






本文分析一下Taier的启动过程
参考官方文档,启动用的命令是 ./bin/taier.sh start
1:找到taier.sh
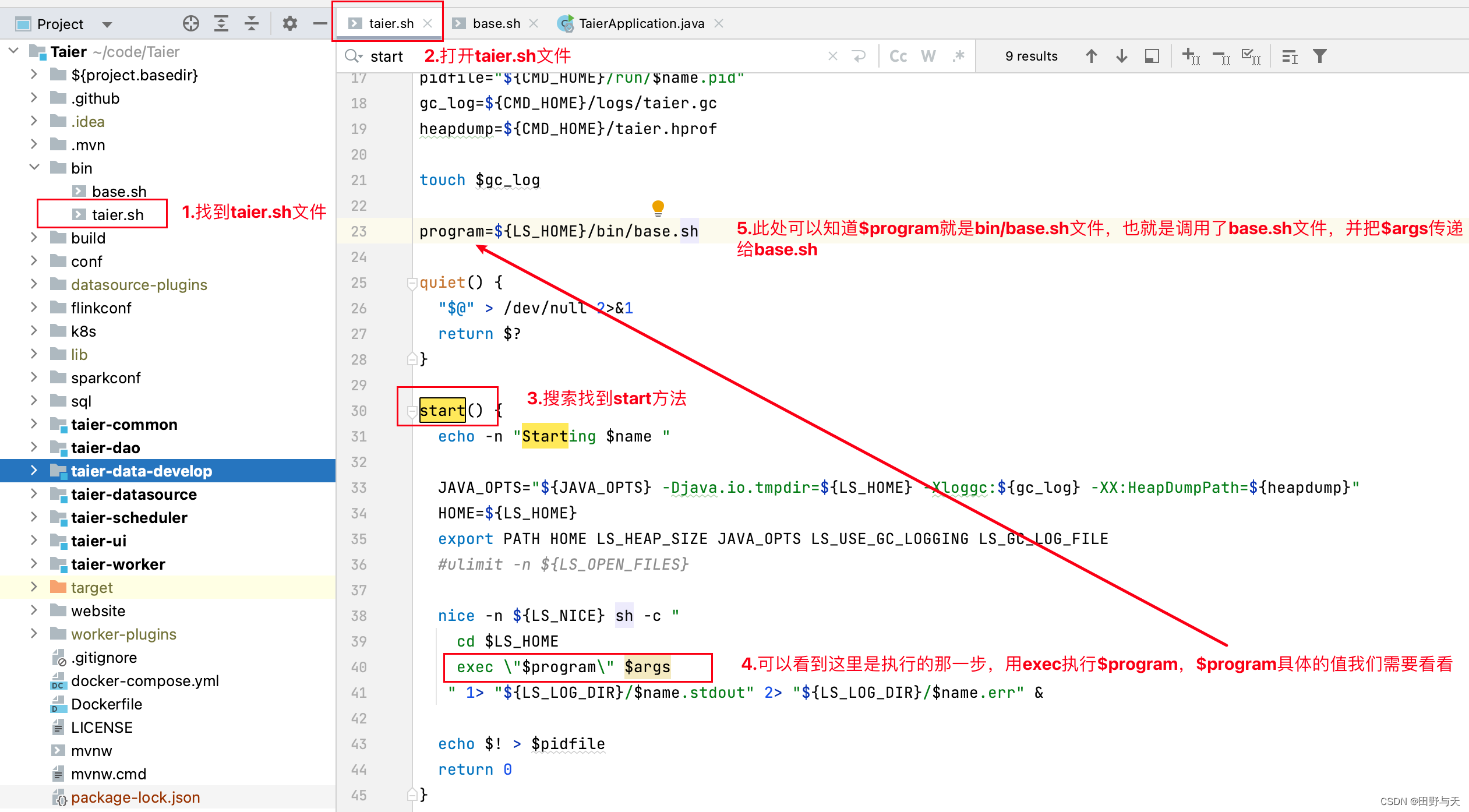
