







习作-知乎收藏夹观察者(上)
爬虫能作什么呢, 来看看这位同学的实用创意
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。
作者:伍新生
链接:http://www.zhihu.com/question/27621722/answer/37636385
来源:知乎
我是个.NET程序猿,有一天女神告诉我有一个很不错的社区叫“知乎”,我经常一过来就看到她在看知乎,但每次我想看她都看了啥啊,她就遮住屏幕不让我看。于是乎,在我心里埋下了一颗强烈的好奇心。知乎中搜了下她的名字,经过各种筛选知道了她的知乎空间。第一时间出现的想法是我要写个监测程序,她关注的所有问题我都想知道。连续奋战5小时,至凌晨3点程序终于写出来了。主要HttpWebRequest加正则表达式来抓取数据,程序开机自动运行,数据库设在一台24小时开机的服务器上。多个监测客户端同时运行,公司的,家里的,远程服务器上的。每隔5分钟自动循环读取一次数据,如果检测到关注了新的问题,立马将它们发送至我的QQ邮箱和我的163邮箱,大家都知道QQ邮箱有提醒功能,一发过来,立马会弹出一个窗体告诉你有新的邮件。手机qq客户端也有,所以不管我是在上班的路上,还是在电脑旁,只要她有新动态我立马就知道了。是不是很酷?监测程序已经运行三个多月了,收集了他二三百个关注的问题,我知道她一般都是吃中饭或者晚饭前喜欢看一下知乎,晚上睡前会看会,她睡得早但偶尔凌晨1点多还看知乎。她关注情感类的问题最多,而且那段时间我一直在追她,所以我能根据她关注的问题来推测她的一些想法,包括约会聊天时我可以聊一些她感兴趣的话题。所以实用性还是比较强的。假如某一天凌晨1点,手机突然响了一下,发现她关注了某个问题。立马给她发一条短信过去,你是不是还没睡啊? 是啊,你怎么知道我没睡的? 凭感觉! 嘿嘿。 然后慢慢靠近她关注的那个话题去聊,这是不是会让她感觉到你特别懂她。好奇你居然知道她睡没睡,好奇你和她聊的话那么符合她的心声。
怎么样,这功能是不是炒鸡好用啊,心动了吧,心动不如行动,作为依然单身的一只小狗, 我立马就想着自己作一个了,but, 我一个搞Android的,这方面实在不大擅长,不过有道是’有志者事竟成’, 不妨试试吧.
首先我们来分解下这个任务
- 核心部分:爬虫获取html页面
- html文档解析
- 数据持久化:数据库技术
- 程序发送通知邮件
技术选择, 这里选了更高效的python作为编程语言, 数据库用mysql, 写完程序后放在centOS上面一直运行. 为了快速起步, 不妨先简化下需求,只观察收藏夹的变化即可,下面是测试用的目标页MY Zhihu
核心部分:爬虫获取html页面
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地。
类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求的内容发送到服务器端, 然后读取服务器端的响应资源。
在Python中,我们使用urllib2这个组件来抓取网页。
urllib2是Python的一个获取URLs(Uniform Resource Locators)的组件。
下面给个最简单的例子:
import urllib2
req = urllib2.Request('http://www.zhihu.com')
response = urllib2.urlopen(req)
the_page = response.read()
print the_page这个很简单,就是把页面的html拿到了,再看我们的目标页面,这个结果已经够用了,拿到页面后如何分析html文档呢, 用字符串方法找效率低下了点吧
html文档解析
这里我用了Beautiful Soupp这个库, 主要是让解析html能像css选择器那样方便,下面是它的文档Beautiful Soup
有了这些我们就可以写出一个小型的demo了,下面的代码能把收藏夹打印出来了
from bs4 import BeautifulSoup
import re
import urllib
import urllib2
url = 'http://www.zhihu.com/people/shang-en-jing/collections'
class Collection:
def __init__(self,id,name,answer_num,watch_num):
self.id=id
self.name=name
self.answer_num=answer_num
self.watch_num=watch_num
def __repr__(self):
return 'id:%d,name:%s,answer:%d,watch_num:%d' % (self.id,self.name,self.answer_num,self.watch_num)
class Answer:
def __init__(self,id,title,collection_id):
self.id=id
self.title=title
self.collection_id=collection_id
def __repr__(self):
return 'id:%d,title:%s,coll_id:%d' % (self.id,self.title,self.collection_id)
req = urllib2.Request(url)
response = urllib2.urlopen(req)
the_page = response.read()
soup = BeautifulSoup(the_page,'html5lib')
collection_list = soup.find_all('div', class_='zm-profile-section-item zg-clear')
for collection in collection_list:
fav_title = collection.find('a', class_='zm-profile-fav-item-title')
fav_id = fav_title['href'][len('/collection/'):]
col_title = fav_title.contents[0].encode('utf8')
num_info_str =''.join(collection.find('div',class_='zm-profile-fav-bio').strings)
answer_num=int(re.findall(r'\d+',num_info_str)[0])
watch_num=int(re.findall(r'\d+',num_info_str)[1])
col=Collection(int(fav_id),col_title,answer_num,watch_num)
print col
下面是输出结果:
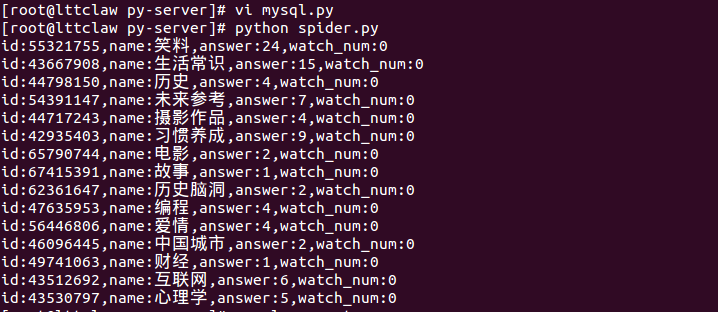
数据持久化:数据库技术
这部分主要包括两个面:
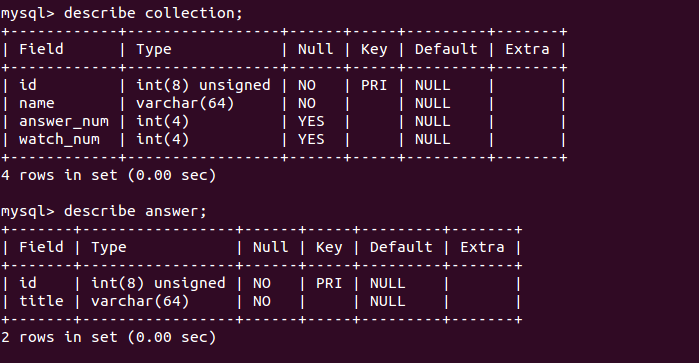
- 分析要存储的数据结构,在mysql上先把表建好,省点事儿
- 用python连接mysql的connector使用技术
首先, 分析知乎的收藏夹,其实就两种东西, 收藏夹和答案,所以建两个表collection和answer,暂时先只加最重要的字段,SQL代码就不贴了,忘了搜一下就有了
然后就是用python连接mysql, 这个也不难,连接数据库的技术都大同小异的,下面是个最简单的demo,拿到cursor以后用execute执行SQL命令就可以啦,所以到这一步这一点也可以打通的
#!/usr/bin/python
# -*- coding: utf-8 -*-
import MySQLdb as mdb
import sys
try:
con = mdb.connect('localhost', 'root', 'yourpwdhere', 'zhihudb');
cur = con.cursor()
cur.execute("SELECT VERSION()")
ver = cur.fetchone()
print "Database version : %s " % ver
except mdb.Error, e:
print "Error %d: %s" % (e.args[0],e.args[1])
sys.exit(1)
finally:
if con:
con.close()
结果:

我们可以稍微改进下这个demo,让它能插入数据,改进如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import MySQLdb as mdb
import sys
def exeSQL(sql):
try:
con = mdb.connect('localhost', 'root', 'yourdbpwd', 'zhihudb')
cur = con.cursor()
cur.execute(sql)
con.commit()
except mdb.Error, e:
print "Error %d: %s" % (e.args[0],e.args[1])
con.rollback()
sys.exit(1)
finally:
if con:
con.close()
def insertCollection(id,name,answer_num,watch_num):
sql = 'insert into collection values(%d,"%s",%d,%d);' % (id, name,answer_num,watch_num)
exeSQL(sql)
如此一来,只要引入这个模块再调用insertCollection方法就能把数据插入数据库了也
程序发送通知邮件
最后这步也很容易, 一般这种功能是要有一个使用smtp协议的电子邮箱, qq邮箱,网易邮箱什么的去后台设置一下把协议打开就可以用了,下面是一个简单的demo,把这个代码本身发送给了两个qq邮箱用户
#! /usr/local/bin/python
SMTPserver = 'smtp.126.com'
sender = 'yonyou_hr@126.com'
destination = ['ltxxxxw@qq.com', '6xxxxxxxx0@qq.com']
USERNAME = "your_usrname"
PASSWORD = "your_pwd"
# typical values for text_subtype are plain, html, xml
text_subtype = 'plain'
with open('mailsender.py') as source_file:
content = source_file.read()
subject = "Sent from Pycharm, lttclaw"
import sys
# from smtplib import SMTP_SSL as SMTP # this invokes the secure SMTP protocol (port 465, uses SSL)
from smtplib import SMTP # use this for standard SMTP protocol (port 25, no encryption)
from email.mime.text import MIMEText
try:
msg = MIMEText(content, text_subtype)
msg['Subject'] = subject
msg['From'] = sender # some SMTP servers will do this automatically, not all
conn = SMTP(SMTPserver)
conn.set_debuglevel(False)
conn.login(USERNAME, PASSWORD)
try:
conn.sendmail(sender, destination, msg.as_string())
finally:
conn.close()
except Exception, exc:
sys.exit("mail failed; %s" % str(exc)) # give a error message测试一下,这部分也搞定了,那么接下来就是”connecting the dots”了,哈哈, 把这些技术衔接起来完成这个任务,应该就比较明了,不过目前我还没开始,先写到这里,有兴趣的伙伴们可以先搞起了.















 1936
1936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









