






一、简单回顾下HDFS的架构
如果不了解HDFS的可以看下我写的一篇博客<Hadoop-HDFS概览>,这里先贴下官网架构图:
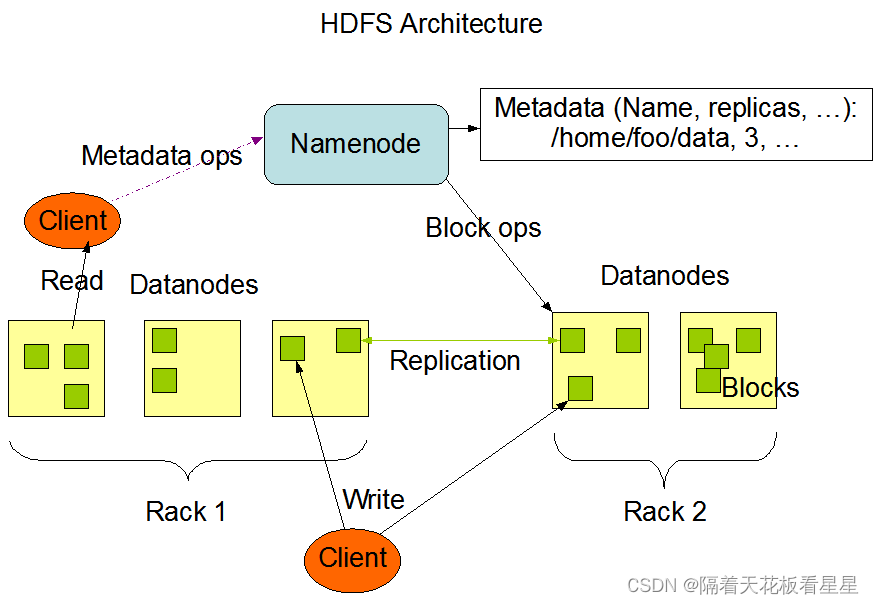
二、源码分析
源码中写的肯定是最真实的,下面是hadoop官方源码下载地址,我下载的是hadoop-3.2.4,那就一起来看下吧
1、命令行
我们以命令行向HDFS上传一份数据为例,即:
hadoop fs -put test.txt /user/hhs/test_dir
我们以 -put 为例看看它背后执行了什么,我们先看下hadoop命令

fs 对应的是 运行一个通用文件系统用户客户端,我们用more命令看下hadoop命令里面的实现
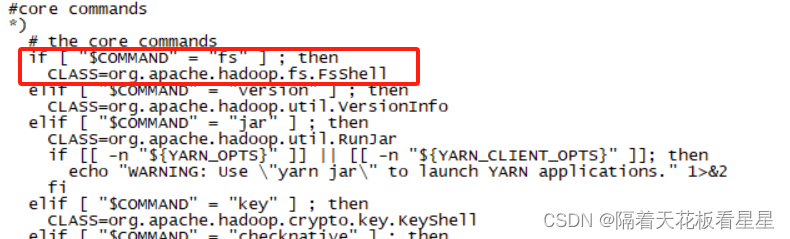

最后用java命令执行($@:表示获取执行脚本传入的所有参数)
我们去源码里面看下 org.apache.hadoop.fs.FsShell
2、FsShell
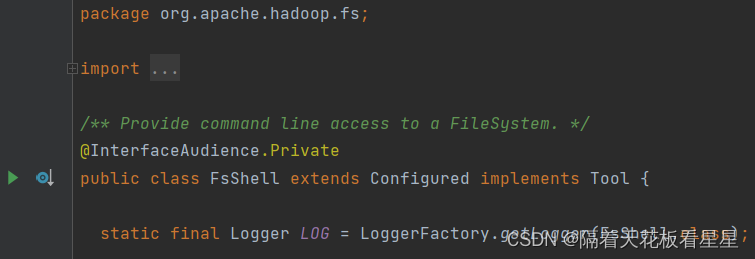
注释:提供对文件系统的命令行访问
我们查看细main方法并跟一下(如果跳一次截图下太多了,这里和后面只截重要的地方)

设置调用者和Configuration并解析命令行参数 例如 [fs,-cat,/user/hhs/test.txt]
Configuration提供了对配置参数的访问,比如读取搭建集群时的配置的core-site.xml
调用tool.run(toolArgs)

