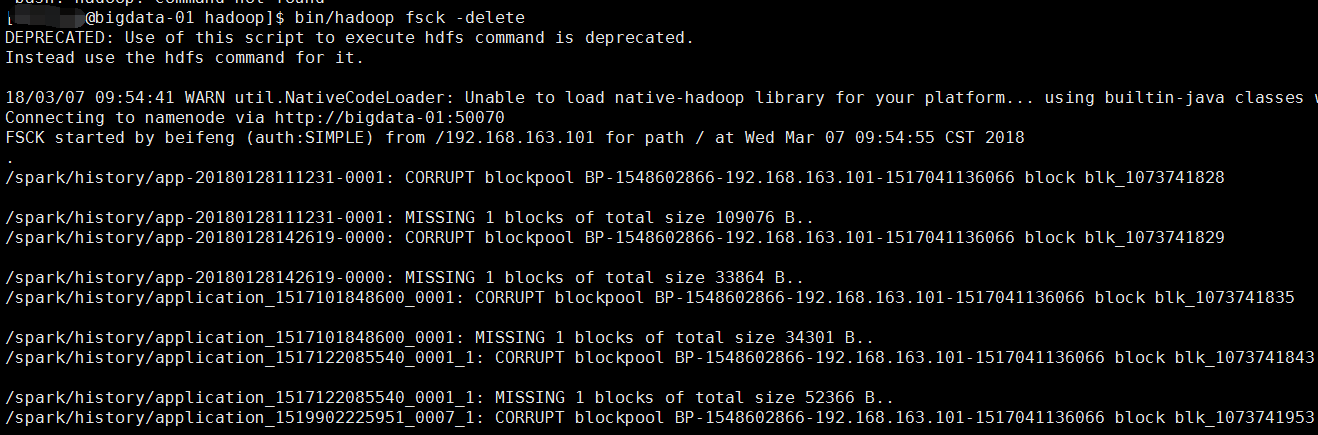
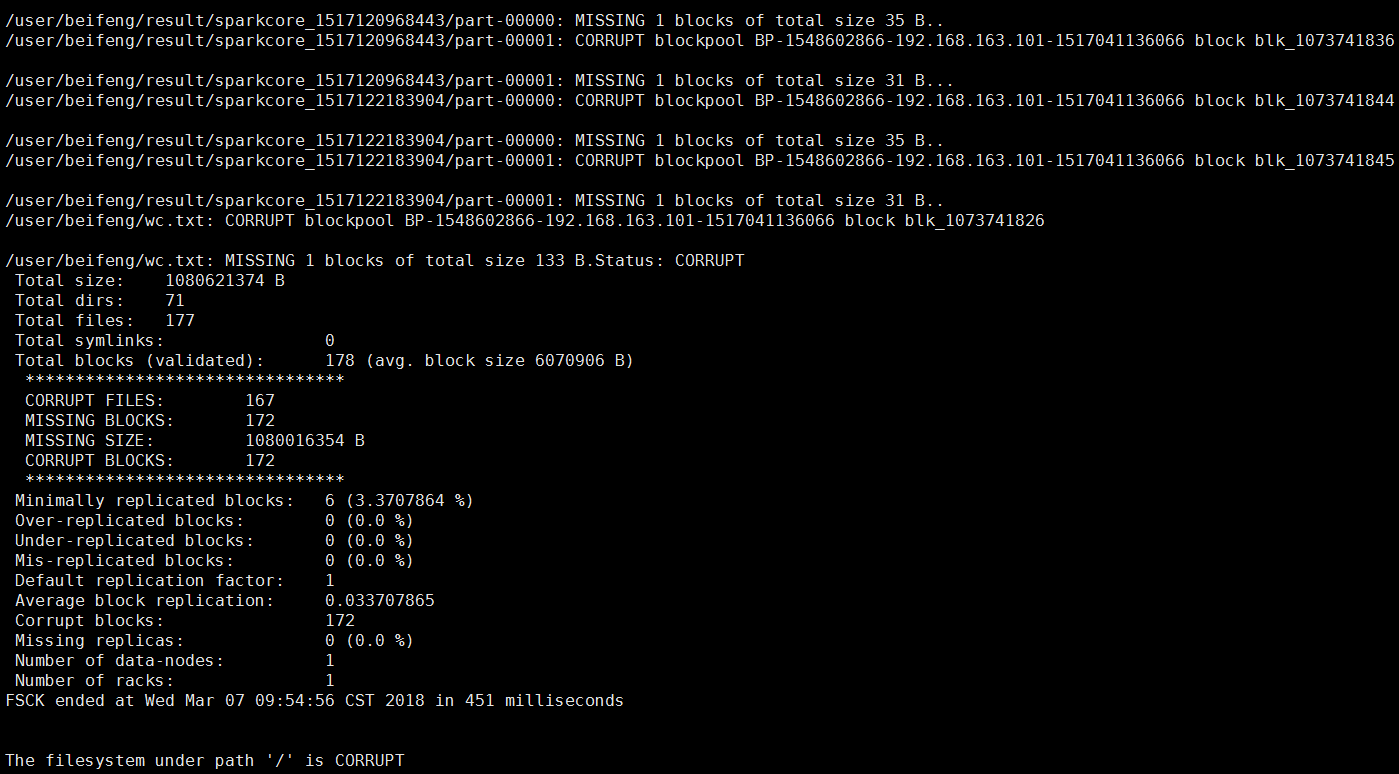
报错二:Please check the logs or run fsck in order to identify the missing blocks. See the Hadoop FAQ for common causes and potential solutions.
