







 本文详细介绍了AlphaGo强化学习的过程,包括模仿学习、策略网络和价值网络的学习等关键步骤。并探讨了AlphaGo如何利用蒙特卡洛树搜索提高围棋水平。
本文详细介绍了AlphaGo强化学习的过程,包括模仿学习、策略网络和价值网络的学习等关键步骤。并探讨了AlphaGo如何利用蒙特卡洛树搜索提高围棋水平。
以 AlphaGo模型来讲解在实际应用中如何使用强化学习。此处笔记根据B站课程,王树森老师的强化学习记录而来。5.深度强化学习(5_5):AlphaGo(Av374239425,P5)_哔哩哔哩_bilibili

1.AlphaGo 强化学习
可分为三个步骤:(这里的策略学习和价值学习并不是同时学习的,而是分布学习的,所以不是actor-critic)
| 模仿学习 | 多分类,监督学习 |
| 强化学习,策略学习 | 学习一个策略网络 |
| 强化学习,价值学习 | 学习一个价值网络,使用蒙特卡洛树搜索 |

AlphaGo的实际执行过程中,使用的是MCTS蒙特卡洛树搜索,策略网络和价值网络的训练是为了确定有价值的搜索。
最开始的AlphaGo下围棋使用19*19*48种状态,最新的使用19*19*17。这里是17可以解释为,白子最近8步的状态矩阵,黑子的最近8步的状态矩阵,还有一个是将要执行的状态,若是白字则全0,黑子则全1.
输出是19*19=361维的概率分布,最后一层是softmax。19*19*48中全部使用卷积层,没有全连接层,输出361维的概率。
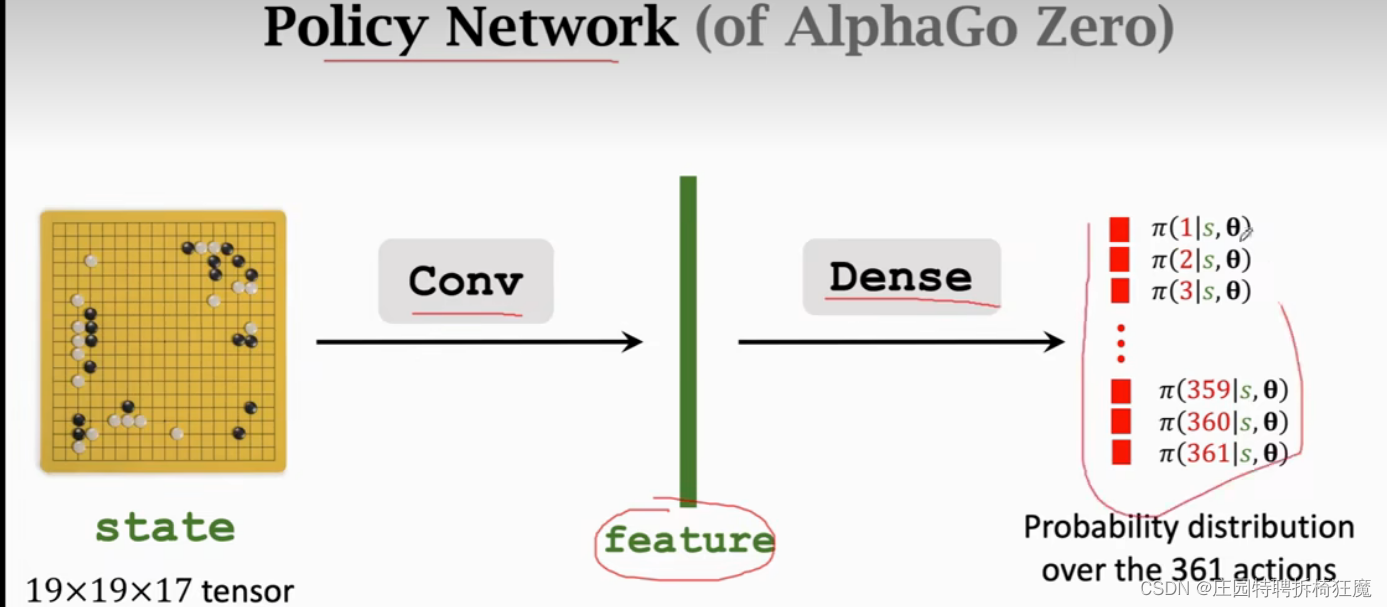

