







文章目录
前言
vLLM 是一个快速且易于使用的库,专为大型语言模型 (LLM) 的推理和部署而设计。具体参考官方文档 https://vllm.hyper.ai/docs/
LLaMA-Factory 是一个专为 LLaMA 系列大语言模型(如 Meta 的 LLaMA、LLaMA-2 等)设计的开源工具库,主要用于模型的 高效微调(Fine-tuning)、部署 和 应用开发。它旨在简化大模型定制化流程,降低用户使用门槛,支持快速适配不同下游任务(如对话、问答、代码生成等)。具体可以参考文档https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/installation.html
一、vLLm部署大模型安装和部署步骤?
1.创建自己的虚拟环境
conda create -n vllm python=3.10 -y
conda activate vllm
pip install vllm2.启动vllm服务端,服务端口8000,这个服务端口不要关
vllm serve /root/autodl-tmp/demo/model/Qwen/Qwen2.5-1.5B-Instruct_merged
#Qwen2.5-1.5B-Instruct_merged注释这个自己训练好的模型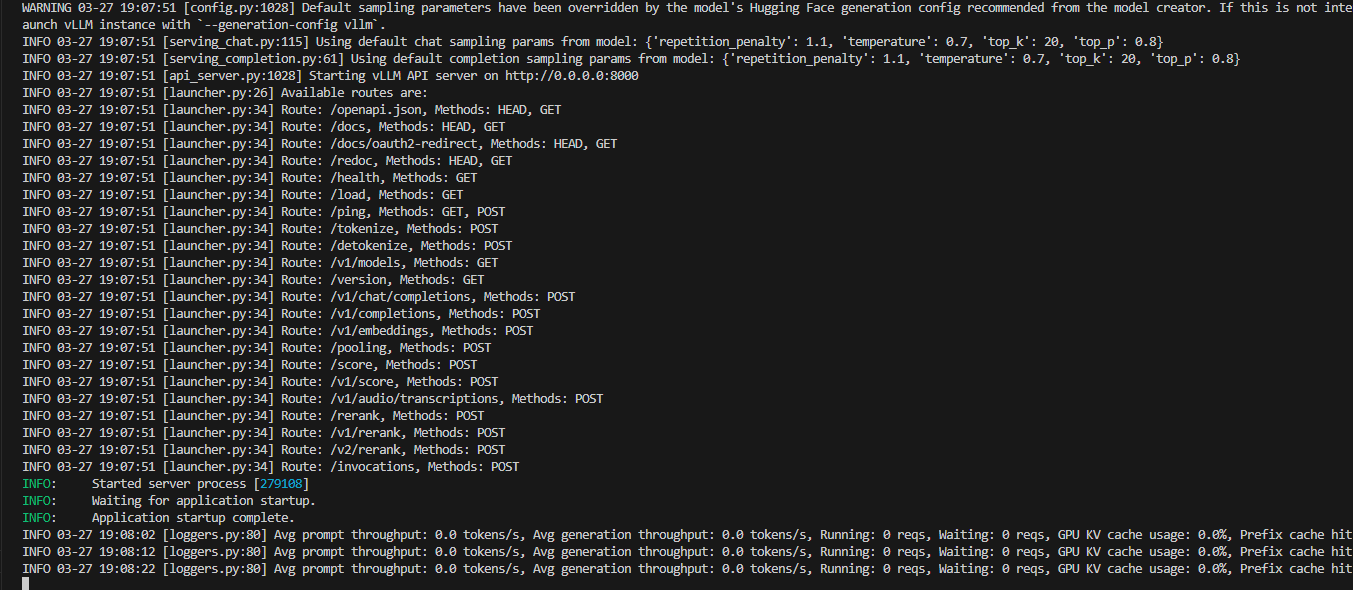
3.进行测试,下面使用多轮对话代码进行测试,将代码拷贝到服务器上,进行执行,并与在llamafactory上对话,以及原始数据进行对比,发现部署到vllm的模型对话达不到llamafactory上对话的效果
将下面代码拷贝到/root/autodl-tmp/demo,建个test.py文件,执行下面命令
python test.py#多轮对话
from openai import OpenAI
#定义多轮对话方法
def run_chat_session():
#初始化客户端
client = OpenAI(base_url="http://localhost:8000/v1/",api_key="token-abc123")
#初始化对话历史
chat_history = []
#启动对话循环
while True:
#获取用户输入
user_input = input("用户:")
if user_input.lower() == "exit":
print("退出对话。")
break
#更新对话历史(添加用户输入)
chat_history.append({"role":"user","content":user_input})
