






GRES: Generalized Referring Expression Segmentation
出版年份:2023
出版期刊:CVPR2023
文章作者:Liu Chang,Ding Henghui,Jiang Xudong
回顾基础知识:
transformer注意力的计算
图像分割
摘要+引言+结论:
研究背景:
1、现有的引用分割数据集和方法通常仅支持单目标表达式,即一个表达式指代一个目标对象。
2、基于这个问题,这篇文章定义了一个名为广义引用分割(Generalized Referring Expression Segmentation,GRES)的新任务
研究设计(这篇文献的研究方法是什么,数据是怎么获取的):
自己建立数据集“gRefCOCO”
自己建立基线方法
研究目的:
目前研究的局限性
经典 RES 不考虑与图像中任何对象都不匹配的 notarget 表达式
现有的大多数数据集(如最流行的 RefCOCO )都不包含指向多个实例的多目标表达式
创建了数据集对RefCOCO 进行了补充了多目标样本和无目标样本
新任务的应用场景
在多目标表达式的支持下,可以使用 "所有的人 "和 "左边的两个球员 "等表达式作为输入,在一次前向处理中选择多个对象(见图 2a),
使用 "前景 "和 "孩子 "等表达式实现用户自定义的开放词汇分割。
在无目标表达式的支持下,用户可以在一组图像上应用相同的表达式,以识别哪些图像包含语言表达中的对象,如图 2b。
如果用户想在一组图像中查找和消隐某些东西,这就非常有用,类似于图像检索,但更加具体和灵活。
更重要的是,允许多目标和无目标表达增强了模型的可靠性和鲁棒性,以应对任何类型的表达都可能意外出现的现实场景,例如,用户可能意外或故意打错一个句子
理论基础:
区域与区域之间的相互作用很重要
但在GRES中,由于多目标表达式涉及一个表达式中的多个对象,因此对长范围的区域-区域依赖关系进行建模更具挑战性和必要性。
从这一点出发,我们提出了一种基于区域的GRES方法,通过实体线索显式地建模区域之间的相互作用。我们设计了一个网络,将图像分割成区域,并使它们明确地相互交互。此外,不同于以前的工作,区域来自输入图像的简单硬分割,我们的网络软对齐每个区域的特征,实现了更多的灵活性。
相关工作
相关的referring任务和数据集
指代分割方法
研究方法:
