








目录
🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支持一下,感谢🤗!
其他优质专栏: 【🎇SpringBoot】【🎉多线程】【🎨Redis】【✨设计模式专栏(已完结)】…等
如果喜欢作者的讲解方式,可以点赞收藏加关注,你的支持就是我的动力
✨更多文章请看个人主页: 码熔burning
前言
大家好!👋 作为一个优秀的程序员,我们每天都在和 MySQL 打交道。我们写 SQL 语句,创建表,优化查询… 但你是否好奇过,当我们敲下回车键,一条 SQL 语句在 MySQL 内部究竟经历了什么?🤔 了解 MySQL 的内部结构,能帮助我们更好地理解性能问题,找到优化的方向。
今天,我们就来一起揭秘 MySQL 的内部组件结构,看看一条 SQL 查询是如何一步步被执行的!🚀
MySQL 的两层架构:Server 层与存储引擎层 🏢↔️📦
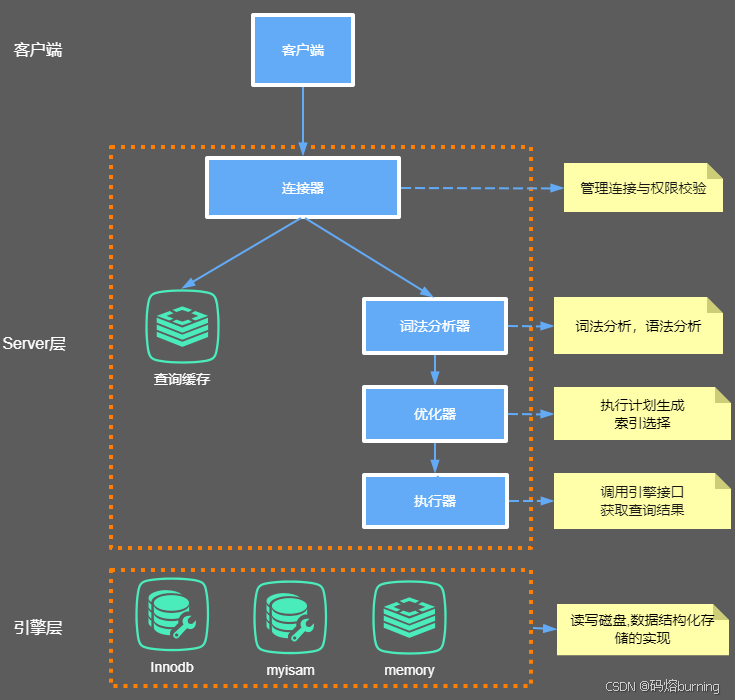
大体来说,MySQL 的架构可以分为两个主要层:
- Server 层: 这是 MySQL 的“大脑”和“指挥中心”。🧠 它负责处理客户端连接、查询解析、优化、缓存、以及所有的内置函数(比如我们常用的
NOW()、COUNT()等),还有存储过程、触发器、视图等跨存储引擎的功能。可以理解为,Server 层处理所有与具体数据存储方式无关的通用服务。 - 存储引擎层: 这是 MySQL 的“仓库”和“搬运工”。📦 它负责实际的数据存储和提取。MySQL 的一个强大之处在于它的存储引擎是插件式的,你可以选择不同的存储引擎来满足不同的需求。目前最常用也是 MySQL 默认的存储引擎是 InnoDB(从 MySQL 5.5.5 版本开始)。当你创建表时如果不指定存储引擎,默认就是 InnoDB。常见的还有 MyISAM, Memory 等。
这两层之间通过一套标准的 API 进行通信。Server 层接收到请求后,会调用存储引擎层提供的接口来完成数据的操作。
所以,Server 层负责“做什么”和“怎么做最优”,存储引擎层负责“怎么存”和“怎么取”。是不是清晰多了?😊
深入 Server 层:SQL 执行的“流水线” 🏭
现在,让我们把目光聚焦到 Server 层,看看一条 SELECT 语句是如何在其中“流转”并最终返回结果的。Server 层的主要组件就像一条精心设计的流水线,各司其职:
连接器 -> 查询缓存 -> 分析器 -> 优化器 -> 执行器
下面我们就逐一揭开它们的面纱!
