






如果当我们需要爬取一些文件时,比如.mp3 .jpg文件的格式,我们可以利用get的方法。
在爬取之前,我们得先来了解下防爬虫机制
如何避免访问被拒绝?
我们在访问之前,可以写一个请求头
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"}
尽量用自己的请求头,我们随便打开一个网页,打开检查(按F12或右键选择检查),点击网络,随便点一个get的文件,往下滑,找到“User-Agent”

“User-Agent”右边就是传入参数(浏览器传入参数)
发送get请求就基本不会请求失败
举例:爬图片
我们先手动爬一下图片,这里,我拿Bing举例
我们来给他分一下段
https://cn.bing.com/images/search?
这是图片搜索的链接
q=爬虫
这是参数q,一般指搜索的东西
&
这是“and”(和)的意思,如果需传入第二个参数需要打“&”
form=HDRSC2
大概就是HDR画质,我也不太清楚
&first=1
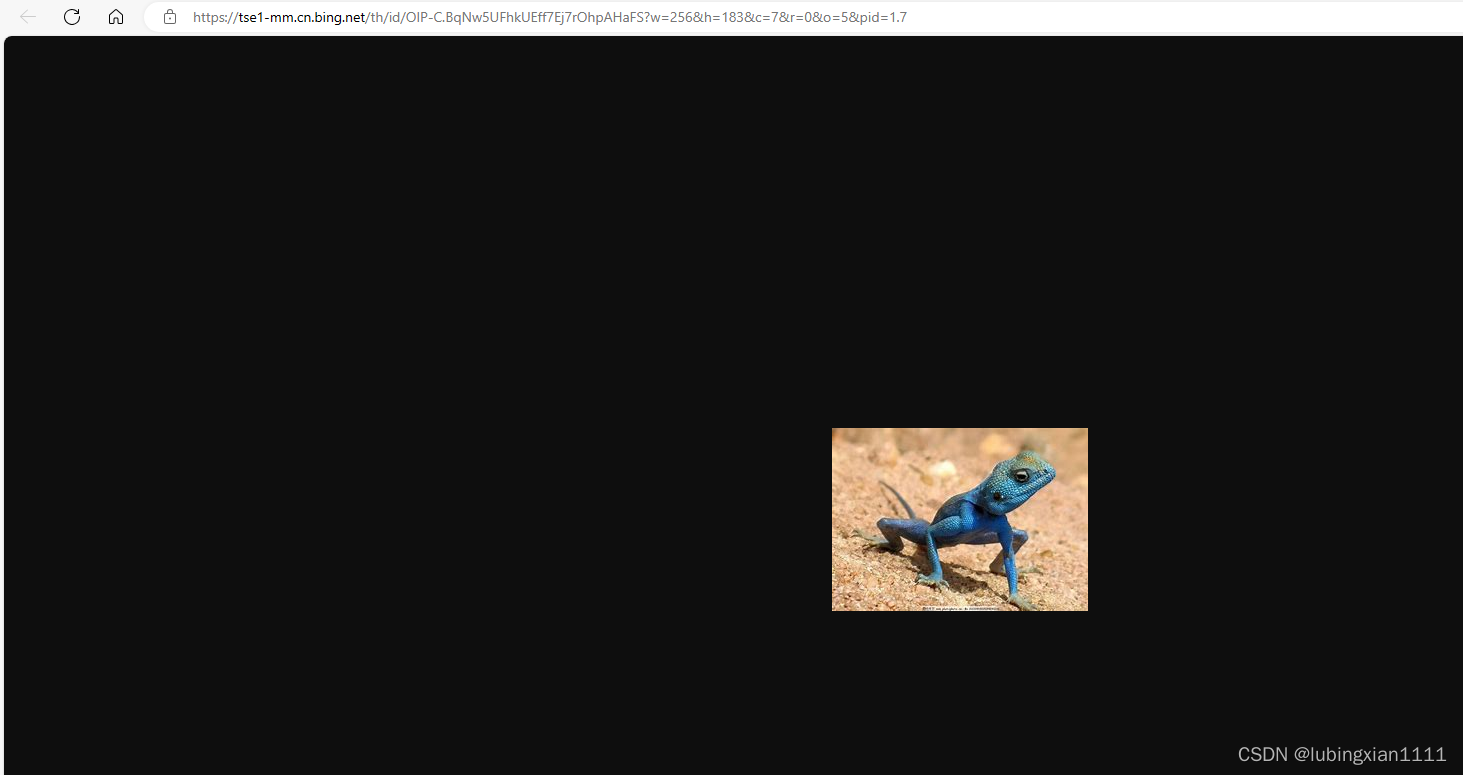
第一张图片是什么,具体如下:
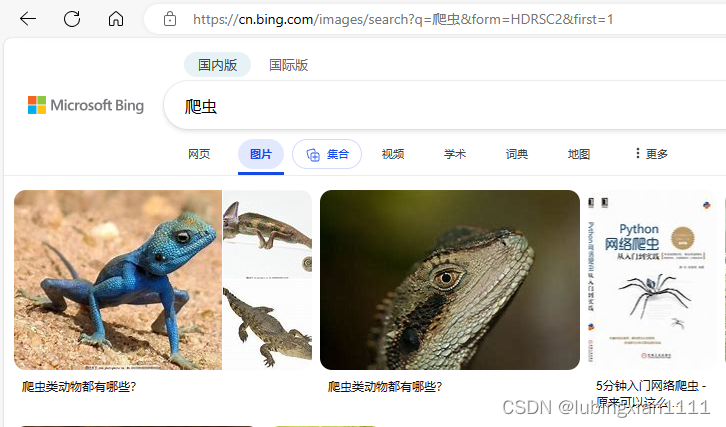
第一张是蓝色的
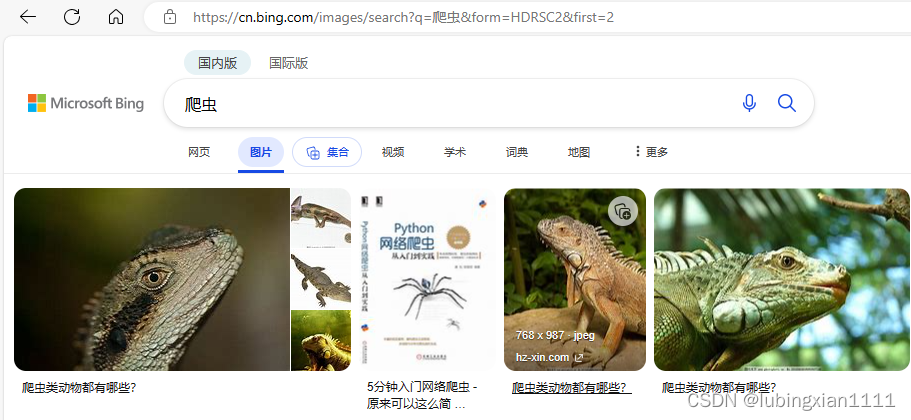
当“first”变动时,图片随之也会变成第二张
了解完链接的作用,来看一看如何爬取
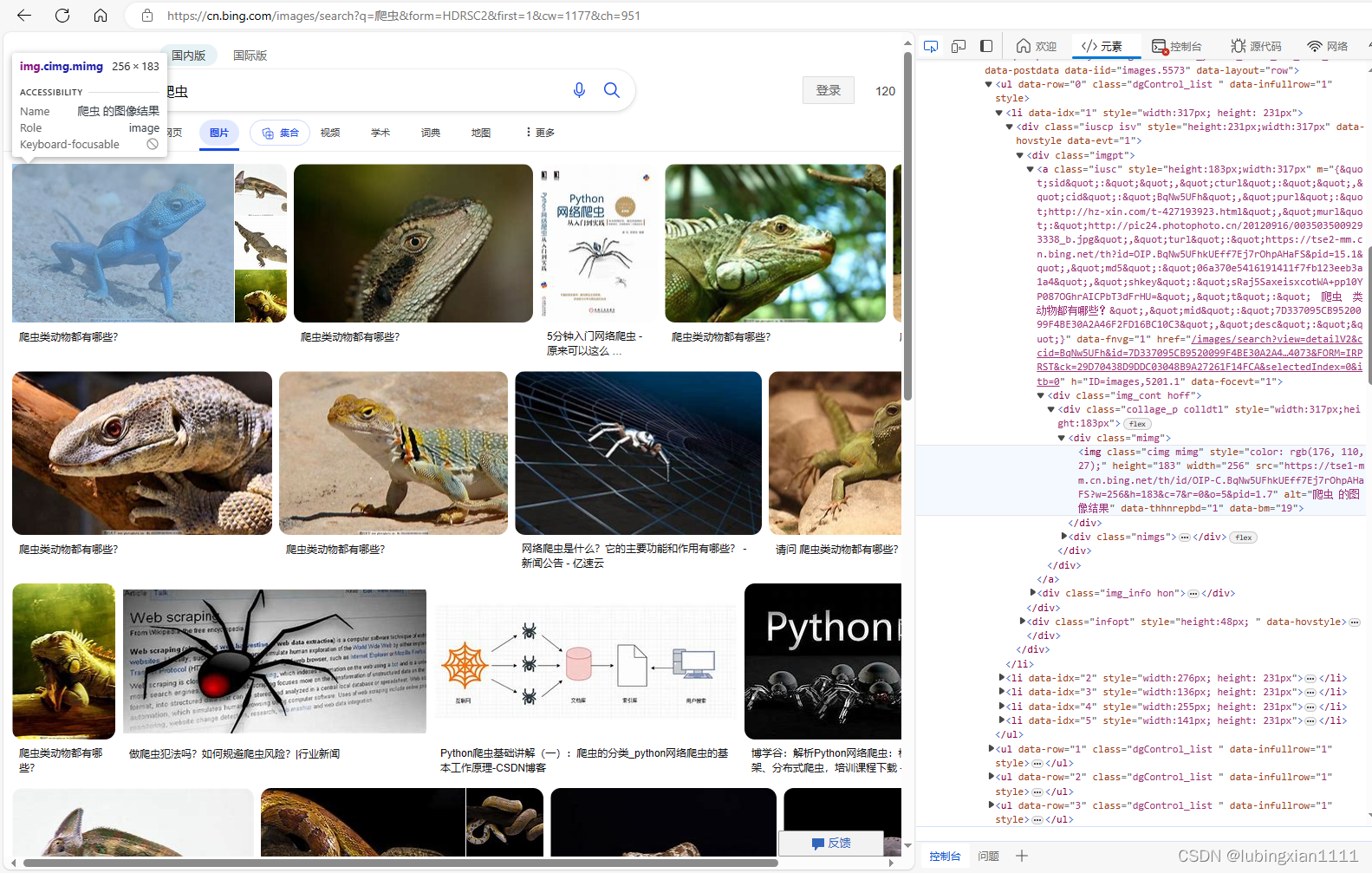
打开检查(按F12或右键选择检查),选中第一张图片
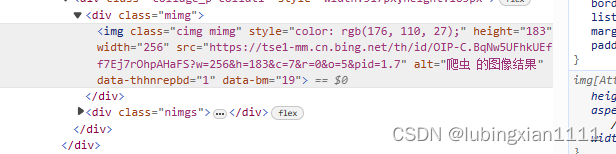
我们可以发现src后的链接正是图片链接
所以,们就可以分析,并传入到爬虫了
解析json对象
get成功后,就会返回json格式的文本
如何让机器解析?我们可以用一个笨方法
import re
def find_text(file_path, target_text):
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
match = re.search(target_text, line)
if match:
return match.group()
return "没有指定文本"
file_path = 'in.txt'
target_text = 'get_json'
result = find_text(file_path, target_text)
print(result)这段代码可以返回指定文本。不过需要先将json文件复制,也就是检查中的元素,复制到一个文本(.txt),然后将代码中的“file_path”改成文本名称(只用改下面result就可以了),再把target_text中的“get_json”改成需要搜索把字符串
现在可以识别有没有指定的文件格式,如果没有,就可以返回“没有指定文本”。
目前先说这么多。如果想获取链接,我在之后会讲。(因为我也不会...)















 257
257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









