







flashbench on windows
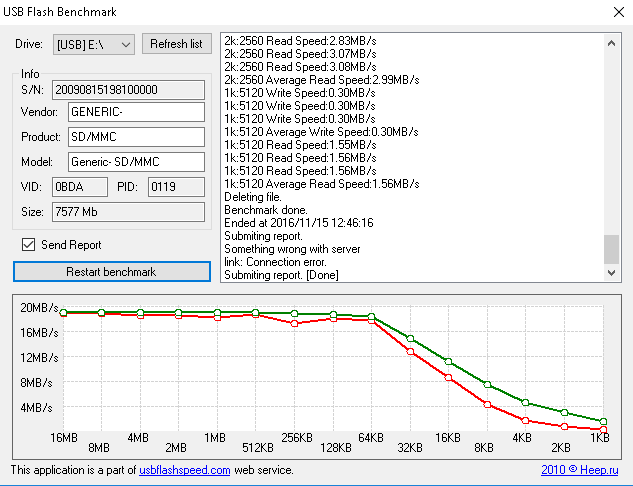
windows上的flashbench对u盘读写速度的测试非常简单,他把100M文件写入到盘中,这样就能测试写入速度,然后读取这个文件,从而获取读取速度。
这个软件使用起来也很简单,在界面的”Drive”后面选择u盘对应的盘符,然后点击Benchmark,就开始测试了,测试的结果会在软件的下半部分通过折线图显示出来。
在FlashBench界面的底部,你会看到16MB,8MB,4MB等字。这个代表每次测试时写入的单个文件的大小。由于flash介质在响应时间上会有差异,所以写入多个文件之间是会有间隔的,所以同样是100MB,1KB文件的数量会比16MB文件的多很多,那么传输小文件时实际的读写性能会下降的厉害。
flashbench on linux
下载git clone git://git.linaro.org/people/arnd/flashbench.git
另外一些关于这个软件的参数及使用的讨论http://lists.linaro.org/mailman/listinfo/flashbench-results
align
align测试用于发现erase block size和page size大小。
因为sd卡所用的flash颗粒是有wear leveling的,而现有的操作系统对于如何格式化和访问flash还没有成熟的方案,所以系统默认的格式化方案对于flash的访问速度和life time来说并不是最优的方案,选择一个最佳的erase block size 和page size可以提高sd卡的读写性能和延长使用寿命。
This is just a non-destructive read test. Sometimes read performance when spanning two eraseblocks will be slower than when reading only in one erase block. The “pre” reads just prior to an expected eraseblock boundary, the “on” reads spanning an eraseblock boundary, and the “post” reads just after an eraseblock boundary. Any spot where the “diff” times drop dramatically may indicate the likely eraseblock size or the likely write page size (write page size will always be smaller than an eraseblock).
上面这段话是从别的地方摘过来的,个人理解align测试的主要原理是跨erase block size读取n个字节的时间与在同一个erase block size读取n个字节的时间是不一样的。测试page size的原理也是一样的。
~ # flashbench -a -b 1024 /dev/mmcblk0
align 2147483648 pre 678us on 910us post 682us diff 230us
align 1073741824 pre 778us on 1.08ms post 754us diff 314us
align 536870912 pre 764us on 1.02ms post 736us diff 271us
align 268435456 pre 744us on 994us post 762us diff 242us
align 134217728 pre 774us on 1.05ms post 688us diff 314us
align 67108864 pre 738us on 984us post 725us diff 253us
align 33554432 pre 756us on 1.03ms post 740us diff 279us
align 16777216 pre 739us on 1.02ms post 725us diff 292us
align 8388608 pre 704us on 950us post 694us diff 251us
align 4194304 pre 694us on 937us post 689us diff 246us
align 2097152 pre 698us on 825us post 697us diff 127us
align 1048576 pre 694us on 783us post 701us diff 85us
align 524288 pre 695us on 785us post 706us diff 84.7us
align 262144 pre 696us on 784us post 706us diff 83.4us
align 131072 pre 691us on 780us post 705us diff 82.5us
align 65536 pre 691us on 781us post 704us diff 82.9us
align 32768 pre 697us on 786us post 710us diff 82.3us
align 16384 pre 702us on 779us post 691us diff 82.4us
align 8192 pre 696us on 735us post 698us diff 37.7us
align 4096 pre 699us on 735us post 698us diff 36.5us
align 2048 pre 700us on 734us post 696us diff 35.5us通过这个命令可以看出erase size可能为4194304和page size为16384
