







之前用BeautifulSoup爬过糗事百科段子,但效率太低,自从使用了Scrapy框架以后,爬取大量信息再也不是事儿。今天要用这个强大的框架来爬取段子们,并将它们保存到本地的json文件中。
scrapy startproject qiushibaike创建好项目后,首先考虑要爬取的内容,为了简洁这里只爬取作者和段子信息,可以根据需要设置其他对象如点赞数、评论数等 。
import scrapy
class QiushibaikeItem(scrapy.Item):
author = scrapy.Field()
duanzi = scrapy.Field()pipelines.py与上篇文章中机票爬虫相同,均要保存为可显示中文的json文件。
import codecs,json
class QiushibaikePipeline(object):
def __init__(self):
self.file = codecs.open('qsbk.json', 'wb', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + '\n'
self.file.write(line.decode("unicode_escape"))
return item同时,修改settings.py中的代码如下:
BOT_NAME = 'qiushibaike'
SPIDER_MODULES = ['qiushibaike.spiders']
NEWSPIDER_MODULE = 'qiushibaike.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/533.21.1 (KHTML, like Gecko) Version/5.0.5 Safari/533.21.1'
ITEM_PIPELINES = {
'qiushibaike.pipelines.QiushibaikePipeline': 300,
}此次所用的爬虫与上次不同,只爬单个页面是不够的,要让它自己往链接上去探索新的世界。scrapy提供了一个爬虫类CrawlSpider可以胜任这项工作。
# -*- encoding: utf-8 -*-
__author__ = 'fybhp'
from qiushibaike.items import QiushibaikeItem
from scrapy.spiders import CrawlSpider,Rule
from scrapy.linkextractors import LinkExtractor
class QiushibaikeSpider(CrawlSpider):
name = "qsbk"
allowed_domains = ["qiushibaike.com"]
start_urls = ['http://www.qiushibaike.com/hot/']
rules = [
Rule(LinkExtractor(allow=r'http://www.qiushibaike.com/hot/.*?'), callback='parse_item', follow=True),
]
def parse_item(self,response):
for sel in response.xpath('//div[@class="article block untagged mb15"]'):
item = QiushibaikeItem()
item['author'] = sel.xpath('.//h2/text()')[0].extract()
item['duanzi'] = sel.xpath('div[@class="content"]/text()').extract()
yield item 这个爬虫类可以设定爬取规则rules,allow中为所规定让它继续爬取的网页的正则表达式,这里设定爬取糗事百科中的hot中的所有帖子。需要注意的是,当使用这个爬虫类时,不可重写parse函数 ,start_urls的回调函数变为了parse_item。rules规则中的callback亦用其作为回调函数,因为处理的页面是相同的,follow=True表示在start_urls之后的网页亦进行如上规则的爬取操作。
接下来输入scrapy crawl qsbk。结果,出现了问题!
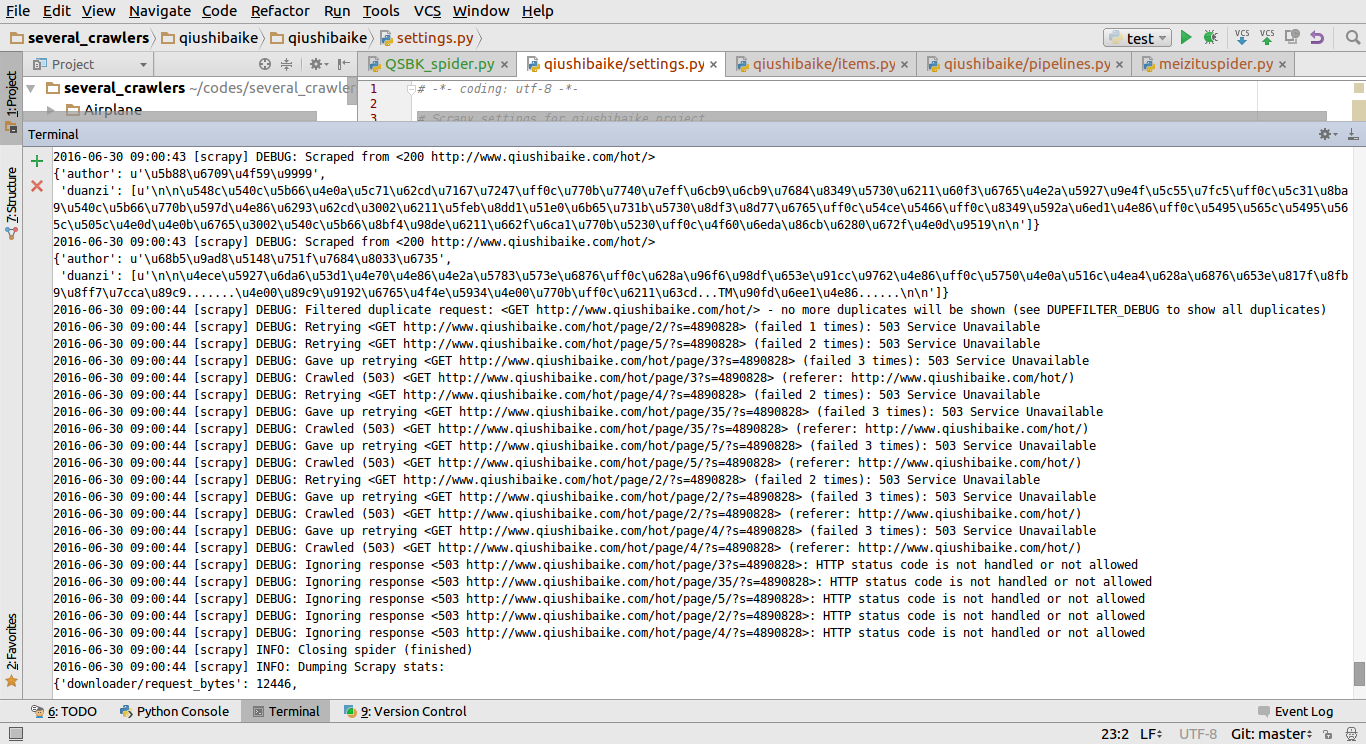
速度非常快,快得不正常,查看看到的json文件及scrapy log发现只爬到了第一页的内容,而其他的均是503状态码,被ban掉了,真的是命途多舛。查看scrapy文档,发现需要在settings.py中设置一个下载延迟。
DOWNLOAD_DELAY = 1 这告诉我们,爬虫不能下载得太暴力,有时得慢慢来。经实验发现,当该值较小时,比如0.1,0.25时,爬到的段子量与其成正相关,当大到一定值,比如上面的1S时,段子量不再增加,应该是爬到了所有hot区的段子。
细心的朋友可能发现,这网站的hot区有35页,一页21个段子,爬到的总段子量却有2040之多。经研究后发现,对于该网站,http://www.qiushibaike.com/hot/page/4/?s=4890821 这样网址的内容与http://www.qiushibaike.com/hot/page/4/ 中的内容是完全不同的。强大的scrapy应该将它们全部爬了下来。















 297
297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









