






决策树算法简单易用,便于解释,在分类问题中运用非常广泛,如果将很多棵决策树绑定在一起进行分类变量的预判或连续变量的预测,将会是一个什么结果呢?其实,这个思想就是集成,通过综合多个算法分类器,运用投票(分类)或均值(预测)的方法实现最终的应用。
本文将介绍几个集成算法,通过对比了解算法之间的优劣,他们分别是Bagging、AdaBoost和RandomForest。这几个集成算法的基础均来源于CART决策树(分类回归树),通过集成N个分类回归树,实现分类或预测。
一、Bagging
思想:按等概率、有放回的抽样方法,得到若干个不同的训练集,并用这些训练集分别建立分类回归树,再根据这些分类器的预测结果进行投票或平均,最终得到比较稳定的预测结果。
算法实现:R语言通过adabag包中的bagging()函数实现该集成算法,有关函数语法和参数如下:
bagging(formula, data, mfinal = 100, control,...)
formula:指定模型的公式形式,类似于y~x1+x2+x3
data:指定分析的数据对象
mfinal:指定需要产生分类回归树的数量
control:该参数与rpart()函数中的control一致,用于控制分类回归树的生长
二、AdaBoost
思想:一般而言,AdaBoost集成算法相比于上文中提到Bagging集成算法更加有效,这是因为其抽样的方式有所不同。AdaBoost集成算法在每次抽样过程中都会综合考虑上一次抽样计算的结果,并更加关注于上一次分类错误的样本。换句话说,如果上一次抽样中,i样本预测错误,在一下次抽样中i样本将赋予更高的抽中概率。这样做的目的就是提高模型整体的预测精度,而且该集成算法还能够很好的处理不平衡数据(即‘Yes’与‘No’两个类相差很大)。
算法实现:R语言通过adabag包中的boosting()函数实现该集成算法,有关函数语法和参数如下:
boosting(formula, data, boos = TRUE, mfinal = 100, coeflearn = 'Breiman',
control,...)
formula:指定模型的公式形式,类似于y~x1+x2+x3
data:指定分析的数据对象
boos: 指定是否用各观测样本的相应权重来抽取bootstrap样本
mfinal:指定需要产生分类回归树的数量
coeflearn:指定选择权重更新的计算方式,可以是Breiman、Freund和Zhu
control:该参数与rpart()函数中的control一致,用于控制分类回归树的生长
三、RandomForest
思想:RandomForest又异于Bagging和AdaBoost,该算法不仅仅从行(观测)的角度进行bootstrap抽样,而且还要从列(变量)的角度进行无放回的随机抽样(抽样的个数少于所有变量个数),通过不同的组合生成不同的训练样本集。有关随机森林的具体应用还可以参考本公众号《基于R语言的随机森林算法运用》(http://mp.weixin.qq.com/s?__biz=MzIxNjA2ODUzNg==&mid=400806663&idx=1&sn=51b4b7a44a33606bd9262e208f91c2df#rd)一文。
算法实现:R语言通过randomForest包中的randomForest()函数实现该集成算法,有关函数语法和参数如下:
randomForest(formula, data=NULL, ..., subset, na.action=na.fail)
randomForest(x, y=NULL, xtest=NULL, ytest=NULL, ntree=500,
mtry=if (!is.null(y) && !is.factor(y))
max(floor(ncol(x)/3), 1) else floor(sqrt(ncol(x))),
replace=TRUE, classwt=NULL, cutoff, strata,
sampsize = if (replace) nrow(x) else ceiling(.632*nrow(x)),
nodesize = if (!is.null(y) && !is.factor(y)) 5 else 1,
maxnodes = NULL,
importance=FALSE, localImp=FALSE, nPerm=1,
proximity, oob.prox=proximity,
norm.votes=TRUE, do.trace=FALSE,
keep.forest=!is.null(y) && is.null(xtest), corr.bias=FALSE,
keep.inbag=FALSE, ...)