#调用模型回答
try:
chat_complition = client.chat.completions.create(messages=chat_history,model="/root/autodl-tmp/demo/model/Qwen/Qwen2.5-1.5B-Instruct_merged")
#获取最新回答
model_response = chat_complition.choices[0]
print("AI:",model_response.message.content)
#更新对话历史(添加AI模型的回复)
chat_history.append({"role":"assistant","content":model_response.message.content})
except Exception as e:
print("发生错误:",e)
break
if __name__ == '__main__':
run_chat_session()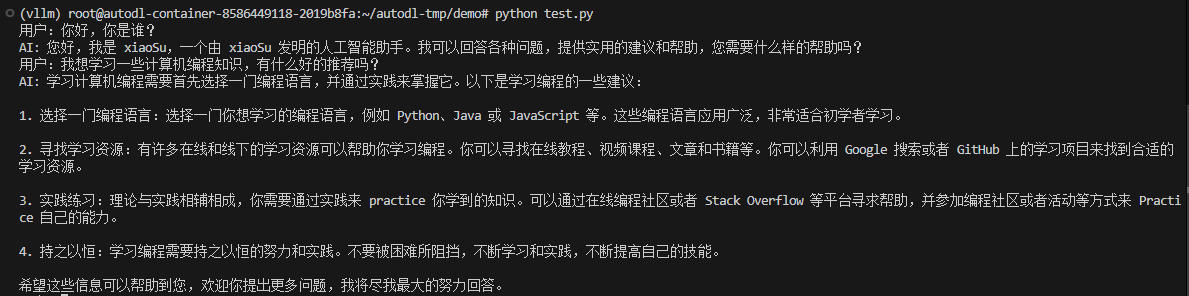
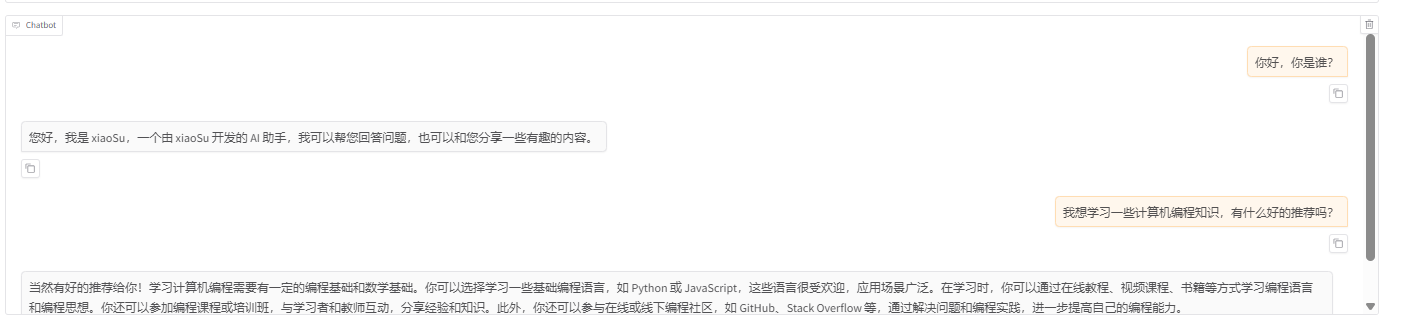

二、解决LLamaFactory微调效果与vllm部署效果不一致
1.分析原因
LLaMA-Factory主要用于微调模型,特别是LLaMA系列的大模型。在微调过程中,对话模板(template)是非常重要的,它决定了输入数据的格式,包括系统提示、用户输入、模型回复的结构,以及使用的特殊标记(如开始符、结束符)。不同的模型可能需要不同的模板,比如LLaMA-2和ChatGLM的模板可能不一样,因为它们训练时使用的数据格式不同。
vLLM它是一个推理和服务部署的库,专注于高效地运行大模型。用户部署模型时,可能需要调整对话模板,以确保生成的结果符合预期。例如,vLLM可能没有自动处理模板的功能,需要用户显式地设置输入格式,或者在生成回复后添加结束符。
总之要解决要确保训练和部署时的对话模板一致,否则模型的生成效果可能受到影响,即对话模版对齐。
2.解决问题:在部署vllm的时候指定对话模版
- 将llamafactory定义的对话模版文件转换vllm部署需要的jinja文件,llamafactory对话模版文件的位置在LLaMA-Factory/src/llamafactory/data/template,将下面代码拷贝到test.py,放到template.py同一级目录中,切换到安装了llamafactory的环境进行脚本执行,否则会报错