使用上面这个命令尝试使用不同的-b参数(1024, 2048, 4096…)来找出分布位置比较稳定的erase block size和page size,找出一个稳定的分布参考这篇文章beaglebone black简单入门(三),这个实验中发现了4k * 3 * N作为page是较为规律的,且突变都发生在12M,最后测试在这种情况下读写速度,发现使用24k作为page size,12M作为erase block size是比较好的。我这里在自己的板子上做了实验数据如下,可以看出erase block size比较稳定的分布在4194304,而page size分布在16384。
~ # flashbench -a -b 1024 /dev/mmcblk0
align 2147483648 pre 672us on 905us post 668us diff 235us
align 1073741824 pre 779us on 1.07ms post 751us diff 308us
align 536870912 pre 767us on 1.02ms post 728us diff 269us
align 268435456 pre 740us on 997us post 766us diff 244us
align 134217728 pre 772us on 1.04ms post 683us diff 315us
align 67108864 pre 730us on 982us post 721us diff 256us
align 33554432 pre 744us on 1.02ms post 730us diff 286us
align 16777216 pre 740us on 1.03ms post 728us diff 293us
align 8388608 pre 694us on 943us post 693us diff 249us
align 4194304 pre 692us on 936us post 683us diff 249us
align 2097152 pre 696us on 817us post 693us diff 123us
align 1048576 pre 693us on 781us post 703us diff 83.5us
align 524288 pre 693us on 788us post 707us diff 87.9us
align 262144 pre 693us on 780us post 704us diff 81.9us
align 131072 pre 691us on 779us post 705us diff 81.3us
align 65536 pre 694us on 779us post 701us diff 81.7us
align 32768 pre 693us on 785us post 701us diff 87.6us
align 16384 pre 701us on 774us post 691us diff 78us
align 8192 pre 695us on 734us post 699us diff 36.7us
align 4096 pre 699us on 733us post 699us diff 34.3us
align 2048 pre 698us on 732us post 697us diff 35.1us
~ #
~ # flashbench -a -b 2048 /dev/mmcblk0
align 2147483648 pre 705us on 921us post 701us diff 219us
align 1073741824 pre 792us on 1.08ms post 776us diff 301us
align 536870912 pre 789us on 1.03ms post 752us diff 262us
align 268435456 pre 761us on 1.01ms post 785us diff 234us
align 134217728 pre 798us on 1.06ms post 708us diff 303us
align 67108864 pre 756us on 997us post 747us diff 246us
align 33554432 pre 759us on 1.04ms post 751us diff 282us
align 16777216 pre 758us on 1.03ms post 744us diff 282us
align 8388608 pre 722us on 962us post 716us diff 242us
align 4194304 pre 714us on 956us post 712us diff 243us
align 2097152 pre 723us on 835us post 719us diff 114us
align 1048576 pre 719us on 794us post 727us diff 70.6us
align 524288 pre 721us on 803us post 730us diff 77us
align 262144 pre 719us on 795us post 728us diff 71.3us
align 131072 pre 717us on 790us post 728us diff 67.6us
align 65536 pre 720us on 797us post 729us diff 72.7us
align 32768 pre 718us on 799us post 727us diff 76.4us
align 16384 pre 727us on 790us post 716us diff 68.4us
align 8192 pre 722us on 749us post 724us diff 26us
align 4096 pre 720us on 745us post 719us diff 25.7us
~ #
~ # flashbench -a -b 4096 /dev/mmcblk0
align 2147483648 pre 756us on 943us post 756us diff 187us
align 1073741824 pre 846us on 1.11ms post 828us diff 276us