2:找到base.sh
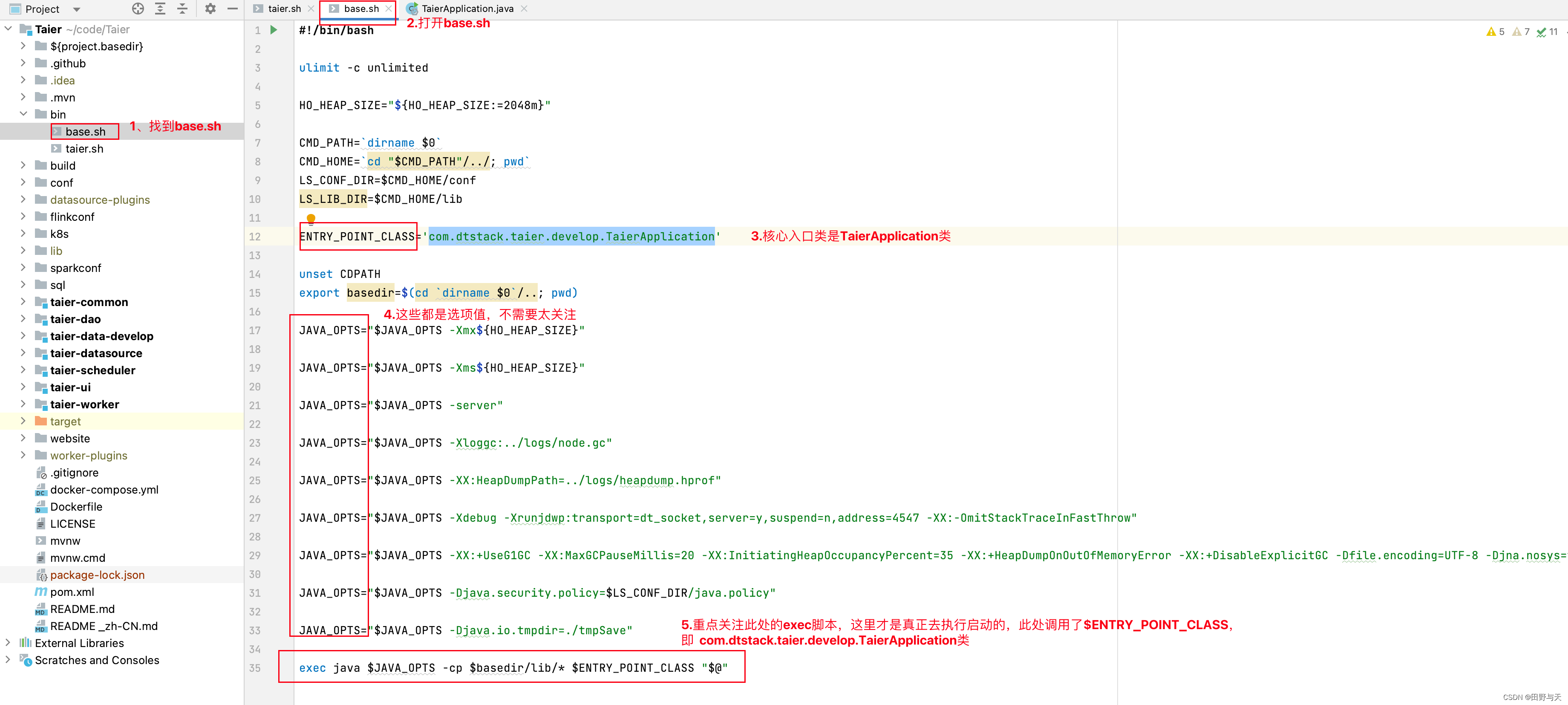
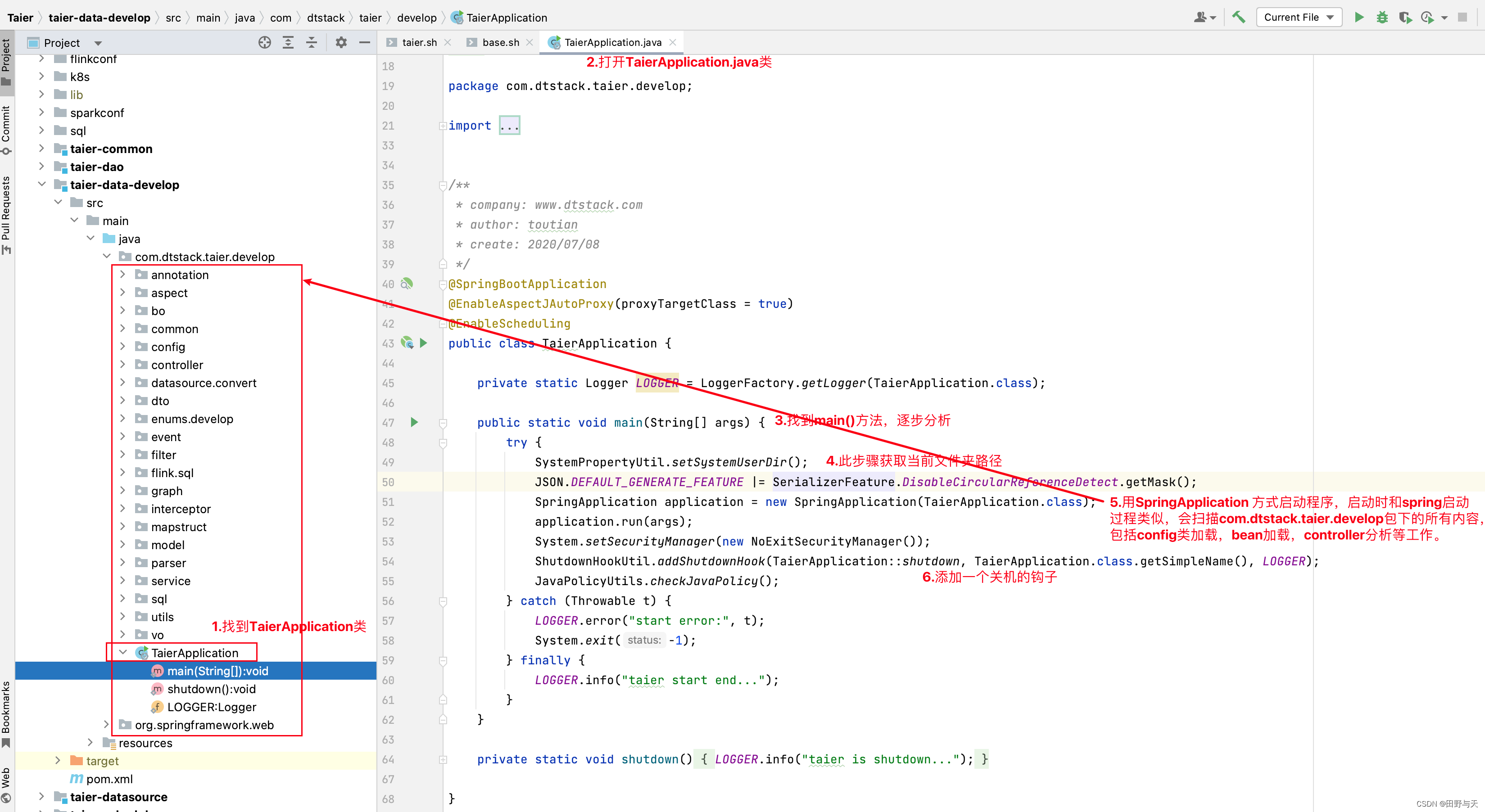
3:打开com.dtstack.taier.develop.TaierApplication类
然后有人就疑惑了,这就结束了???
其他模块如何启动的呢?