数据集的建立
广义RES .为了解决经典RES中的这些局限性,我们提出了一个名为广义参考表达式分割( Generalized Reference Expression Segmentation,GRES )的基准,该基准允许表示任意数量的目标对象的表达式。一个GRES数据样本包含四项:一个图像I,一个语言表达T,一个覆盖T所指代的所有目标像素的真实分割掩码MGT,以及一个表示T是否为非目标表达的二进制无目标标签EGT。T中的实例数不受限制。GRES模型以I和T作为输入,预测一个掩码M。对于无目标表达式,M应全部为负。”
具体看数据集笔记
模型
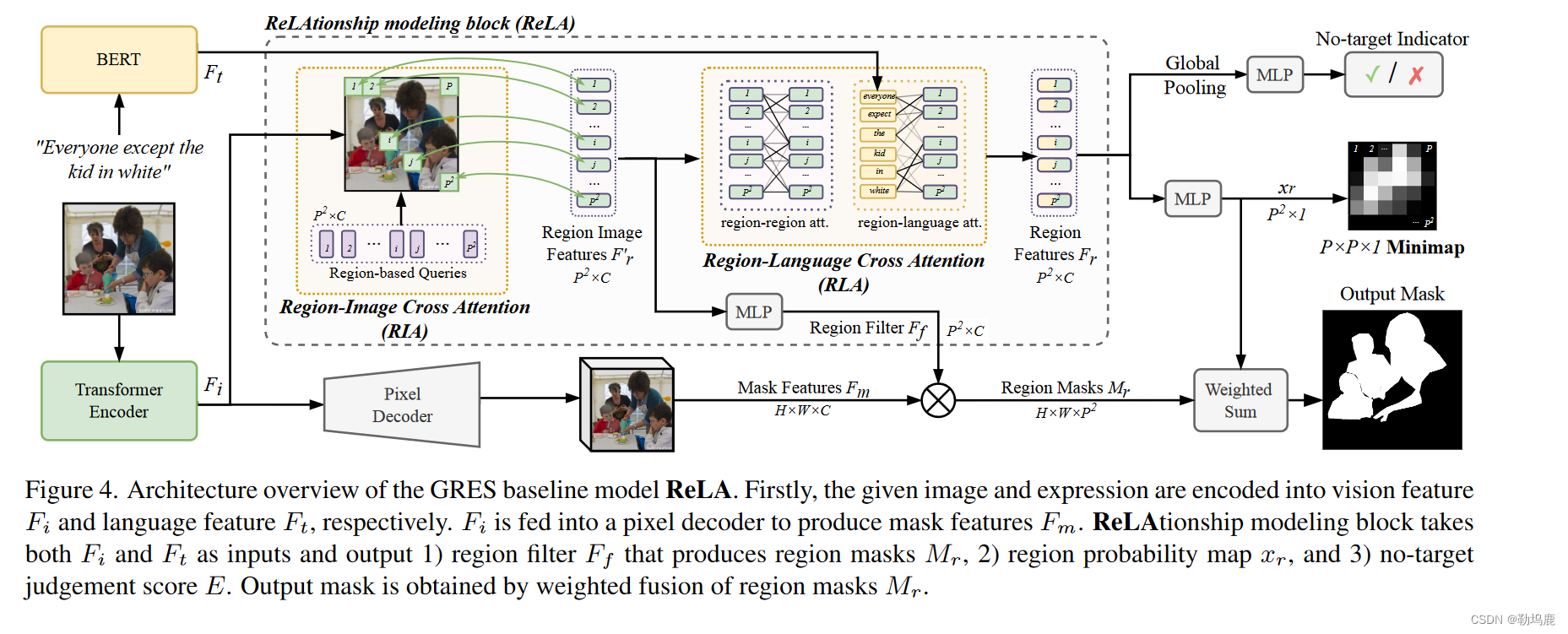
见图4。GRES基线模型ReLA的架构概述。首先,将给定的图像和表情分别编码为视觉特征Fi和语言特征Ft。Fi送入像素解码器产生掩膜特征Fm。关系建模模块以Fi和Ft作为输入,输出1 )产生区域掩码Mr的区域滤波器Ff,2 )区域概率图xr,3 )无目标判决分数E。输出掩码由区域掩码Mr加权融合得到。”
图像编码器:swim transformer
提取视觉特征Fi∈RH × W × C,其中H,W为空间尺寸,C为通道尺寸
文字编码器:BERT
产生语言特征Ft∈RNt × C,其中Nt是表达式中的单词数
Pixel Decoder
Fi送入像素解码器,得到掩膜特征Fm,用于掩膜预测。
ReLAtionship建模模块
Fi和Ft被送入我们提出的ReLAtionship建模模块
将特征图划分为P × P = 个区域,并对它们之间的相互作用进行建模。这些"区域"对应于图像的P × P Patches,如ViT
其空间区域的形状和大小不是预先设定的,而是由 ReLA 动态发现的,这与之前使用硬分割的研究成果不同
7:“An image is worth 16x16 words: Transformers for image recognition at scale” 一幅图像大小为16 × 16字:用于图像识别的比例尺转换器
21:“Restr: Convolution-free referring image segmentation using transformers.”
37:“Segmenter: Transformer for semantic segmentation.”