align 536870912 pre 848us on 1.05ms post 802us diff 228us
align 268435456 pre 803us on 1.03ms post 840us diff 209us
align 134217728 pre 843us on 1.08ms post 759us diff 280us
align 67108864 pre 806us on 1.02ms post 797us diff 220us
align 33554432 pre 805us on 1.06ms post 810us diff 253us
align 16777216 pre 813us on 1.05ms post 800us diff 246us
align 8388608 pre 764us on 991us post 771us diff 224us
align 4194304 pre 773us on 985us post 763us diff 217us
align 2097152 pre 762us on 857us post 768us diff 91.9us
align 1048576 pre 783us on 827us post 781us diff 44.6us
align 524288 pre 766us on 824us post 787us diff 47.6us
align 262144 pre 775us on 819us post 783us diff 40.1us
align 131072 pre 769us on 813us post 784us diff 37.1us
align 65536 pre 774us on 822us post 781us diff 44.5us
align 32768 pre 771us on 825us post 781us diff 48.6us
align 16384 pre 778us on 816us post 779us diff 37.5us
align 8192 pre 773us on 770us post 773us diff -2926ns
~ #
~ # flashbench -a -b 8192 /dev/mmcblk0
align 2147483648 pre 861us on 1.06ms post 859us diff 195us
align 1073741824 pre 956us on 1.22ms post 937us diff 272us
align 536870912 pre 952us on 1.17ms post 911us diff 235us
align 268435456 pre 905us on 1.13ms post 944us diff 203us
align 134217728 pre 948us on 1.19ms post 870us diff 279us
align 67108864 pre 912us on 1.12ms post 924us diff 202us
align 33554432 pre 920us on 1.16ms post 917us diff 244us
align 16777216 pre 908us on 1.16ms post 921us diff 242us
align 8388608 pre 870us on 1.09ms post 878us diff 216us
align 4194304 pre 872us on 1.08ms post 871us diff 209us
align 2097152 pre 874us on 951us post 874us diff 76.9us
align 1048576 pre 879us on 927us post 884us diff 45.6us
align 524288 pre 873us on 929us post 896us diff 44.7us
align 262144 pre 887us on 931us post 895us diff 39.8us
align 131072 pre 882us on 925us post 887us diff 40us
align 65536 pre 881us on 936us post 883us diff 54.5us
align 32768 pre 884us on 932us post 884us diff 48us
align 16384 pre 887us on 926us post 879us diff 43.2us
~ #
~ # flashbench -a -b 16384 /dev/mmcblk0
align 2147483648 pre 1.05ms on 1.24ms post 1.09ms diff 165us
align 1073741824 pre 1.15ms on 1.42ms post 1.13ms diff 279us
align 536870912 pre 1.15ms on 1.37ms post 1.11ms diff 235us
align 268435456 pre 1.1ms on 1.32ms post 1.15ms diff 196us
align 134217728 pre 1.15ms on 1.39ms post 1.08ms diff 277us
align 67108864 pre 1.11ms on 1.33ms post 1.11ms diff 212us
align 33554432 pre 1.1ms on 1.36ms post 1.12ms diff 254us
align 16777216 pre 1.1ms on 1.36ms post 1.12ms diff 250us
align 8388608 pre 1.07ms on 1.28ms post 1.09ms diff 201us
align 4194304 pre 1.08ms on 1.27ms post 1.07ms diff 197us
align 2097152 pre 1.08ms on 1.15ms post 1.08ms diff 72.7us
