






Python爬虫爬取简历模板——BeautifulSoup解析网页数据
网址:https://sc.chinaz.com/jianli/
这个网站中有多种风格的简历模板,这里以爬取“适合大学毕业生简历表格模板”为例。网址为:https://sc.chinaz.com/jianli/biaoge.html 。
一、观察网页数据

“适合大学毕业生简历表格模板”共有31页,因此我们需要找到每一页的URL的规律,以便使用循环遍历请求每一个的数据。
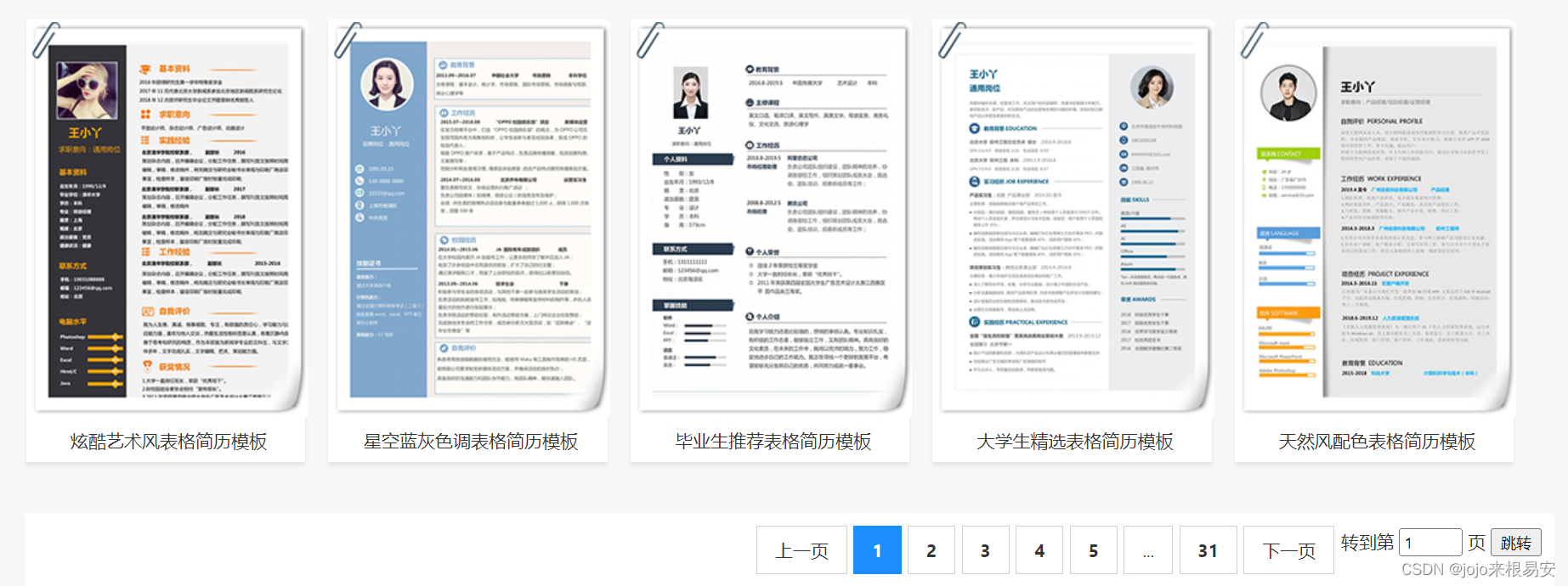
第一页的url:https://sc.chinaz.com/jianli/biaoge.html
第二页的url:https://sc.chinaz.com/jianli/biaoge_2.html
第三页的url:https://sc.chinaz.com/jianli/biaoge_3.html
…
将第一页的url修改为:https://sc.chinaz.com/jianli/biaoge_1.html ,但是并不能获取到第一页的内容,因此从第二页开始的url是有规律的,都带有页数,第一页的url没有规律,所以可以单独获取第一页的模板文件,通过循环获取其他页的模板文件。
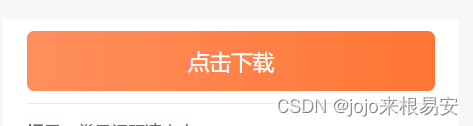
点进去其中一个简历模板查看,可以发现,只要点击黄色的“点击下载”按钮就可以下载简历模板的.rar文件。

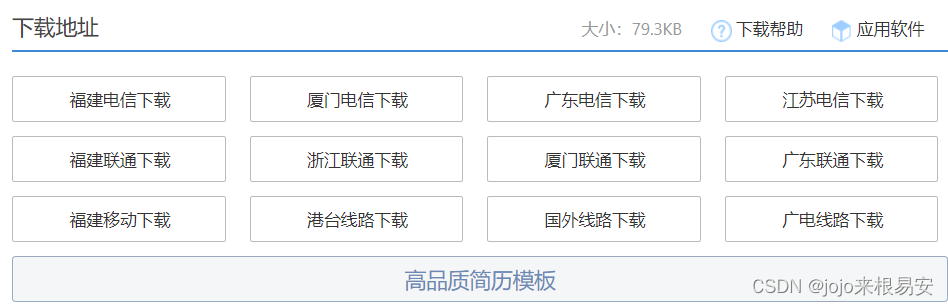
这是其中一种下载情况,另一种下载情况如下图,有多个下载地址,同样,只要点击其中一个下载地址就可以下载模板的.rar文件
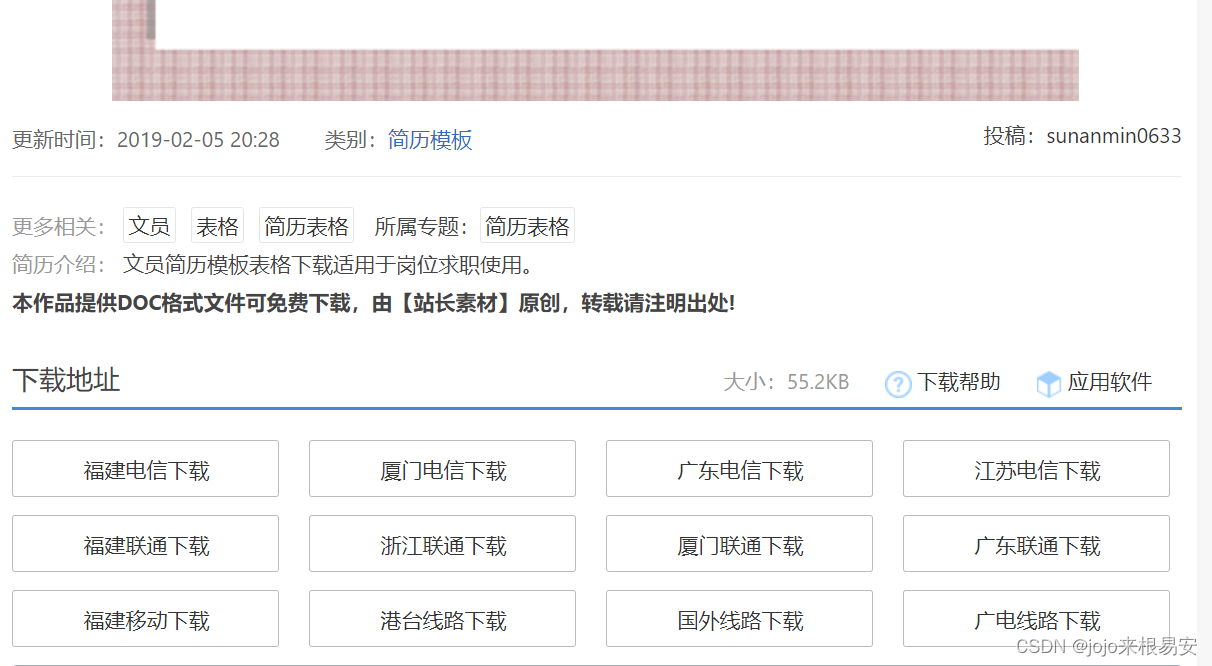
查看网页源码:
打开网址https://sc.chinaz.com/jianli/biaoge.html。点击网页源码中的选择按钮,然后选中网页中的任意一个简历模板:
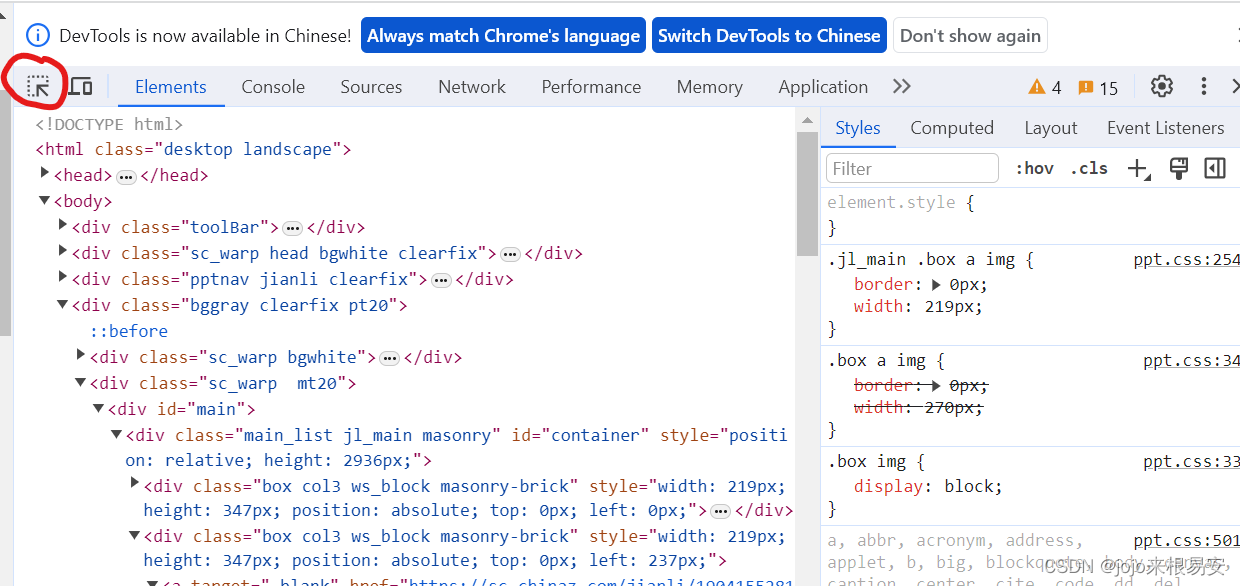
