







之前写过贴吧图片区的爬虫,一次只能下载一个主题下的一个图册,而且还要手动输入,很不方便且效率有限,学了scrapy之后,使其变得更加强大,一次性可爬到贴吧图片区的所有图片,堪称史上最强。
首先要建立一个tieba_pic的scrapy project。
改写items.py。
import scrapy
class TiebaPicItem(scrapy.Item):
zhutiname = scrapy.Field()
tucename = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()
image_paths = scrapy.Field()一切照旧,之后是pipelines.py,与上一篇妹子图的基本相似。
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
from spiders.pic_spider import tiebaname
import os
import codecs
import json
class TiebaPicPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield scrapy.Request(image_url,meta={'item': item})
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
#item['image_paths'] = image_paths
return item
def file_path(self, request, response=None, info=None):
item = request.meta['item']
# 从URL提取图片的文件名
image_guid = request.url.split('/')[-1]
# 拼接最终的文件名,格式:full/{主题}/{图册}/图片文件名.jpg
filename = u'full/'+tiebaname+u'/{0[zhutiname]}/{0[tucename]}/{1}'.format(item, image_guid)
return filenamesettings.py亦做相应更改。
BOT_NAME = 'tieba_pic'
SPIDER_MODULES = ['tieba_pic.spiders']
NEWSPIDER_MODULE = 'tieba_pic.spiders'
ITEM_PIPELINES = {'tieba_pic.pipelines.TiebaPicPipeline1': 1,
'tieba_pic.pipelines.TiebaPicPipeline': 1}
IMAGES_STORE = '.' 爬虫部分与之前思路相同,由于scrapy内置多线程,可以同步爬取不同的主题,不同图册,明显提高了效率,观察电脑下载速度会发现可以达到该网络最大的下载速度。
根据输入构造图片区url,根据该页面的html文件得到不同主题的图册id,从而构造相应主题的url,进入之后再得到不同图册的id,构造出图册中图片加载时传输的json文件url,最后进行json解析,便可以得到所需要的图片地址完成下载啦!
# -*- coding:utf-8 -*-
__author__ = 'fybhp'
import scrapy
from scrapy.selector import Selector
from tieba_pic.items import TiebaPicItem
import json,sys
reload(sys)
sys.setdefaultencoding('utf-8')
class TiebapicSpider(scrapy.Spider):
name = "tiebapic"
allowed_domains = ["tieba.baidu.com"]
start_urls = []
def __init__(self):
global tiebaname
tiebaname = raw_input(u'贴吧名称:')
self.tiebaname = tiebaname
self.start_urls = ['http://tieba.baidu.com/photo/g?kw='+tiebaname+'&ie=utf-8']
def parse(self,response):
sel = Selector(response)
for_zhuti = sel.xpath('//a[@class="grbh_left_title"]/@href').extract()
if for_zhuti == []:
request = scrapy.Request(response.url,callback=self.parse_zhuti)
yield request
else:
for yige in for_zhuti:
zhuti_url = self.start_urls[0]+'&cat_id='+yige[10:]
#print zhuti_url
request = scrapy.Request(zhuti_url, callback=self.parse_zhuti)
yield request
def parse_zhuti(self,response):
sel = Selector(response)
item = TiebaPicItem()
for_tuce = sel.xpath('//div[@class="grbm_ele_wrapper"]')
for yige in for_tuce:
#item = TiebaPicItem()
item['zhutiname'] = sel.xpath('//a[@class="grbh_left_title"]/text()').extract()
if item['zhutiname'] == []:
item['zhutiname'] = u'未分类图册'
else:
item['zhutiname'] = item['zhutiname'][0]
item['tucename'] = yige.xpath('./div[@class="grbm_ele_title"]/a/text()').extract()[0]
if item['tucename'][-3:] == '...':
item['tucename'] = item['tucename'][:-3]
tuce_id = yige.xpath('./a[@class="grbm_ele_a grbm_ele_big"]/@href').extract()[0][3:]
#print item['tuce_id']
pic_num = yige.xpath('./a[@class="grbm_ele_a grbm_ele_big"]/span[1]/text()').extract()[0]
#print item['pic_num']
json_url = 'http://tieba.baidu.com/photo/g/bw/picture/list?kw='+self.tiebaname+'&alt=jview&rn=200&tid='+ tuce_id+'&pn=1&ps=1&pe='+pic_num+'&info=1'
yield scrapy.Request(json_url,meta={'item': item}, callback=self.parse_json)
def parse_json(self,response):
sel = json.loads(response.body,encoding='latin1')#response.body, encoding="unicode-escape",ensure_ascii=False)
item = response.meta['item']
for yige in sel['data']['pic_list']:
image = yige['purl']
pic1 = image[:30]
pic2 = image[-44:]
#item['image_urls']为列表而不是str.