align 1048576 pre 1.1ms on 1.14ms post 1.09ms diff 47.1us
align 524288 pre 1.08ms on 1.13ms post 1.1ms diff 40.7us
align 262144 pre 1.09ms on 1.14ms post 1.1ms diff 43.2us
align 131072 pre 1.09ms on 1.14ms post 1.1ms diff 44.4us
align 65536 pre 1.09ms on 1.13ms post 1.09ms diff 44.3us
align 32768 pre 1.09ms on 1.14ms post 1.09ms diff 50us
~ #
~ # flashbench -a -b 32768 /dev/mmcblk0
align 2147483648 pre 1.56ms on 1.64ms post 1.59ms diff 62.1us
align 1073741824 pre 1.65ms on 1.82ms post 1.58ms diff 205us
align 536870912 pre 1.65ms on 1.77ms post 1.57ms diff 163us
align 268435456 pre 1.59ms on 1.71ms post 1.6ms diff 110us
align 134217728 pre 1.64ms on 1.79ms post 1.55ms diff 193us
align 67108864 pre 1.6ms on 1.72ms post 1.58ms diff 131us
align 33554432 pre 1.59ms on 1.74ms post 1.58ms diff 154us
align 16777216 pre 1.6ms on 1.76ms post 1.58ms diff 176us
align 8388608 pre 1.54ms on 1.67ms post 1.54ms diff 124us
align 4194304 pre 1.54ms on 1.67ms post 1.53ms diff 133us
align 2097152 pre 1.54ms on 1.56ms post 1.52ms diff 26.9us
align 1048576 pre 1.57ms on 1.56ms post 1.55ms diff 6.15us
align 524288 pre 1.55ms on 1.56ms post 1.57ms diff 4.59us
align 262144 pre 1.55ms on 1.57ms post 1.56ms diff 13.4us
align 131072 pre 1.55ms on 1.56ms post 1.57ms diff 5.72us
align 65536 pre 1.54ms on 1.56ms post 1.55ms diff 11.7us
~ # open-au
用于寻找allocation unit(au)的数目,open-au代表copy-on-write-then-erase能同时发生的个数,越多代表读写性能越好
what is copy-and-write-then-erase ?
if you want to change just one bit within an eraseblock the controller will often copy the entire eraseblock contents to another eraseblock but with your one bit change. The controller will then set the old eraseblock to be erased, possibly in the background.
flashbench软件会测试从-b到-e之间指定的文件块大小写到sd卡里面,然后测试不同的速度,通过–open-au-nr选项可以指定open allocation unit的个数,根据不同open allocation unit个数的测试情况,可以看出sd卡拥有多少个open allocation unit。
~ # flashbench -e 4194304 -b 16384 --open-au --open-au-nr=1 /dev/mmcblk0
4MiB 10.1M/s
2MiB 6.16M/s
1MiB 7.86M/s
512KiB 16.7M/s
256KiB 16M/s
128KiB 14.8M/s
64KiB 13M/s
32KiB 10.9M/s
16KiB 8.87M/s
~ #
~ # flashbench -e 4194304 -b 16384 --open-au --open-au-nr=2 /dev/mmcblk0
4MiB 10.9M/s
2MiB 16.8M/s
1MiB 16.6M/s
512KiB 16.6M/s
256KiB 15.8M/s
128KiB 14.7M/s
64KiB 12.8M/s
32KiB 10.8M/s
16KiB 8.53M/s
~ #
~ # flashbench -e 4194304 -b 16384 --open-au --open-au-nr=8 /dev/mmcblk0
4MiB 14.2M/s
2MiB 16.8M/s
1MiB 13.8M/s
512KiB 16.6M/s
256KiB 15.9M/s
128KiB 14.7M/s
64KiB 12.7M/s
32KiB 10.7M/s
16KiB 8.45M/s
~ #
~ # flashbench -e 4194304 -b 16384 --open-au --open-au-nr=9 /dev/mmcblk0
4MiB 16.7M/s
2MiB 7.2M/s
1MiB 3.22M/s
512KiB 1.44M/s
256KiB 692K/s
128KiB 344K/s
64KiB 170K/s
32KiB 84.9K/s
16KiB 42.5K/s 从上面看出来是在–open-au-nr=9时候的速度和前面比明显变慢了。所以–open-au-nr=8了。