可以发现定位到网页源码的标签<a>中有一个属性href,这就是简历模板的详情页连接,我们点击该链接发现可以跳转到对应的简历模板详情页。所以我们可以从对当前页面发起请求,获取页面中每一个简历模板的详情页链接。
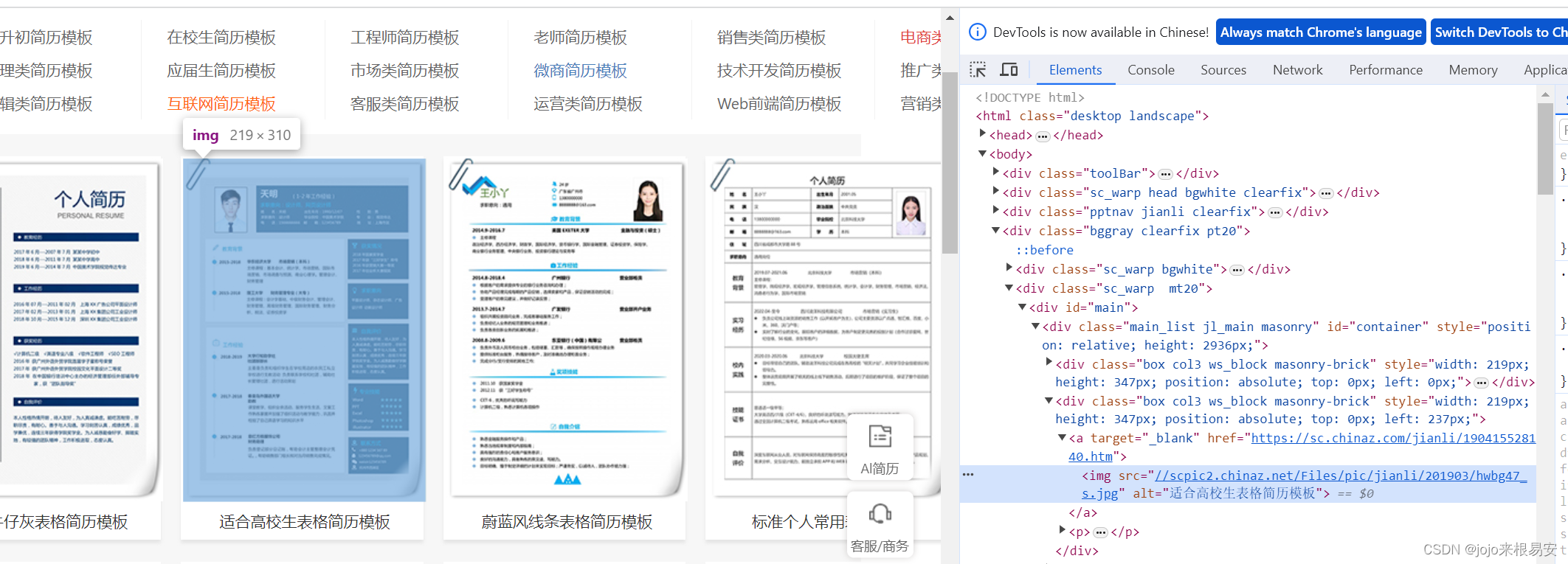
打开模板的详情页,查看网页源码,同样定位到黄色的“点击下载”按钮,可以发现该<a>标签中有一个href属性,是以.rar结尾的地址,点击该地址就可以下载模板文件的.rar文件。
因此我们可以对简历模板详情页发起请求,获取其下载地址。
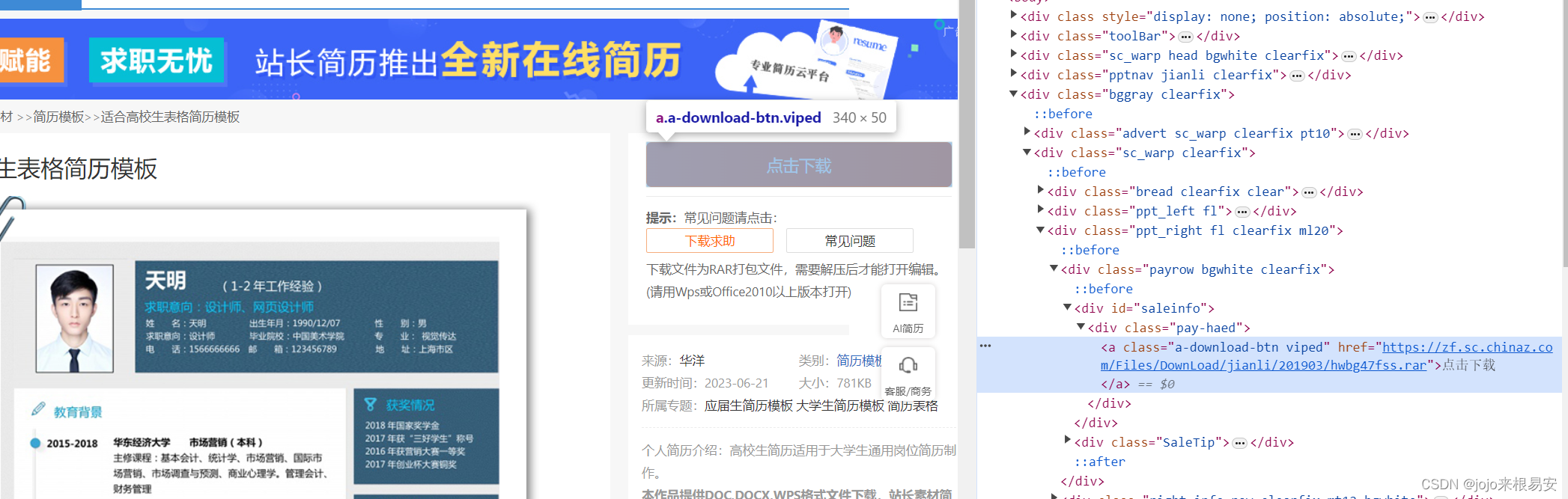
对于有多个下载地址的下载情况,我们只需要获取其中一个下载地址即可。
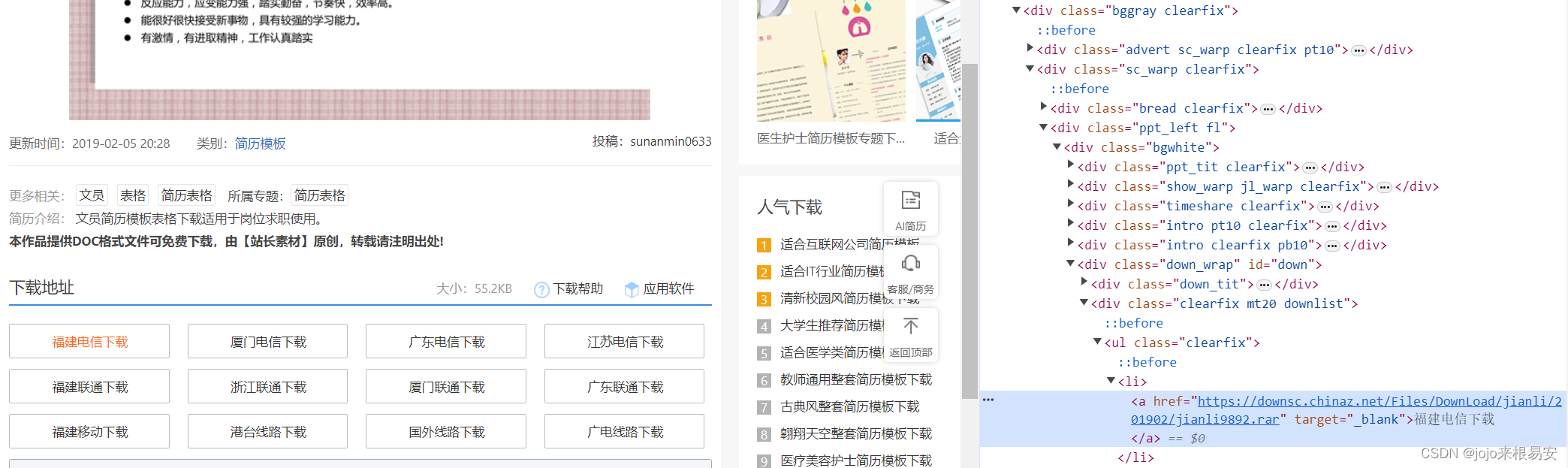
整体思路:
1)先对每个页面发起请求
第一页的url:https://sc.chinaz.com/jianli/biaoge.html
第二页的url:https://sc.chinaz.com/jianli/biaoge_2.html
第三页的url:https://sc.chinaz.com/jianli/biaoge_3.html
…
由于第一页的URL与其他页规律性不符,因此可以单独请求第一页,对其他页面则通过循环改变页数。获取每个页面中所有的简历模板的详情页地址。
2)对每个简历模板详情页发起请求
由于有两种下载情况,因此需要通过条件判断模板文件的下载情况属于两种中的哪一种,然后获取相应的下载地址。
3)对模板文件的下载地址发起请求,将模板的.rar文件保存到本地。
二、对页面发起请求,获取简历模板详情页链接
2.1 获取第一页的模板详情页地址
- 导入所需的模块
import requests
from bs4 import BeautifulSoup
from time import sleep
- 对网页发起请求,获取网页响应
# 发起请求,获取网页响应
response = requests.get(url,headers=headers)