最开始笔者也很疑惑,也找不到很多的资料参考。后来是经过调试才发现的一些小机关。
重要的点:
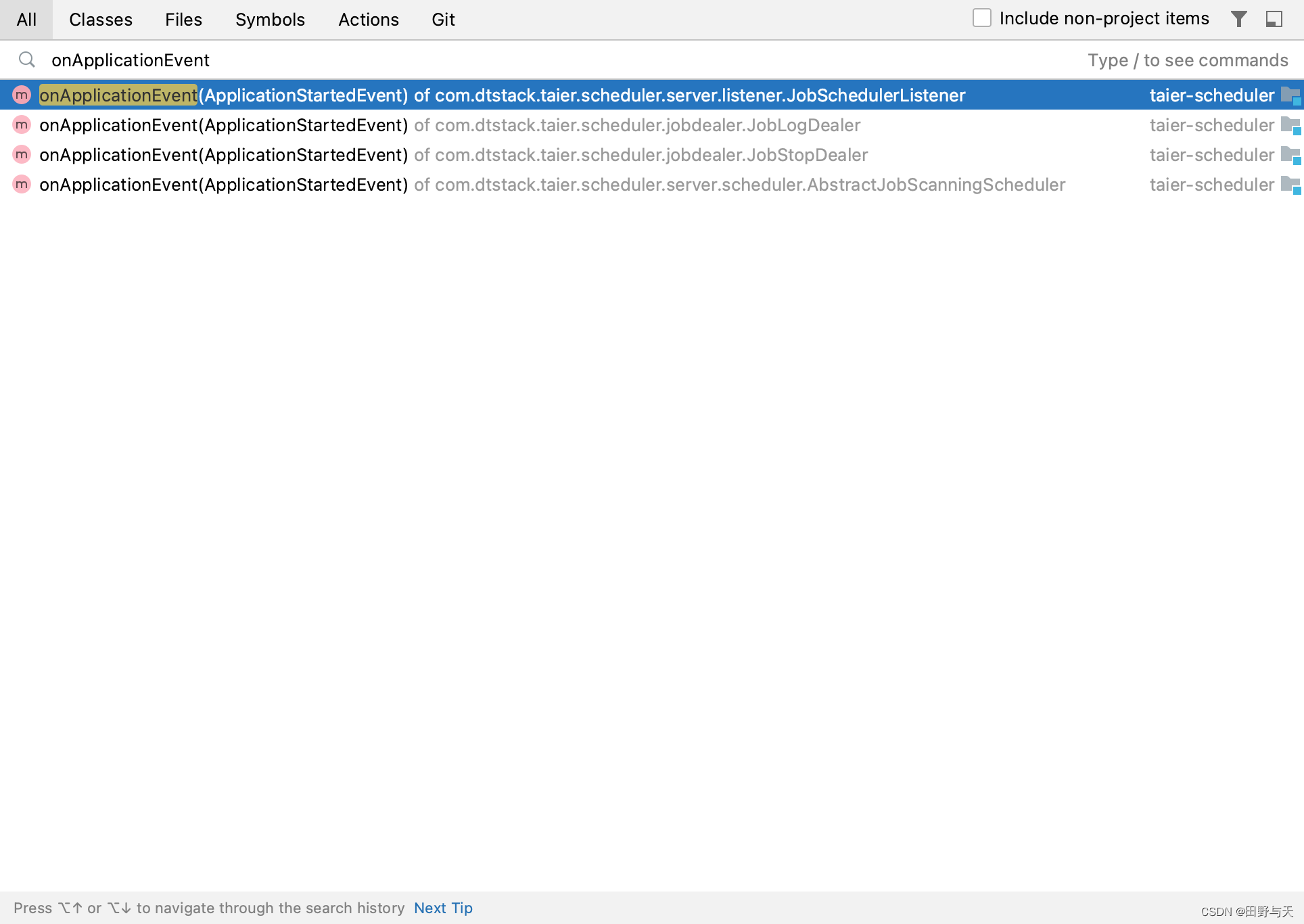
spring的onApplicationEvent方法会在spring启动过程中执行。
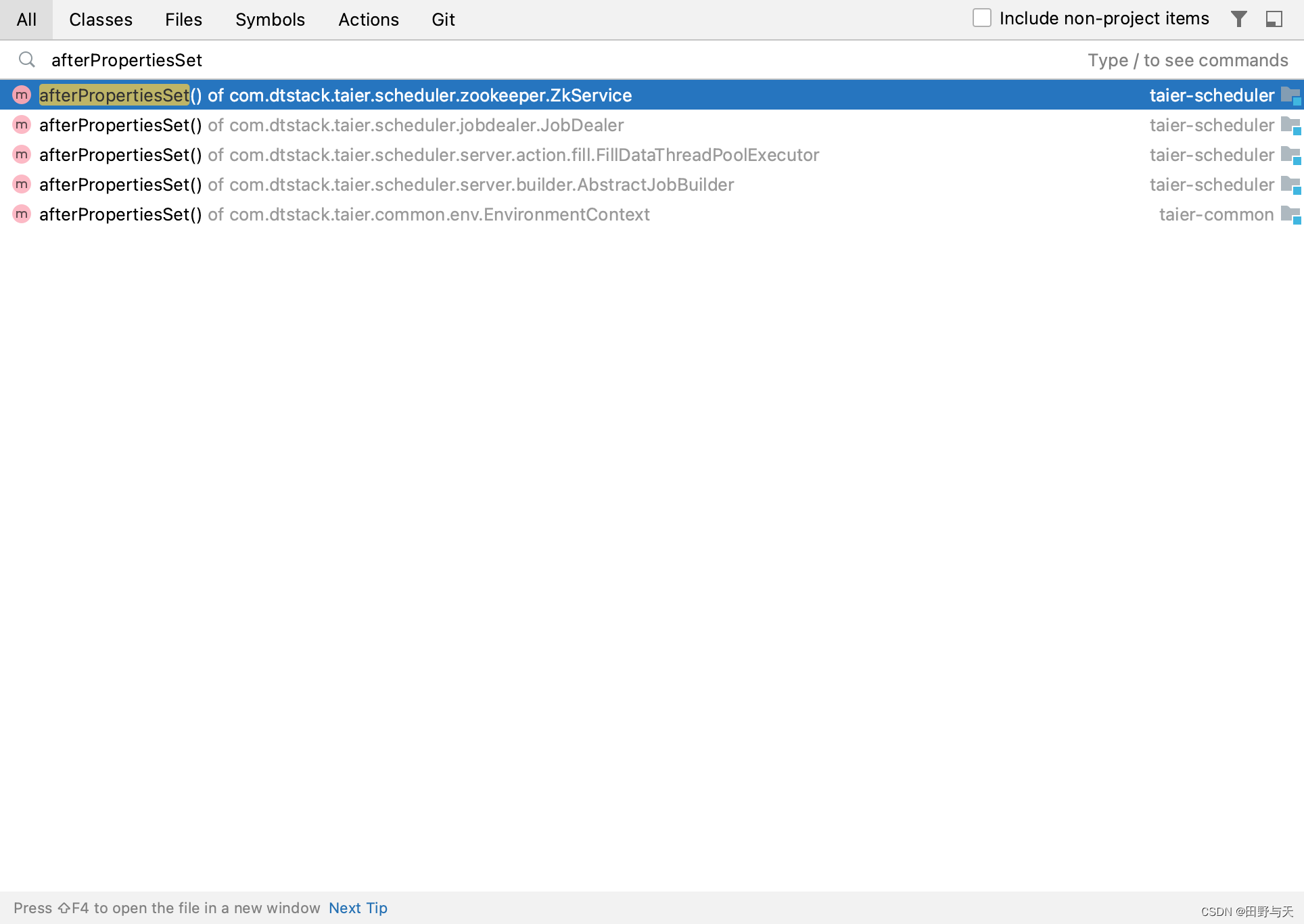
spring的afterPropertiesSet方法会在spring启动过程中执行。
Taier的其他部分启动就是散落在各个类的这俩方法里的。要快速找到他们也很简单,idea直接双击shift,然后搜索onApplicationEvent以及afterPropertiesSet就可以找到了。如下所示:
调试的时候我还特地测试了一下这5个afterPropertiesSet()方法每次启动被spring拉起的顺序是不是一致的,还是每次随机的,测试了多次发现其实是固定的,具体是如何固定的,我暂时也没有深究,有发现的小伙伴可以告知一下哦。
这是我调试的结果:第四个、第六个都是ZkService.java的afterPropertiesSet()方法
第一个执行的afterPropertiesSet
com/dtstack/taier/common/env/EnvironmentContext.java 的 afterPropertiesSet()
第二个执行的afterPropertiesSet
com/dtstack/taier/scheduler/jobdealer/JobDealer.java 的 afterPropertiesSet()
第三个执行的afterPropertiesSet
com/dtstack/taier/scheduler/server/builder/AbstractJobBuilder.java 的 afterPropertiesSet()
第四个执行的afterPropertiesSet
com/dtstack/taier/scheduler/zookeeper/ZkService.java 的 afterPropertiesSet()
第五个执行的afterPropertiesSet
com/dtstack/taier/scheduler/server/action/fill/FillDataThreadPoolExecutor.java 的 afterPropertiesSet()
第六个执行的afterPropertiesSet
com/dtstack/taier/scheduler/zookeeper/ZkService.java 的 afterPropertiesSet()
然后就是我自己在看代码的过程中,脑海中浮现的一些问题,以及自己看代码的解答,仅供参考哈。不正确的地方请大家指出哦。
问题一:
可能有的小伙伴看代码的时候有疑问,只看到taier-data-develop模块的类启动了,那么taier-scheduler类以及其他类是怎么启动的呢?