item['image_urls'] = [pic1+'pic/item/'+pic2]
yield item 简单爬了些夏目友人帐吧(没有下载完就终止了,太多了…),效果基本是这个样子的。
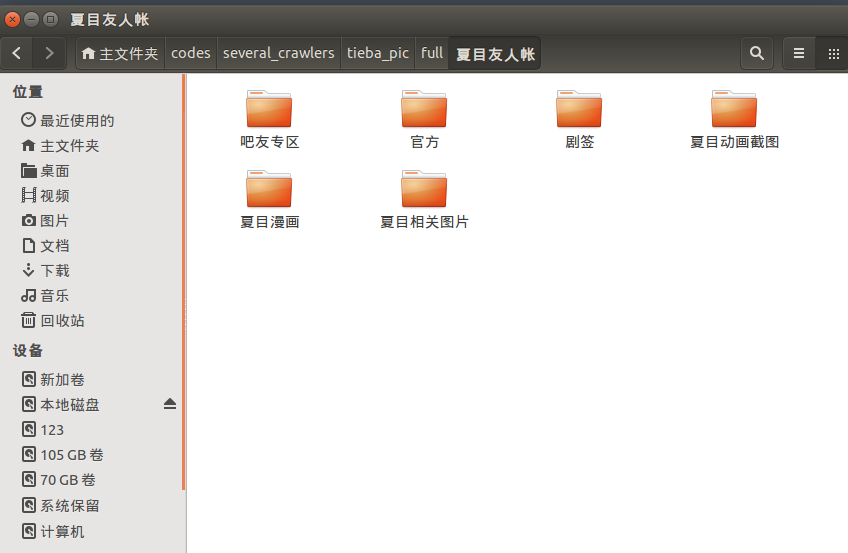
每个图片都在:
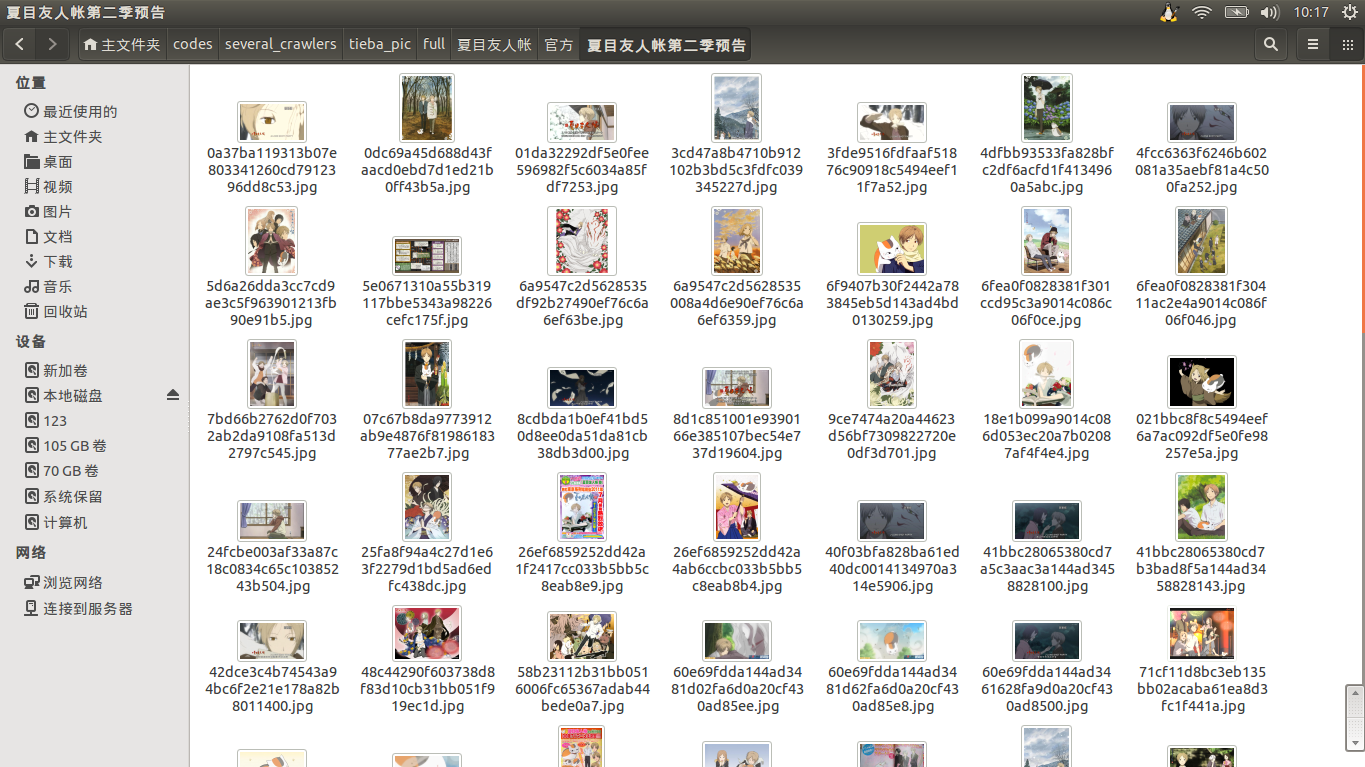
希望它能给或许喜欢某个作品的你,带来便捷与喜悦。















 1577
1577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