41:“Segformer: Simple and efficient design for semantic segmentation with transformers.”\

Fr区域特征
Ff区域过滤
损失
产出与损失。预测掩模M由地面-真值目标掩模MGT监督。P × P概率图xr由MGT下采样得到的"制造信息服务"监督,这样我们就可以将图像中的每个区域与其对应的块链接起来。
同时,我们取所有区域特征的全局平均值Fr来预测一个非目标标签E。
在推断中,如果预测E为正,则输出掩码M将被设置为空。即为无目标
M、xr和E由交叉熵损失引导。
关系建模模块
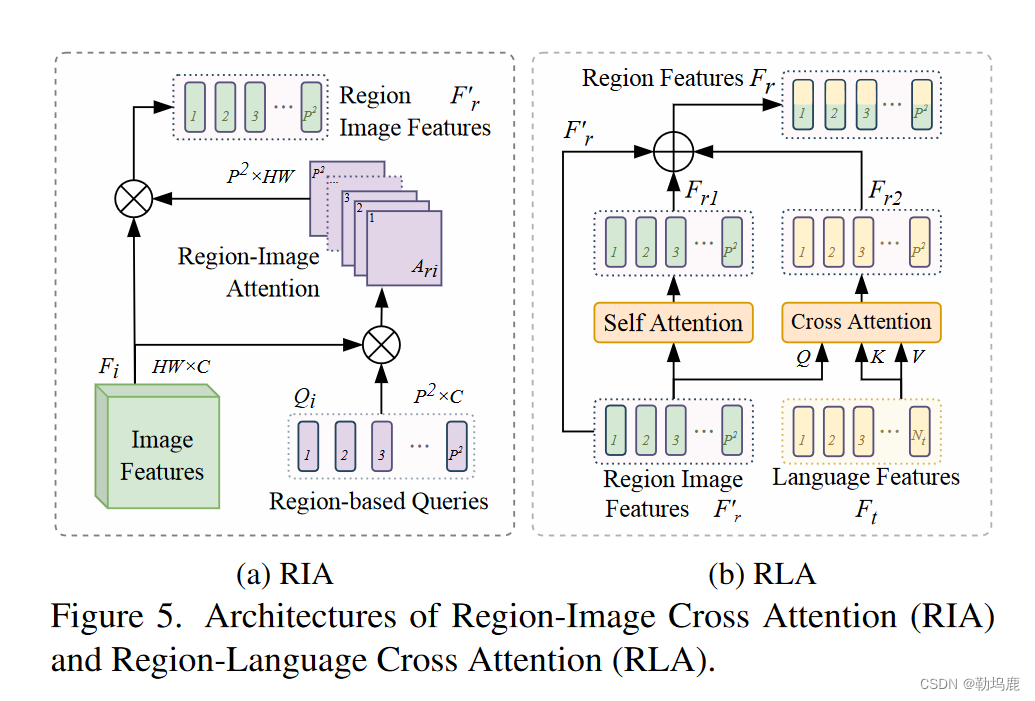
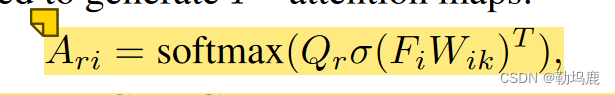
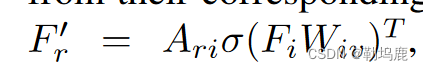
RIA区域-图像交叉注意力
灵活采集区域图像特征
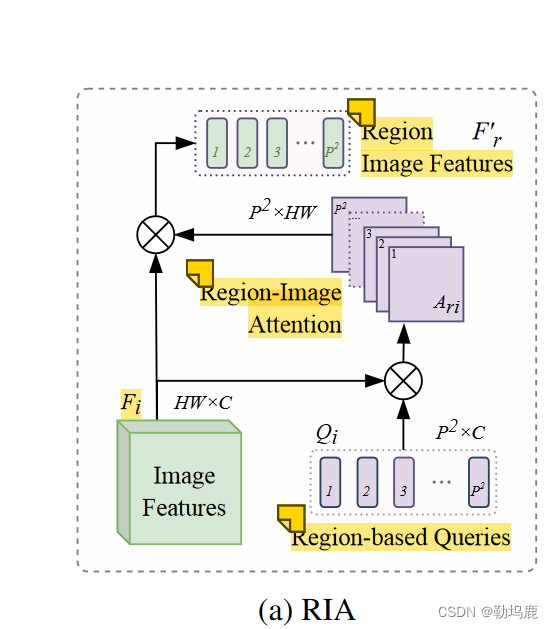
RIA将视觉特征Fi和P2可学习的基于区域的查询Qr作为输入。在图4所示的制造信息服务的监督下,每个查询对应图像中的一个空间区域,并负责该区域的特征解码。结构如图5a所示。首先,图像特征Fi与P 2个查询嵌入之间的注意力Qr∈RP 2 ×
得到的Ari∈RP 2 × HW给每个查询一个H × W的注意力图,表示其在图像中对应的空间区域。接下来,我们使用这些注意力图从它们对应的区域中获得区域特征:F′r = Ariσ ( FiWiv ) T,其中Wiv是C × C可学习参数。”
最终得到区域图像特征
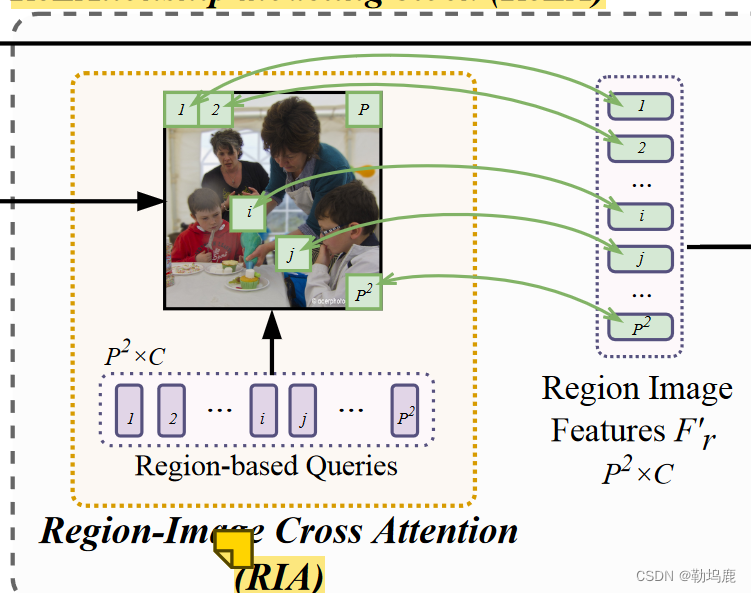
这样,每个区域的特征都能从其相关位置动态收集到。与硬性将图像分割成块相比,这种方法更具灵活性。一个实例可以由最小图中的多个区域来表示(见图 4),从而使区域在子实例级别上表示更细粒度的属性,例如人的头部和上半身。要解决 GRES 中复杂的关系和属性描述问题,就需要这种子实体表示法。根据用于掩码预测的 F ′ r,可获得包含区域线索的区域过滤器 Ff。F ′ r 将进一步输入 RLA,用于区域-区域和区域-词交互建模。