print(response.encoding) # 编码格式是:ISO-8859-1
print(response.status_code)
# print(response.text) # 输出有乱码
response.encoding = 'utf-8' # 将响应内容的编码改为utf-8编码
# print(response.text)
data = response.text
- 解析网页数据,获取模板详情页链接和模板的标题
我们之前定位页面中的简历模板时定位到<a>标签,页面中所有的简历模板详情页地址都是在该标签的href属性中。定位到<div id='main'>可以定位页面中所有的简历模板,说明所有简历模板的地址都在该标签下。这里我们通过BeautifulSoup来解析网页响应数据。具体可以参考Python爬虫——网页数据解析方法。
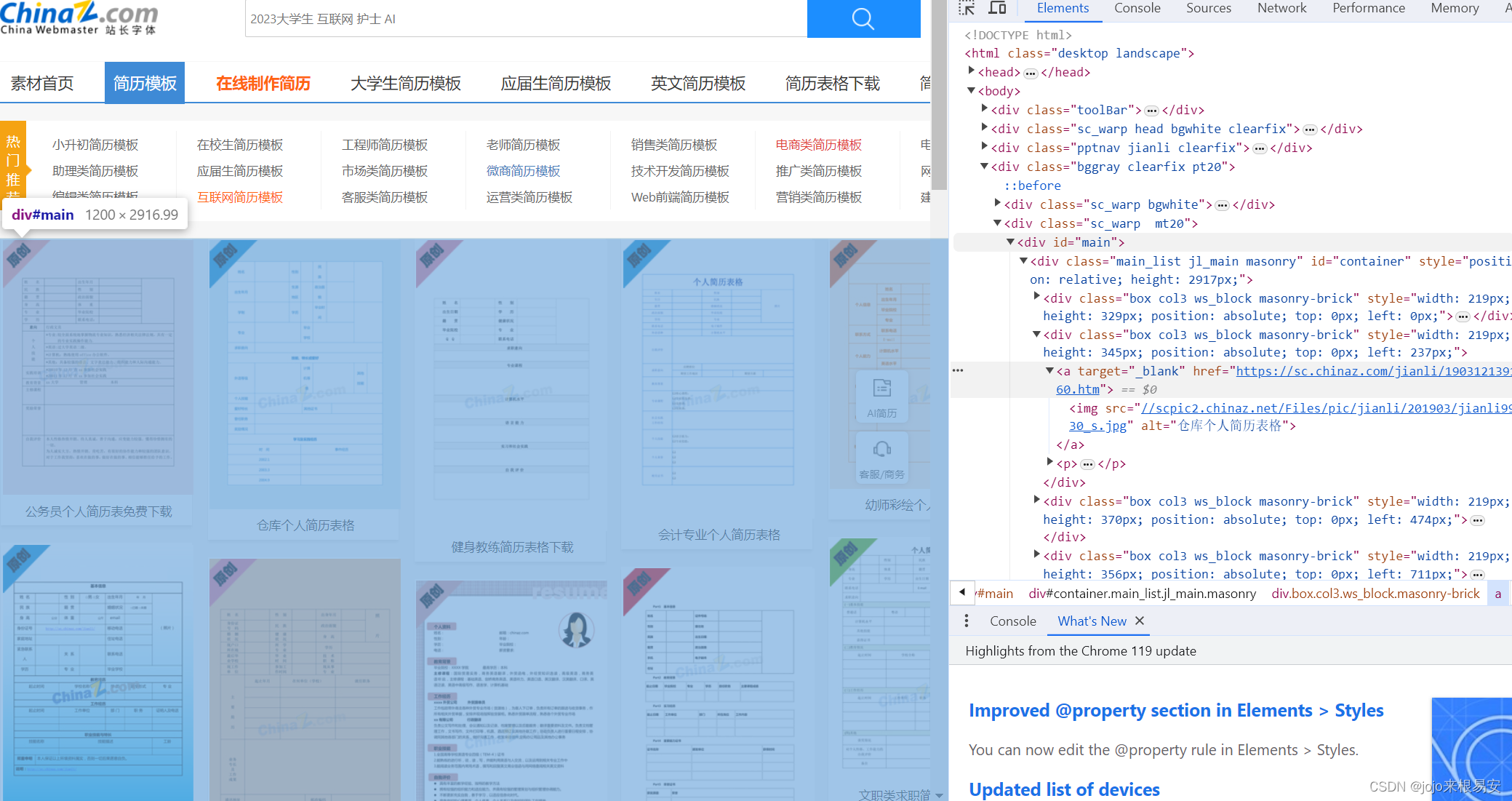
定位到模板所在的a标签,右键选择“复制”——“复制selector”,即可复制当前标签的selector,#container > div:nth-child(2) > a 。
label = soup.select('#container > div:nth-child(2) > a')
print(label)
目前我们已经定位到简历模板地址所在的a标签,输出查看标签中的内容。模板详情页地址是a标签href属性值,模板标题是a标签的子标签img的属性alt的属性值。

可以发现,取到的a标签被放一个列表中,所以需要通过列表的索引取值才能获取到a标签:

现在已经获取a标签,接下来获取a标签中的属性href的属性值,即简历模板的详情页地址。通过在标签后面加上[‘属性名’]即可取到对应的属性值:

获取简历模板的标题:

已经获取到其中一个简历模板的详情页地址和标题,我们需要的是页面中所有模板的详情页地址和标题。观察标签的selector:#container > div:nth-child(2) > a 可以发现,a标签的上一级标签是<div>标签,再上一级是id='container’的div标签,所有简历模板的详情页地址都在该标签下。而中间的div:nth-child(2)表示container下的第2个div标签,所以只要我们去掉这个序号,就可以获取到所有的a标签。

