







PSENet
Progressive Scale Expansion Network 渐进式规模扩展网络
1. 网络结构
论文使用resnet作为PSENet的主干网络,将特征图F映射到多个分支中,即S1,S2…Sn,每个S都是文本区域的一个mask。
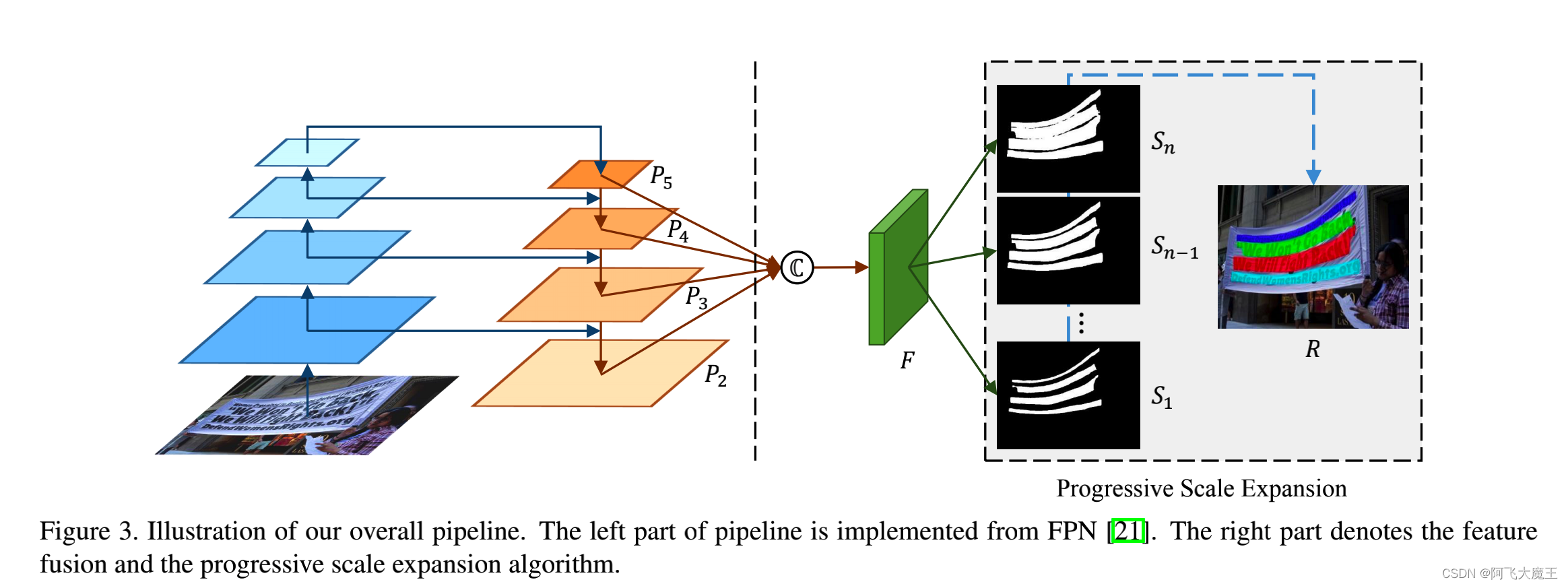 基于分割的方法很难分离出彼此接近的文本实例。为了解决这一问题,论文提出了一种渐进式尺度扩展算法。
基于分割的方法很难分离出彼此接近的文本实例。为了解决这一问题,论文提出了一种渐进式尺度扩展算法。
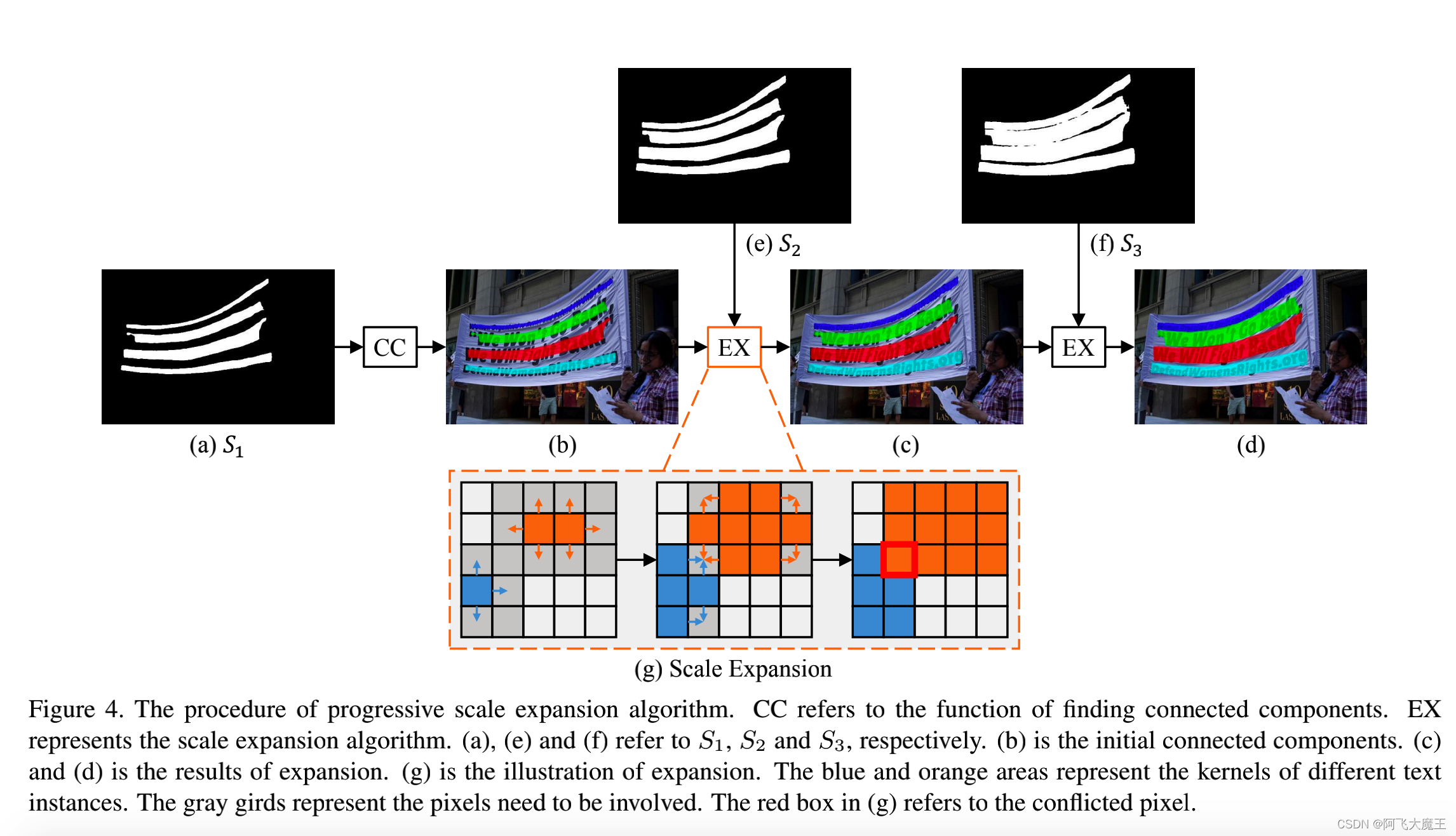
如上图,(a)中显示的是初始区域,也是最小核的mask,可以看出有四个不同文字区域,分别用四种不同颜色表示。然后,我们通过合并S2中的像素来逐步扩展检测到的核,然后合并S3中的像素。两种尺度扩展的结果分别如图( c )和图(d)所示。最后,我们提取在图(d)中用不同颜色标记的连接区域作为对文本实例的最终预测。
渐进式扩展的过程如(g)所示,该扩展是基于广度优先搜索算法,从多个核的像素开始,迭代合并相邻的文本像素。请注意,可能存在冲突的像素,如(g)中红色框所示。当发生冲突时,采用先到先得的策略,保证一个像素只能被合并一次。
2. label生成
论文利用Vatti clippint算法将原始多边形pn缩小得到收缩多边形pi。计算公式如下:

其中Area表示其面积,Perimeter表示其周长,r表示缩放比例,由如下公式计算得到:

其中m是最小尺度,r由m和n决定,范围从m增加到1。
在代码中,实际生成使用pyclipper函数库来实现:
pco = pyclipper.PyclipperOffset()
pco.AddPath(bbox, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
offset = min((int)(area * (1 - rate) / (peri + 0.001) + 0.5), max_shr)
shrinked_bbox = pco.Execute(-offset)
3. 损失函数
 其中,Lc和Ls分别表示完整文本实例和缩小文本实例的损失,λ平衡了Lc和Ls之间的重要性。
其中,Lc和Ls分别表示完整文本实例和缩小文本实例的损失,λ平衡了Lc和Ls之间的重要性。
当使用二值交叉熵损失函数时,文本实例通常只占据一个极小的区域,因此论文在实验中采用了dice loss。
dice loss 对正负样本严重不平衡的场景有着不错的性能,训练过程中更侧重对前景区域的挖掘。但训练loss容易不稳定,尤其是小目标的情况下。另外极端情况会导致梯度饱和现象。因此有一些改进操作,主要是结合ce loss等改进,比如: dice+ce loss,dice + focal loss等。

其中s和g分别代表result和GT的像素值。
Lc侧重于对文本区域和非文本区域的分割,对应Sn。M是由OHEM给出的训练mask,公式如下:

Ls是收缩的文本实例的损失,对应S1到Sn-1,公式如下

其中W是一个忽略非文本区域的像素的mask。
DBNet
1. 网络结构
首先,将输入的图像输入到一个特征金字塔的主干中。其次,将金字塔特征上采样到相同的尺度,并进行级联生成特征F。
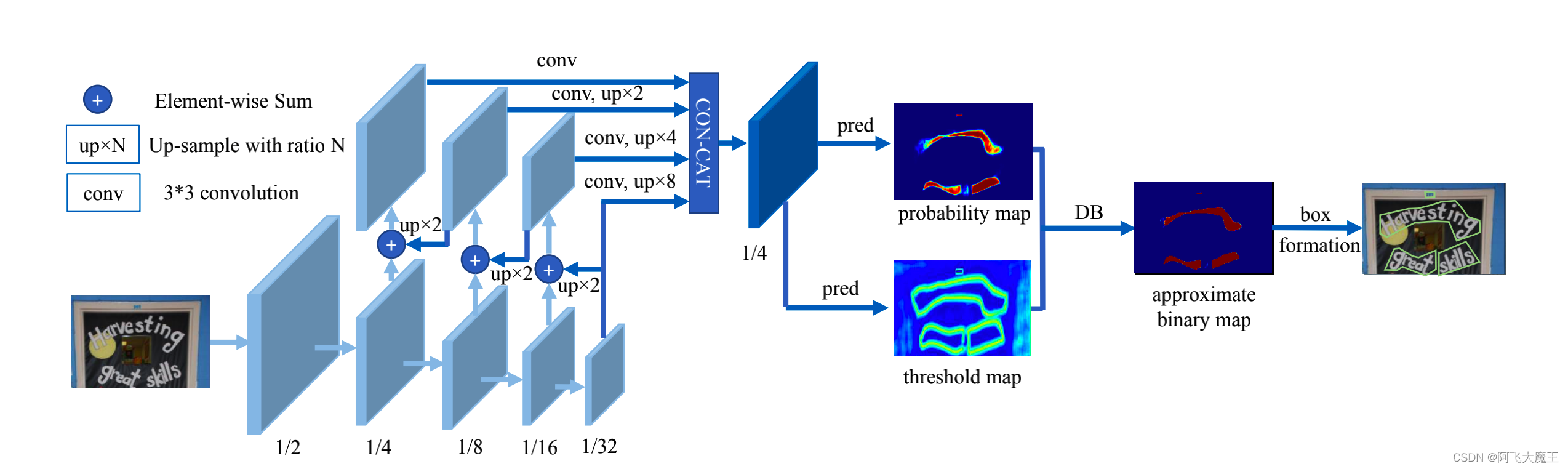
然后,利用特征F对概率图§和阈值图(T)进行预测。然后,用P和F计算出近似的二进制映射(Bˆ)。通常,计算二进制映射这个二值化过程可以描述如下:

在上式中描述的标准二值化方法是不可微的。因此,它不能在训练期间与分割网络一起进行优化。为了解决这个问题,论文进行改进 具有近似阶跃函数的二值化

其中,Bˆ为近似的二值映射;T为从网络中学习到的自适应阈值映射;k表示放大因子。根据经验设置为50。这个近似的二值化函数 表现类似于标准二值化函数(见图4),但是可微的,因此可以在训练期间随着分割网络进行优化。

2. label生成
label生成采用了PSENet中的方法,给定一个文本图像,其文本区域的每个多边形由一组segment来描述。
label通过偏移收缩到Gs,收缩的偏移D由原始多边形的周长L和面积A计算,其中r是收缩比,根据经验设置为0.4。

对于threshold label,按照上述公式扩张到Gd,Gs和Gd之间为threshold label。
3. 损失函数和优化
损失函数L可以表示为概率映射Ls的损失、二值映射Lb的损失和阈值映射Lt的损失的加权和

对Ls和Lb都应用了二进制交叉熵(BCE)损失。为了克服正负数量的不平衡,采用难例挖掘。Sl是正负比为1:3的采样集。

Lt计算为扩展文本多边形Gd内的预测和标签之间的L1距离之和:
4. 推理阶段
在推理期间,可以使用概率映射或近似的二进制映射来生成文本边界框,从而产生几乎相同的结果。为了提高效率,我们使用了概率映射,以便可以删除阈值分支。
推理分三个步骤:
1.首先对概率映射/近似二值二值映射进行二值化,得到二进制映射,阈值为0.2
2.从二值映射中获得连接区域,作为shrunk text regions
3.shrunk text regions通过以下公式扩张,r‘=1.5
















 901
901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









