







原创文章,转载请注明:http://blog.csdn.net/lsttoy/article/details/52419138
Oops, 你还可以直接github来download我文章中提到的所有资料,都是开源的:)
https://github.com/lekko1988/hadoop.git
首先来个图开心下:

配合intellij idea
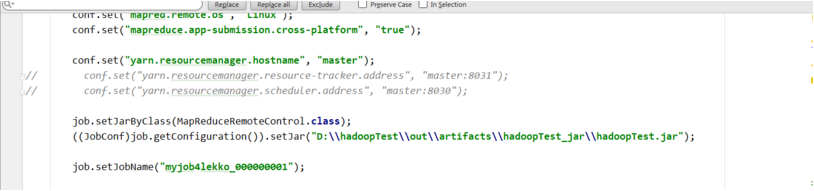
可以看到job已经成功通过本地提交。并且正确的执行了这个job。
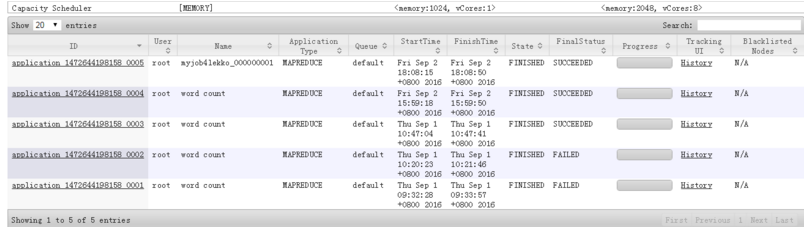
这里面的坑,堪称天坑,网络上没几个能跑的。
那么结合这么多天的经验,来写这个博吧。
首先,搭建好hadoop环境,详情可以参考http://blog.csdn.net/lsttoy/article/details/52318232。
如果安装好后,确认job执行上遇到什么问题(keng),可以食用这篇http://blog.csdn.net/lsttoy/article/details/52400193。
好了回到当前的话题。
在确认所有节点启动并是存活状态下

再次,自己可以在linux运行下hadoop自己提供的wordcount。这个例子很多我就不再赘述。最主要是保证自己hadoop环境没问题。
第三,做好准备intellij集成的准备工作。
主要分两块,一块是载入的hadoop支持包。
另一块是远程调用的属性文件的建立。至于说项目用java或者maven都可以搭建成功。
我们详细的说下上面两块,以及这个过程中的各种坑。
第一块是hadoop支持包。这里也可能是一个坑。一开始我以为是直接去hadoop官网里面下载lib文档,后来发现,里面都是未编译的项目。直到最后我膝盖中了一箭,发现所谓的share包就在我之前安装在linux中的share文件夹中。具体路径请参照:

