







为了解决特定问题而进行的学习是提高效率的最佳途径。这种方法能够使我们专注于最相关的知识和技能,从而更快地掌握解决问题所需的能力。
(以下练习题来源于《统计学—基于Python》。联系获取完整数据和Python源代码文件。)
练习题
为了研究上市公司对其股价波动的关注程度,一家研究机构对在主板、科创板和创业板上市的190家公司进行了调查,得到如下数据:
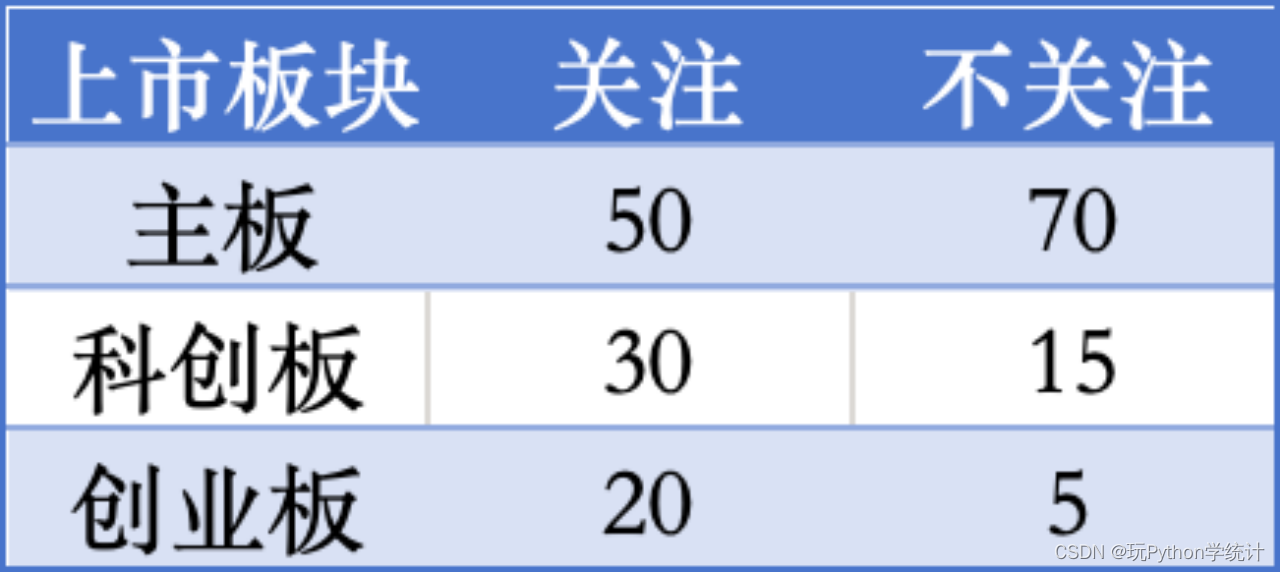
(1)检验上市板块与对股价波动的关注程度是否独立(α=0.05);
(2)计算上市板块与对股价波动的关注程度两个变量之间的φ系数、Cramer's V系数和列联系数,并分析其相关程度。
题目分析
根据题意并观察数据,可以发现此题考查列联表和卡方独立性检验,还要求计算两个类别变量的相关性度量。
本题要检验“上市板块与对股价波动的关注程度是否独立”,我们通过观察数据的表格形式,发现它其实是由两个分类变量交叉分类形成的频数分布表,即列联表(contingency table)。对列联表中的两个分类变量进行分析,通常是判断两个变量是否独立,即对数据进行卡方独立性检验。该检验的原假设是:两个变量独立(无关),如果原假设被拒绝,这表明两个变量不独立,或者说两个变量相关。卡方独立性检验的统计量为:
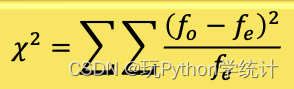
式中,f0为观察频数,fe为期望频数。该统计量服从自由度为(r-1)(c-1)的卡方分布,r为行数,c为列数。
除此之外,还要计算φ系数、Cramer's V系数和列联系数以度量两个类别变量的相关性。
φ系数的公式为:

Cramer's V系数的公式为:
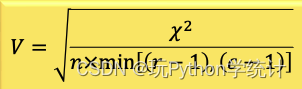
列联系数的公式为:

针对本题,我们按如下步骤进行检验:
第一步,提出假设:H0:上市板块与对股价波动的关注程度独立;H2:上市板块与对股价波动的关注程度不独立。
第二步,用Python计算期望频数和检验统计量。
第三步,用Python计算φ系数、Cramer's V系数和列联系数。
Python代码
import pandas as pd
from scipy.stats import chi2_contingency
x = [[50, 70], [30, 15], [20, 5]]
df = pd.DataFrame(x, index = ['主板', '科创板', '创业板'], columns = ['关注', '不关注'])
# print(df)
chi2, p_value, dof, f_exp = chi2_contingency(df)
print(f"卡方统计量 = {chi2:.4f}, p值 = {p_value:.4f}, 自由度 = {dof}\n期望频数为:\n {f_exp}")
# 计算φ系数、Cramer's V系数和列联系数
import math
n = 190
chi2 = 16.8537
phi = math.sqrt(chi2/n)
v = math.sqrt(chi2/n*(2-1))
c = math.sqrt(chi2/(chi2+n))
print(f"φ系数 = {phi:4f}; Cramer's V系数 = {v:.6f}; 列联系数 = {c:.6f}")计算结果与分析
卡方统计量 = 16.8537, p值 = 0.0002, 自由度 = 2。
期望频数矩阵:
[[63.15789474 56.84210526] [23.68421053 21.31578947] [13.15789474 11.84210526]]
由于p小于0.05,拒绝原假设,接受备择假设,说明有证据表明上市板块与对股价波动的关注程度不独立。
φ系数 = 0.297832;Cramer's V系数 = 0.297832;列联系数 = 0.285441;系数结果表明二者之间有一定的相关性,但关系较弱。
都读到这里了,不妨关注、点赞一下吧!















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