2.Behavioral Cloning模仿学习
 Initialize Policy Network by behavior cloning 使用模拟学习来初始化策略网络。
Initialize Policy Network by behavior cloning 使用模拟学习来初始化策略网络。
如果使用随机初始化,纯随机的初始化,强化学习的摸索过程比较长,使用模拟学习,使用人类知识预训练,可以减少摸索时间。
Behavioral Cloning不是强化学习,它和强化学习的最本质的区别是强化学习有reward,而模仿学习没有。它知识强化学习的替代品,实质是分类和回归一类,可以看作是多分类问题,其结果是动作的概率分布,真实的动作是at就是ground truth。
观测到真实的动作a*(t)时,eg:a*(t)=281,将其编码维one-hot向量,将真实值与预测值计算loss,可以使用交叉熵损失,使用梯度下降,较少loss,使预测值靠近真实值。
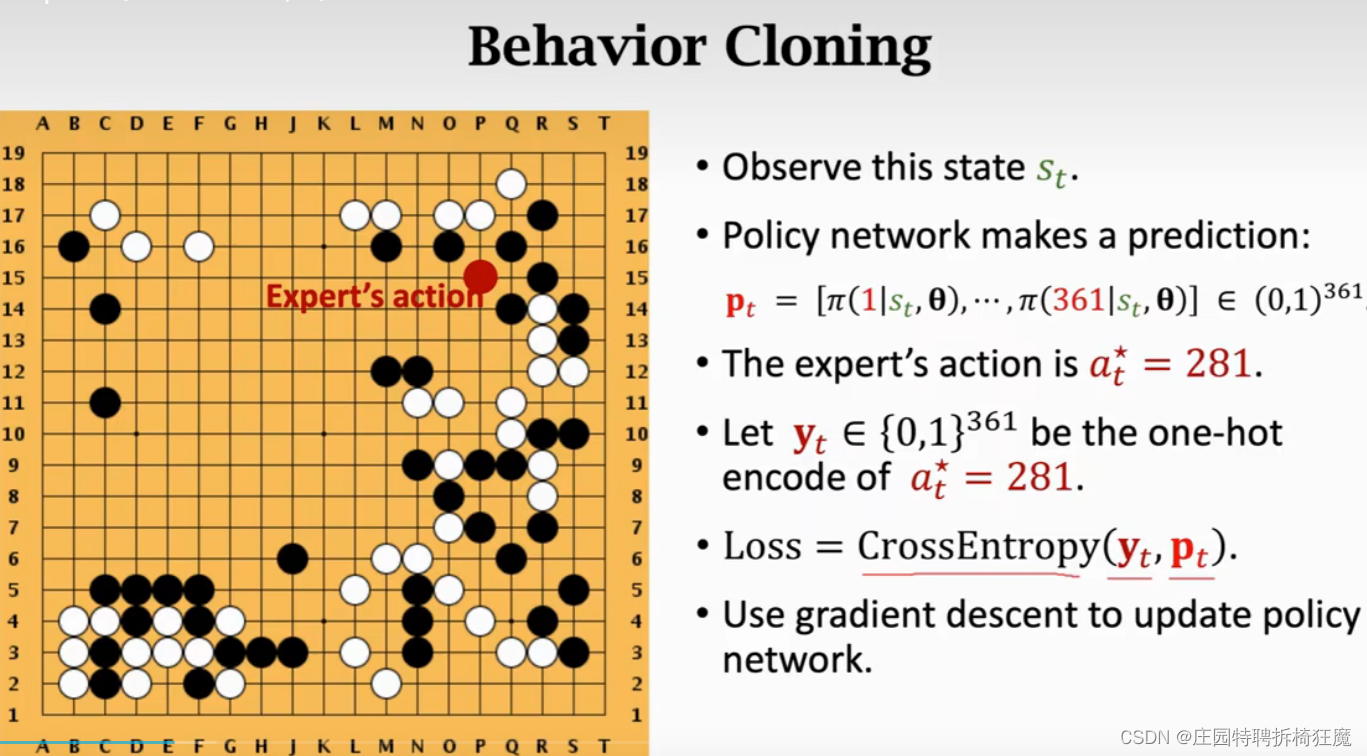
在Behavioral Cloning之后,该网络可以打败一个小白玩家。只要网络见过状态s(t)他就表现的很好,为什么要使用强化学习,因为当Behavioral Cloning训练的网络遇到没见过的s(t)时,就会做出糟糕的操作,且错误会累积,使结果更加糟糕。围棋的状态比较多,Behavioral Cloning不能收集所有s(t),故引入强化学习,且Behavioral Cloning+RL有80%的可能性能应付仅有Behavioral Cloning的失误。
3.训练策略网络Policy Network
AlphaGo使用两个Policy Network对弈,其中一个是Player,相当于agent,一个是opponent,相当于environment,在训练时,更新Player的参数,Opponent的参数不更新,仅作辅助训练的功能。

