







很多百度贴吧都有图片区,这里以最喜欢的能年犬的贴吧为例,见下图。
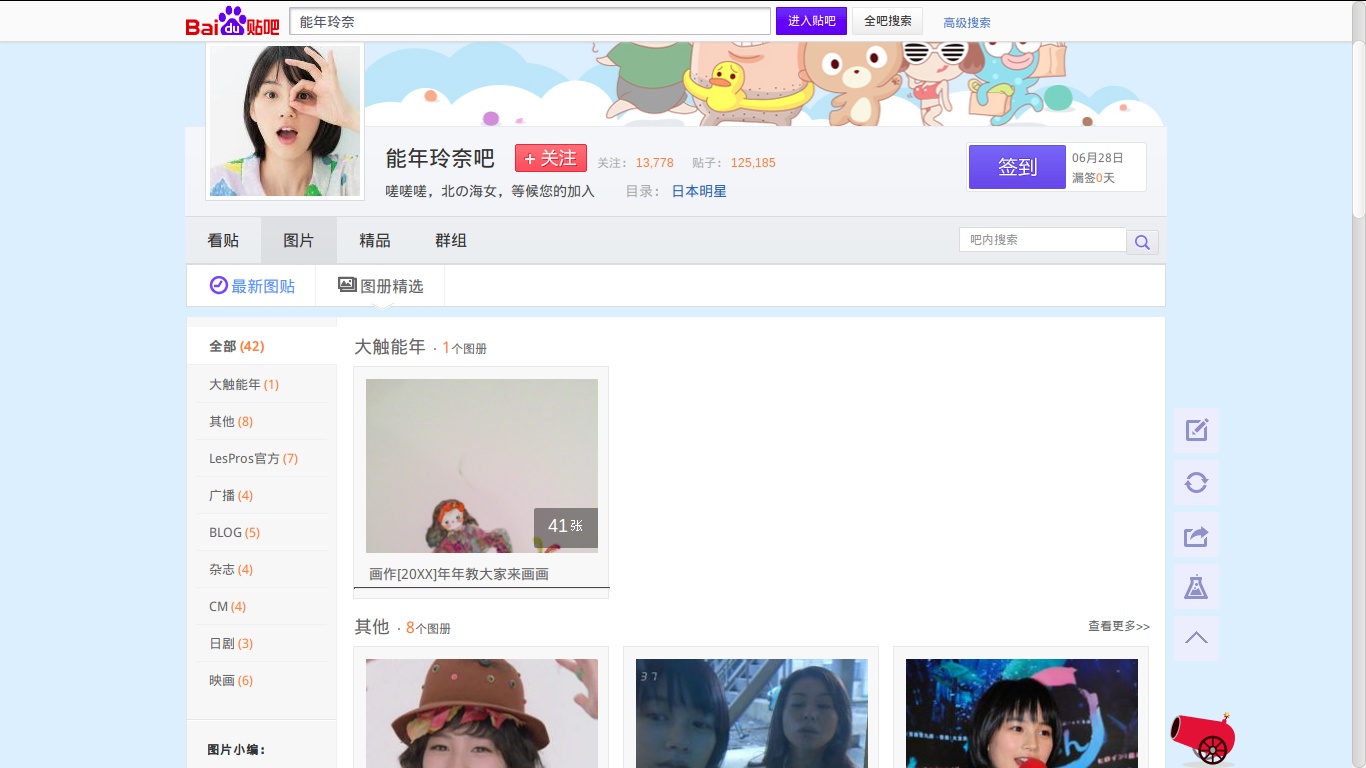
根据观察发现它的网址为"http://tieba.baidu.com/photo/g?kw=” + tieba_name + “&ie=utf-8"。会发现有不同的主题,大触能年,杂志等等。需要注意的是,在这个页面,每个主题最多显示三个图册,若该图册有多于三个主题,则需要进入主题url才能进入。这里点击Blog,经观察发现其url为“ http://tieba.baidu.com/f?kw=%E8%83%BD%E5%B9%B4%E7%8E%B2%E5%A5%88&tab=album&subtab=album_good&cat_id=d13370a98226cffc766d8a82b9014a90f603ea35 ”,构造网址需要的信息是“cat id”,它可由图片区的html代码得到。
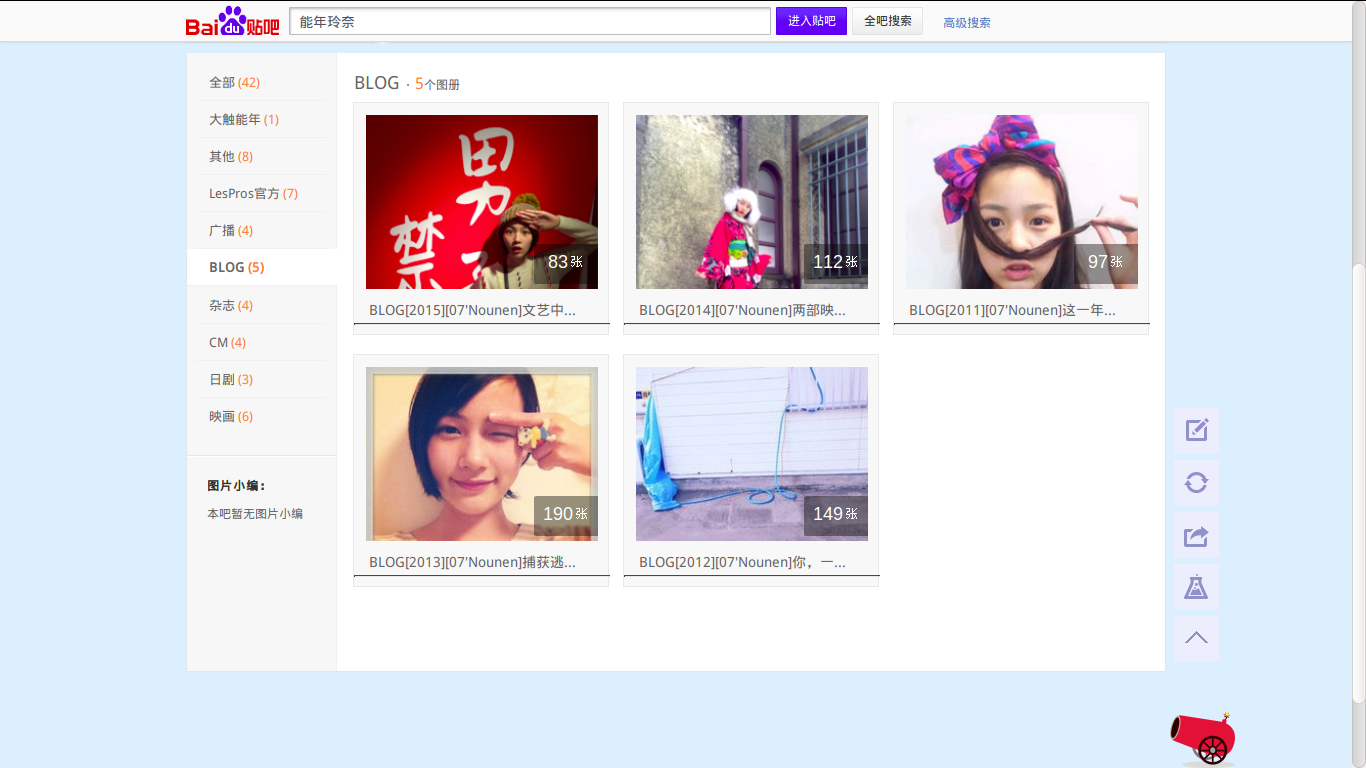
所写爬虫在运行后,可以指定贴吧,会返回该贴吧图片区有几个主题,选择主题后,会返回该主题所包含的图册名,选择后,即可对该图册进行下载,依然保存在all文件夹中。代码如下。
# -*- coding:utf-8 -*-
__author__ = 'fybhp'
import requests, json
from bs4 import BeautifulSoup
import os
import urllib
from allfiledir import allfilrdir
#requests用法,一个全局的会话对象.
s = requests.session()
#得到BeautifulSoup对象.
def get_soup(url):
h = s.get(url)
html = h.content
soup = BeautifulSoup(html, "html.parser")
return soup
#创建好按图册分类及图册名安排的目录.
def path(f, z, y):
#将z的相对路径加入f之后.