RLA区域语言交叉注意力
包括了一个自注意力和一个交叉注意力
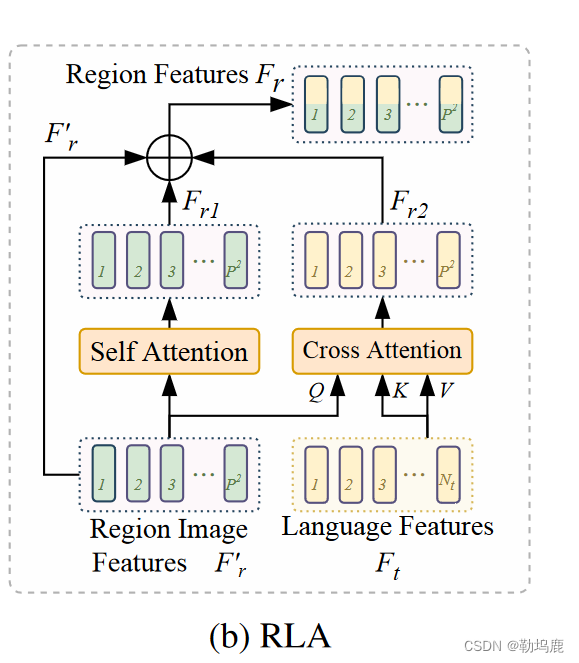
区域图像特征F′r来源于整理图像特征,这个特征不包含区域与语言信息之间的关系。
我们提出RLA模块对区域和区域-语言交互进行建模。
如图5b所示,RLA由区域图像特征F′r的自注意力和多模态交叉注意力组成。
自注意力模型对区域-区域依赖关系进行建模。它通过将一个区域特征与所有其他区域进行交互来计算注意力矩阵,并输出关系感知区域特征Fr1。
同时,交叉注意力将语言特征Ft作为Value和Key输入,区域图像特征F′r作为Query输入。”
这首先对每个单词和每个区域之间的关系进行建模:
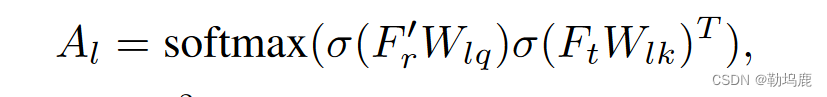
然后使用派生的单词-区域注意力形成语言感知的区域特征”
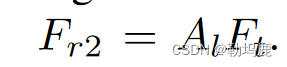
最后,将交互感知的区域特征Fr1、语言感知的区域特征Fr2和区域图像特征F′r相加,构成MLP进一步融合三组特征:Fr = MLP( F′r + Fr1 + Fr2)。”
得到区域特征Fr
实验:
评价指标
除了广泛使用的RES度量指标累积IoU ( cIoU )和Precision @ X ( Pr @ X )外,进一步引入了GRES的无目标精度( N-acc . )、目标精度( T-acc . )和广义IoU ( gIoU )。
无目标精度 N-acc、目标精度 T-acc
这两个都是针对无目标识别问题
这个问题实际上是一个分类问题
N-acc衡量识别非目标样本的性能
表示识别的无目标样本中有多少是正确的
分类模型中的acc
T-acc
非目标上的泛化对目标样本性能的影响程度,即有多少有目标的样本被误分类为非目标
广义IoU gIoU
?有一点疑问