# test.py import sys import os from pathlib import Path # 配置路径 sys.path.append(r"/root/autodl-tmp/demo/llamafactory") # 替换为你的 LLaMA-Factory 路径 output_file = r"/root/autodl-tmp/demo/template_qwen.jinja" # 自定义输出文件路径 # 创建输出目录(如果不存在) Path(output_file).parent.mkdir(parents=True, exist_ok=True) from llamafactory.data.template import TEMPLATES from transformers import AutoTokenizer # 1. 初始化分词器 tokenizer = AutoTokenizer.from_pretrained(r"/root/autodl-tmp/demo/model/Qwen/Qwen2.5-1.5B-Instruct") # 2. 获取模板对象 template_name = "qwen" template = TEMPLATES[template_name] # 3. 修复分词器的 Jinja 模板 template.fix_jinja_template(tokenizer) # 4. 将模板内容写入指定文件 with open(output_file, "w", encoding="utf-8") as f: f.write(tokenizer.chat_template) print(f"模板已保存至:{output_file}")不切换环境,没安装llamafactory,会报以下错误:

- 执行vllm serve 命令,指定对话模版
vllm serve /root/autodl-tmp/demo/model/Qwen/Qwen2.5-1.5B-Instruct_merged --chat-template /root/autodl-tmp/demo/template_qwen.jinja - 等重启完后,进行验证,重启一个窗口,执行python test.py,得到效果,效果不错
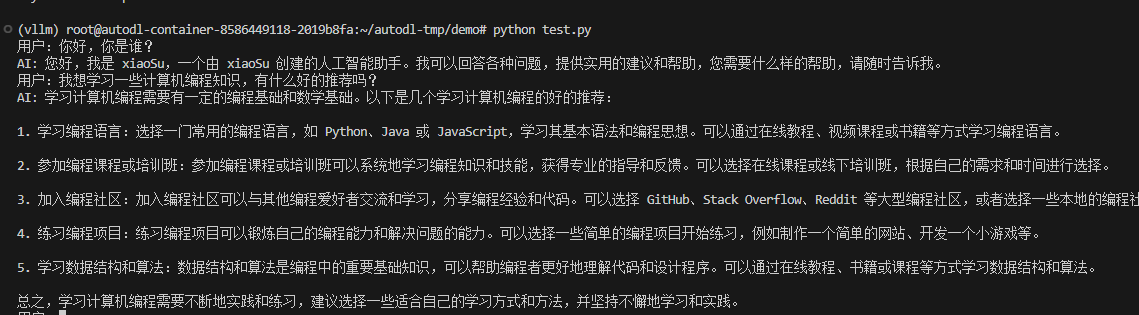

















 1312
1312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