接着调用的是org.apache.hadoop.fs.shell.Command.run(String...argv)
3、Command

方法注释为:调用命令处理程序。默认行为是处理选项、展开参数,然后处理每个参数。
//处理命令行标志并检查其余参数的边界。如果抛出IllegalArgumentException,FsShell对象将打印该命令的简短用法。
//调用子类实现,下面看下org.apache.hadoop.fs.shell.Put.processOptions(args)
processOptions(args);
//注释中已经给出了路径的走向,我们直接跳过去
processRawArguments(args);

4、CopyCommands-Put
CopyCommands包括了需要复制文件的命令如:-cp、-get、-put、-getmerge、-copyFromLocal、-copyToLocal
Put类注释:将本地文件复制到远程文件系统
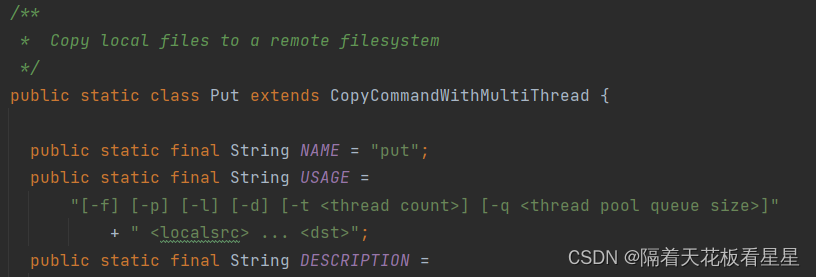
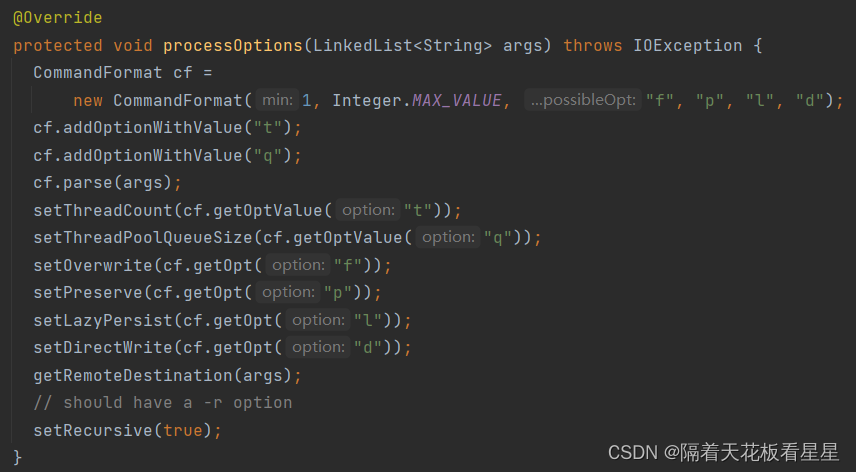
接着看下getRemoteDestination(args);
5、CommandWithDestination

构建PathData(类注释:封装路径(Path)、文件状态(stat)和文件系统(fs)。PathData确保返回的路径字符串与初始化期间传入的路径字符串相同(与可以修改路径字符串的path对象不同)。如果路径不存在,则stat字段将为null。)
根据命令中最后一个参数(/user/hhs/test_dir)构建PathData
6、再回Command
现在看processRawArguments(args);最终调的是Command的processPath(PathData item)