gIoU。众所周知,cIoU偏爱较大的对象[ 40、44 ]。由于多目标样本在GRES中具有更大的前景区域,我们引入广义IoU ( gIoU ),将所有样本同等对待。与均值IoU一样,gIoU计算每个图像IoU在所有样本上的平均值。对于无目标样本,将真阳性无目标样本的IoU值视为1,假阴性样本的IoU值视为0。”
消融实验
数据集的必要性
比较了同一模型在RefCOCO和gRefCOCO上训练的结果。

如图6所示,图像( a )是使用共享属性( ‘穿黑夹克’)来寻找"两个人"的多目标样本。在RefCOCO上训练的模型只找到一个,即使表达式明确指出有两个目标对象。
图像( b )给出一个无目标的表达,RefCOCO训练的模型输出一个无意义的掩码。
结果表明,仅在Ref COCO等单目标指称表达数据集上训练的模型不能很好地推广到GRES上。相比之下,新构建的gRefCOCO可以有效地使模型能够处理表示任意数量对象的表达式。
RIA的设计
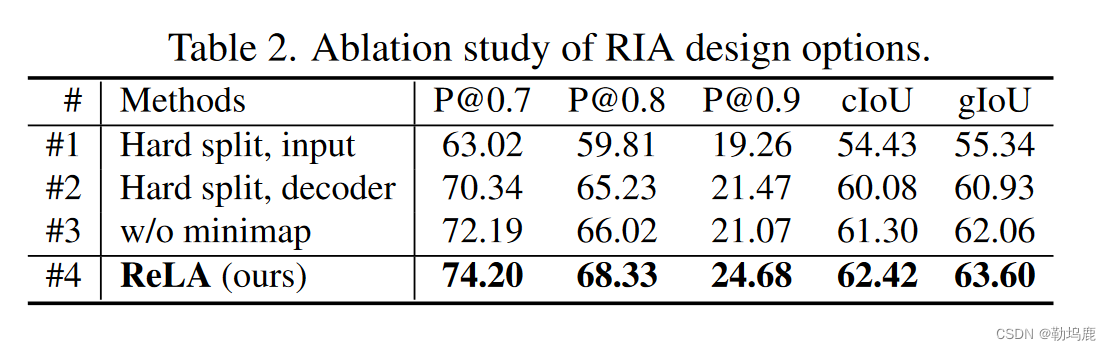
表明动态区域特征融合自适应区域分配的有效性
我们考察RIA带来的性能增益。在模型# 1中,我们遵循先前的方法[ 7、21 ],并将图像严格地分割成P × P块,然后将它们送入编码器。表2 . 2表明该方法不适合我们的ReLA框架,因为它使全局图像信息由于完整性受损而变得不明显。在模型# 2中,
RIA被替换为将图像特征平均池化为P × P。gIoU从模型# 1中获得了5.59 %的显著增益,表明了全局上下文在视觉特征编码中的重要性。
然后,将我们提出的动态区域特征聚合添加到每个查询中,可以获得另外2.67 %的gIoU增益(式( 3 ) )。( 2 ) ),表明了所提自适应区域分配的有效性。”
此外,我们还研究了将查询与实际图像区域联系起来的重要性。
在模型# 3中,我们去掉了制造信息服务的监督,使得基于区域的查询Qr变成了普通的可学习查询。
导致g Io U下降1.54 %。这表明查询与空间图像区域之间的明确对应关系对我们的网络是有益的。
得到了三点重要结论