我们已经获取了第一页所有简历模板的详情页地址所在的a标签,它们被封装在一个列表中,接下来循环列表,获取每个a标签的href属性值,即模板的详情页地址。
labels_1 = soup.select('#container > div > a')
labels_2 = soup.select('#container > div> a > img')
detail_urls = [] # 存放模板详情页地址的列表
titles = []
for i in range(len(labels_1)):
link = labels_1[i]['href'] # 获取标签中href属性的属性值
detail_urls.append(link)
title = labels_2[i]['alt']
titles.append(title)
print(detail_urls)
print(titles)
输出结果:

至此,我们已经获取到了第一页的简历模板的详情页地址和标题。
2.2 通过for循环实现翻页,获取不同页面中简历模板详情页地址
这里以获取第二页、第三页模板详情页地址为例。通过循环实现翻页,接下来获取详情页地址的方法与上面相同。
for i in range(2,4):
url = f'https://sc.chinaz.com/jianli/biaoge_{i}.html' # 将页面数作为参数传入url中
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.61'}
# 发起请求,获取网页响应
response = requests.get(url,headers=headers)
sleep(3) # 睡眠3秒
response.encoding = 'utf-8' # 将响应内容的编码改为utf-8编码
# print(response.text)
data = response.text
# 实例化一个BeautifulSoup对象
soup = BeautifulSoup(data,'lxml') # 使用lxml解析器进行解析
labels_1 = soup.select('#container > div > a')
labels_2 = soup.select('#container > div> a > img')
for i in range(len(labels_1)):
link = labels_1[i]['href'] # 获取标签中href属性的属性值
detail_urls.append(link)
title = labels_2[i]['alt']
titles.append(title)
print(len(detail_urls))
print(detail_urls)
print(len(titles))
print(titles)
执行结果:
获取三页共120个详情页地址和标题(包括第一页的模板地址和标题)

三、请求模板详情页,获取模板下载地址
我们已经获取了页面中简历模板的详情页地址,接下来对详情页地址发起请求。
我们可以先向其中一个简历模板详情页发起请求,看看具体情况如何。
res = requests.get(url=detail_urls[0],headers=headers)
print(res.status_code) # 查看状态码
print(res.encoding) # 查看响应数据的编码类型
print(res.text)
输出结果:
可以发现,响应内容的编码格式是ISO-8859-1,与我们编译环境的编码格式不兼容,所以呈现的是乱码,所以需要将其编码格式改为utf-8。
解析请求模板详情页返回的响应数据:
实例化一个BeautifulSoup对象:
res.encoding = 'utf-8' # 修改响应内容的编码格式为utf-8
data = res.text
soup = BeautifulSoup(data,'lxml') # 实例化一个 BeautifulSoup对象
- 对于第一种下载情况
