







粗略地说,大模型训练有四个主要阶段:预训练、有监督微调、奖励建模、强化学习。
预训练消耗的时间占据了整个训练pipeline的99%,其他三个阶段是微调阶段,更多地遵循少量 GPU 和数小时或数天的路线。预训练对于算力和数据的要求非常高,对于普通开发者来说基本上不用考虑了。
对于开发者来说,如果你有几块GPU显卡,那么就可以尝试微调了。不过在微调之前,我们要弄明白为什么要微调,大模型为什么不能直接用?
一、为什么要微调?
大语言模型的预训练的目标很简单:文字接龙,通过前面的词语预测下一个字也就是预测token序列的下一个token。
预训练基于大规模无监督数据集训练,得到的大语言模型可以保存很多知识,但是可能无法充分利用这些知识来回答问题。
我的理解是预训练就是一个班上学习很好的学霸,不过只会死记硬背,脑袋里记忆了很多知识,但是不会灵活应用这些知识。一般预训练的数据格式如下所示:
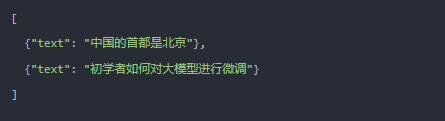
如果将“中国的首都是”输入大模型,大模型做文字接龙,可以很轻松的补全“北京”作为回答。但是如果问题的形式是“中国的首都是哪个城市?”这种疑问句形式的时候,虽然只进行了预训练的大模型大概率也能回答这个简单问题,比如采用Few-shot prompt等方法。
但这种形式的问题如果内容更复杂一些,大模型可能无法很好的作答(尽管预训练语料中可能包含了问题的答案)。这时我们就需要指令微调来挖掘大语言模型的潜力。让大模型不仅仅满足于文字接龙,而是要真正具备逻辑推理、文案总结等能力。
一般来说我们可以在modelscope中搜索最新的大模型,以Llama系列为例子。其中
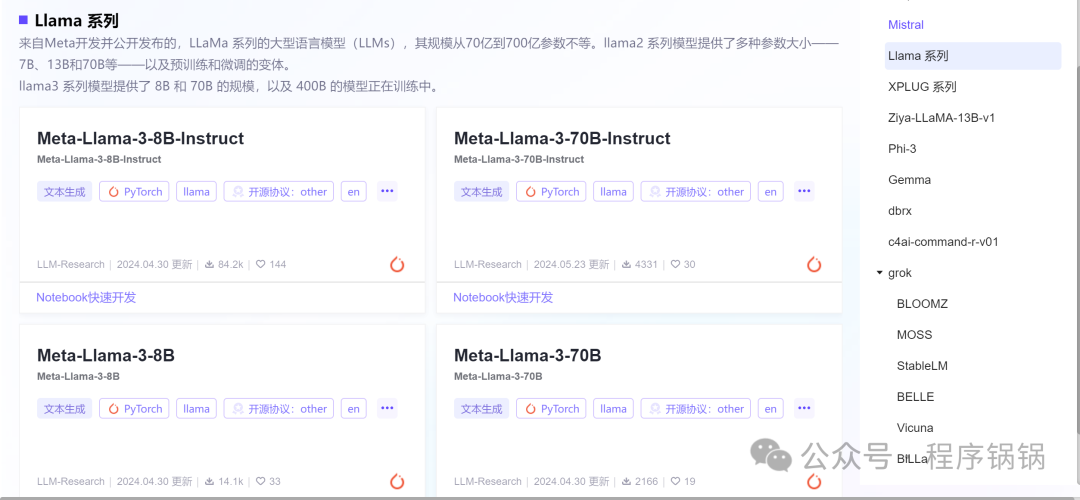
Meta-Llama-3-8B不包含Instruct关键词,说明它只有预训练,未经过指令微调。Meta-Llama-3-8B-Instruct包含Instruct关键词,经过预训练、指令微调。
二、初学者如何微调?
对于初学者来说,我们不需要指令微调来挖掘大语言模型的潜力,虽然这个时候的指令微调相比预训练资源消耗小很多,但是对于初学者来说还是很困难的,在微调过程中会碰到灾难性遗忘、复读
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1000
1000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