1. 连接器:欢迎光临,请出示您的“门票” 🤝
当你使用各种客户端工具(Navicat, SQLyog, JDBC 等)连接到 MySQL 数据库时,第一个接待你的就是连接器 (Connector)。
连接器负责以下工作:
- 建立连接: 完成经典的 TCP 握手,建立客户端与 Server 端的通信链路。
- 身份认证: 校验你提供的用户名和密码。如果不对,直接给你一个
Access denied的错误,连接也就中断了。🚪 - 获取权限: 如果用户名密码正确,连接器会去数据库的权限表(如
mysql.user,mysql.db等)查询你这个用户拥有的权限。
一个关键点: 连接器在完成权限查询后,会将这个连接的权限信息缓存起来。这意味着,在一个连接的生命周期内,即使管理员修改了这个用户的权限,已经建立的连接的权限也不会立刻改变! 新的权限只会在用户下次建立新连接时生效。这一点在做权限管理和排查问题时非常重要哦!📝
你可以使用这样的命令来连接 MySQL:
mysql -h host[数据库地址] -u root[用户] -p root[密码] -P 3306
这里的 mysql 就是客户端工具,它通过连接器与 Server 端建立通信。
2. 查询缓存:记忆碎片,效率陷阱? 🤔
连接建立后,如果你执行的是 SELECT 语句,执行流程会来到查询缓存 (Query Cache)。
MySQL 会在这里看看,之前是否执行过完全相同的 SQL 语句。如果找到,并且缓存结果有效,就会直接把缓存的结果返回给客户端。这样做的好处是显而易见的:跳过了后续复杂的步骤,效率非常高!🚀
缓存的 key 是查询语句本身,value 是查询结果。
然而,理想很丰满,现实很骨感!💔
查询缓存往往是个“鸡肋”,这是为什么呢?
原因就在于:查询缓存的失效非常频繁! 只要对任何一个表进行了更新(INSERT, DELETE, UPDATE),所有涉及到这个表的查询缓存都会被全部清空!😲
想想看,在一个读写混合的应用中,数据更新是很常见的。你刚把一个查询结果缓存起来,还没来得及用几次,可能就被一个更新操作清空了。这投入产出比也太低了!📉 而且,MySQL 维护查询缓存本身也是需要消耗资源的。
所以,对于更新压力大的数据库来说,查询缓存的命中率会非常低,开启它反而可能带来负面影响。
何时使用?
查询缓存更适合静态表,也就是那些极少更新的数据表,比如配置表、字典表等。
如何“按需使用”?
MySQL 提供了 query_cache_type 参数来控制查询缓存的行为:
[mysqld]
# query_cache_type 参数有3个值:
# 0 (OFF): 关闭查询缓存
# 1 (ON): 开启查询缓存,所有查询都尝试缓存,除非使用 SQL_NO_CACHE
# 2 (DEMAND): 默认不缓存,只有在 SQL 语句中包含 SQL_CACHE 关键字时才缓存
query_cache_type=2