formula:指定模型的公式形式,类似于y~x1+x2+x3...;
data:指定分析的数据集;
subset:以向量的形式确定样本数据集;
na.action:指定数据集中缺失值的处理方法,默认为na.fail,即不允许出现缺失值,也可以指定为na.omit,即删除缺失样本;
x:指定模型的解释变量,可以是矩阵,也可以是数据框;
y:指定模型的因变量,可以是离散的因子,也可以是连续的数值,分别对应于随机森林的分类模型和预测模型。这里需要说明的是,如果不指定y值,则随机森林将是一个无监督的模型;
xtest和ytest用于预测的测试集;
ntree:指定随机森林所包含的决策树数目,默认为500;
mtry:指定节点中用于二叉树的变量个数(随机抽取的变量数目),默认情况下数据集变量个数的二次方根(分类模型)或三分之一(预测模型)。一般是需要进行人为的逐次挑选,确定最佳的m值;
replace:指定Bootstrap随机抽样的方式,默认为有放回的抽样;
classwt:指定分类水平的权重,对于回归模型,该参数无效;
strata:为因子向量,用于分层抽样;
sampsize:用于指定样本容量,一般与参数strata联合使用,指定分层抽样中层的样本量;
nodesize:指定决策树节点的最小个数,默认情况下,判别模型为1,回归模型为5;
maxnodes:指定决策树节点的最大个数;
importance:逻辑参数,是否计算各个变量在模型中的重要性,默认不计算,该参数主要结合importance()函数使用;
proximity:逻辑参数,是否计算模型的临近矩阵,主要结合MDSplot()函数使用;
oob.prox:是否基于OOB数据计算临近矩阵;
norm.votes:显示投票格式,默认以百分比的形式展示投票结果,也可以采用绝对数的形式;
do.trace:是否输出更详细的随机森林模型运行过程,默认不输出;
keep.forest:是否保留模型的输出对象,对于给定xtest值后,默认将不保留算法的运算结果。
应用
对于三个集成算法的应用和比较,我们使用C50包中的客户流失数据作为案例分析,具体操作如下:
library(C50)
#使用C50包中自带的客户流失数据,数据中包含了训练集和测试集
data(churn)
#训练集和测试集排除客户所属区域代码area_code变量
train <- churnTrain[,-3]
test <- churnTest[,-3]
str(train)
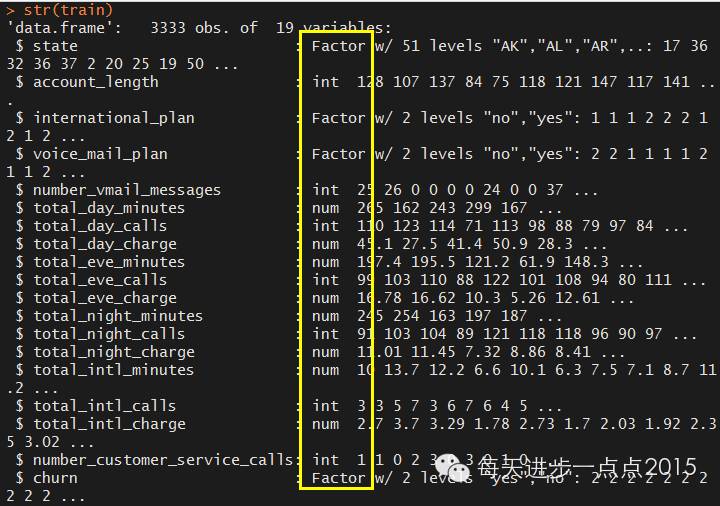
数据集本身混合了数值型变量和离散的字符型变量,对于决策树来说,不需要对数据做任何的变动。
使用adabag包中的bagging()函数建模
library(adabag)
model_bagging <- bagging(formula = churn ~ ., data = train)
#查看模型中包含了哪些结果
names(model_bagging)

这里class、importance是重点了解的结果变量,前者表示模型内分类的结果,后者表示模型变量的重要性
#绘制模型变量重要性图
importance <- as.data.frame(model_bagging$importance)
names(importance) <- c('Value')
library(ggplot2)
ggplot(data = importance, mapping = aes(x = row.names(importance), y = Value)) + geom_bar(stat = "identity", fill = 'blue') + coord_flip()