dir_name = os.path.join(f, z)
if not os.path.exists(dir_name):
print u'---正在创建目录\"' + z + '\"---'
os.makedirs(dir_name)
dir_name2 = os.path.join(dir_name, y)
if not os.path.exists(dir_name2):
print u'---正在创建目录\"' + y + '\"---'
os.makedirs(dir_name2)
return dir_name2
def check_xuanze_zhuti(xuanze_zhuti, zhuti):
add_url = ''
for yigezhuti in zhuti:
if xuanze_zhuti == yigezhuti[0]:
add_url = yigezhuti[1]
if add_url == '':
print u'该主题不存在,请重新输入。\n'
xuanze_zhuti = raw_input(u'请选择主题:\n').decode('utf-8')
check_xuanze_zhuti(xuanze_zhuti, zhuti)
else:
return add_url, xuanze_zhuti
def check_xuanze_tuce(xuanze_tuce, tuce):
tid = ''
pe = ''
for yigetuce in tuce:
if xuanze_tuce == yigetuce[0]:
tid = yigetuce[1]
pe = yigetuce[2][:-1]
if tid == '':
print u'图册不存在,请重新输入。\n'
xuanze_tuce = raw_input(u'请选择图册:\n').decode('utf-8')
check_xuanze_tuce(xuanze_tuce, tuce)
else:
return tid, pe, xuanze_tuce
def get_zhuti_neirong(main_url):
# 得到1,主题名;2,主题url;3,某主题图册数
zhuti_neirong = []
soup = get_soup(main_url)
zhuti_tag = soup.find_all('div', class_="grbh_left")
for item in zhuti_tag:
yige_zhutiming = item.a.text
yige_zhutiurl = item.a['href']
yige_tuceshu = item.span.text
zhuti_neirong.append([yige_zhutiming, yige_zhutiurl, yige_tuceshu])
return zhuti_neirong
def get_tuce_neirong(zhuti_url):
# 得到1,图册名;2,图册id;3,某图册中图片个数
tuce_neirong = []
soup = get_soup(zhuti_url)
tuce_tag = soup.find_all('div', class_="grbm_ele_wrapper")
for item in tuce_tag:
yige_tuceming = item.div.a.text
# 若图册最后为...,在创建目录时会出现差异,导致错误,在这里将...去掉。
if yige_tuceming[-3:] == '...':
yige_tuceming = yige_tuceming[:-3]
yige_tuceid = item.a['href']
yige_tupiangeshu = item.span.text
tuce_neirong.append([yige_tuceming, yige_tuceid, yige_tupiangeshu])
return tuce_neirong
# 处理json,得到所需要信息。
def get_pic_address(json_url):
pic_addres = []
h = s.get(json_url)
html = h.content.decode('unicode-escape')
target = json.loads(html)
for item in target['data']['pic_list']:
pic_addres.append(item['purl'])
return pic_addres
def pic_download(pic_address, dir_name2):
i = 1
for pic in pic_address:
pic1 = pic[:30]
pic2 = pic[-44:]
new_pic = pic1 + 'pic/item/' + pic2 # 获得高清图地址
basename = str(i) + '.jpg'
filename = os.path.join(dir_name2, basename)
if not os.path.exists(filename):
print 'Downloading ' + filename + '......'
urllib.urlretrieve(new_pic, filename)
else:
print filename + u'已存在,略过'
i += 1
def main():
tieba_name = raw_input(u'请输入贴吧名称:\n').decode('utf-8')
#构造图片区url.
main_url = 'http://tieba.baidu.com/photo/g?kw=' + tieba_name + '&ie=utf-8'
zhuti = get_zhuti_neirong(main_url)
if zhuti == []:
print u'抱歉,该贴吧图片区是空的。\n'
exit()
# print zhuti
for yigezhuti in zhuti:
print yigezhuti[0] + ' ' + yigezhuti[2] + u'个图册'
xuanze_zhuti = raw_input(u'请选择主题:\n').decode('utf-8')
add_url, xuanze_zhuti = check_xuanze_zhuti(xuanze_zhuti, zhuti)
#构造主题页面url.
