






数分小伙伴们都知道,SQL中的case when语句非常好用,尤其在加工变量的时候,可以按照指定的条件的进行赋值,并且结合其他嵌套用法还可以实现非常强大的功能。
同样作为数据分析常用工具之一,pandas中却没有像case when这样的语句,一直以来收到很多朋友吐槽,这样一个常用的功能竟然没有?一般通过使用np.where,where,mask,map,apply,loc等其他方式来实现case when的效果。
好消息是,最近pandas2.2.0稳定版本发布了,其中一个新功能就是增加了case_when方法,可以说这个一直被大家诟病的方法终于补齐了!
一、环境
首先,pandas2.2.0的版本有个安装的前提条件,就是python的版本需要在3.9及以上才行,因此如果使用anaconda的朋友,可以通过conda install python=3.12.1命令先进行python版本升级,完成后再敲入python --version检验版本是否安装成功。
import pandas as pd首次执行pandas包导入后会有一个警告提示,提示你pandas 3.0版本需要Pyarrow但是你目前没有,忽略即可。
二、case_when用法
东哥了解了一下case_when用法,总结了以下几点要点。
对象:case_when属于series对象的方法,dataframe对象无法使用。
功能:如果判断条件为真(True)则替换数据,反之保持原值不变。有点类似于升级版的where/mask。
参数:只有一个参数caselist,是一个元组构成的列表,元组内包含判断条件和想要替换的值。具体形式如下:
caselist = [
(condition1,replacement1),
(condition2,replacement2),
...]condition(判断条件):可以是一维布尔类型的数组或者是可调用的对象(比如函数)。如果是可调用对象,那么应用在series上计算然后返回一个布尔类型的数组或者series。另外,可调用对象不得更改输入series数据。
replacement(替换值):可以是一维数组类对象、标量或者可调用对象。如果是可调用对象,那么应用在series上计算然后返回标量或series。同样的,可调用对象不得更改输入series数据。
对于condition和replacement的要求可以看出,case_when的用法非常的灵活。
举例
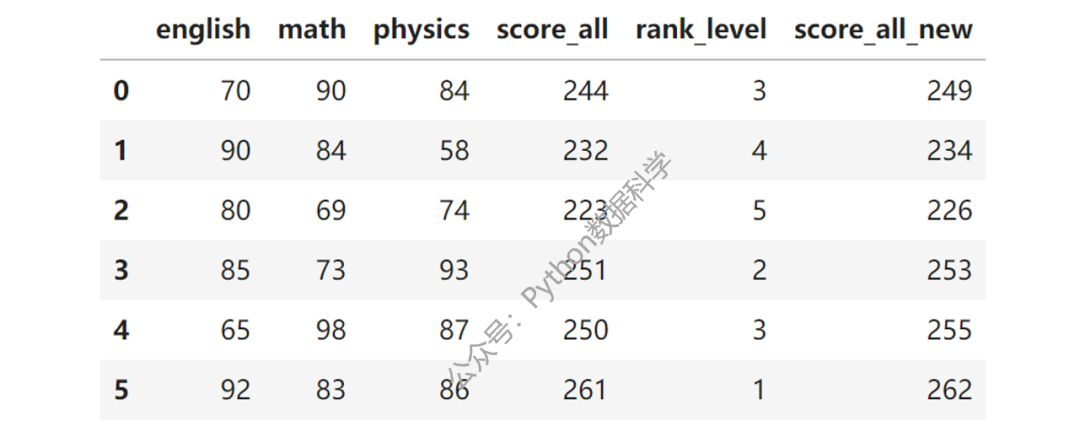