Behavioral Cloning和Policy Network的区别在于,Behavioral Cloning是纯粹的模仿,强化学习靠奖励更新。
reward是如何定义的?在博弈过程中,没结束之前,reward都是0,在结束时,赢得到reward=1,输得到reward=-1。
回忆u(t),这里不考虑折扣。赢得比赛时,u1=u2=……=u(t)=+1,每一步的操作都是好的。输了比赛时,u1=u2=……=u(t)=-1,每一步的操作都是坏的。每一步的u(t)同等对待,获得相同的回报。
 4.策略梯度Policy Gradient
4.策略梯度Policy Gradient
 使用u(t)近似QΠ(s(t),a(t))的值,u(t)只有一局游戏结束时才知道,梯度求解时,是logΠ对θ的导数。
使用u(t)近似QΠ(s(t),a(t))的值,u(t)只有一局游戏结束时才知道,梯度求解时,是logΠ对θ的导数。
 计算gθ,使用策略上升,更新player。 训练好了Π,之后观测到s(t),Π分句st随机抽样选择a(t)。经过策略学习以后,AlphaGo已经很强了,但它不是很稳定,还不够好。
计算gθ,使用策略上升,更新player。 训练好了Π,之后观测到s(t),Π分句st随机抽样选择a(t)。经过策略学习以后,AlphaGo已经很强了,但它不是很稳定,还不够好。

5.价值网络训练
通过价值网络的训练,选择有益的蒙特卡罗搜索,使得AlphaGo表现更加稳定。
这里的价值学习是近似V而不是近似q函数。V是回报u(t)的条件期望,只依赖于A和S.期望消除了A和S外的随机变量的依赖。