答案:由于taier-data-develop模块下的代码很多都会依赖taier-scheduler模块代码。比如ConsoleService类里可以搜索一下JobDealer类,ConsoleService类是taier-data-develop模块下的,JobDealer是taier-scheduler模块下的代码。

因此表面上看只是启动了taier-data-develop模块的代码,其实不是的,其实启动了taier-data-develop类以及它依赖的所有代码。
这个图从右往左看,ConsoleService类里可以搜索到JobDealer类,也就是ConsoleService类依赖JobDealer类。
同理,JobDealer类里可以搜索到JobSubmittedDealer类,也就是JobDealer类依赖JobSubmittedDealer类。
同理,JobSubmittedDealer类里可以搜索到JobSubmitDealer类,也就是JobSubmittedDealer类依赖JobSubmitDealer类。
同理,JobSubmitDealer类里可以搜索到JobPartitioner类,也就是JobSubmitDealer类依赖JobPartitioner类。
同理,JobPartitioner类里可以搜索到QueueListener类,也就是JobPartitioner类依赖QueueListener类。
其他的我不再一一分析依赖链。只是想通过这个例子说明,taier-data-develop模块是依赖taier-scheduler模块的代码。
因此表面上只是启动了taier-data-develop模块的代码,其实启动了taier-data-develop类以及它依赖的所有代码,这其中就包括taier-scheduler模块的代码。
因此,每一个含有afterPropertiesSet方法的类都要分析,每个afterPropertiesSet方法在启动时都会一并启动的。
问题二
Taier是当天提交的Task要第二天定点才会生成Task的实例(Job)。所以这个是怎么实现Task转Job的呢?哪个线程负责的?何时实现的?
答案:首先观察一下AbstractJobBuilder的afterPropertiesSet()方法初始化了一个ThreadPoolExecutor,名称为jobGraphBuildPool
然后第二步观察在AbstractJobBuilder类的继承类CycleJobBuilder类中,有一处会调用submit方法,向这个线程提交了运行程序。这个submit()提交了一个Runnable类,所以其实是在这个Runnable里实现了将Task转为Task实例(Job)。加粗的buildJob大家可以仔细去看看源码。
jobGraphBuildPool.submit(() -> {
try {
for (ScheduleTaskShade batchTaskShade : batchTaskShades) {
try {
List<ScheduleJobDetails> scheduleJobDetails = RetryUtil.executeWithRetry(() -> buildJob(batchTaskShade, triggerDay, sortWorker),
environmentContext.getBuildJobErrorRetry(), 200, false);
// 插入周期实例
savaJobList(scheduleJobDetails);
} catch (Throwable e) {
LOGGER.error("build task failure taskId:{}", batchTaskShade.getTaskId(), e);
}
}
} catch (Throwable e) {
LOGGER.error("!!! buildTaskJobGraph build job error !!!", e);
} finally {
sph.release();
ctl.countDown();
}
});
问题三:
既然CycleJobBuilder负责把Task转为Job,那么CycleJobBuilder类是何时被执行的呢?是谁来触发执行它的呢?