Hook 是“钩子”的意思,在程序中可以理解为“代理”,用代理对象替换为原有对象,也可以理解为偷梁换柱。
7、再回CommandWithDestination
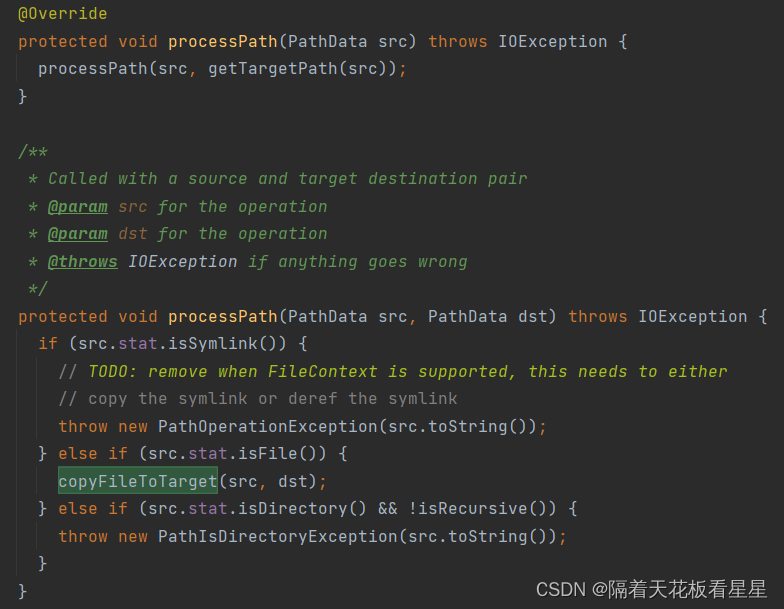
方法注释:如果禁用直接写入,则将流内容复制到临时文件“target_COPYING_”。如果复制成功,则临时文件将重命名为实际路径,否则将删除临时文件。如果启用了直接写入,则跳过创建临时文件。
接着看 copyFileToTarget(src, dst); //将源文件复制到目标。
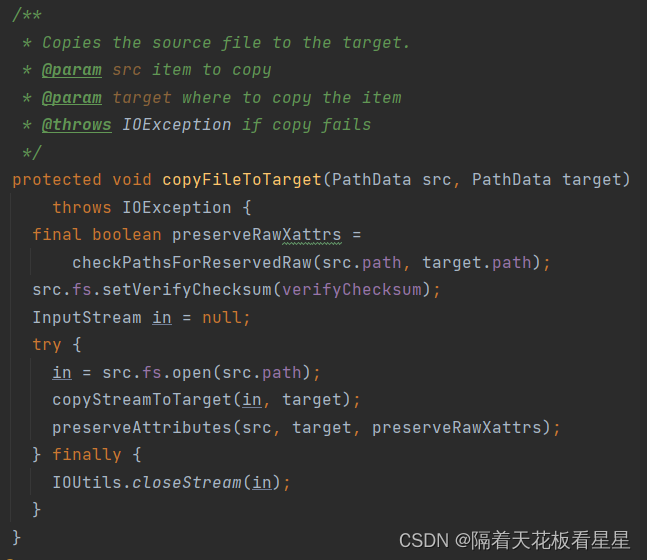
in = src.fs.open(src.path); 输入流就是我们要上传的文件的输入流
下面看 copyStreamToTarget(in, target);

方法注释:如果禁用直接写入,则将流内容复制到临时文件“target_COPYING_”。如果复制成功,则临时文件将重命名为实际路径,否则将删除临时文件。如果启用了直接写入,则跳过创建临时文件。
//Helper筛选器文件系统,将创建的文件注册为要在退出时删除的临时文件,除非成功重命名
TargetFileSystem targetFs = new TargetFileSystem(target.fs);
//开始些临时文件
targetFs.writeStreamToFile(in, tempTarget, lazyPersist, direct);
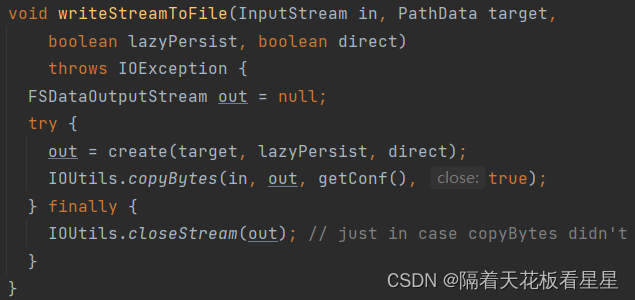
//先获取输出流,即需要请求NameNode创建新文件,并返回输出流
out = create(target, lazyPersist, direct);
会调用FileSystem.create()
最终会调用DistributedFileSystem.create()
8、DistributedFileSystem

又调用DFSClient.create()
9、DFSClient

//申请权限
final FsPermission masked = applyUMask(permission);
//创建输出流
final DFSOutputStream result = DFSOutputStream.newStreamForCreate(...)
10、DFSOutputStream

类注释:(
DFSOutputStream从字节流中创建文件。
客户端应用程序写入由该流内部缓存的数据。数据被分解成多个数据包,每个数据包的大小通常为64K。数据包由块组成。每个块通常是512字节,并且具有与其相关联的校验和。
当客户端应用程序填充currentPacket时,它将被排入DataStreamer的dataQueue。DataStreamer是一个线程,它从dataQueue中拾取数据包并将其发送到管道中的第一个数据节点。
)
该方法最后是一个 out.start(); 就是启动了一个DataStreamer线程。
我们先看下这段代码:
stat = dfsClient.namenode.create(...)
最终通过 ClientProtocol 链接NameNode
//构建DataStreamer 并为创建文件提供输出流
out = new DFSOutputStream(...)
最终是走的DataStreamer的构造方法 可以看下其中的run方法
11、NameNodeRpcServer
类注释:这个类负责处理对NameNode的所有RPC调用。它由{@link NameNode}创建、启动和停止。
方法注释:(
在命名空间中创建一个新的文件条目。
这将创建一个由源路径指定的空文件。该路径应反映源自根的完整路径。名称节点没有客户端的“当前”目录的概念。
创建后,该文件可见,可供其他客户端读取。尽管如此,其他客户端在文件完成之前或由于租约到期而明确地无法{@link#delete(String,boolean)}、重新创建或{@link#rename(String,String)}。
块具有最大大小。打算创建多块文件的客户端也必须使用{@link#addBlock}
)