下面创建一组数据说明,是不同学生的三科考试成绩。
案例1
我们想对所有的学生成绩的总分划分不同的等级。
import pandas as pd
df = pd.DataFrame(
dict(enligsh= [70, 90, 80, 85, 65, 92],
math = [90, 84, 69, 73, 98, 83],
physic = [84, 58, 74, 93, 87, 86]
))
df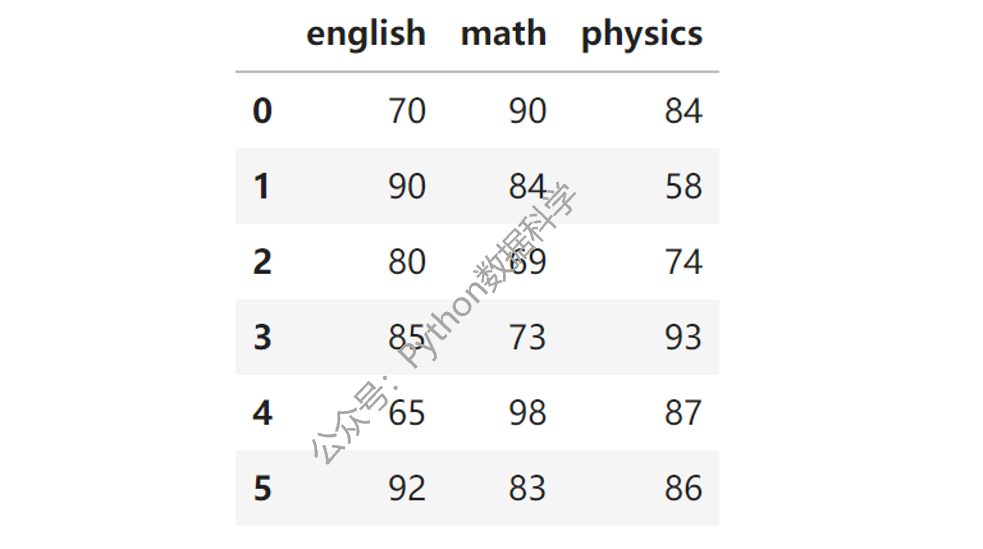
首先,对三科考试求和生成总分数新列。
df['score_all'] = df.sum(axis=1)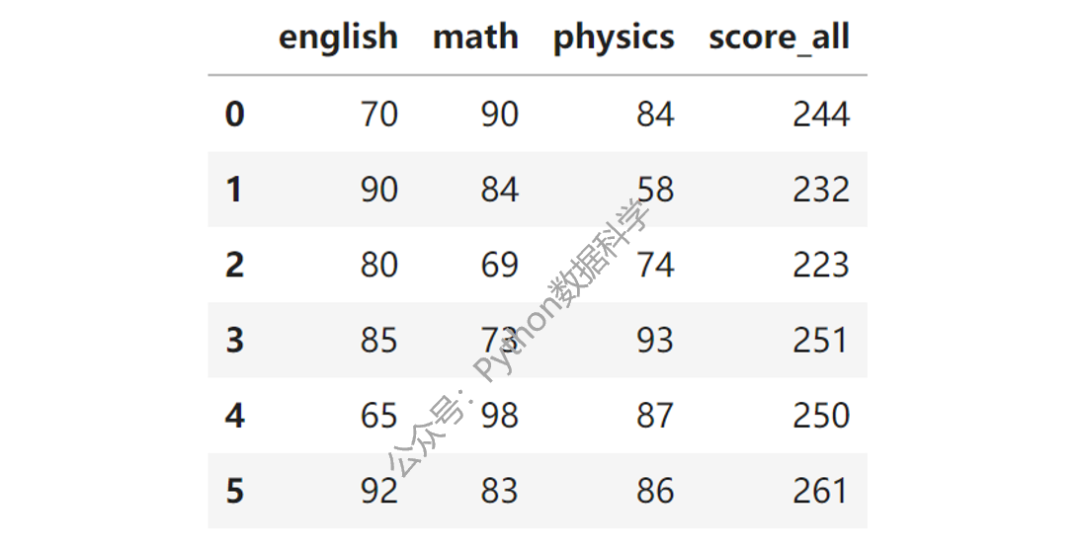
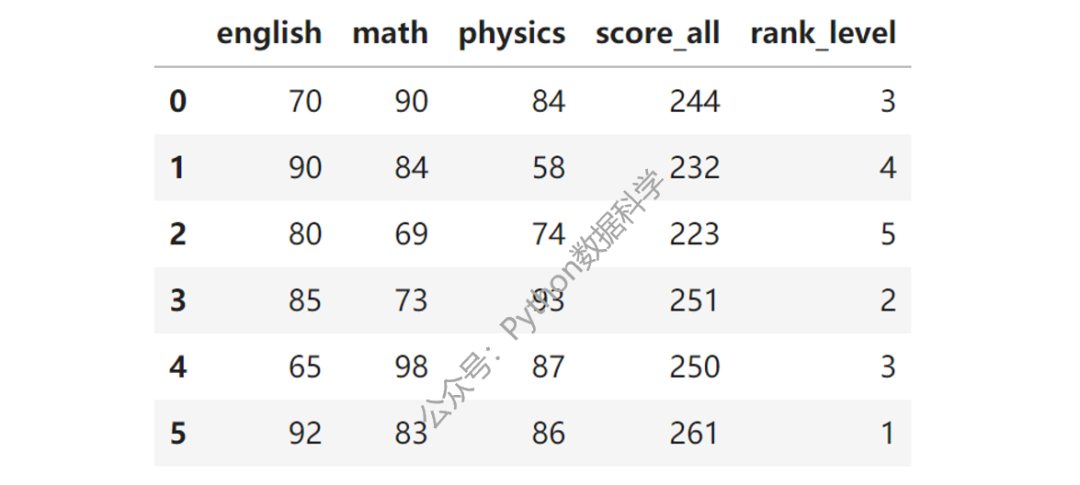
对加工的总成绩列使用case_when方法,生成1-5的排序等级。
df['rank_level'] = df.score_all.case_when(
caselist=[
((df.score_all > 220)&(df.score_all <=230), '5'),
((df.score_all > 230)&(df.score_all <=240), '4'),
((df.score_all > 240)&(df.score_all <=250), '3'),
((df.score_all > 250)&(df.score_all <=260), '2'),
((df.score_all > 260)&(df.score_all <=270), '1'),
]
)
案例2
再比如,我们想针对不同英语成绩的同学,在其总成绩上阶梯式的增加分数。
df['score_all_new'] = df.score_all.case_when(
caselist=[
((df.english <= 70), lambda x:x+5),
((df.english > 70)&(df.english <= 80), lambda x:x+3),
((df.english > 80)&(df.english <= 90), lambda x:x+2),
((df.english > 90), lambda x:x+1),
]
)
注意,以上代码中有两点不同的地方:
判断条件:判断条件的布尔值数组不是基于输入series产生的,而是由series所在的dataframe中其他同维度的series加工获取。这里输入series是score_all,判断条件用的是english。