为了更符合实际的情况,常常在测试的时候加上参数-r,表示随机写。
~ # flashbench -e 4194304 -b 16384 --open-au --open-au-nr=1 -r /dev/mmcblk0
4MiB 18.4M/s
2MiB 3.61M/s
1MiB 3.13M/s
512KiB 3.13M/s
256KiB 1.12M/s
128KiB 576K/s
64KiB 324K/s
32KiB 157K/s
16KiB 75.3K/s
~ #
~ # flashbench -e 4194304 -b 16384 --open-au --open-au-nr=2 -r /dev/mmcblk0
4MiB 5.12M/s
2MiB 16.6M/s
1MiB 12M/s
512KiB 4.51M/s
256KiB 1.12M/s
128KiB 591K/s
64KiB 323K/s
32KiB 156K/s
16KiB 74.8K/s
~ #
~ # flashbench -e 4194304 -b 16384 --open-au --open-au-nr=8 -r /dev/mmcblk0
4MiB 16.8M/s
2MiB 13.8M/s
1MiB 12M/s
512KiB 4.29M/s
256KiB 1.09M/s
128KiB 592K/s
64KiB 322K/s
32KiB 156K/s
16KiB 74.6K/s
~ #
~ # flashbench -e 4194304 -b 16384 --open-au --open-au-nr=9 -r /dev/mmcblk0
4MiB 14.4M/s
2MiB 5.26M/s
1MiB 3.21M/s
512KiB 1.44M/s
256KiB 692K/s
128KiB 344K/s
64KiB 170K/s
32KiB 84.9K/s
16KiB 42.4K/s fat
we can check if the first few eraseblocks have any special ability. Some cards will provide for the first few eraseblocks to be backed by SLC flash instead of MLC, or otherwise improve the performance of these special eraseblocks. This is important when using the card with the FAT filesystem as all the metadata is stored in the beginning of the disk and will get the most wear and small writes.
~ # flashbench /dev/mmcblk0 -f -e 4194304
4MiB 16.7M/s 32.2M/s 16.7M/s 16.8M/s 16.7M/s 16.7M/s
2MiB 16.8M/s 29.7M/s 16.6M/s 16.8M/s 16.8M/s 16.8M/s
1MiB 16.8M/s 29.9M/s 16.7M/s 16.8M/s 16.8M/s 16.7M/s
512KiB 16.6M/s 29.7M/s 16.5M/s 16.8M/s 16.7M/s 16.7M/s
256KiB 16.1M/s 25.8M/s 16M/s 16.1M/s 16M/s 16.1M/s
128KiB 14.7M/s 20M/s 14.6M/s 14.9M/s 14.8M/s 14.9M/s
64KiB 13M/s 20.5M/s 12.9M/s 13M/s 13M/s 12.9M/s
32KiB 11M/s 15.2M/s 10.8M/s 11M/s 10.9M/s 10.9M/s
16KiB 8.89M/s 9.97M/s 8.92M/s 8.95M/s 8.97M/s 8.96M/s 从上面可以看出来在第二列的速度明显比周围的速度快很多,可以作为fat分区会提高读写效率。
scatter
flashbench --scatter --scatter-order=N --scatter-span=N -b blocksize /dev/mmcblk0 -o /tmp/scatter_result
it is mainly a way to detect the block size if the -a test gives no conclusive result
–scatter
–scatter-order=M 定义scatter测试读取的区域,那么读取的区域的总大小为blocksize * 2^M (-b指定blocksize大小)
–scatter-span=N 一次读取的block的数量,那么一次读取的大小为blocksize * 2^N
-b 指定blocksize大小
-o 指定测试结果的输出文件
然后使用工具gnuplot将scatter_result绘制成二维图像,gnuplot -p -e ‘plot “scatter_result”’。
下面是我在自己这边的平台上测试的数据:
flashbench --scatter --scatter-order=11 --scatter-span=1 -b 16384 /dev/mmcblk0 -o /tmp/scatter_result
flashbench --scatter --scatter-order=11 --scatter-span=2 -b 16384 /dev/mmcblk0 -o /tmp/scatter_result
横轴为32M,因为这里的–scatter-order=11,所以整个scatter测试覆盖的区域是16384 * 2^11=32M,是sd卡最开头的32M
纵轴代表一次读取–scatter-span指定这么多个blocksize所要的时间,单位是ms
图中的每一个”+”都是一个测试结果,每次测试往后偏移blocksize大小,然后测试读取–scatter-span指定个数的blocksize大小的文件的时间,就得到一个”+”,横坐标代表偏移的位置,纵坐标代表读取–scatter-span指定个数的blocksize大小的文件的时间。