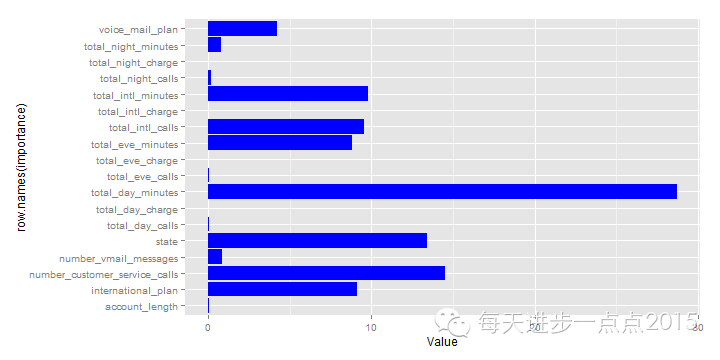
很显然,变量total_day_minutes最重要
#预测
pred_bagging <- predict(object = model_bagging, newdata = test)
#预测精度
Freq_bagging <- table(pred_bagging$class, test$churn)
Freq_bagging
accuracy_bagging <- 1-sum(diag(Freq_bagging))/sum(Freq_bagging)
accuracy_bagging
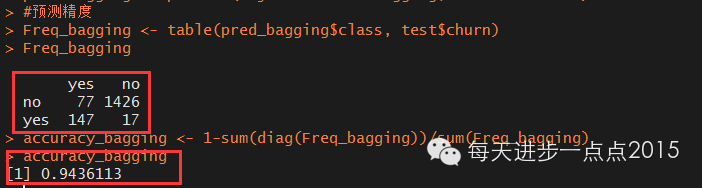 模型的准确度超过94%,说明该集成算法还是非常成功的。
模型的准确度超过94%,说明该集成算法还是非常成功的。
使用adabag包中的boosting()函数建模
library(adabag)
model_boosting <- boosting(formula = churn ~ ., data = train, coeflearn = 'Breiman')
#查看模型中包含了哪些结果
names(model_boosting)
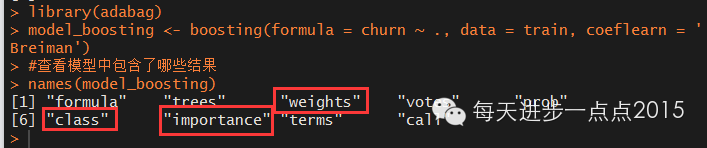
相比于bagging集成算法,模型中还包括了抽样的权重结果,即weights。同样class和importance仍然是重点关注的结果变量,我们看看该集成算法得到的最重要变量是什么。
library(ggplot2)
importance <- as.data.frame(model_boosting$importance)
names(importance) <- c('Value')
ggplot(data = importance, mapping = aes(x = row.names(importance), y = Value)) + geom_bar(stat = "identity", fill = 'blue') + coord_flip()
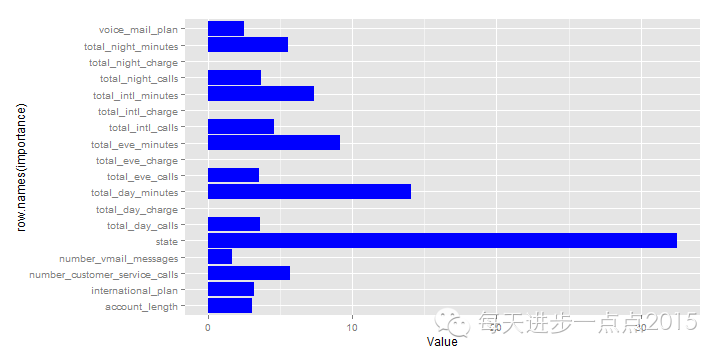
与bagging集成算法不同的是,boosting函数得到的最重要变量是客户所属的洲。
#预测
pred_boosting <- predict(object = model_boosting, newdata = test)
#预测精度
Freq_boosting <- table(pred_boosting$class, test$churn)
Freq_boosting
accuracy_boosting <- 1-sum(diag(Freq_boosting))/sum(Freq_boosting)
accuracy_boosting
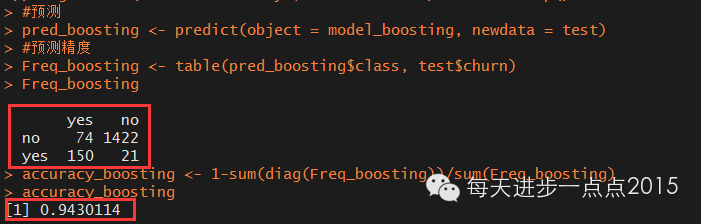
模型效果几乎和bagging集成算法一致,准确率仍然超过94%。
使用randomForest包中的randomForest()函数建模
library(randomForest)
#为选出最佳的mtry参数,这里使用循环的方法进行挑选
n <- length(names(train))
set.seed(1234)
for (i in 1:(n-1)){
