







Hadoop Docker容器化部署
我们学习Hadoop的过程中基本使用的是虚拟机,如果能用Docker来部署我们的Hadoop要比安装虚拟机方便多了,而且也便于我们移植我们的Docker镜像。所以这里我就想自己实现一个Hadoop的Docker镜像,通过配置可以在本地搭建一套基于Docker部署的Hadoop单机版本或者是Hadoop集群版本。废话不多说,首先要做的就是写一个Hadoop的Dockerfile出来,而且Hadoop我们使用的是Hadoop 3.2.2,截止到本文的编写该版本还是最新的版本。
Dockerfile编写
基于centos:centos8作为基础镜像,如果要部署Hadoop我们需要做以下几个步骤的准备:
- 在linux镜像中安装Java并配置环境变量
- 配置SSH远程登陆
- 创建hadoop账号并赋予sudo权限
- 设置hadoop用户ssh免密登陆
- 安装部署hadoop服务
大体上我们要做以上5个阶段的配置工作,因为基于的是纯净的centos系统镜像,所以一些常用的基础命令还是要安装的。
由于是基础镜像所以每次docker build都需要重新下载Java和Hadoop太麻烦,干脆先在本地下载好后,在Dockerfile中将本地的Java和Hadoop安装包添加进镜像中。同理为了灵活配置Hadoop,我这里也先在本地环境编写好Hadoop的相关配置文件,在构建镜像的时候直接替换掉镜像中的配置文件即可。
下面是具体的Dockerfile的编写:
# 以 CentOS8 镜像为基础生成新的镜像
FROM centos:centos8
# 指定维护者,名字随便起啦
MAINTAINER stackstone
# passwd 命令安装
RUN yum -y install passwd && \
# sudo 命令安装
yum -y install sudo && \
# 安装 ssh 客户端
yum -y install openssh-clients
# JAVA 安装
## 创建 JAVA 目录
RUN mkdir /opt/java
## 将 JDK 放入 /opt/jdk 目录下
ADD install/jdk/jdk-8u301-linux-x64.tar.gz /opt/java
## 配置 JAVA 全局环境变量
RUN echo "export JAVA_HOME=/opt/java/jdk1.8.0_301" >> /etc/profile
RUN echo "export PATH=\$JAVA_HOME/bin:\$PATH" >> /etc/profile
ENV JAVA_HOME /opt/java/jdk1.8.0_301
ENV PATH $JAVA_HOME/bin:$PATH
# 配置 ssh 远程登录
## 安装 openssh-server
RUN yum -y install openssh-server
## 指定 root 密码
RUN /bin/echo 'root:123456'|chpasswd