interval
用于分析从读取512 bytes到读取512 * 2^(N-1) bytes之间的速度与大小的关系,并将这些值做线性回归分析。
–interval-order=N 指定依次测试从512 bytes到512 * 2^N-1 bytes大小的blocksize
-c 指定测试的次数,这样每次测试的时候依次往后偏移9 * blocksize大小,指定次数测试完后会计算平均值,最大值,最小值等。
~ # flashbench -i --interval-order=13 -b 16384 /dev/mmcblk0
512 bytes: min 408us avg 493us max 924us: 1.25414 MB/s
1024 bytes: min 439us avg 462us max 508us: 2.33469 MB/s
2048 bytes: min 466us avg 488us max 510us: 4.39144 MB/s
4096 bytes: min 535us avg 550us max 571us: 7.66278 MB/s
8192 bytes: min 633us avg 687us max 744us: 12.9385 MB/s
16384 bytes: min 906us avg 941us max 1.02ms: 18.0824 MB/s
32768 bytes: min 1.34ms avg 1.43ms max 1.54ms: 24.4092 MB/s
65536 bytes: min 2.2ms avg 2.27ms max 2.51ms: 29.8218 MB/s
131072 bytes: min 3.34ms avg 3.7ms max 4.32ms: 39.1904 MB/s
262144 bytes: min 6.22ms avg 7.17ms max 8.06ms: 42.1701 MB/s
524288 bytes: min 11.8ms avg 15ms max 21.4ms: 44.5035 MB/s
1048576 bytes: min 27.7ms avg 30.5ms max 43.6ms: 37.871 MB/s
2097152 bytes: min 55ms avg 61.5ms max 86.6ms: 38.1285 MB/s
38.4339 MB/s, 62.2us access time
bytes 512, time 408248 overhead 332736
bytes 1024, time 438602 overhead 349769
bytes 2048, time 466362 overhead 350886
bytes 4096, time 534532 overhead 365769
bytes 8192, time 633148 overhead 357813
bytes 16384, time 906074 overhead 417593
bytes 32768, time 1342443 overhead 427672
bytes 65536, time 2197584 overhead 430232
bytes 131072, time 3344490 overhead -128025
bytes 262144, time 6216344 overhead -666496
bytes 524288, time 11780814 overhead -1.92268e+06
bytes 1048576, time 27688070 overhead 343282
bytes 2097152, time 55002223 overhead 374836program
~ # flashbench -p /dev/mmcblk0
2MiB 7.62M/s 10.3M/s 12.1M/s 35.4M/s 6.02M/s 7.71M/s 7.6M/s 38M/s
1MiB 11.4M/s 13.3M/s 13.3M/s 38.2M/s 6.21M/s 7.68M/s 7.66M/s 37.5M/s
512KiB 16.6M/s 16.7M/s 16.7M/s 37.9M/s 7.63M/s 4.83M/s 5.2M/s 37M/s
256KiB 15.3M/s 16.1M/s 16.1M/s 36.3M/s 2.68M/s 1.22M/s 1.16M/s 36.6M/s
128KiB 14.4M/s 14.9M/s 14.8M/s 34.4M/s 2.17M/s 1.67M/s 1.68M/s 33.8M/s
64KiB 12.9M/s 13M/s 13.1M/s 30.3M/s 1.27M/s 1.04M/s 1.05M/s 29.8M/s
32KiB 11M/s 11M/s 10.9M/s 24.5M/s 476K/s 441K/s 438K/s 24.1M/s
16KiB 9.93M/s 9.92M/s 9.96M/s 18M/s 273K/s 253K/s 247K/s 17.8M/s
8KiB 3.74M/s 3.75M/s 3.75M/s 11.6M/s 3.8M/s 3.82M/s 3.82M/s 11.5M/s
4KiB 1.52M/s 1.6M/s 1.6M/s 6.8M/s 1.92M/s 1.93M/s 1.92M/s 6.73M/s
2KiB 604K/s 683K/s 683K/s 3.71M/s 980K/s 979K/s 979K/s 3.67M/s
1KiB 246K/s 273K/s 273K/s 1.94M/s 470K/s 469K/s 472K/s 1.91M/s
512B 264K/s 286K/s 286K/s 1.04M/s 243K/s 243K/s 244K/s 1.04M/s 第一列代表每次读写文件的大小,测试的原理是写4M的文件,对于2M的大小,测试两次,对于1M的大小,测试4次,依次类推。
后面的几列依次是linear write zeros, linear write ones, linear write 0x5a, linear read,