//在命名空间中创建一个新的文件条目。
status = namesystem.startFile(...)
最终会调用 FSNamesystem.startFileInt(...)
12、FSNamesystem
类注释:(
FSNamesystem是一个临时和持久名称空间状态的容器,并在NameNode上完成所有的记账工作。
其作用简述如下:
1) 是BlockManager、DatanodeManager、DelegationTokens、LeaseManager等服务的容器。
2) 修改或检查命名空间的RPC调用应在此处获得委派。
3) 任何只涉及区块的东西(例如区块报告),都会委托给区块管理器。
4) 任何只涉及文件信息(例如权限、mkdirs)的内容,它都会委托给FSDirectory。
5) 任何跨越上述两个组成部分的内容都应该在此处进行协调。
6) 将突变记录到FSEditLog。
此类及其内容保持:
1) 有效的fsname-->阻止列表(保存在磁盘上,已记录)
2) 所有有效块的集合(反转#1)
3) 块-->机器列表(保存在内存中,根据报告动态重建)
4) machine-->阻止列表(反向#2)
5) 更新的心跳机器的LRU缓存
)
该方法比较长就不截取了,有兴趣的朋友可以跟读到这里看看这块逻辑。
该方法所做的事情有
1、输出debug级别log:那个客户端创建父目录并要写入文件了,该文件块大小是多少......
2、校验当前集群状态是否允许写操作
3、校验NameNode是否在安全模式下
4、创建INode(INode类注释:(在内存中保留文件/块层次结构的表示形式。这是一个基本的INode类,包含文件和目录索引节点的公共字段。))
5、校验块大小是否小于最小块大小(块的最小值设定:dfs.namenode.fs-limits.min-block-size)
6、校验副本数是否在允许的范围内
7、更新块映射关系
.......
13、DataStreamer
类注释:(
DataStreamer类负责将数据包发送到管道中的数据节点。它从namenode检索新的块ID和块位置,并开始将数据包流式传输到Datanodes的管道。每个数据包都有一个与之相关的序列号。当一个块的所有数据包都被发送出去,并且每个数据包的acks都被接收到时,DataStreamer就会关闭当前块。
DataStreamer线程从dataQueue中拾取数据包,将其发送到管道中的第一个数据节点,并将其从dataQueue移动到ackQueue。ResponseProcessor从数据节点接收ack。当从所有数据节点接收到数据包的成功ack时,ResponseProcessor会从ackQueue中删除相应的数据包。
如果出现错误,所有未处理的数据包都会从ackQueue中移出。通过从原始管道中消除坏的数据节点来设置新的管道。DataStreamer现在开始从dataQueue发送数据包
)

方法注释:(
streamer线程是唯一一个向datanode打开流并关闭流的线程。任何错误恢复也由该线程完成。
)
//意思是等刚才得到的输入流开始向输出流开始复制后(IOUtils.copyBytes(in, out, getConf(), true);
),该线程开始启动向DataNodes写入数据。
while (!streamerClosed && dfsClient.clientRunning) {
}

三、流程梳理
1、命令行输入hadoop fs -put test.txt /user/hhs/test_dir
2、hadoop命令对应脚本启动java进程(启动类为org.apache.hadoop.fs.FsShell)并把所有参数(fs -put test.txt /user/hhs/test_dir)作为参数都传进去
3、解析参数(如果参数有fs设置FileSystem的默认Uri)并调用命令处理程序Command
4、调用CopyCommands-Put程序构建PathData(封装路径(Path)、文件状态(stat)和文件系统(fs))
5、利用代理模式创建输入流和输出流,并连接NameNode(更新命名空间和EditLog并检查当下环境是否允许写操作)
6、启动DataStreamer线程等待客户端将输入流复制到输出流
7、DataStreamer类开始将数据包放入管道向下一个DataNode写数据
8、输入流到输出流复制完毕,将临时文件重命名为原本名字,管道也写入完毕
9、界面无报错,通过命令(hadoop fs -du -h /user/hhs/test_dir)查看结果 (如果可能也会报错,DataStreamer会进行维护将原始管道中消除坏的数据节点来设置新的管道)















 2031
2031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