## 配置可以远程连接
RUN ssh-keygen -q -t rsa -b 2048 -f /etc/ssh/ssh_host_rsa_key -N ''
RUN ssh-keygen -q -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key -N ''
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_ed25519_key -N ''
RUN /bin/sed -i 's/.*session.*required.*pam_loginuid.so.*/session optional pam_loginuid.so/g' /etc/pam.d/sshd
RUN /bin/echo -e "LANG=\"en_US.UTF-8\"" > /etc/default/local
RUN echo "StrictHostKeyChecking ask" >> /etc/ssh/ssh_config
# 创建 hadoop 账号
RUN groupadd hadoop && useradd -d /home/hadoop -g hadoop -m hadoop
# 指定 hadoop 密码
RUN /bin/echo 'hadoop:123456'|chpasswd
# hadoop 账号赋予 sudo 权限
RUN /bin/echo 'hadoop ALL=(ALL) ALL' >> /etc/sudoers
# 设置 root 用户 ssh 免密登录
RUN rm /run/nologin && \
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa && \
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys && \
chmod 0600 ~/.ssh/authorized_keys
# 设置 hadoop 用户 ssh 免密登录
RUN su - hadoop -c "ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa && cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys && chmod 0600 ~/.ssh/authorized_keys"
# 安装部署 hadoop 服务
ADD install/hadoop/hadoop-3.2.2.tar.gz /home/hadoop
## 编辑 hadoop 目录下的 etc/hadoop/hadoop-env.sh文件,定义JAVA_HOME
RUN sed -i '/# export JAVA_HOME=/a\export JAVA_HOME=/opt/java/jdk1.8.0_301' /home/hadoop/hadoop-3.2.2/etc/hadoop/hadoop-env.sh