hadoop的50070页面直接显示文件块丢失
解决:执行 bin/hadoop fsck -delete
原因:因为手贱,删除了linux上hadoop的文件快,就是blk_XXXXX
就是hdfs上的数据其实是以这种方式存在linux磁盘上的,因此我删除了一部分存储日志的blk,导致了元数据信息在,但是数据块不在了,才报的那个错,但是这部分数据其实我不需要了,所有就直接把出异常的文件块的元数据信息也删除就可以了
报错三:提交spark任务,但是任务执行不了,一直在ACCEPTED状态
18/03/07 10:46:48 INFO yarn.Client: Application report for application_1520390683689_0001 (state: ACCEPTED)
解决:这种错误去看yarn的状态!就是8088页面
注意看下你是否有ActiveNodes(正常的nodemanger)来执行job,如果出问题,这个nodemanager就会变成UnhealthyNodes(不健康的节点),程序运行不了,就是没有一个正常节点了!
然后查看${HADOOP_HOME}/logs目录下nodemanager的报错信息,我发现了这个:
used space above thresholdof 90.0% (其实挺不好找到的,要仔细找才能看到)
磁盘空间的使用率超过90% ,nodemanager变成不健康的节点;
我的hadoop环境是在根目录下的,所以就看第一个值,现在是83%,是已经解决了的状态!
解决:
第一种:增大90%这个阈值,增加到95%
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>95.0</value></property>
不过治标不治本
第二种:删除本地一些没用的东西,日志或者什么安装包(tar.gz)等等的文件(这种解决方式比较常见)



第三种:掏钱,加磁盘。。。
最后的最后总结下我曾经使用过,测试过,看到过的添加jar和配置文件的方法:
注意:下面的几种选项是否会生效,还要看不同的集群实际测试结果,运行之后去查看hadoop的运行日志(hadoop集群上要开启日志聚合),可以通过bin/yarn logs ${appname},或者可以直接去hdfs上看tmp/yarn/....找你对应applicationname,如果不生效,一般来说就是报某个类找不到,把找不到的类,去百度,看看是在哪个jar中的
1、--jars XXXXX / --package XXXX
2、可以在代码当中
conf.setJars("spark应用的jar文件在当前机器上的路径"),在要每一台机器上的相同路径上放入jars
3、spark on yarn
-1.记得让spark可以读取到yarn-site.xml,classpath中添加上hadoop的etc目录,或者让spark读取到yarn-site(让spark知道resourcemanager在哪里)
-2.可以把jar包cp到${HADOOP_HOME}/share/hadoop/yarn/lib/
-3.添加完之后,在yarn上运行spark任务的时候会自动去读取相关的jar包
4、在sparkjar打包的时候,把所有的依赖全部打进去(胖包相对来说就会比较大,可能几百M)
可以使用assembly,或者使用idea直接build
但是这种模式也有可能遇到问题,jar包冲突,照样查看yarn上的运行日志去确定异常
5、一般来说资源文件
log4j,hive-site,yarn-site....
这种文件,占用磁盘空间很小,所以可以在打成jar包的时候直接添加到jar中,然后就可以读取到资源文件
6、在spark-env上添加相关配置(我记得不太一定能够添加上)SPARK_CLASSPATH=${SPARK_HOME}/external_jars/*















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