RLA的设计

表明依赖关系建模的重要性
表2 . 3说明了依赖关系建模对GRES的重要性。在基线模型中,RLA被逐点相乘的区域特征和全局平均的语言特征取代,以实现与先前工作[ 5、32 ]类似的基本特征融合。
**在模型# 2中,将语言交叉注意力加入到基线模型中,带来了2 %的gIoU增益。**这说明了区域-词交互建模的有效性。然后,我们进一步加入地区自我关注来考察地区-地区关系的重要性。区域-区域关系建模带来了3.85 % gIoU的性能增益。区域-区域和区域-词关系建模共同带来了5.07 % gIoU的显著提升。”
交叉注意力和自注意力逐步增加
区域的数量

较小的P导致较粗的区域,不利于捕获细粒度的属性,而较大的P消耗更多的资源,减小了每个区域的面积,使得关系学习变得困难。我们对表中P的选取进行实验。④寻找优化后的P。该模型的性能随着P的增加而提高,直到10,被选为我们的设置。
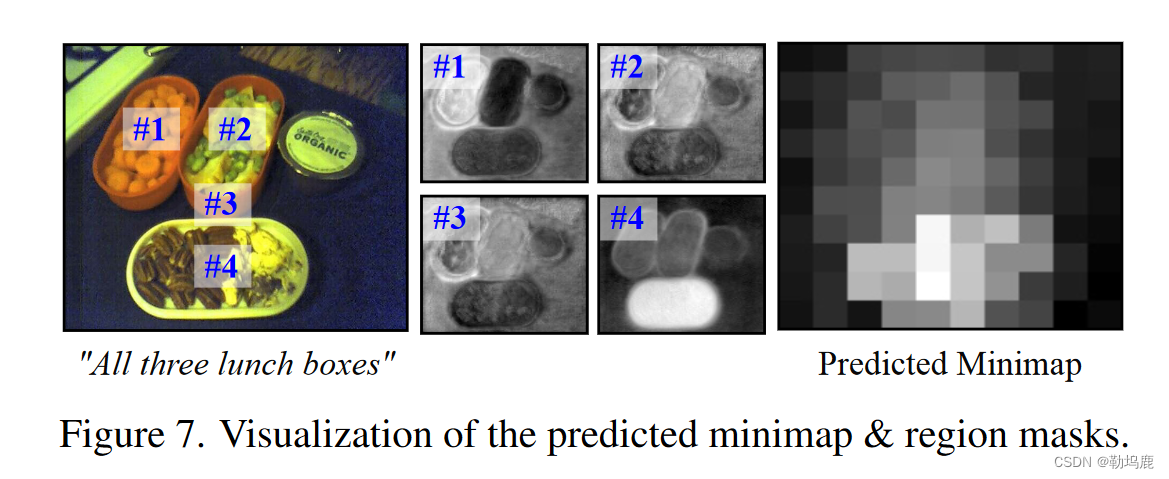
在图7中,我们可视化了预测的minimap xr 和 区域map Mr
xr 显示了每个区域的大致目标概率,显示了minimap监督的有效性。
我们还看到,区域掩码捕捉到了相应区域的空间相关性。
由于区域大小和形状灵活,每个区域掩码不仅包含该区域的实例,还包含其他具有强关系的实例。
例如,区域# 4位于底部午餐盒内部,但由于输入表达式告诉3个盒子都是目标,因此在区域# 4的输出掩码中,前两个也会引起一些响应。”
结果:
与最先进的Res方法进行比较。

这一部分不涉及无目标的比较,因为小于50哥像素点的被视为无目标
对于单级网络,小于50个正像素的输出掩码被清除为全负,以更好地识别非目标。”
对于两阶段网络MattNet [ 46 ],我们让模型为每个实例预测一个二进制标签,表示该候选实例是否为目标,然后合并所有目标实例。”
