







提出背景
通常的识别模型,例如CRNN,只使用RNN来隐式的建模语义信息。然而,我们发现基于RNN的方法存在一些明显的缺点,如时间依赖的解码方式和语义上下文的单向串行传输,这极大地限制了RNN的语义信息和计算效率。
其中引入了一个全局语义推理模块(GSRM),通过多路并行传输的方式来捕获全局语义上下文。

对比multi-way并行模式,one-way串行模式有以下几个缺点:
-
从每个解码时间步长只能感知非常有限的语义上下文。
-
当在较早的step出现错误解码时,可能会传递错误的语义信息并导致错误积累。
-
总是耗时且效率低。
因此文章提出了全局语义推理模块:global semantic reasoning module(GSRM),GSRM以一种新颖的多路并行传输的方式来考虑全局语义上下文。多路并行传输可以同时感知一个单词或文本行中所有字符的语义信息,从而更加鲁棒和有效。此外,错误的单个字符的内容只能对其他step造成相当有限的负面影响。
网络结构
SRN的网络结构如下图所示:
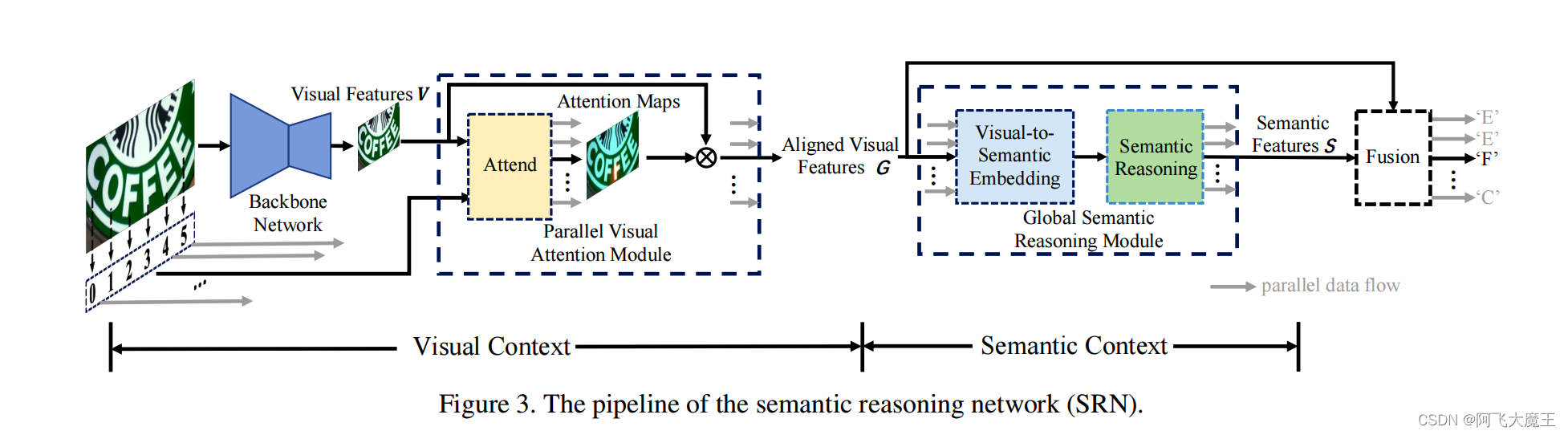
SRN包括以下4个模块:骨干网络、并行视觉注意模块(PVAM)、全局语义推理模块(GSRM)、视觉-语义融合解码器(VSFD)。
首先使用主干网络提取二维特征V。然后,使用PVAM生成N个对齐的一维特征G,其中每个特征对应于文本中的一个字符,并捕获对齐的视觉信息。然后将这N个1-d特征G输入GSRM以获取语义信息S,最后将对齐的视觉特征G和语义信息S融合,用VSFD来预测N个字符。.对于小于N的文本字符串,将填充“EOS”。
骨干网络:使用ResNet50+FPN。
PVAM:PVAM输入为二维特征,通过注意力机制,为每个字符输出一个特征图。

GSRM:结构由两个关键部分组成:视觉到语义的嵌入块和语义推理块。GSRM遵循了多路并行传输的思想,从而克服了单向语义上下文传递的缺点。使用与时间无关的e‘来代替e,这样可以进行多路并行传输,e’由视觉到语义的嵌入块生成,如图5。

VSFD:图像特征G和语义特征S属于不同的领域,它们在不同情况下对最终序列识别的权重应该是不同的。VSFD使用可训练的单元,利用权重来平衡在VSFD中来自不同领域的特征的贡献。
实验结果
SRN尝试了6个英文测试集上的结果。其中包括了包含弯曲文本的测试集CUTE-80。

Table5显示了不同识别模型在这6个数据集上的对比结果。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VM8yvJFj-1671774945547)(/image-20221222101501957.png)]](https://img-blog.csdnimg.cn/eaf2aa98518340498a6ebed55689a0a7.png)
Table6显示了SRN在中文数据集上的识别结果。

可以看出,SRN支持弯曲文本识别,同时也支持中文识别。















 1571
1571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