打开网页源码,定位到该按钮所在标签,并复制其selector。
#saleinfo > div > a
获取该标签的内容:
label = soup.select('#saleinfo > div > a')
label
输出结果:

- 对于第二种下载情况
打开网页源码,选中其中一种下载方式,并复制其selector:
#down > div.clearfix.mt20.downlist > ul > li:nth-child(1) > a
获取该标签的内容:
res = requests.get(url=detail_urls[-1],headers=headers)
print(res.status_code) # 查看状态码
print(res.encoding) # 查看响应数据的编码类型
res.encoding = 'utf-8'
# print(res.text)
data = res.text
soup = BeautifulSoup(data,'lxml') # 实例化一个 BeautifulSoup对象
label = soup.select('#down > div.clearfix.mt20.downlist > ul > li:nth-child(1) > a')
label
输出结果:

这两种下载情况在同一个简历模板的详情页是不可能同时出现的,可以试试看在情况1中使用情况2的selector或者在情况2中使用情况1的selector在来获取标签,返回的都是空列表。所以我们可以同时使用两种selector来获取标签,然后通过if条件判断列表是否为空,从而判断当前的模板文件是属于那种下载类型。
download_urls = []
for link in detail_urls:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.61'}
response = requests.get(url=link,headers=headers) # 发起网页请求
sleep(1) # 睡眠1秒
response.encoding = 'utf-8' # 修改编码格式为utf-8
data = res.text
soup = BeautifulSoup(data,'lxml') # 实例化一个 BeautifulSoup对象
label1 = soup.select('#saleinfo > div > a') # 返回值是一个列表
label2 = soup.select('#down > div.clearfix.mt20.downlist > ul > li:nth-child(1) > a') # 返回值是一个列表
if (len(label1) != 0): # 如果label1不是空列表,那么说明是第一种下载类型
src = label1[0]['href']
download_urls.append(src)
elif (len(label2) != 0): # 如果label2不是空列表,那么说明是第二种下载类型
src = label2[0]['href']
download_urls.append(src)
print(len(download_urls))
print(download_urls)
输出结果:

四、对下载地址发起请求,持久化存储文件
for j in range(len(download_urls)):
path = 'D:\\scrape\\jianli\\' + titles[j] + '.rar'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.61'} # UA伪装
data = requests.get(url=download_urls[j], headers=headers).content
sleep(0.5) # 睡眠0.5秒
with open(path,'wb') as fp:
fp.write(data)
print(titles[j]+'.rar'+'下载成功!')
print('=================================================')
print('下载完成!!')