zhuti_url = 'http://tieba.baidu.com/photo/g?kw=' + tieba_name + '&ie=utf-8&cat_id=' + str(add_url[10:])
tuce = get_tuce_neirong(zhuti_url)
# print tuce
for yigetuce in tuce:
print yigetuce[0] + ' ' + yigetuce[2] + u'图片'
xuanze_tuce = raw_input(u'请选择图册:\n').decode('utf-8')
tid, pe, xuanze_tuce = check_xuanze_tuce(xuanze_tuce, tuce)
json_url = 'http://tieba.baidu.com/photo/g/bw/picture/list?kw=' + tieba_name + '&alt=jview&rn=200&tid=' + str(
tid[3:]) + '&pn=1&ps=1&pe=' + str(pe) + '&info=1'
# print json_url
pic_address = get_pic_address(json_url)
# print pic_address
dir_name2 = path(allfilrdir+'/'+tieba_name, xuanze_zhuti, xuanze_tuce)
pic_download(pic_address, dir_name2)
if __name__ == '__main__':
main() 试了能年犬的贴吧,还有犬夜叉的贴吧,均运行无误。
效果如下图:
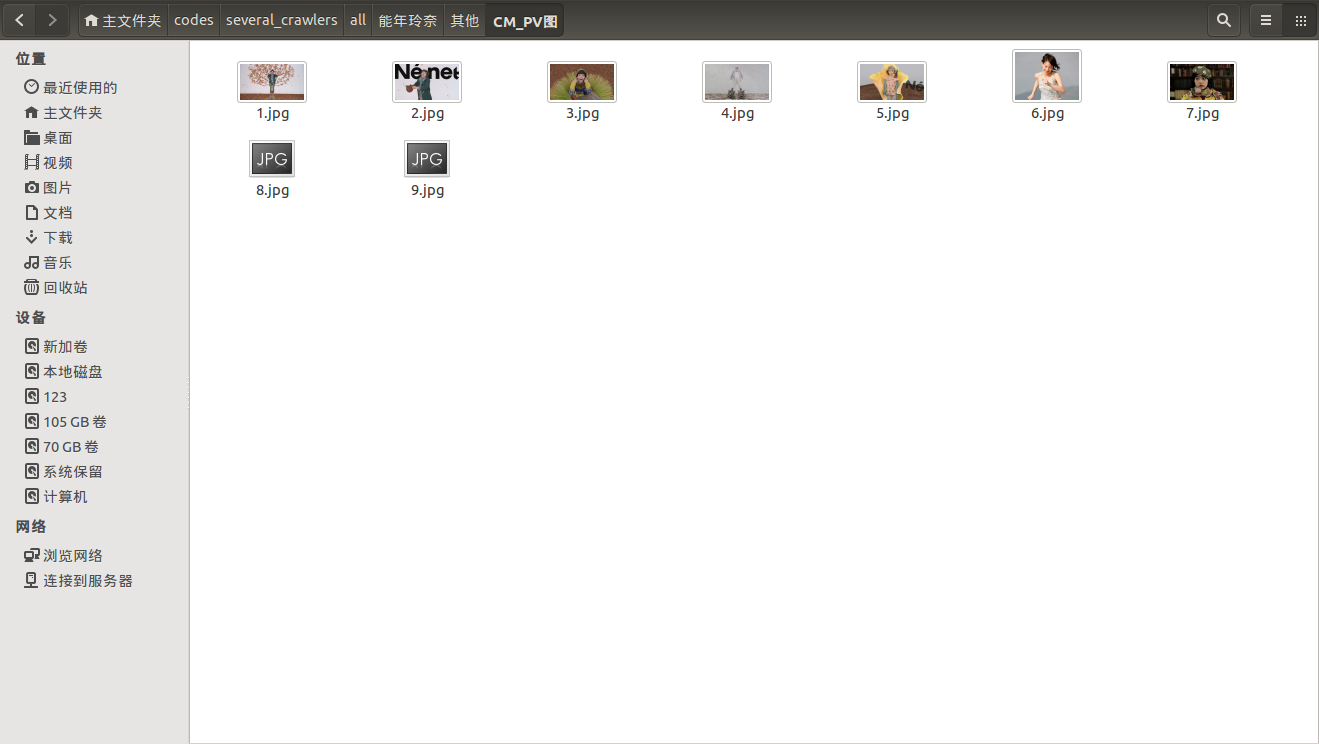
这个爬虫并不是一般地对贴吧某图片帖中的图片进行爬取,它爬虫具有通用性,且可交互,但可能并未测试尽所有可能的情况,若在使用过程中出现问题,欢迎指正!















 6529
6529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