## 设置 HADOOP_HOME 并添加环境变量
RUN echo "export HADOOP_HOME=/home/hadoop/hadoop-3.2.2" >> /etc/profile
RUN echo "export PATH=\$HADOOP_HOME/bin:\$PATH" >> /etc/profile
ENV HADOOP_HOME /home/hadoop/hadoop-3.2.2
ENV PATH $HADOOP_HOME/bin:$PATH
## 创建 hadoop.tmp.dir 目录
RUN su - hadoop -c "mkdir /home/hadoop/tmp"
## 上传配置文件并覆盖原有配置文件
### HDFS
ADD install/hadoop/config/core-site.xml /home/hadoop/hadoop-3.2.2/etc/hadoop
ADD install/hadoop/config/hdfs-site.xml /home/hadoop/hadoop-3.2.2/etc/hadoop
### YARN
ADD install/hadoop/config/mapred-site.xml /home/hadoop/hadoop-3.2.2/etc/hadoop
ADD install/hadoop/config/yarn-site.xml /home/hadoop/hadoop-3.2.2/etc/hadoop
# 暴露端口号
EXPOSE 22 9870 9000 9864 9866 8088
# 启动镜像,环境变量生效,容器启动会自动运行 ~/.bashrc
RUN echo "source /etc/profile" >> ~/.bashrc
# 格式化 HDFS 文件系统
# RUN su - hadoop -c "hdfs namenode -format"
# CMD su - hadoop -c "/home/hadoop/hadoop-3.2.2/sbin/start-dfs.sh && /home/hadoop/hadoop-3.2.2/sbin/start-yarn.sh" & /usr/sbin/sshd -D
CMD /usr/sbin/sshd -D
Docker镜像构建和启动容器
大家可以直接访问 https://github.com/lt5227/DockerDeploy 将项目下载下来,在项目的dockerfile目录下运行下面的命令构建镜像:
docker build -f hadoop.Dockerfile -t lt5227/hadoop:latest .
启动容器可以使用下面的命令,这里设置了主机名为hadoop-001:
docker run -itd -p 10022:22 -p 9870:9870 -p 9000:9000 -p 9864:9864 -p 9866:9866 -p 8088:8088 --network hadoop --name hadoop-001 --hostname hadoop-001 lt5227/hadoop:latest
