










需求背景:
前段时间入组了一个大型C/S架构的项目(目前代码量300万+左右),入组时项目的开发已经进入了中后期。随着常规需求的研发完成,随之而来的就是性能问题,作为一个C/S架构的应用软件,客户端使用时效率问题无疑也是重点之一。产品是个BIM(Building Information Modeling建筑信息模型)相关的算量软件,类似AutoCAD、Revit。优化专项任务要做的事简单一句话就是:让算量软件算得更快。
优化思路:
效率优化的三个层次:系统层次、算法层次、代码层次。
系统层次就是软件架构和流程等方面来优化,关注的业务点偏弱;
算法层次主要是针对不同具体的计算策略来优化,业务耦合度高;
代码层次主要是编码技巧和风格,跟业务无关。
效率优化的三个准备:心理准备、业务准备、工具准备。
心理准备:通常来说优化的时候是写函数的时候2倍还多,优化不是容易的事,不然别人正常开发的时候都写出了高质量高效率的代码。
业务准备:脱离了业务的优化是不成熟的优化,要优化程序需要比原作者更了解其业务需求背景,需要学习业务多跟需求人员和测试以及原作者沟通。
工具准备:工欲善其事必先利其器,打蛇打七寸。根据二八法则20%是重要的其决定作用,通过工具精准找到程序真正的效率热点瓶颈达到事半功倍的作用。需要熟悉常用的效率内存分析工具,常用的有AQTime(效率)、VTune(效率)、VLD(内存)、UMDH(内存)等。
设计实现:
一、系统层次
问题抽象三维仿真的建筑中多个图元(墙梁板柱等)的算量问题,从系统层次也就是架构和流程设计上来优化无疑效果是最明显也是最通用的方式。
1.多线程:第一步优化多个图元的并行计算,也就是多线程计算。主要设计思想,开始计算的时候创建一个线程池,线程池的线程核数根据当前用户CPU核数动态确定,因为不同电脑核数不一样,其次线程数设置大于CPU数的话不是真正的并行,所以线程数设置为CPU数能最大限度的利用用户CPU。把每个图元的计算打包成一个小的子任务给线程,所有图元计算完后统一释放线程池中的线程。
2.多进程:为了进一步提供并行计算,由于单机的CPU核数是有限的,单机的多进程没意义。所以引入多电脑的分布式计算(基于局域网的)。主要思想就是把计算任务以楼层为单位拆分成一个个独立的计算任务包,通过分布式系统分化给局域网中的计算节点,计算节点计算完后把结果返回到主机进行汇总。
基于多线程实现计算线程池设计主要UML图如下:
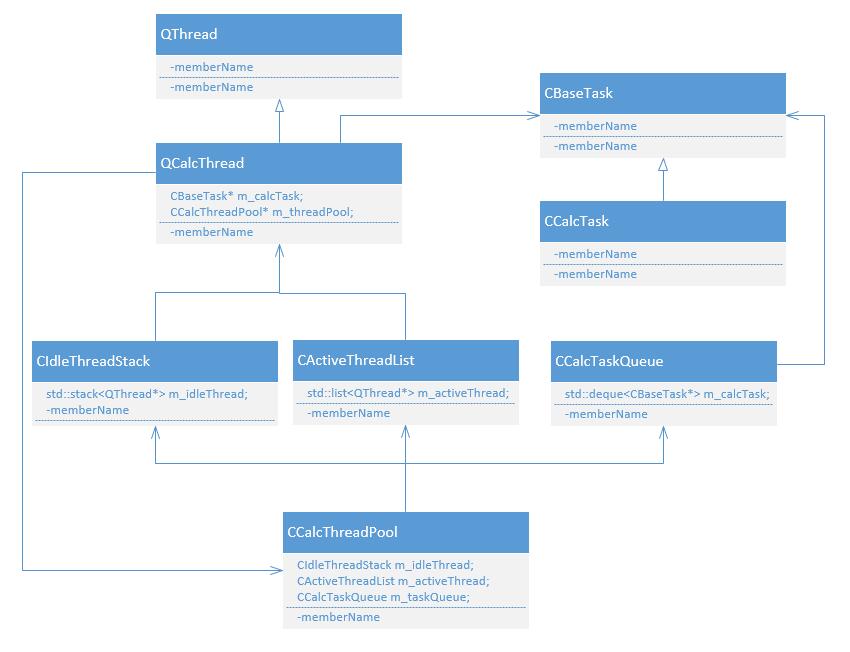
主要类说明:
a、CBaseTask:计算任务基类,每个构件模型的具体计算任务类从该类派生。
b、CCalcTask:具体的构件模型计算任务类,从CBaskTask派生。
c、CCalcTaskQueue:任务队列,内部采用std::deque双向队列来存储计算任务,能实现计算任务优先级控制,普通任务直接入队,优先级高的计算任务可以直接插入队首,外部线程池调度的时候默认从队首取任务。
d、QCalcThread:具体的计算线程类,由于项目是基于Qt框架,所以从Qt的QThread派生。主要成员包含计算任务、和所属线程池。