如表所示。5时,这些经典的RES方法在包含多目标和无目标样本的gRefCOCO上表现不佳。进一步地,为了更好地验证显式建模的有效性,我们在VLT [ 5 ]和LAVT [ 44 ]上添加了我们的ReLA来代替它们的解码器部分。由Tab . 5,我们的显式关系建模极大地提升了模型的性能。例如,加入Re LA后,LAVT的c Io U性能在val集上提升了4 %以上。”
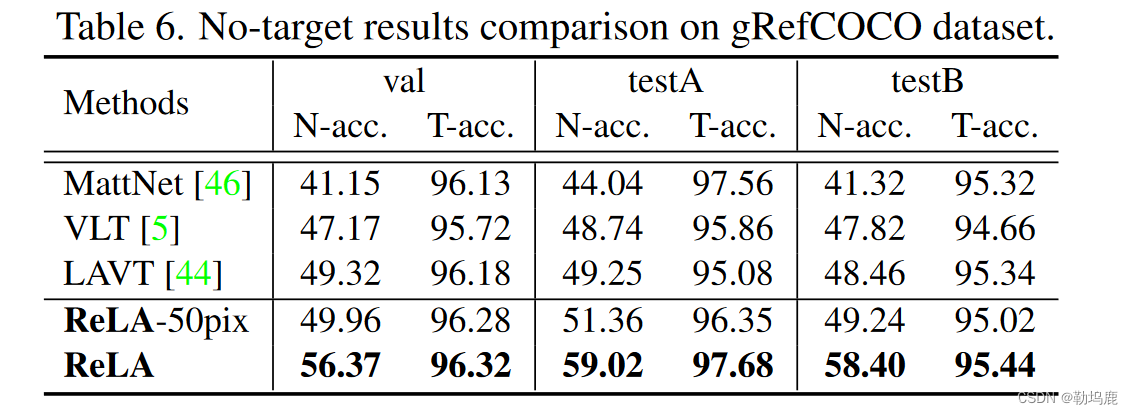
如表所示,所有方法的T - acc .大多高于95 %,表明我们的gRefCOCO在泛化到无目标样本的同时,并没有显著影响模型的靶向性能。
但是从经典RES方法的Nacc .中我们看到,即使使用非目标样本进行训练,仅仅根据输出掩码来识别非目标样本也是不令人满意的。
我们还测试了我们的模型,禁用了无目标分类器,仅使用输出掩膜中的正像素计数来识别无目标样本(表1中’ ReLA-50pix '。6 )。性能与其他方法类似。这表明需要一个专用的无目标分类器。
然而,尽管我们的N - acc .高于RES方法,但仍有约40 %的非目标样本被遗漏”
可能是因为许多非目标表述是十分具有欺骗性的,与图中真实的实例相似
定性分析结果

定性结果。我们的模型在gRefCOCO的val集上的一些定性例子如图8所示.在Image ( a )中,我们的模型可以检测并精确分割同类别( “女孩”)或不同类别( “女孩和狗”)的多个目标,表现出了较强的泛化能力。图像( b )使用计数词( “两个碗”)和共享属性( ‘右边’)来描述一组目标。图( c )有一个复合句,表明我们的模型能够理解排除关系:“除了模糊的家伙”,并做出了很好的预测。”
失败原因和讨论

我们在图9中展示了我们方法的一些失败案例。图像( a )介绍了一种占有关系:“左边的女孩和她的笔记本电脑”。这是一个极具欺骗性的案例。在图像中,中心的笔记本电脑比左边的笔记本电脑更占优势,更接近左边的女孩,因此模型将中心的笔记本电脑突出为"她的笔记本电脑"。这样一个具有挑战性的情况需要模型对所有对象都有深刻的理解,对图像和表达有上下文的理解。第二种情况下,该表达为无目标表达,指"穿着灰色衬衫坐在床上的人"。在图像中,确实有一个穿着灰色衬衫的坐着的人,但他坐在离床很近的黑色椅子上。这进一步要求模型能够观察到所有对象的细粒度细节,并进行理解”