model <- randomForest(formula = churn ~ ., data = train, mtry = i, ntree=100)
err <- mean(model$err.rate)
print(err)
}
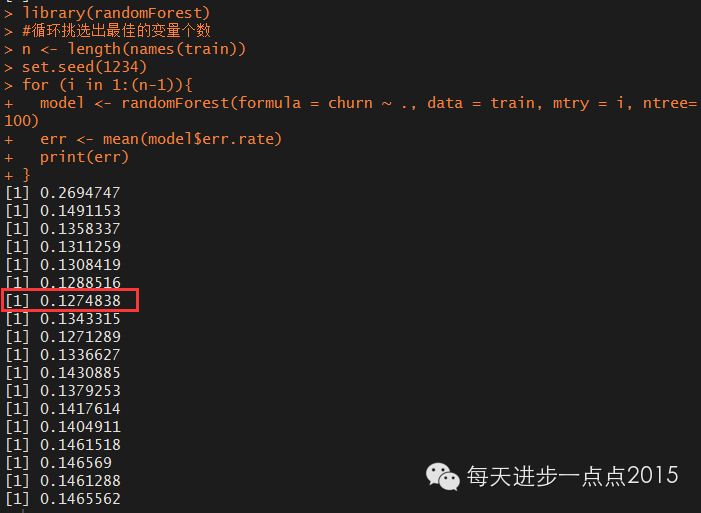
结果发现,当mtry=7时,误差最小,故选择7个随机参生的变量。
#建模
model_randomForest <- randomForest(formula = churn ~ ., data = train, mtry = 7, ntree=100)
names(model_randomForest)
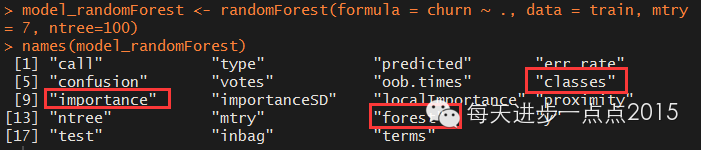
模型结果中包含了更多的内容,这里先重点看一下变量的重要性。
#绘制变量的重要性图
library(ggplot2)
importance <- as.data.frame(model_randomForest$importance)
names(importance) <- c('Value')
ggplot(data = importance, mapping = aes(x = row.names(importance), y = Value)) + geom_bar(stat = "identity", fill = 'blue') + coord_flip()
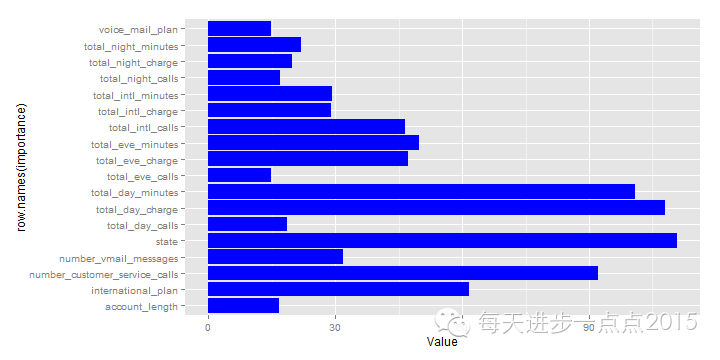
结果发现,客户所属的洲仍然是最重要的变量。
#预测
pred_randomForest <- predict(object = model_randomForest, newdata = test)
#预测精度
Freq_randomForest <- table(pred_randomForest, test$churn)
Freq_randomForest
accuracy_randomForest <- sum(diag(Freq_randomForest))/sum(Freq_randomForest)
accuracy_randomForest
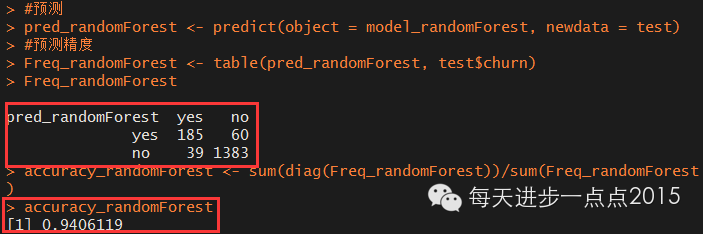
同样模型的准确率也达到了94%。
如果模型在训练样本和测试样本中都具有比较高的准确率,那么模型就可以部署到实际的应用场景中,对于一个未知的分类用户来说,将其相应的指标带入到模型,就可以识别出该用户是否可能流失,以及流失的概率是多大,从而起到客户流失预警的作用。
模型比较:
1)从运行的效率来看,随机森林算法非常快
2)从模型的准确率来看,bagging>boosting>randomForest,但准确率几乎相同,均超过94%
3)boosting和randomForest均把客户所属的洲作为最重要的变量,而bagging算法则将客户每天打电话的总时长作为最重要的变量
文中脚本可到如下链接下载:
http://yunpan.cn/c3CHtsaGZZhPp 访问密码 fcdf
总结:文中涉及到的R包和函数
adabag包
bagging()
boosting()
predict()
randomForest包
randomForest()
ggplot2包
geom_bar()
参考资料
机器学习与R语言
数据挖掘:R语言实战















 5984
5984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









