







一、hadoop简介:hadoop是一个适合海量数据存储和计算的分布式基础框架,其起源于google三篇论文。其中,hadoop2.x的版本中,概括起来可分为三大核心或四大模块。三大核心是指:hdfs(分布式文件系统)、yarn(任务调度和资源管理)、mapreduce(分布式离线计算框架);而四大模块除了包括上述的三个核心组件外,外加一个hadoop common组件(其为三大核心组件提供基础工具,如配置工具configuration、远程过程调用rpc工具、序列化机制等)
二、hadoop的存储机制
hadoop框架中,包含一个用于存储海量数据的分布式文件系统;即HDFS。其中与HDFS的存储文件相关的节点主要包括:client(客户端)、namenode(名称节点)、datanode(数据节点),其中,client用于发送读写文件请求;namenode用于处理客户端发来的IO请求以及维护元数据,而datanode用于存储数据并定期向namenode发送存储在本地的块报告信息

三、hdfs写数据流程
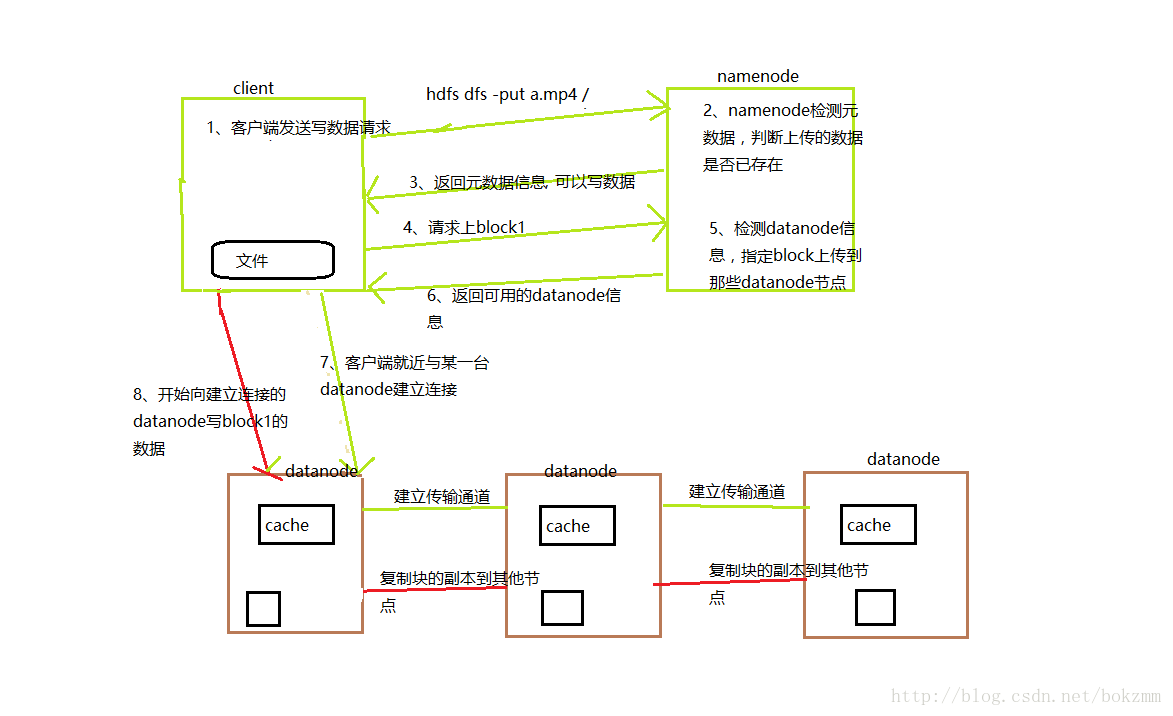
(1)客户端向namenode发送写数据的请求【命令:hdfs dfs -put 要上传文件的路径 存储在hdfs上的路径】
(2)namenode收到客户端的请求后,首先会检测元数据的目录树;判断待上传的文件是否已存在,如果已存在,则拒绝client的上传。如果不存在,则响应客户端可以上传。
(3)客户端收到可以上传的响应后,会把待上传的文件切块(hadoop2.x默认块大小为128M);然后再次给namenode发送请求,上传第一个block块。
(4)namenode收到客户端上传block块的请求后,首先会检测其保存的datanode信息,确定该文件块存储在那些节点上;最后,响应给客户端一组datanode节点信息。
(5)客户端根据收到datanode节点信息,首先就近与某台datanode建立网络连接;然后该datanode节点会与剩下的节点建立传输通道,通道连通后返回确认信息给客户端;表示通道已连通,可以传输数据。
(6)客户端收到确认信息后,通过网络向就近的datanode节点写第一个block块的数据;就近的datanode收到数据后,首先会缓存起来;然后将缓存里数据保存一份到本地,一份发送到传输通道;让剩下的datanode做备份。
(7)第一个block块写入完毕,若客户端还有剩余的block未上传;则客户端会从(3)开始,继续执行上述步骤;直到整个文件上传完毕。
四、hdfs读数据流程

(1)客户端发送读数据请求给namenode【命令:hdfs dfs -get hdfs文件路径】
(2)namnode收到请求后,会检测元数据;判断读取的文件是否存在。存在,则响应客户端该文件保存在那些datanode节点上。
(3)客户端收到可以读文件的响应后,根据拿到的datanode节点信息;会与每个datanode节点建立网络连接,然后读取保存在每个datanode节点的block块数据。
(4)客户端会将从网络中读取的数据保存到缓存中,然后保存到本地磁盘。
















 824
824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