执行结果:
并且文件已经保存到本地:
五、完整代码
import requests
from bs4 import BeautifulSoup
from time import sleep
########################################### 获取第一页的简历模板详情页地址 #####################################
# url
url = 'https://sc.chinaz.com/jianli/biaoge.html'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.61'}
# 发起请求,获取网页响应
response = requests.get(url,headers=headers)
print(response.encoding) # 编码格式是:ISO-8859-1
print(response.status_code)
# print(response.text) # 输出有乱码
response.encoding = 'utf-8' # 将响应内容的编码改为utf-8编码
# print(response.text)
data = response.text
# 实例化一个BeautifulSoup对象
soup = BeautifulSoup(data,'lxml') # 使用lxml解析器进行解析
labels_1 = soup.select('#container > div > a')
labels_2 = soup.select('#container > div> a > img')
detail_urls = [] # 存放模板详情页地址的列表
titles = []
for i in range(len(labels_1)):
link = labels_1[i]['href'] # 获取标签中href属性的属性值
detail_urls.append(link)
title = labels_2[i]['alt']
titles.append(title)
print(detail_urls)
print(titles)
################################## 获取第二、三页的简历模板详情页地址 ########################################
download_urls = []
for link in detail_urls:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.61'}
response = requests.get(url=link,headers=headers) # 发起网页请求
sleep(1) # 睡眠1秒
response.encoding = 'utf-8' # 修改编码格式为utf-8
data = res.text
soup = BeautifulSoup(data,'lxml') # 实例化一个 BeautifulSoup对象
label1 = soup.select('#saleinfo > div > a') # 返回值是一个列表
label2 = soup.select('#down > div.clearfix.mt20.downlist > ul > li:nth-child(1) > a') # 返回值是一个列表
if (len(label1) != 0): # 如果label1不是空列表,那么说明是第一种下载类型
src = label1[0]['href']
download_urls.append(src)
elif (len(label2) != 0): # 如果label2不是空列表,那么说明是第二种下载类型
src = label2[0]['href']
download_urls.append(src)
print(len(download_urls))
print(download_urls)
############################## 对模板详情页发起请求,获取模板下载地址 ########################################
download_urls = []
for link in detail_urls:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.61'}
response = requests.get(url=link,headers=headers) # 发起网页请求
sleep(1) # 睡眠1秒
response.encoding = 'utf-8' # 修改编码格式为utf-8
data = res.text
soup = BeautifulSoup(data,'lxml') # 实例化一个 BeautifulSoup对象
label1 = soup.select('#saleinfo > div > a') # 返回值是一个列表
label2 = soup.select('#down > div.clearfix.mt20.downlist > ul > li:nth-child(1) > a') # 返回值是一个列表
if (len(label1) != 0): # 如果label1不是空列表,那么说明是第一种下载类型
src = label1[0]['href']
download_urls.append(src)
elif (len(label2) != 0): # 如果label2不是空列表,那么说明是第二种下载类型
src = label2[0]['href']
download_urls.append(src)
print(len(download_urls))
print(download_urls)
############################# 对模板下载地址发起请求,持久化存储数据 ####################################
for j in range(len(download_urls)):
path = 'D:\\scrape\\jianli\\' + titles[j] + '.rar'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.61'} # UA伪装
data = requests.get(url=download_urls[j], headers=headers).content
sleep(0.5) # 睡眠0.5秒
with open(path,'wb') as fp:
fp.write(data)
print(titles[j]+'.rar'+'下载成功!')
print('=================================================')
print('下载完成!!')
六、总结
以上就是爬取简历模板的全部过程,程序中只爬取了第一、二、三页,如果想获取更多的模板,可以修改for循环翻页中的数字。或者,可以先使用for循环生成第2、3、4……页的请求URL,连同第一页的URL放到一个列表中,循环列表获取每一页的URL并对该页面发起请求。
在程序中,为了分解每个步骤,把各个部分的代码分开写。可以尝试将各个步骤合并起来,比如,获取到模板详情页的URL之后,对该URL发起请求来获取模板的下载地址,再对下载地址发起请求来将文件保存到本地,需要多嵌套几层循环。获取的.rar压缩文件,可以使用python对它们进行批量解压,这里不介绍。
该网站中还有其他模板,比如ppt、各种类型的图片等等。如果感兴趣可以继续去探索。














 3927
3927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