在经典数据集上的结果
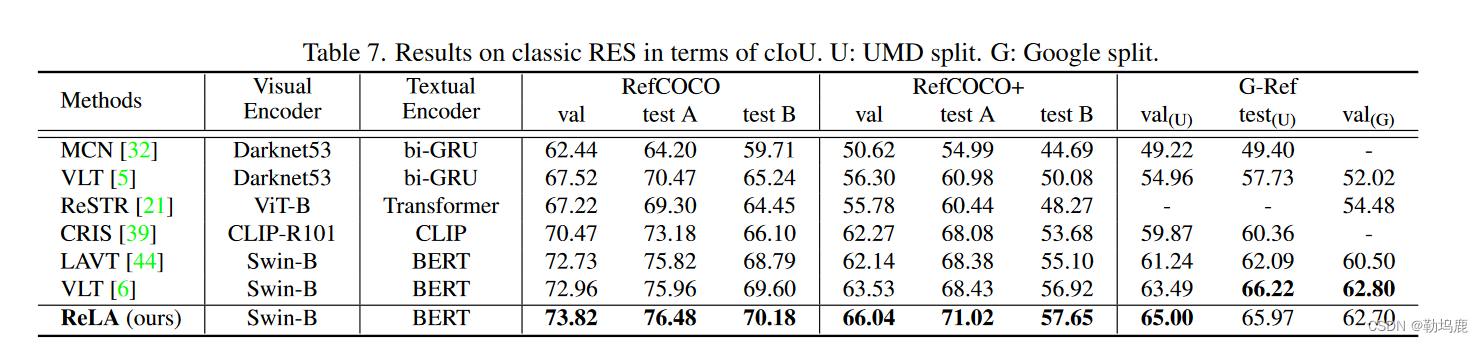
本文提出的框架在经典数据集上也是有改进的,但是改进不是十分明显,因为原来的任务要求不高,本文的模型是用来解决要求更高的问题的
讨论:
我们分析并解决了经典RES任务的局限性,即它不能处理多目标和非目标表达式。在此基础上,定义了一个新的基准,称为广义参考表达式分割( Generalized Reference Expression Segmentation,GRES ),允许表达式中包含任意数量的目标。为了支持对GRES的研究,我们构建了一个大规模数据集gRefCOCO。我们提出了一种针对GRES的基线方法ReLA,显式地建模不同图像区域和单词之间的关系,在经典的RES和新提出的GRES任务上都取得了一致的最新结果。提出的GRES极大地降低了对自然语言输入的限制,增加了对多实例和图像中没有正确对象的应用范围,具有开放性”
●总结
创新点:
1、
2、
3、
4、
局限性:
在无目标的识别上还有很大的进步空间
对于比较有迷惑性的信息仍然无法识别
需要加强对文字和图片的理解能力
改进方法:
是否能针对交叉熵损失函数进行修改
(具体可以看一下综述)
设计网络增加非目标样本识别的准确性
复现代码,看一下研究失败数据集失败的原因,针对性的进行改进
能不能使用模块化的方法加强物体与物体之间的关系?
疑问与发现:
1、giou不太明白
理解:应该与均值IOU的定义相同,加上了无目标的定义
2、p*p的动态到底是如何实现的
与之前的硬分割不同具体不同在哪里
看一下7与21理解什么是硬分割
后期回顾:
自己也是才接触referring image segmentation,请各位大佬多指教
有问题可以在评论区多讨论














 1132
1132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