e、CIdleThreadStack:空闲计算线程堆栈,内部采用std::stack栈来实现,主要是利用其后进先出的特性,当一个计算线程执行完任务此处任务队列中没有任务的话,此线程会被push压入空闲线程堆栈,当有新的计算任务的时候,刚被压入的计算线程会被pop弹出来用于执行新的计算任务。由于线程是刚被push进去的,该线程对应内存空间位于内存的概率比其他线程大,从而在一定程度上可以节省系统页交换文件的开销。
f、CActiveThreadList:当前正在计算的活动线程列表,内部采用std::list链表来实现,主要是方便计算完后随时删除。
g、CCalcThreadPool:计算线程池,用于管理调度空闲线程堆栈、活动线程列表以及任务队列。
基于多进程的计算(也就是所谓的分布式计算):
单机上多线程引入后计算效率有了质的提升,要想再进一步提高计算效率,下一个突破口就是多进程计算,但是一个电脑的CPU核数是固定的,也就是说单机的多进程计算对计算效率提升起不到作用,进而做基于局域网的分布式计算。
a、第一步需要考虑计算任务是否能够拆分?由于多线程计算都实现了,所以不同构件模型的计算任务是可以拆分并行的。以什么样的粒度拆分?如果以单个模型为粒度太小,结合业务建筑的特点最后以楼层为单位拆分,每个楼层包含了许多构件模型。
b、局域网中其他电脑节点怎么才能独立完成计算?必要的数据信息+计算策略,也就是涉及到构件模型数据信息的传输和包含不同计算策略的计算进程。
c、任务的分配调度、数据的传输等等,上面涉及的几个关键点解决了一个简单基于局域网的分布式计算系统就完成了。
主要流程和架构设计如下:
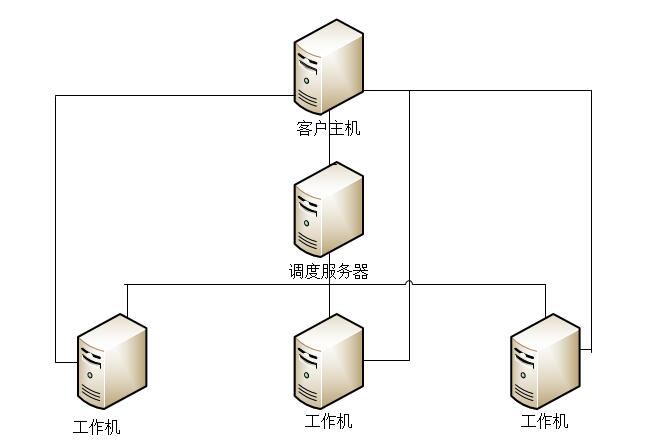
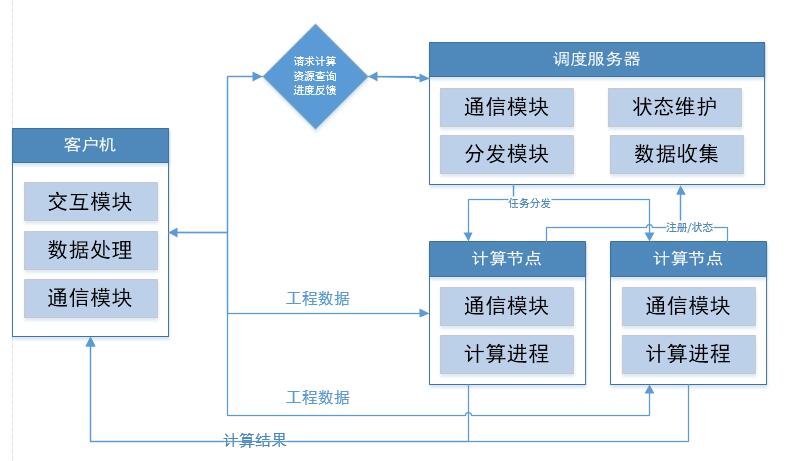
客户机:
交互模块:分布式计算的启动和停止、获取当前局域网计算节点资源信息(电脑名、电脑配置、版本信息等)、显示不同节点计算任务进度信息。
数据处理:工程数据信息的初始化和准备、以及计算任务的拆分、计算结果汇总。
通信模块:数据收发(计算任务数据发送到计算节点、接收计算节点返回的结果)、命令收发(计算任务请求和终止、计算进度、状态、资源查询)
调度服务器:
通信模块:计算节点信息维护、客户机计算请求维护。
分发模块:任务分发调度策略。
计算节点:
通信模块:计算任务和工程数据的接收、计算结果的发送、定时发送当前节点状态和信息。
计算进程:包含所有的计算策略、输出计算结果和计算进度。
技术选型和对比:
开源网络库:
ACE:重量级的网络库,比较复杂,20万+的代码量,支持跨平台,适合大型网络。内部主要reactor模式和Proactor模式。
boost的ASIO:异步IO库,封装了Socket的常用操作,中等复杂。内部实现Proactor模式。
Libevent(选用):C语言编写的轻量级基于事件驱动的高性能网络库,复杂度低,跨平台。内部实现reactor模式。
消息队列:
ApacheMQ:比较成熟,依赖JDK,需要中心服务,性能一般。
ZeroMQ(选用):独立的API开发模式灵活,基于C语言开发的性能好。
备注:详细设计与实现见后续更新,未完待更新!!!















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