之后获取启动容器的containerId,并进入到容器中
docker ps -a -f "name=hadoop-001" -q
docker exec -it [containerId] bash
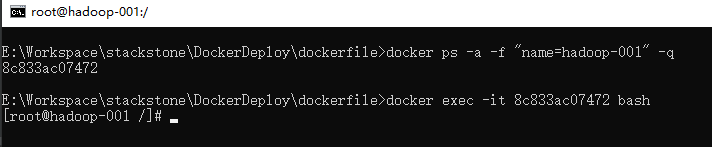
进入到容器之后,Hadoop的安装路径如下:

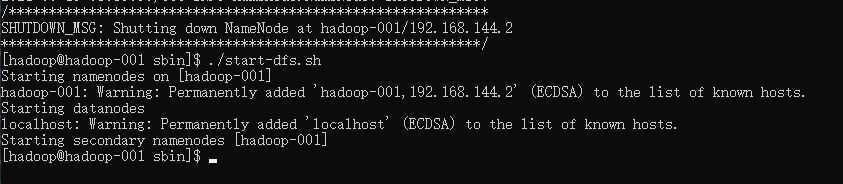
运行su hadoop切换至hadoop账号,之后执行hdfs name -format命令初始化数据,如下图所示:

之后直接执行start-dfs.sh脚本即可启动Hadoop:
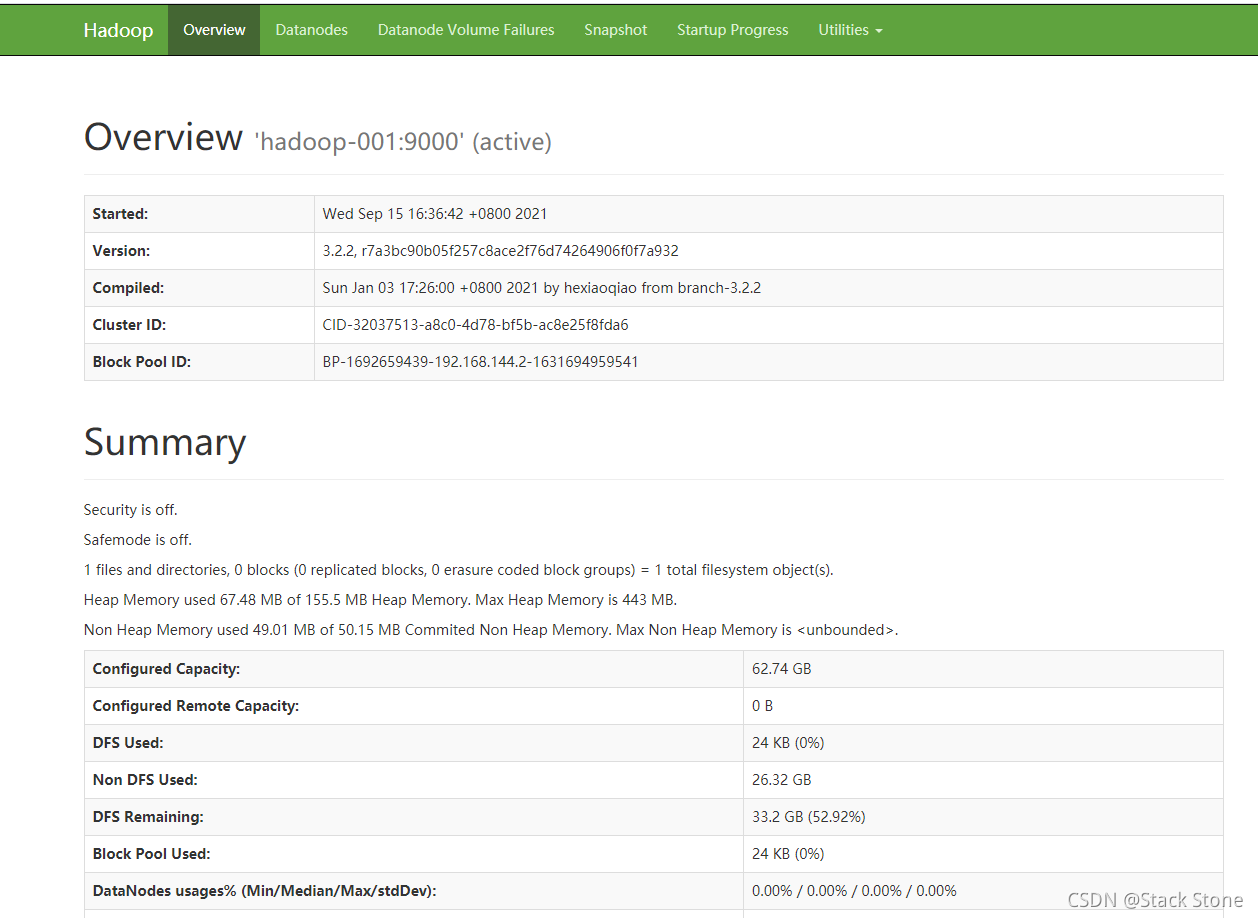
之后本地电脑访问 :http://localhost:9870/ 可以看到Hadoop在Docker中启动成功,当然这里端口是根据你启动时候本地端口映射来定义的。
通过脚本初始化镜像并启动
这里为了更方便初始化搭建部署,我编写了Hadoop单机启动的启动脚本,可以直接运行项目bin目录下的initAndStart.sh脚本。Windows电脑可以通过git的bash.exe来执行shell脚本,相信大家如果在Windows电脑上安装了Docker都应该可以运行shell脚本。
脚本的执行流程如下,运行intiAndStart.sh脚本:
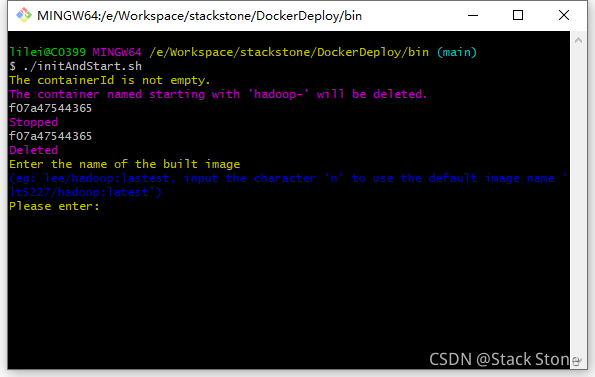
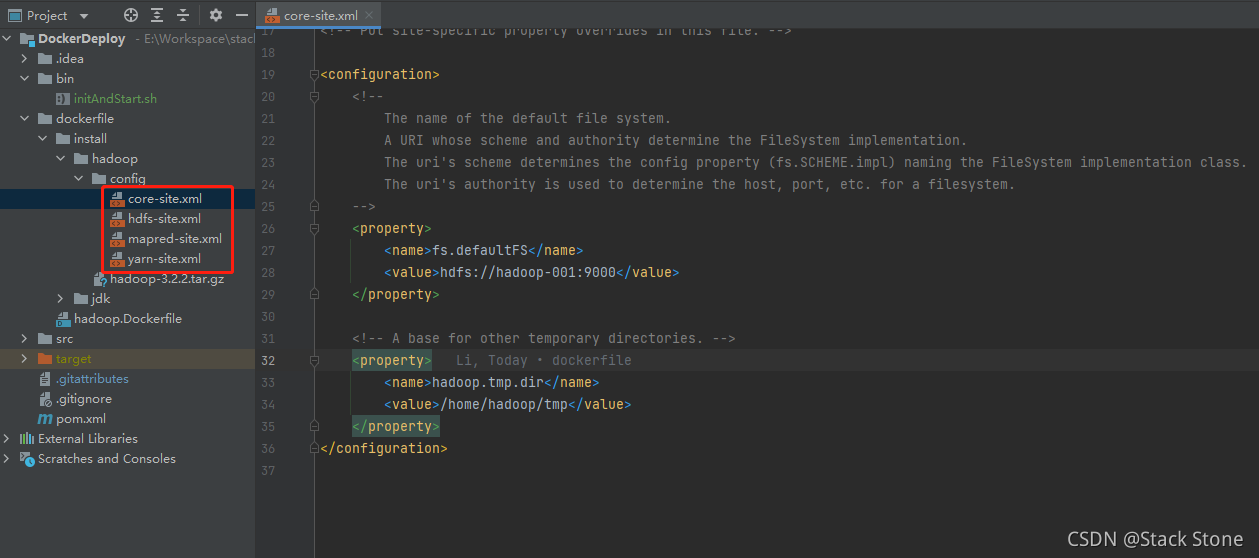
脚本首先会停止并删除hadoop-开头命名的Docker容器,之后会让输入你构建的镜像名称,如果输入n默认使用lt5227/hadoop:latest来命名,当然如果镜像名称重复也还是会删除已有的镜像的。脚本如果执行成功,本地访问 http://localhost:9870/ 就可以看到UI页面了,大家可以根据自己的需求对脚本进行修改,或者修改Dockerfile,或直接进入容器更改配置,初始化镜像时使用的Hadoop配置在项目的dockerfile/install/hadoop/config目录下,如下图所示:
通过Java程序初始化镜像并启动
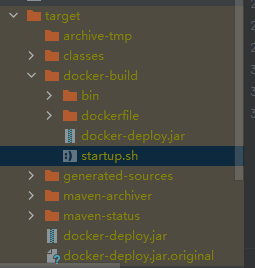
项目中编写了Java程序,来替代脚本执行整个流程,该程序支持启动集群,我们可以将项目打包,进入生成的target目录下的docker-build目录,运行startup.sh即可帮助我们自动构建Docker镜像并启动容器,大体流程和脚本的启动流程一致,大家运行的时候可以根据信息提示来完成初始化构建。如果有兴趣的话,该项目也就抛砖引玉,大家可以自己重新定义整个执行流程。


















 886
886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