蒙特卡洛树搜索需要V的辅助,v(s,w)价值网络对当前状态打分,评价当前状态好不好,胜算大不大。AlphaGo的策略网络和价值网络是分开训练的,先训练策略网络后训练价值网络,所以不是actor-critic,但是策略网络和价值网络可以共享一些卷积层的参数。
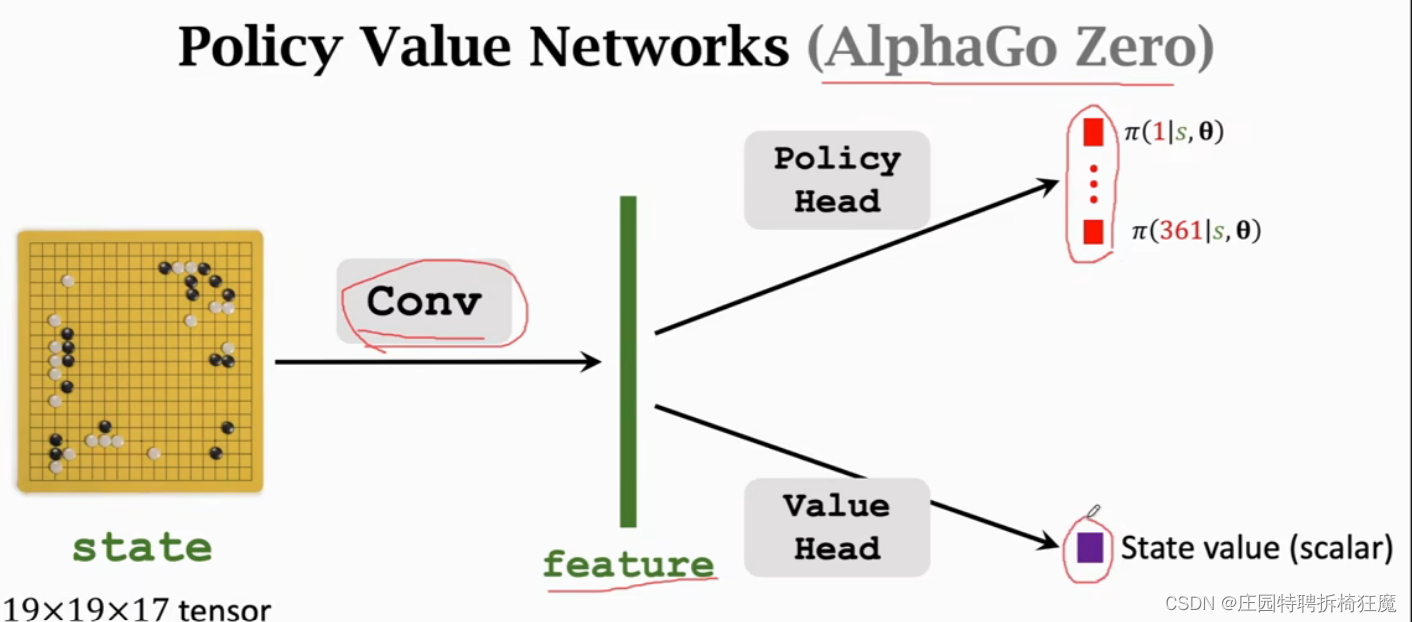
价值网络的训练过程中任然是两个策略网络进行博弈,在一局结束后,loss定义为v(s(t);w)和u(t)的差的平方的累积。根据loss更新w,使用梯度下降,降低loss的值。

此时强化学习结束:初步学习 策略学习 价值学习
6.蒙特卡洛树搜索
select actions by look-ahead search

AlphaGo在具体决策时使用蒙特卡罗树搜索,之前的训练就是为了辅助蒙特卡洛树搜索寻找有意义的搜索。蒙特卡罗树本身不需要训练,它的本质是几个可行的走法,几步后会占优势,即走一步看三步,未来发生的事情取决于现在的动作。
过程大致如下:选出一个动作a,根据概率可以选出好的动作,排除不好的动作;随后策略网络进行自我博弈,价值网络进行打分;重复上述步骤;选出得分高的动作进行执行。
Selection Expansion Evaluation Backup

Selection:
观测到状态s(t),有多个actions可以选择,随机选择一个action,这个action并不会真的去做这个动作,对着个动作打分score(a)=动作价值Q(a)+系数*价值得分
其中1+N(a)是为了避免重复探索,刚开始的时候价值得分由Π决定,搜索次数多了之后,1+N(a)的值会升高,得分就变得很小了,Π 的影响就变小了。价值得分的部分,动作越好,得分越高,则价值就越高。

Expansion:
上一步骤选择的a(t)是假想动作,并没有真正执行,opponent假想动作a'(t),是opponent的策略网络根据Π‘(.|s'(t);θ)随机抽样来的,下一状态维s(t+1).
对手相当于环境,环境的状态转移函数是不知道的,使用对手的策略网络代替价值状态转移函数。

Evaluation:
自我博弈分出胜负后,获得奖励r(t),评价s(t)的好坏。价值网络评价s(t+1),V(s(t+1);w)评价胜算大小。重复很多次,a(t)由很多分数,求均值作为分数,反应s(t)的好坏。