替换值:替换值使用了lambda隐函数对输入series计算。
这就是case_when非常灵活的原因,判断条件和替换值既可以是固定的值,也可以是自定义的函数,根据自己的需求随意设置。
案例3
case_when只实现区域内的变量加工,其输出结果也可以与其他函数方法结合,产生更多强大的功能。
比如,可以将以上全部变量加工过程通过链式的方式更优雅的实现,结合assign的使用一行代码可完成全部。
# 链式
(
df.assign(score_all = lambda x: x.sum(axis=1))
.assign(rank_level = lambda x: x.score_all.case_when(
caselist=[
((x.score_all > 220)&(x.score_all <=230), '5'),
((x.score_all > 230)&(x.score_all <=240), '4'),
((x.score_all > 240)&(x.score_all <=250), '3'),
((x.score_all > 250)&(x.score_all <=260), '2'),
((x.score_all > 260)&(x.score_all <=270), '1')]))
.assign(score_all_new = lambda x: x.score_all.case_when(
caselist=[
((df.english <= 70), lambda x:x+5),
((df.english > 70)&(df.english <= 80), lambda x:x+3),
((df.english > 80)&(df.english <= 90), lambda x:x+2),
((df.english > 90), lambda x:x+1)]))
)关于pandas的更多进阶玩法、实战案例可以看下东哥原创的《pandas进阶宝典》,或者扫码了解👇

以下是官方的文档:
https://pandas.pydata.org/docs/reference/api/pandas.Series.case_when.html#pandas.Series.case_when
--end--

















 1228
1228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