而这个里面的五个包都是我们需要导入到intellij idea中的。包含comon hdfs mapreduce tools yarn。至于功能,大家都能看得到。
这里提供intellij的导入后截图 File->project Structure->Modules->Dependencies
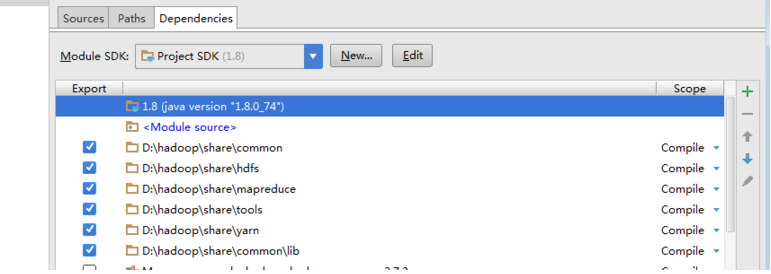
OK,导入完毕后为了方便后面执行时候的说明,顺便把Artifacts也一起配置。
这个是我的配置:
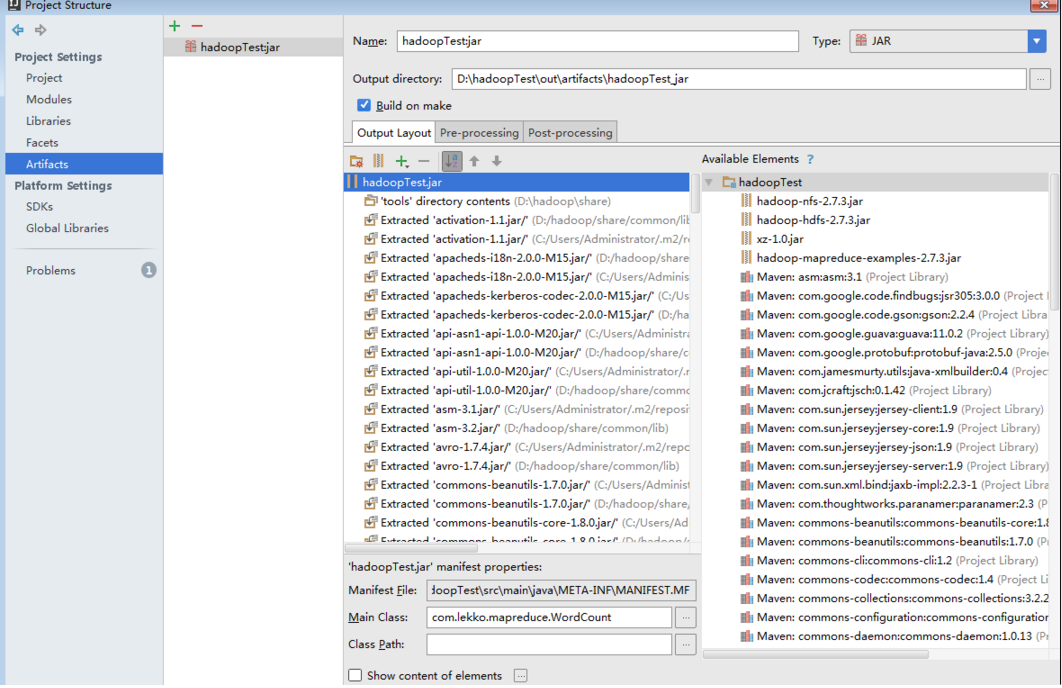
主要抓住两个重点,一个是build on make。另一个是output directory。
一个是方便我们在build的时候能打出jar,另一个是把intellij中打出的jar放到指定路径,方便之后我们在程序中的调用。(后话)
第二个,准备配置intellij 的项目文件。建议使用maven配置,这样打包也方便。
项目结构:
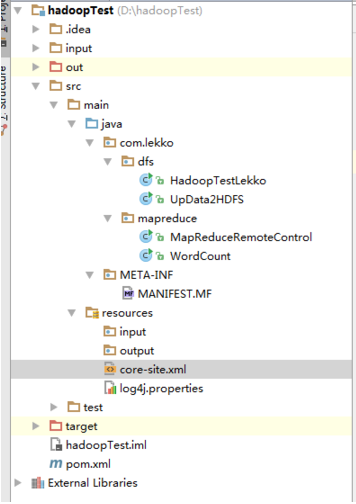
在resouce中新建core-site.xml
其中只需要写入
fs.defaultFS
hdfs://master:9000
另外,pom文件中需要导入对应的包。因为本地已经导入了支持包,所以可以直接写depenencies配置。主要以2.7.3的内容为主。
org.apache.hadoop
hadoop-common
2.7.3
org.apache.hadoop
hadoop-hdfs
2.7.3
org.apache.hadoop
hadoop-client
2.7.3
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
log4j可以配置也可以不配置。
当一切完毕之后,基本就可以开始coding了。
首先我们要尝试下远程操作hadoop,比如新建个文件夹,本地文件和dfs中的交互等等。
可以通过读取以下的代码来进行测试。
package com.lekko.dfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.InputStream;
import java.net.URI;
/**
* Created by Administrator on 2016/9/1.
*/
public class HadoopTestLekko {
public static void main(String[] args) throws Exception {
String uri = “hdfs://master:9000/”;
Configuration config = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), config);
// 列出hdfs上/input目录下的所有文件和目录
FileStatus[] statuses = fs.listStatus(new Path("/input"));
for (FileStatus status : statuses) {
System.out.println(status);
}
// 在hdfs的/input目录下创建一个文件,并写入一行文本
FSDataOutputStream os = fs.create(new Path("/input/test.log"));
os.write("Hello World!".getBytes());
os.flush();
os.close();
// 显示在hdfs的/input下指定文件的内容
InputStream is = fs.open(new Path("/input/test.log"));
IOUtils.copyBytes(is, System.out, 1024, true);
}
}
执行完毕后,可以看到下图:
有个hello world。 基本就OK了。
OK,有了和dfs的交互,基本上八九不离十了。
当然,如果你遇到执行权限问题,或者报roll错误的话,其中一个可能的做法是修改你windoes的用户名,改为root。还有一种做法是提供hadoop user角色为System.setProperty(“HADOOP_USER_NAME”, “root”) 但这个暂时不给出。
接下来,我们就可以进行job的投递,通过本地生成jar,然后jar上传到hadoop的dfs,最终进行整个job的执行。
具体代码这里给出:
package com.lekko.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* Created by root on 2016/9/2.
*/
public class MapReduceRemoteControl {
public static class Map extends Mapper
结束语
觉得好的朋友可以给我大赏一杯咖啡钱缓解通宵梳理环境的疲乏〜!
方式一:支付宝

方式二:以太坊

















 1477
1477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