我们先找找看谁调用过CycleJobBuilder这个类。看代码后我们发现JobGraphBuilderTrigger类中有个run方法,里边有调用CycleJobBuilder这个类。我们把代码贴上来看看:
JobGraphBuilderTrigger的run()方法:
@Override
public void run() {
try {
if (RUNNING.get()) {
try {
String triggerDay = getTriggerDay(environmentContext.getJobGraphBuildCron());
LOGGER.warn("---check jobGraph build day:{} job graph start!--", triggerDay);
cycleJobBuilder.buildTaskJobGraph(triggerDay);
LOGGER.warn("---check jobGraph build day:{} job graph end!--", triggerDay);
} catch (Exception e) {
LOGGER.error("", e);
}
} else {
LOGGER.warn("---triggering, but Running is false---");
}
} catch (Exception e) {
LOGGER.error("---trigger job graph error---", e);
}
}
重点在cycleJobBuilder.buildTaskJobGraph(triggerDay);这行代码。
triggerDay先计算当前的时间是不是已经大于定时的时间,如果是,那么triggerDay就是明天的日期,如果当前时间还没到当前定时的时间,那么triggerDay就是今天的日期。
cycleJobBuilder.buildTaskJobGraph()方法里会判断triggerDay对应的job是不是已经生成过了,具体就是去查看schedule_job_graph_trigger表里有没有trigger_time字段等于triggerDay的Job,如果有,证明已经生成过了,如果没有,那么说明没有生成过。
问题四:
JobGraphBuilderTrigger这个类是何时被触发的呢?
当上述的选举结束,当前节点被选举为master节点的时候,会执行
setIsMaster方法,这个方法里会执行masterNodeDealer.submit(new JobGraphChecker());这一句代码,这句代码就把JobGraphChecker类正式启动起来了
zkService#afterPropertiesSet()中调用zkRegistration();
zkRegistration()调用initScheduledExecutorService();
initScheduledExecutorService()调用new MasterListener(failoverStrategy, zkClient, latchPath, localAddress)来构造MasterListener对象
MasterListener在构造时候,会构造FailoverStrategy类对象
FailoverStrategy类在初始化的时候还会被Spring框架自动注入JobGraphBuilderTrigger类的对象
@Autowired
private JobGraphBuilderTrigger jobGraphBuilderTrigger;
而JobGraphBuilderTrigger类初始化的时候又会执行下面代码创建一个线程池:线程池叫
scheduledService
scheduledService = new ScheduledThreadPoolExecutor(1, new CustomThreadFactory(“JobGraphTrigger”));
接着JobGraphBuilderTrigger类会执行scheduledService.scheduleWithFixedDelay方法,该方法会调用FailoverStrategy的setIsMaster()方法,
setIsMaster()方法会调用jobGraphBuilderTrigger.dealMaster(true);
dealMaster(true)方法会判断如果自己节点是master的话,会执行startJobGraph()
如果发现自己不是master节点就会执行stopJobGraph()方法。这样确保只有一个master节点会执行Task到Job的转换过程,而其他节点则不会。
public void dealMaster(boolean isMaster) {
try {
if (isMaster) {
startJobGraph();
} else {
stopJobGraph();
}
} catch (Throwable e) {
LOGGER.error("JobGraphBuilderTrigger.dealMaster error:", e);
}
}
而startJobGraph()方法如下:
scheduledService.scheduleAtFixedRate(
this,
100,
CHECK_JOB_BUILD_INTERVAL,
TimeUnit.MILLISECONDS);
CHECK_JOB_BUILD_INTERVAL = 60 * 10 * 1000L;//等于600秒
也就是每隔600秒master会检查一次是否到时间要把task构建为job了,如果到点了就执行,如果没有到点就不执行。
问题五:
多台机器同时启动的时候,是如何选master节点的?
Spring启动时候会执行MasterListener这个类的构造方法,这个构造方法里有下面的代码,
private LeaderLatch latch;
this.latch = new LeaderLatch(curatorFramework, latchPath, localAddress);
this.latch.addListener(this);
this.latch.start();
可以发现是用LeaderLatch类来选master的,这是比较常见的分布式系统选master节点的方法。
有兴趣的具体可以参考这篇文章,此处不展开LeaderLatch类的介绍。
Curator应用场景(三)-Master选举LeaderLatch,LeaderSelector使用及原理分析_hosaos的博客-CSDN博客














 2372
2372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









