







一.引入基本模块
from requests-html import HTMLSession
from urllib.parse import urlparse, parse_qs
import pandas as pd
#使用代码更加美观
import pprint
二.翻页
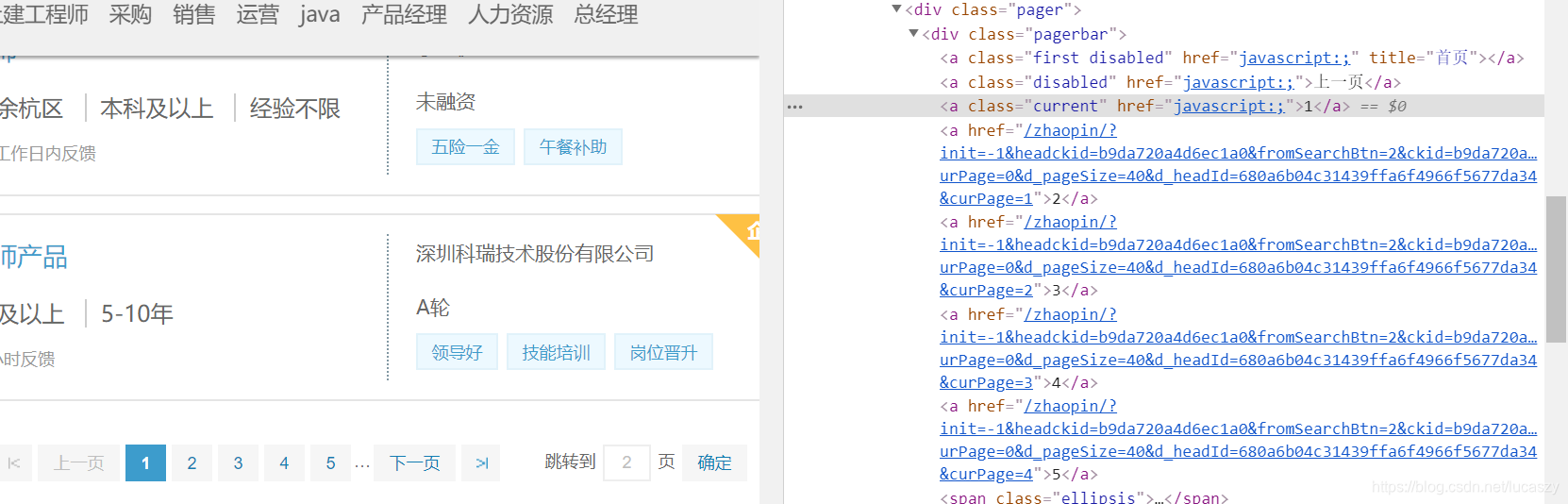
翻页,其实就是url不同而已,但是url不同在哪我们就要对url进行拆解才能知道
 接下来就是利用xpath把url抓取下来
接下来就是利用xpath把url抓取下来
#建立连接
url = "https://www.liepin.com/zhaopin/"
session = HTMLSession()
r = session.get( url )
#starts-with可以指定url连接开头部分,这样子可以避免抓取到无用的url,因为猎聘网有几个链接是javascript,我们要排除掉
xpath_翻页a = '//div[@class="pagerbar"]/a[starts-with(@href,"/zhaopin")]'
href_列表 = [x.xpath('//@href')[0] for x in r.html.xpath(xpath_翻页a)]
pprint.pprint(href_列表)
#使用字典存储url
#x.xpath('//@href')[0]是因为for循环输出的是一个列表,[0]才能把链接取出来
"""
href_字典={}
for x in r.html.xpath():
href_字典[x.text]=x.xpath('//@href')[0]
"""
以上等式等于以下推导式
href_字典 = {x.text:x.xpath('//@href')[0] for x in r.html.xpath(xpath_翻页a)}
pprint.pprint (href_字典)这样就把链接抓取下来
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 793
793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