random write zeros, random write ones, random write 0x5a, random read的速度
补充一下:
线性读写:每次读写完N字节后,偏移也加N字节,然后从偏移处继续读写,这样写指针在进行新的一次读写的时候不需要移动。
随机位置读写:写完上一笔数据后,重新移动写指针到别的某个位置,然后在进行一次新的读写。
随机内容读写:写的内容是随机的内容,这个对读写速度的测试不影响。
随机位置读写由于要重新移动写指针,而线性读写不需要移动写指针,所以随机位置的读写速度明显要比线性读写的速度慢。
通过dd测试sd卡读写速度
使用dd命令来测试sd卡读写速度,测试内容如下:

从图中可以看出来,在输入分别为/dev/zero,/dev/random, /dev/urandom,写卡的速度是有很大差别的,与上面使用flashbench测试随机写1M文件的速度25.2M/s相比小很多,看起来dd测试速度的时候将读取输入的时间也算在内了,所以速度相对来说小很多,而且在读取/dev/zero,/dev/random, /dev/urandom这3个不同的输入的时间的差别也相差很大。
所以,dd测试速度的时候将读取输入的时间也算在内了,使用dd测试sd卡速度是不够准确的。
通过dd测试sd卡真实容量
Create a file with the required capacity, filled with random data. We’re writing blocks of 1024 bytes, so adjust the count to the capacity required (16GB in my case).
dd if=/dev/urandom of=rnd_init_data bs=1024 count=16000000
Now, we write the data to the SD card.
$ dd if=rnd_init_data of=/dev/sdb bs=1024 count=16000000
15558145+0 records in
15558144+0 records out
15931539456 bytes (16 GB) copied, 536.286 s, 29.7 MB/sYou can see, we didn’t manage to write all the bytes to the card. This is expected, as we don’t know the capacity of the card down to the last byte. As long as the capacity reported by dd (16 GB) is close to the expected result, we’re happy.
Now, we copy the bytes written to a new file, which we use for later comparison. Notice here the count, which we adapted to the bytes written to the card (15931539456 / 1024 = 15558144). I am sure this can be done easier using tools like truncate, but I didn’t want to start messing with programs that I don’t know by heart.
$ dd if=rnd_init_data of=rnd_written_data bs=1024 count=15558144
$ rm -f rnd_init_dataRead back the data from the card:
$ dd if=/dev/sdb of=rnd_read_data bs=1024 count=15558144
Finally, we’re comparing the two data files:
$ md5sum rnd*
dfed784abed6662926eb01f7fb5359ca rnd_written_data
dfed784abed6662926eb01f7fb5359ca rnd_read_data通过fio测试sd卡读写速度
使用fio命令测试sd卡读写速度,测试命令
读:fio -filename=/dev/mmcblk0 -direct=1 -numjobs=1 -thread -group_reporting -ioengine=psync -iodepth=1 -size=4M -name=mytest -bs=1M -rw=read
随机读:fio -filename=/dev/mmcblk0 -direct=1 -numjobs=1 -thread -group_reporting -ioengine=psync -iodepth=1 -size=4M -name=mytest -bs=1M -rw=randread
写:fio -filename=/dev/mmcblk0 -direct=1 -numjobs=1 -thread -group_reporting -ioengine=psync -iodepth=1 -size=4M -name=mytest -bs=1M -rw=write
随机写:fio -filename=/dev/mmcblk0 -direct=1 -numjobs=1 -thread -group_reporting -ioengine=psync -iodepth=1 -size=4M -name=mytest -bs=1M -rw=randwrite测试的结果与使用flashbench测试结果对比如下:

fio所测试的速度相对flashbench所测试的速度稍微慢一点,在合理的偏差范围内,但基本的速度随着读写文件的大小变化情况是一致的。
















 3999
3999











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