当你设置 query_cache_type=2 时,只有像这样明确指定 SQL_CACHE 的语句才会使用查询缓存:
SELECT SQL_CACHE * FROM test WHERE ID = 5;
重要提示: 在 MySQL 8.0 版本中,查询缓存功能已经被彻底移除了! 所以如果你使用的是 8.0 或更高版本,就不用考虑查询缓存了。👍
你可以通过以下命令查看当前 MySQL 实例的查询缓存是否开启:
SHOW GLOBAL VARIABLES LIKE "%query_cache_type%";
3. 分析器:读懂你的“语言” 📖
如果查询缓存没有命中,或者查询缓存已关闭,接下来就进入分析器 (Parser) 阶段。分析器的任务是理解你输入的 SQL 语句到底是什么意思。
分析器主要做两件事情:
- 词法分析 (Lexical Analysis): 将你输入的 SQL 语句字符串分解成一个个有意义的“词法单元” (tokens)。就像我们读句子,先认出每个字、每个词。比如
SELECT * FROM test WHERE id = 1;,分析器会识别出SELECT是关键字,*是通配符,FROM是关键字,test是表名,WHERE是关键字,id是列名,=是运算符,1是数值。📜 - 语法分析 (Syntax Analysis): 根据 MySQL 的语法规则,检查这些词法单元的组合是否构成一个合法的 SQL 语句。就像检查句子是否符合语法规则。如果语法不对,你就会收到一个
You have an error in your SQL syntax的错误。❌
把 FROM 写成了 fro,语法分析器就会报错:
mysql> select * fro test where id=1;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right use near 'fro test where id=1' at line 1
经过词法分析和语法分析后,分析器会生成一个内部的语法树 (Syntax Tree),这棵树代表了 SQL 语句的结构和含义,方便后续的组件进行处理。🌳就像这样:
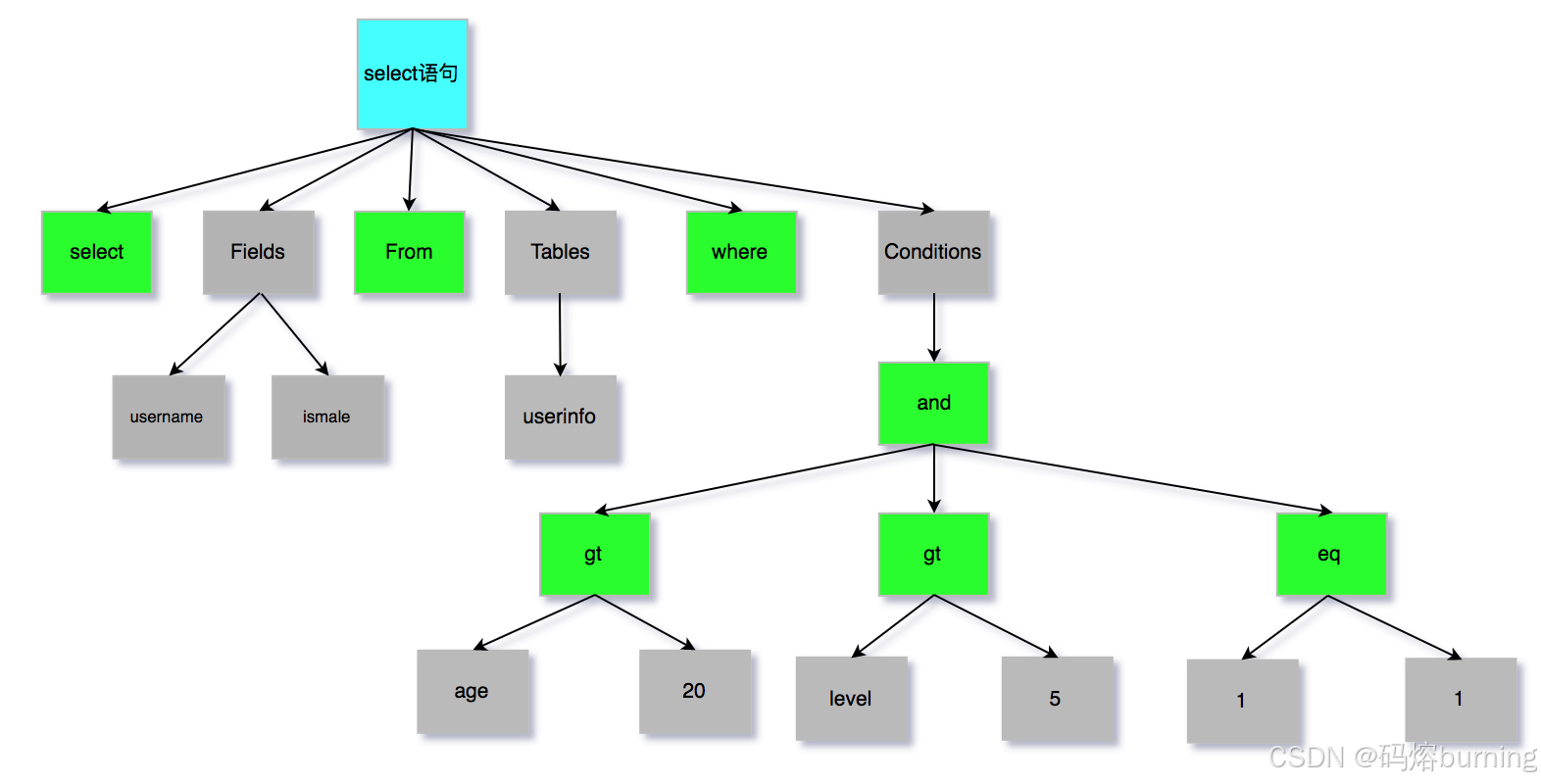
至此,分析器的工作就完成了,MySQL 已经完全理解了你要干什么。
4. 优化器:制定最佳“执行计划” 🗺️
了解了你要干什么后,接下来就进入优化器 (Optimizer) 阶段。优化器是 MySQL 的“智囊团”,它的任务是找出执行这条 SQL 语句的最优方案。制定执行计划的过程非常复杂,考虑的因素也非常多。