Backup:
Q(a(t))评价a(t)的好坏,第一步选择时需要
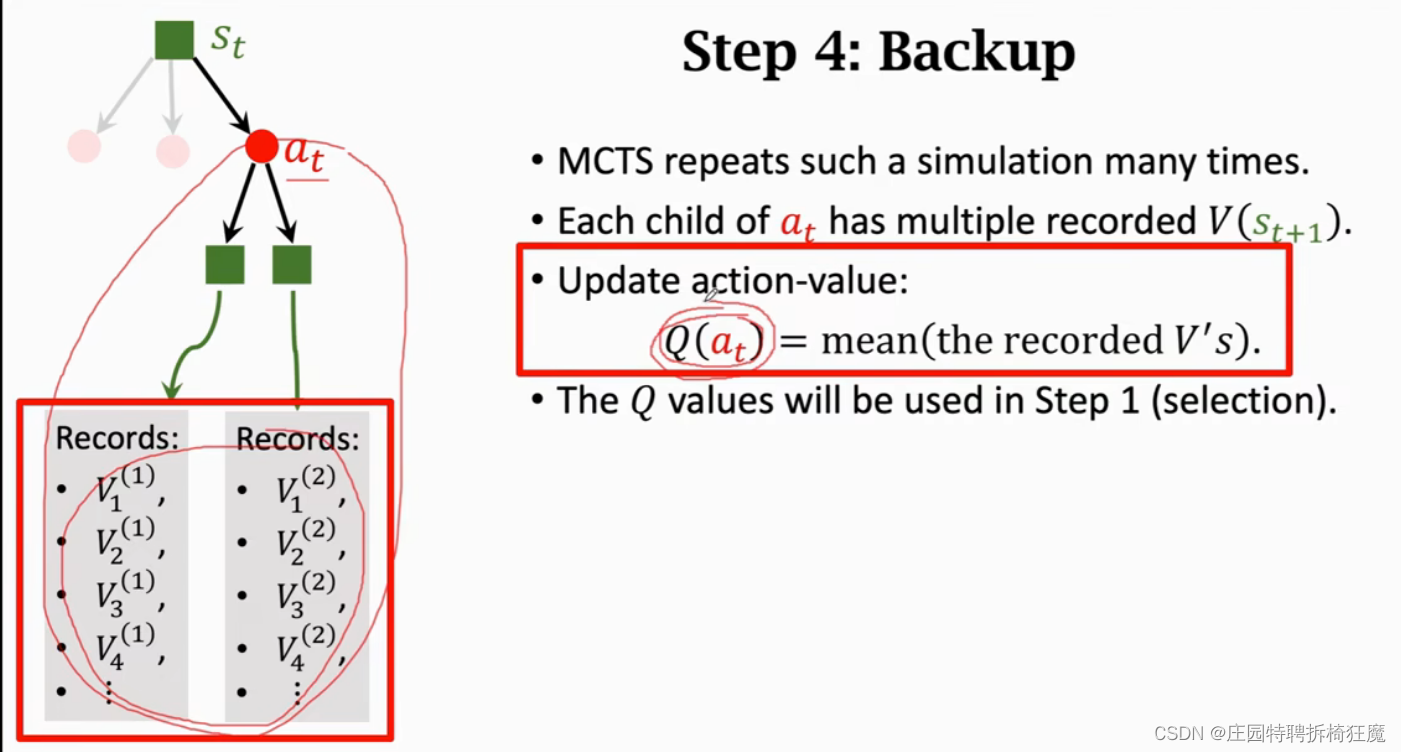
根据s(t)选a(t),用Q和Π的分数加权选择at,Q是主要决策者,Π是一开始的策略网络。N(a)表示a被选中的次数,反应a的好坏。重复多次at=argmax a N(a).
总结:选择一个动作,一次模拟,Q(a),N(a)的分数初始化为0 ,重复多次,选择分数高的a进行执行。蒙特卡洛树搜索走一步进行多个模拟搜索。



7.Summary

7.AlphaGo Zero VS AlphaGo
AlphaGo Zero是AlphaGo的新版本。zero版本没有behavioral Cloning,直接进行强化学习,在这个例子中,人类知识反而是有害的。但是behavioralCloning总是有害的吗?并不是这样的,在物理世界中,直接使用强化学习是有代价的,当代价过大时,引入人类知识进行behavioral cloning就能弥补代价大的问题。

策略网络学习的不同,老版本模拟人类玩家,新版本模拟蒙特卡洛树搜索。
Zero版本是怎么使用蒙特卡洛树搜索的呢?


















 1180
1180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