优化器会做很多决策,比如:
- 索引选择: 如果一个表上有多个索引,哪个索引能最快地找到你需要的数据?🧐
- 多表连接顺序: 如果一个查询涉及到多个表的 JOIN,以什么样的顺序连接这些表效率最高?先连接 A 再连接 B,还是先连接 B 再连接 A?🔄
- 其他优化: 比如是否可以使用覆盖索引、是否需要创建临时表、是否可以进行条件下推等等。
优化器会根据统计信息(比如表的大小、索引的选择性等)和复杂的算法,生成一个或多个可能的执行计划,然后选择成本最低(通常是预计读盘次数最少)的那个。
理解优化器的行为对于性能调优至关重要。我们可以使用 EXPLAIN 命令来查看优化器为一条 SQL 语句生成的执行计划。🕵️♀️
5. 执行器:按照计划“行动”! 🏃♂️
经过优化器确定了执行计划后,就轮到执行器 (Executor) 出场了。执行器负责按照优化器生成的执行计划,真正地去执行查询。
执行器首先会进行权限校验。再次检查你对要操作的表是否有执行相应操作(例如 SELECT)的权限。如果在这个阶段发现没有权限,也会返回错误。🚫(注意:如果在查询缓存命中时,权限校验是在返回结果前进行的)。
如果权限通过,执行器就会打开表,并根据优化器指定的执行计划,调用存储引擎层提供的 API 接口来获取数据。
举个例子,如果执行器发现要查询的数据需要走某个索引,它就会调用存储引擎的索引读取接口;如果需要全表扫描,它就会调用存储引擎的扫描接口。📦
执行器获取到数据后,会根据查询的要求进行过滤、排序、分组等操作(如果这些操作优化器没有下推给存储引擎处理),最后将结果返回给客户端。🎉
至此,一条 SQL 查询的完整旅程就结束了!
总结:理解流程,事半功倍! 💪
通过了解 MySQL Server 层的这几个核心组件以及它们之间的协作流程:
连接器负责接入 -> 查询缓存尝试快速返回 -> 分析器理解意图 -> 优化器制定计划 -> 执行器调用存储引擎执行
我们就能更清楚地知道一条 SQL 语句在数据库内部是如何被处理的。这对于我们排查慢查询、理解为什么某些查询走了某个索引、或者为什么查询缓存没有生效等问题非常有帮助!
理解这些内部机制,就像是拿到了 MySQL 的“使用说明书”,能让你更有效地进行数据库设计和优化。🛠️
希望这篇文章能帮助你对 MySQL 的内部组件结构有一个清晰的认识!如果你有任何问题或想法,欢迎在评论区留言,一起学习,一起进步!👇
下次写 SQL 的时候,不妨在脑海里过一遍这条“流水线”吧!😄

















 54万+
54万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









